Erste Schritte mit der Evaluierung von Antworten in einer Chat-App in JavaScript
In diesem Artikel erfahren Sie, wie Sie die Antworten einer Chat-App anhand einer Reihe von korrekten oder idealen Antworten (als „Ground Truth“) evaluieren können. Wenn Sie Ihre Chat-Anwendung so ändern, dass sich dies auf die Antworten auswirkt, führen Sie eine Evaluierung durch, um die Änderungen zu vergleichen. Diese Demoanwendung bietet Tools, die Sie sofort verwenden können, um die Ausführung von Evaluierungen zu vereinfachen.
Indem Sie die Anweisungen in diesem Artikel befolgen, werden Sie:
- Verwenden Sie die bereitgestellten Beispielaufforderungen, die auf das jeweilige Thema zugeschnitten sind. Diese Eingabeaufforderungen befinden sich bereits im Repository.
- Generieren Sie Beispielbenutzerfragen und Ground Truth-Antworten aus Ihren eigenen Dokumenten.
- Führen Sie Evaluierungen mithilfe einer Beispielaufforderung mit den generierten Benutzerfragen aus.
- Überprüfen Sie die Analyse der Antworten.
Hinweis
In diesem Artikel wird mindestens eine KI-App-Vorlage als Grundlage für die Beispiele und Anleitungen im Artikel verwendet. KI-App-Vorlagen bieten Ihnen gut gepflegte, einfach bereitzustellende Referenzimplementierungen, die helfen, einen qualitativ hochwertigen Ausgangspunkt für Ihre KI-Apps zu gewährleisten.
Übersicht über die Architektur
Zu den wichtigsten Komponenten der Architektur gehören:
- In Azure gehostete Chat-App: Die Chat-App wird im Azure App Service ausgeführt.
- Das Microsoft KI-Chat-Protokoll bietet standardisierte API-Verträge über KI-Lösungen und Sprachen hinweg. Die Chat-App entspricht dem Microsoft KI-Chat-Protokoll, mit dem die Evaluierungs-App für jede Chat-App ausgeführt werden kann, die dem Protokoll entspricht.
- Azure KI-Suche: Die Chat-App verwendet Azure KI-Suche, um die Daten aus Ihren eigenen Dokumenten zu speichern.
- Beispielfragen-Generator: Kann viele Fragen für jedes Dokument zusammen mit der Antwort Ground Truth-Antwort generieren. Je mehr Fragen, umso länger die Evaluierung.
- Evaluator führt Beispielfragen und Eingabeaufforderungen für die Chat-App aus und gibt die Ergebnisse zurück.
- Mit dem Überprüfungstool können Sie die Ergebnisse der Evaluierungen überprüfen.
- Mit dem Diff-Tool können Sie die Antworten zwischen Evaluierungen vergleichen.
Wenn Sie diese Auswertung in Azure bereitstellen, wird der Azure OpenAI-Endpunkt für das GPT-4-Modell mit eigener Kapazität erstellt. Bei der Evaluierung von Chat-Anwendungen ist es wichtig, dass der Evaluator über eine eigene OpenAI-Ressource mit GPT-4 mit eigener Kapazität verfügt.
Voraussetzungen
Azure-Abonnement. Kostenloses Konto erstellen
Zugriff auf Azure OpenAI im gewünschten Azure-Abonnement gewährt.
Derzeit wird der Zugriff auf diesen Dienst nur auf Antrag gewährt. Sie können den Zugriff auf Azure OpenAI beantragen, indem Sie das Formular unter https://aka.ms/oai/access ausfüllen.
Bereitstellen einer Chat-App
Diese Chat-Apps laden die Daten in die Azure KI-Suche-Ressource. Diese Ressource ist erforderlich, damit die Evaluierungs-App funktioniert. Schließen Sie den Abschnitt Ressourcen bereinigen des vorherigen Verfahrens nicht ab.
Sie benötigen die folgenden Azure-Ressourceninformationen aus dieser Bereitstellung, die in diesem Artikel als Chat-App bezeichnet wird:
- Chat-API-URI: Der Service-Back-End-Endpunkt, der am Ende des
azd up-Prozesses angezeigt wird. - Azure KI-Suche. Die folgenden Werte sind erforderlich:
- Ressourcenname: Der Name des Azure KI-Suche-Ressourcennamens, der während als
Search servicewährend desazd up-Prozesses gemeldet wird. - Indexname: Der Name des Azure KI-Suche-Indexes, in dem Ihre Dokumente gespeichert sind. Diesen finden Sie im Azure-Portal für den Suchdienst.
