LLMOps-Workflows in Azure Databricks
Dieser Artikel ergänzt MLOps-Workflows in Databricks durch spezifische Informationen zu LLMOps-Workflows. Weitere Details finden Sie im The Big Book of MLOps.
Wie ändert sich der MLOps-Workflow bei LLMs?
LLMs sind eine Klasse von NLP-Modellen (Natural Language Processing, Verarbeitung natürlicher Sprache), die ihre Vorgänger in Größe und Leistung in einer Vielzahl von Aufgaben deutlich überholt haben, z. B. bei Fragen und Antworten ohne Limit, Zusammenfassungen und der Ausführung von Anweisungen.
Die Entwicklung und Bewertung von LLMs unterscheidet sich bei einigen wichtigen Faktoren von herkömmlichen ML-Modellen. In diesem Abschnitt werden einige der wichtigsten Eigenschaften von LLMs und die Auswirkungen auf MLOps kurz zusammengefasst.
| Wichtige Eigenschaften von LLMs | Auswirkungen auf MLOps |
|---|---|
| LLMs sind in vielen Formen verfügbar. – Allgemeine proprietäre und OSS-Modelle, auf die mit kostenpflichtigen APIs zugegriffen wird. – Einsatzbereite Open-Source-Modelle für universelle bis sehr spezielle Anwendungen. – Benutzerdefinierte Modelle, die für bestimmte Anwendungen optimiert wurden. – Benutzerdefinierte vortrainierte Anwendungen. |
Entwicklungsprozess: Projekte werden häufig inkrementell entwickelt, beginnend mit vorhandenen Drittanbieter- oder Open-Source-Modellen bis zu benutzerdefinierten, fein abgestimmten Modellen. |
| Viele LLMs verwenden allgemeine Fragen und Anweisungen in natürlicher Sprache als Eingabe. Diese Abfragen können sorgfältig entwickelte Prompts enthalten, um die gewünschten Antworten zu erhalten. | Entwicklungsprozess: Das Entwerfen von Textvorlagen für die Abfrage von LLMs ist häufig ein wichtiger Bestandteil der Entwicklung neuer LLM-Pipelines. Packen von ML-Artefakten: Viele LLM-Pipelines verwenden vorhandene LLMs oder LLM-Dienstendpunkte. Die ML-Logik, die für diese Pipelines entwickelt wurde, ist möglicherweise auf Promptvorlagen, Agents oder Ketten ausgerichtet und nicht auf das Modell selbst. Die gepackten und in die Produktion heraufgestuften ML-Artefakte können diese Pipelines anstelle von Modellen sein. |
| Viele LLMs können Prompts mit Beispielen, Kontext oder anderen Informationen nutzen, um eine Frage zu beantworten. | Bereitstellungsinfrastruktur: Beim Erweitern von LLM-Abfragen mit Kontext können Sie zusätzliche Tools wie Vektordatenbanken verwenden, um nach relevanten Kontexten zu suchen. |
| Drittanbieter-APIs stellen proprietäre und Open-Source-Modelle bereit. | API-Governance: Die Verwendung einer zentralen API-Governance bietet die Möglichkeit, einfach zwischen API-Anbietern zu wechseln. |
| LLMs sind sehr große Deep Learning-Modelle, die oft Größen von einigen Gigabyte bis zu Hunderten von Gigabyte erreichen. | Bereitstellungsinfrastruktur: LLMs erfordern möglicherweise GPUs für die Bereitstellung von Echtzeitmodellen und schnellen Speicher für Modelle, die dynamisch geladen werden müssen. Kosten-Leistungs-Kompromisse: Da größere Modelle mehr Berechnungen erfordern und teurer in der Unterhaltung sind, können Techniken zum Verringern der Modellgröße und des Berechnungsaufwands erforderlich sein. |
| LLMs sind mit herkömmlichen ML-Metriken schwierig zu bewerten, da es häufig keine einzige „richtige“ Antwort gibt. | Menschliches Feedback: Feedback durch Personen ist für die Auswertung und Prüfung von LLMs unerlässlich. Sie sollten Benutzerfeedback direkt in den MLOps-Prozess integrieren, und dabei Tests, Überwachung und zukünftige Optimierungen einbeziehen. |
Gemeinsamkeiten zwischen MLOps und LLMOps
Viele Aspekte von MLOps-Prozessen ändern sich bei LLMs nicht. Die folgenden Richtlinien gelten beispielsweise auch für LLMs:
- Verwenden Sie separate Umgebungen für Entwicklung, Staging und Produktion.
- Verwenden Sie Git für die Versionskontrolle.
- Verwalten Sie die Modellentwicklung mit MLflow, und verwenden Sie Modelle in Unity Catalog, um den Modelllebenszyklus zu verwalten.
- Speichern Sie Daten in einer Lakehouse-Architektur mithilfe von Deltatabellen.
- Ihre vorhandene CI/CD-Infrastruktur sollte keine Änderungen erfordern.
- Die modulare Struktur von MLOps bleibt gleich, mit Pipelines für Featurisierung, Modelltraining, Modellinferenz usw.
Referenzarchitekturdiagramme
In diesem Abschnitt werden zwei LLM-basierte Anwendungen verwendet, um einige der Anpassungen an der Referenzarchitektur für herkömmliches MLOps zu veranschaulichen. Die Diagramme zeigen die Produktionsarchitektur für 1) eine RAG-Anwendung (Retrieval-Augmented Generation) mit einer Drittanbieter-API und 2) eine RAG-Anwendung mit einem selbst gehosteten, optimierten Modell. Beide Diagramme zeigen eine optionale Vektordatenbank, die durch eine direkte Abfrage des LLM über den Model Serving-Endpunkt ersetzt werden kann.
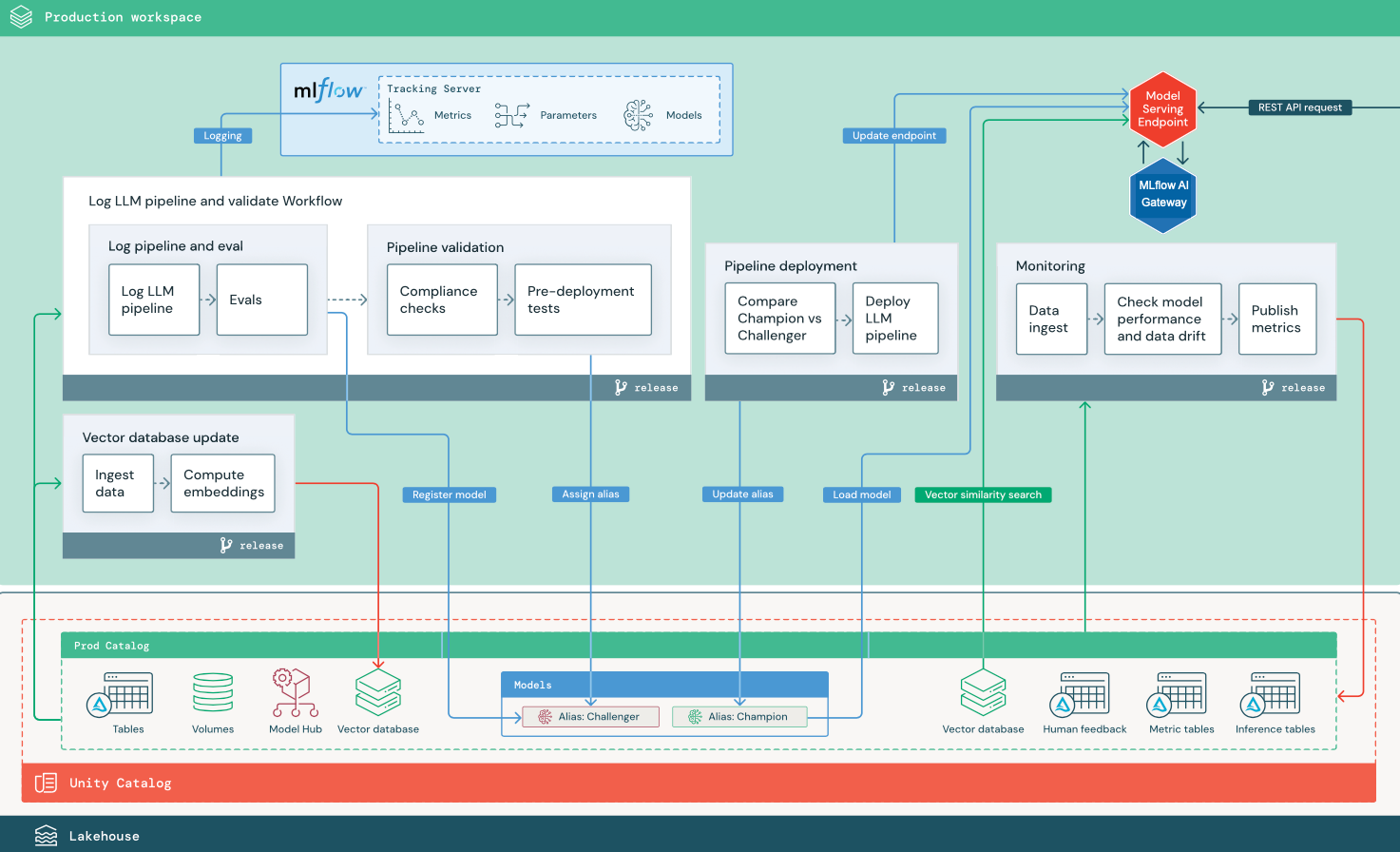
RAG mit einer LLM-API eines Drittanbieters
Das Diagramm zeigt eine Produktionsarchitektur für eine RAG-Anwendung, die mithilfe externer Databricks-Modelle eine Verbindung mit einer LLM-API eines Drittanbieters herstellt.