- Ressourcenname: Der Name des Azure KI-Suche-Ressourcennamens, der während als
Die Chat-API-URL ermöglicht den Evaluierungen, Anforderungen über Ihre Back-End-Anwendung zu stellen. Die Azure KI-Suche-Informationen ermöglichen den Evaluierungsskripts, dieselbe Bereitstellung wie Ihr Back-End zu verwenden, mit den Dokumenten.
Nachdem Sie diese Informationen erfasst haben, sollten Sie die Entwicklungsumgebung der Chat-App nicht mehr verwenden müssen. Auf diese wird später in diesem Artikel mehrmals verwiesen, um anzugeben, wie die Chat-App von der Evaluierungs-App verwendet wird. Löschen Sie die Chat-App-Ressourcen erst, wenn Sie das gesamte Verfahren in diesem Artikel abgeschlossen haben.
- Chat-API-URI: Der Service-Back-End-Endpunkt, der am Ende des
Eine Entwicklungscontainerumgebung ist mit allen Abhängigkeiten verfügbar, die zum Abschließen dieses Artikels erforderlich sind. Sie können den Entwicklungscontainer in GitHub Codespaces (in einem Browser) oder lokal mit Visual Studio Code ausführen.
- GitHub-Konto
Öffnen Sie die Entwicklungsumgebung
Beginnen Sie jetzt mit einer Entwicklungsumgebung, in der alle Abhängigkeiten installiert sind, um diesen Artikel abzuschließen. Sie sollten Ihren Monitor-Arbeitsbereich so anordnen, dass Sie diese Dokumentation und die Entwicklungsumgebung gleichzeitig sehen können.
Dieser Artikel wurde mit der switzerlandnorth-Region für die Evaluierungsbereitstellung getestet.
GitHub Codespaces führt einen von GitHub verwalteten Entwicklungscontainer mit Visual Studio Code für Web als Benutzeroberfläche aus. Verwenden Sie für die einfachste Entwicklungsumgebung GitHub Codespaces, damit Sie die richtigen Entwicklertools und Abhängigkeiten vorinstalliert haben, um diesen Artikel abzuschließen.
Wichtig
Alle GitHub-Konten können Codespaces für bis zu 60 Stunden pro Monat mit zwei Kerninstanzen kostenlos verwenden. Weitere Informationen finden Sie im Artikel zu monatlich enthaltener Speicherkapazität und Kernstunden in GitHub Codespaces.
Starten Sie den Prozess, um einen neuen GitHub Codespace im Branch
maindes GitHub-RepositorysAzure-Samples/ai-rag-chat-evaluatorzu erstellen.Klicken Sie mit der rechten Maustaste auf die folgende Schaltfläche, und wählen Sie den Link in neuem Fenster öffnen aus, damit sowohl die Entwicklungsumgebung als auch die Dokumentation gleichzeitig verfügbar sind.

Überprüfen Sie auf der Seite Codespace erstellen die Codespace-Konfigurationseinstellungen, und wählen Sie dann Neuen Codespace erstellen aus.
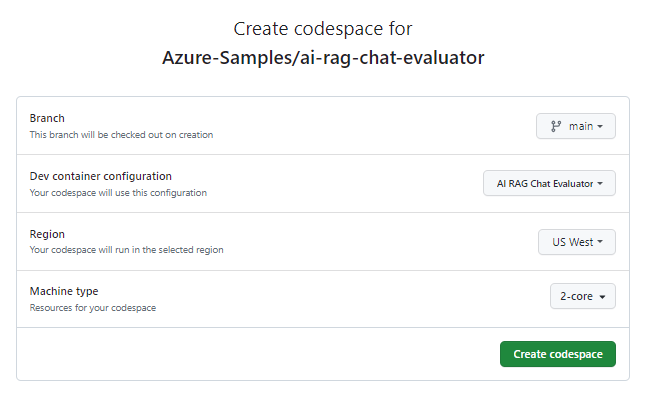
Warten Sie den Start des Codespaces ab. Dieser Startvorgang kann einige Minuten dauern.
Melden Sie sich am unteren Bildschirmrand am Terminal mit der Azure Developer CLI bei Azure an.
azd auth login --use-device-codeKopieren Sie den Code vom Terminal und fügen Sie ihn dann in einen Browser ein. Befolgen Sie die Anweisungen zum Authentifizieren mit Ihrem Azure-Konto.