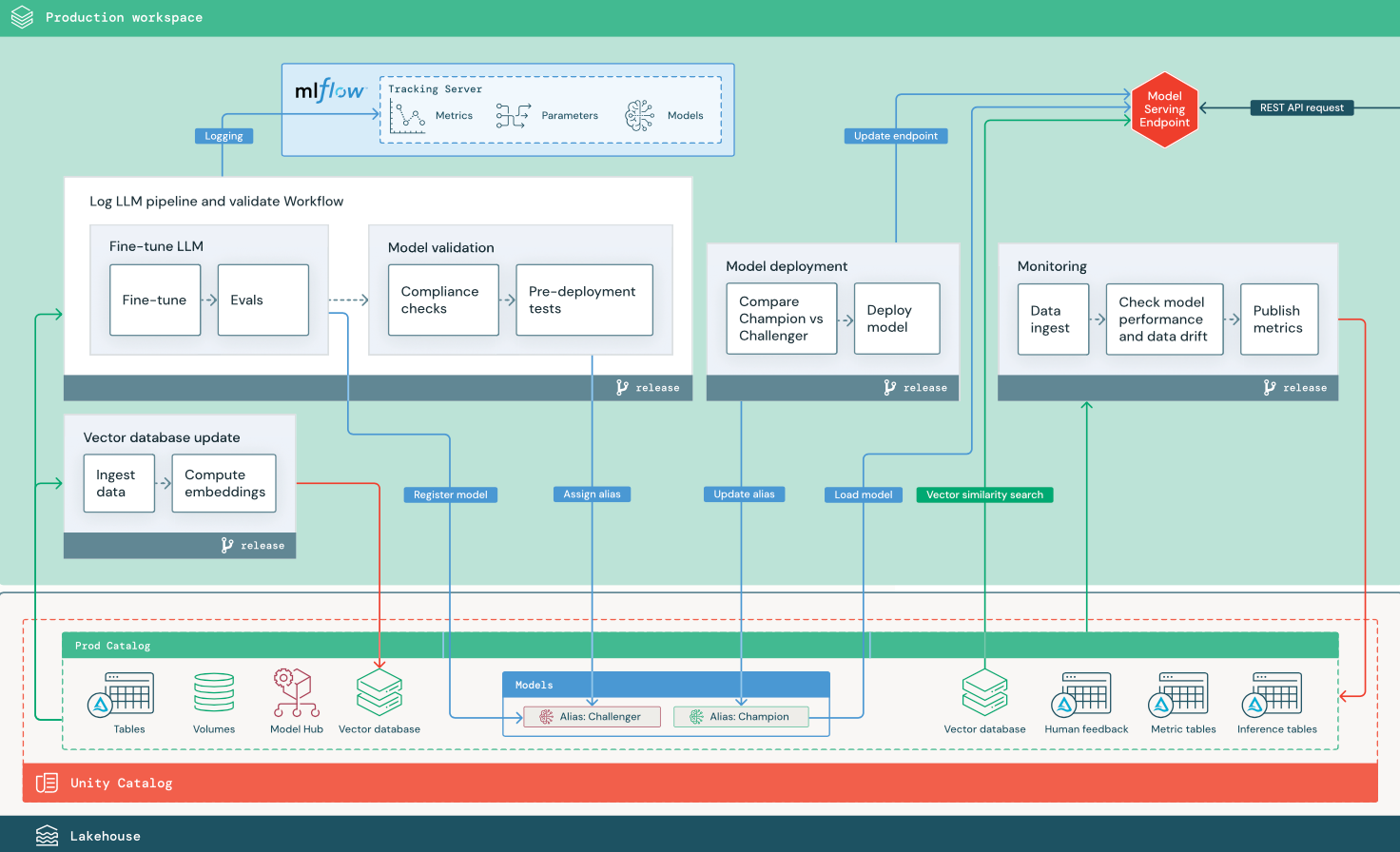
RAG mit einem optimierten Open-Source-Modell
Das Diagramm zeigt eine Produktionsarchitektur für eine RAG-Anwendung, die ein Open-Source-Modell optimiert.
LLMOps-Änderungen an der MLOps-Produktionsarchitektur
In diesem Abschnitt werden die wichtigsten Änderungen an der MLOps-Referenzarchitektur für LLMOps-Anwendungen beschrieben.
Modellhub
LLM-Anwendungen verwenden häufig vorhandene, vortrainierte Modelle, die von einem internen oder externen Modellhub ausgewählt wurden. Das Modell kann unverändert verwendet oder optimiert werden.
Databricks umfasst eine Auswahl an qualitativ hochwertigen, vortrainierten Basismodellen in Unity Catalog und im Databricks Marketplace. Mit diesen vortrainierten Modellen haben Sie Zugriff auf modernste KI-Funktionen und können so Zeit und Kosten für die Erstellung eigener benutzerdefinierter Modelle sparen. Weitere Einzelheiten finden Sie unter Vortrainierte Modelle in Unity Catalog und Marketplace.
Vektordatenbank
Einige LLM-Anwendungen verwenden Vektordatenbanken für schnelle Ähnlichkeitssuchen, um z. B. Kontext oder Fachwissen zu LLM-Abfragen bereitzustellen. Databricks bietet eine integrierte Vektorsuchfunktion, mit der Sie eine beliebige Delta-Tabelle in Unity Catalog als Vektordatenbank verwenden können. Der Vektorsuchindex wird automatisch mit der Delta-Tabelle synchronisiert. Weitere Einzelheiten finden Sie unter Vektorsuche.
Sie können ein Modellartefakt erstellen, das die Logik zum Abrufen von Informationen aus einer Vektordatenbank kapselt und die zurückgegebenen Daten als Kontext für das LLM bereitstellt. Anschließend können Sie das Modell mit den Optionen MLflow-LangChain oder PyFunc protokollieren.
Optimieren von LLMs
Da eine Neuerstellung von LLMs teuer und zeitaufwendig ist, optimieren LLM-Anwendungen häufig ein vorhandenes Modell, um die Leistung für ein bestimmtes Szenario zu verbessern. In der Referenzarchitektur werden Optimierungen und Modellimplementierungen als unterschiedliche Databricks-Aufträge dargestellt. Die Überprüfung eines optimierten Modells vor der Bereitstellung erfolgt häufig manuell.
Databricks bietet Foundation Model Fine-Tuning, mit dem Sie Ihre eigenen Daten verwenden können, um eine vorhandene LLM anzupassen, um ihre Leistung für Ihre spezifische Anwendung zu optimieren. Ausführliche Informationen finden Sie unter Foundation Model Fine-Tuning.
Modellbereitstellung
In einem Szenario mit RAG mithilfe einer Drittanbieter-API besteht eine wichtige Architekturänderung darin, dass die LLM-Pipeline externe API-Aufrufe vom Model Serving-Endpunkt über interne oder Drittanbieter-LLM-APIs durchführt. Dies erhöht die Komplexität und potenziell auch die Latenz und verursacht einem Mehraufwand bei der Verwaltung von Anmeldeinformationen.
Databricks bietet Mosaik AI Model Serving, das eine einheitliche Schnittstelle zum Bereitstellen, Steuern und Abfragen von KI-Modellen bietet. Weitere Einzelheiten finden Sie unter Mosaik AI Model Serving.
Menschliches Feedback zur Überwachung und Bewertung
Regelmäßiges menschliches Feedback ist bei den meisten LLM-Anwendungen unerlässlich. Menschliches Feedback sollte wie andere Daten verwaltet und idealerweise per Streaming in Quasi-Echtzeit in die Überwachung integriert werden.
Die Überprüfungs-App des Mosaik AI Agent Frameworks hilft Ihnen, Feedback von menschlichen Reviewern zu sammeln. Weitere Informationen finden Sie unter Einholen von Feedback zur Qualität einer Agent-Anwendung.