Stellen Sie die erforderliche Azure-Ressource, Azure OpenAI, für die Evaluierungs-App bereit.
azd upDies
AZD commandstellt die Evaluierungs-App nicht bereit, erstellt aber die Azure OpenAI-Ressource mit einer erforderlichenGPT-4-Bereitstellung, um die Evaluierungen in der lokalen Entwicklungsumgebung auszuführen.Die verbleibenden Aufgaben in diesem Artikel finden im Kontext dieses Entwicklungscontainers statt.
Der Name des GitHub-Repositorys wird in der Suchleiste angezeigt. Mit diesem visuellen Indikator können Sie die Evaluierungs-App von der Chat-App unterscheiden. Dieses
ai-rag-chat-evaluatorRepository wird in diesem Artikel als Evaluierungs-App bezeichnet.

Vorbereiten von Umgebungswerten und Konfigurationsinformationen
Aktualisieren Sie die Umgebungswerte und Konfigurationsinformationen mit den Informationen, die Sie während der Voraussetzungen für die Evaluierungs-App erfasst haben.
Erstellen einer
.envDatei basierend auf.env.sample:cp .env.sample .envFühren Sie diese Befehle aus, um die erforderlichen Werte für
AZURE_OPENAI_EVAL_DEPLOYMENTundAZURE_OPENAI_SERVICEaus der bereitgestellten Ressourcengruppe abzurufen und diese Werte in die.envDatei einzufügen:azd env get-value AZURE_OPENAI_EVAL_DEPLOYMENT azd env get-value AZURE_OPENAI_SERVICEFügen Sie die folgenden Werte aus der Chat-App für ihre Azure KI-Suche-Instanz zum Abschnitt
.envVoraussetzungen hinzu, die Sie im Abschnitt „Voraussetzungen“ erfasst haben.AZURE_SEARCH_SERVICE="<service-name>" AZURE_SEARCH_INDEX="<index-name>"
Verwenden des Microsoft AI-Chat-Protokolls für Konfigurationsinformationen
Die Chat-App und die Evaluierungs-App implementieren beide Microsoft AI Chat Protocol specification, einen sprachagnostischen Open-Source- und Cloud-KI-Endpunkt-API-Vertrag für Nutzung und Evaluierung. Wenn Ihre Client- und Endpunkte auf mittlerer Ebene dieser API-Spezifikation entsprechen, können Sie Evaluierungen auf Ihren KI-Back-Ends konsistent nutzen und ausführen.
Erstellen Sie eine neue Datei mit dem Namen
my_config.json, und kopieren Sie die folgenden Inhalte in diese Datei:{ "testdata_path": "my_input/qa.jsonl", "results_dir": "my_results/experiment<TIMESTAMP>", "target_url": "http://localhost:50505/chat", "target_parameters": { "overrides": { "top": 3, "temperature": 0.3, "retrieval_mode": "hybrid", "semantic_ranker": false, "prompt_template": "<READFILE>my_input/prompt_refined.txt", "seed": 1 } } }Das Evaluierungsskript erstellt den
my_results-Ordner.Das
overrides-Objekt enthält alle Konfigurationseinstellungen, die für die Anwendung erforderlich sind. Jede Anwendung definiert einen eigenen Satz von Einstellungseigenschaften.Verwenden Sie die folgende Tabelle, um die Bedeutung der Einstellungseigenschaften zu verstehen, die an die Chat-App gesendet werden:
Settings-Eigenschaft Beschreibung semantic_ranker Gibt an, ob semantischer Rangfolger verwendet werden soll, ein Modell, das Suchergebnisse basierend auf der semantischen Ähnlichkeit mit der Abfrage des Benutzers rerankt. Wir deaktivieren es für dieses Lernprogramm, um Kosten zu senken. retrieval_mode Der zu verwendende Abrufmodus. Der Standardwert ist hybrid.Temperatur Die Temperatureinstellung für das Modell. Der Standardwert ist 0.3.Oben Die Anzahl der zurückzugebenden Suchergebnisse. Der Standardwert ist 3.prompt_template Eine Außerkraftsetzung der Eingabeaufforderung, die verwendet wird, um die Antwort basierend auf der Frage und den Suchergebnissen zu generieren. seed Der Startwert für alle Aufrufe von GPT-Modellen. Das Festlegen eines Startwerts führt zu konsistenteren Ergebnissen in allen Auswertungen. Ändern Sie den
target_urlURI-Wert Ihrer Chat-App, den Sie im Abschnitt Voraussetzungen erfasst haben. Die Chat-App muss dem Chatprotokoll entsprechen. Der URI weist das folgende Format aufhttps://CHAT-APP-URL/chat. Stellen Sie sicher, dass das Protokoll und diechat-Route Teil des URI sind.
Generieren von Beispieldaten
Um neue Antworten auszuwerten, müssen sie mit einer „Ground Truth“-Antwort verglichen werden, d.h. der idealen Antwort für eine bestimmte Frage. Generieren Sie Fragen und Antworten aus Dokumenten, die in Azure KI-Suche für die Chat-App gespeichert sind.
Kopieren Sie den
example_inputOrdner in einen neuen Ordner mit dem Namenmy_input.Führen Sie in einer Befehlszeile den folgenden Befehl aus, um die Beispieldaten zu generieren:
python -m evaltools generate --output=my_input/qa.jsonl --persource=2 --numquestions=14
Die Frage-/Antwort-Paare werden als Eingabe für den im nächsten Schritt verwendeten Evaluator generiert und im my_input/qa.jsonl JSONL-Format gespeichert. Bei einer Evaluierung in der Produktion würden Sie mehr Frage/Antwort-Paare generieren, nicht nur die 200 wie für dieses Dataset.
Hinweis
Die geringe Anzahl der Fragen und Antworten pro Quelle sollen Ihnen ermöglichen, dieses Verfahren schnell abzuschließen. Dies ist nicht als Produktionsevaluierung gedacht, die mehr Fragen und Antworten pro Quelle verwenden sollte.
Ausführen der ersten Evaluierung mit einer optimierten Eingabeaufforderung
Bearbeiten Sie die Eigenschaften der
my_config.json-Konfigurationsdatei:Eigenschaft Neuer Wert results_dir my_results/experiment_refinedprompt_template <READFILE>my_input/prompt_refined.txtDie optimierte Eingabeaufforderung ist spezifisch für das jeweilige Thema.
If there isn't enough information below, say you don't know. Do not generate answers that don't use the sources below. If asking a clarifying question to the user would help, ask the question. Use clear and concise language and write in a confident yet friendly tone. In your answers ensure the employee understands how your response connects to the information in the sources and include all citations necessary to help the employee validate the answer provided. For tabular information return it as an html table. Do not return markdown format. If the question is not in English, answer in the language used in the question. Each source has a name followed by colon and the actual information, always include the source name for each fact you use in the response. Use square brackets to reference the source, e.g. [info1.txt]. Don't combine sources, list each source separately, e.g. [info1.txt][info2.pdf].Führen Sie in eine Befehlseingabe den folgenden Befehl aus, um die Evaluierung auszuführen:
python -m evaltools evaluate --config=my_config.json --numquestions=14Dieses Skript hat mit der Evaluierung einen neuen Experimentordner in
my_results/erstellt. Der Ordner enthält die Ergebnisse der Evaluierung, einschließlich:Dateiname Beschreibung config.jsonEine Kopie der konfigurationsdatei, die für die Auswertung verwendet wird. evaluate_parameters.jsonDie parameter, die für die Auswertung verwendet werden. Sehr ähnlich wie config.jsonbei zusätzlichen Metadaten wie Zeitstempel.eval_results.jsonlJede Frage und Antwort, zusammen mit den GPT-Metriken für jedes Frage/Antwort-Paar. summary.jsonDie Gesamtergebnisse, z. B. die durchschnittlichen GPT-Metriken.
Ausführen der zweiten Evaluierung mit schwacher Eingabeaufforderung
Bearbeiten Sie die Eigenschaften der
my_config.json-Konfigurationsdatei:Eigenschaft Neuer Wert results_dir my_results/experiment_weakprompt_template <READFILE>my_input/prompt_weak.txtDiese schwache Eingabeaufforderung hat keinen Kontext im Zusammenhang mit dem Thema:
You are a helpful assistant.Führen Sie in eine Befehlseingabe den folgenden Befehl aus, um die Evaluierung auszuführen:
python -m evaltools evaluate --config=my_config.json --numquestions=14
Ausführen der dritten Evaluierung mit einer bestimmten Temperatur
Verwenden Sie eine Eingabeaufforderung, die mehr Kreativität ermöglicht.
Bearbeiten Sie die Eigenschaften der
my_config.json-Konfigurationsdatei:Vorhanden Eigenschaft Neuer Wert Vorhanden results_dir my_results/experiment_ignoresources_temp09Vorhanden prompt_template <READFILE>my_input/prompt_ignoresources.txtNeue Temperatur 0.9Der Standard
temperatureist „0.7“. Je höher die Temperatur, umso kreativer die Antworten.Die Eingabeaufforderung
ignoreist kurz:Your job is to answer questions to the best of your ability. You will be given sources but you should IGNORE them. Be creative!Das Konfigurationsobjekt sollte wie folgt aussehen, mit der Ausnahme, dass
results_dirdurch Ihren Pfad ersetzt wurden:{ "testdata_path": "my_input/qa.jsonl", "results_dir": "my_results/prompt_ignoresources_temp09", "target_url": "https://YOUR-CHAT-APP/chat", "target_parameters": { "overrides": { "temperature": 0.9, "semantic_ranker": false, "prompt_template": "<READFILE>my_input/prompt_ignoresources.txt" } } }Führen Sie in eine Befehlseingabe den folgenden Befehl aus, um die Evaluierung auszuführen:
python -m evaltools evaluate --config=my_config.json --numquestions=14
Überprüfen der Auswertungsergebnisse
Sie haben drei Evaluierungen basierend auf unterschiedlichen Eingabeaufforderungen und App-Einstellungen durchgeführt. Die Ergebnisse werden in dem Ordner my_results gespeichert. Überprüfen Sie, wie sich die Ergebnisse je nach den Einstellungen unterscheiden.
Verwenden Sie das Überprüfungstool , um die Ergebnisse der Evaluierungen anzuzeigen:
python -m evaltools summary my_resultsDie Ergebnisse sehen etwa so aus:

Jeder Wert wird als Zahl und Prozentsatz ausgegeben.
Verwenden Sie die folgende Tabelle, um die Bedeutung der Werte zu verstehen.
Wert Beschreibung Quellenübereinstimmung Dies bezieht sich darauf, wie gut die Antworten des Modells auf faktenbezogenen und überprüfbaren Informationen basieren. Eine Antwort wird als gut fundiert betrachtet, wenn sie sachlich korrekt ist und die Realität widerspiegelt. Relevance Dies ist ein Maß dafür, wie genau die Antworten des Modells mit dem Kontext oder der Eingabeaufforderung übereinstimmen. Eine relevante Antwort passt direkt zur Frage oder Anweisung des Benutzers. Kohärenz Dies bezieht sich darauf, wie logisch konsistent die Antworten des Modells sind. Eine kohärente Antwort wahrt einen logischen Fluss und widerspricht sich nicht selbst. Quellenangaben Dies gibt an, ob die Antwort im in der Eingabeaufforderung angeforderten Format zurückgegeben wurde. Length Dies misst die Länge der Antwort. Die Ergebnisse sollten darauf hinweisen, dass alle drei Evaluierungen eine hohe Relevanz hatten, während die
experiment_ignoresources_temp09die niedrigste Relevanz hatte.Wählen Sie den Ordner aus, um die Konfiguration für die Evaluierung anzuzeigen.
Betätigen Sie Strg + C, um die App zu beenden.
Vergleichen der Antworten
Vergleichen Sie die zurückgegebenen Antworten aus den Evaluierungen.
Wählen Sie zwei der zu vergleichenden Evaluierungen aus, und verwenden Sie dann dasselbe Überprüfungstool, um die Antworten zu vergleichen:
python -m evaltools diff my_results/experiment_refined my_results/experiment_ignoresources_temp09Überprüfen Sie die Ergebnisse. Ihre Ergebnisse können variieren.

Betätigen Sie Strg + C, um die App zu beenden.
Vorschläge für weitere Evaluierungen
- Bearbeiten Sie die Eingabeaufforderungen in
my_input, um die Antworten nach Themenbereich, Länge und anderen Faktoren anzupassen. - Bearbeiten Sie die
my_config.json-Datei, um die Parameter wietemperatureundsemantic_rankerzu ändern, und führen Sie die Experimente erneut aus. - Vergleichen Sie verschiedene Antworten, um zu verstehen, wie sich Eingabeaufforderung und Frage auf die Antwortqualität auswirken.
- Generieren Sie für jedes Dokument im Azure KI-Suche-Index eine separate Gruppe von Fragen und Ground Truth-Antworten. Führen Sie dann die Evaluierungen erneut aus, um zu sehen, wie sich die Antworten unterscheiden.
- Ändern Sie die Eingabeaufforderungen, um kürzere oder längere Antworten anzugeben, indem Sie die Anforderung am Ende der Eingabeaufforderung hinzufügen. Beispiel:
Please answer in about 3 sentences..
Bereinigen von Ressourcen und Abhängigkeiten
Bereinigen von Azure-Ressourcen
Die in diesem Artikel erstellten Azure-Ressourcen werden Ihrem Azure-Abonnement in Rechnung gestellt. Wenn Sie nicht erwarten, dass diese Ressourcen in Zukunft benötigt werden, löschen Sie sie, um weitere Gebühren zu vermeiden.
Führen Sie den folgenden Azure Developer CLI-Befehl aus, um die Azure-Ressourcen zu löschen und den Quellcode zu entfernen:
azd down --purge
Bereinigen von GitHub-Codespaces
Durch das Löschen der GitHub Codespaces-Umgebung wird sichergestellt, dass Sie die Anzahl der kostenlosen Berechtigungsstunden pro Kern maximieren können, die Sie für Ihr Konto erhalten.
Wichtig
Weitere Informationen zu den Berechtigungen Ihres GitHub-Kontos finden Sie im Artikel zu monatlich enthaltener Speicherkapazität und Kernstunden in GitHub Codespaces.
Melden Sie sich beim GitHub Codespaces-Dashboard (https://github.com/codespaces) an.
Suchen Sie Ihre derzeit ausgeführten Codespaces, die aus dem GitHub-Repository
Azure-Samples/ai-rag-chat-evaluatorstammen.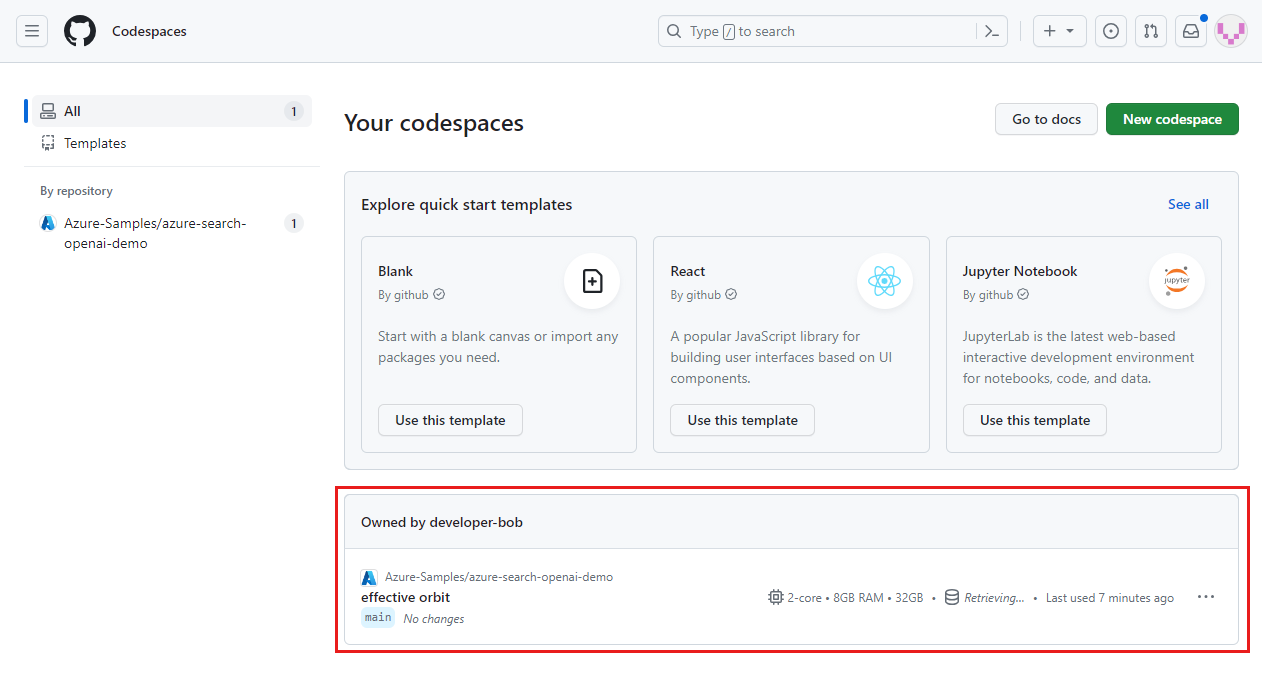
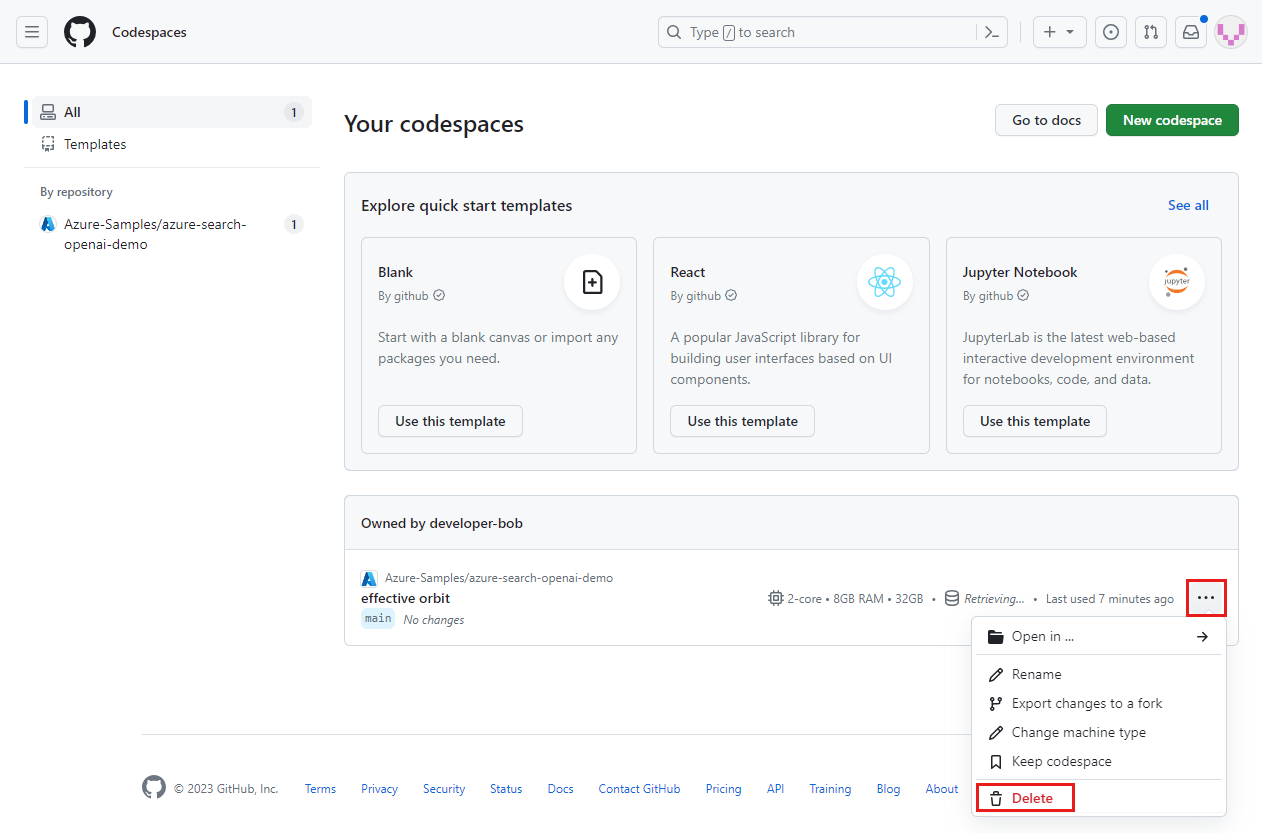
Öffnen Sie das Kontextmenü für den Codespace, und wählen Sie dann Löschen aus.
Kehren Sie zum Artikel zur Chat-App zurück, um diese Ressourcen zu bereinigen.
Nächste Schritte
- Evaluierungsrepository
- GitHub-Repository für Unternehmenschat-Apps
- Erstellen einer Chat-App mit Azure OpenAI Best Practice-Lösungsarchitektur
- Zugriffssteuerung in generativen KI-Apps mit Azure KI-Suche
- Erstellen einer unternehmensbereiten OpenAI-Lösung mit Azure API Management
- Übertreffen der Vektorsuche mit hybridem Abruf und Rangfolgefähigkeiten