Grundlagen von RAG (Retrieval Augmented Generation)
In diesem Abschnitt werden die wichtigsten Komponenten und Prinzipien der Entwicklung von RAG-Anwendungen für unstrukturierte Daten vorgestellt.
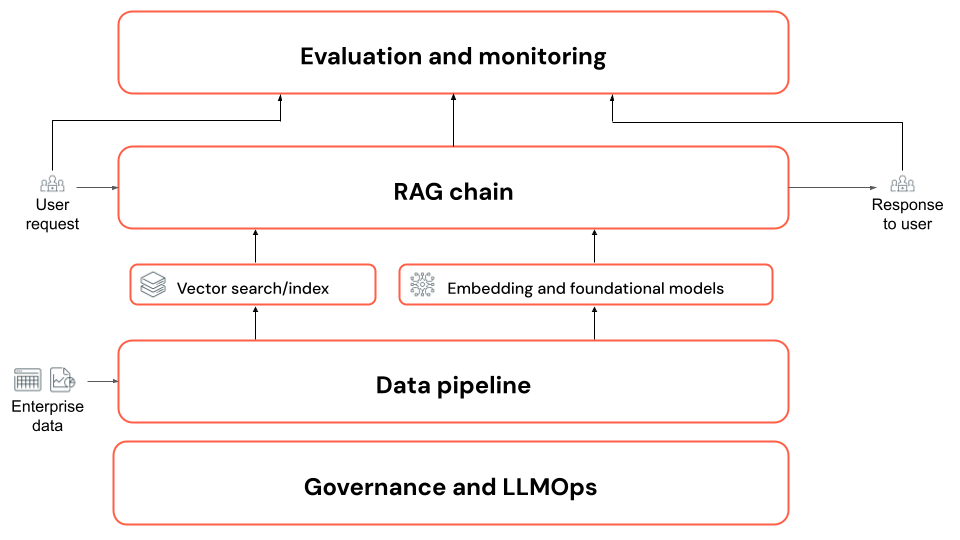
Dies gilt insbesondere für:
- Datenpipeline: Transformieren unstrukturierter Dokumente, z. B. Sammlungen von PDF-Dateien, in ein Format, das zum Abrufen mithilfe der Datenpipeline der RAG-Anwendung geeignet ist
- Abrufen, Erweitern und Generieren (RAG-Kette): Eine Reihe (oder Kette) von Schritten wird zu folgenden Zwecken aufgerufen:
- Verstehen der Frage des Benutzers
- Abrufen der unterstützenden Daten
- Aufrufen eines LLM, um eine Antwort basierend auf der Frage des Benutzers und der unterstützenden Daten zu generieren
- Auswertung: Bewerten der RAG-Anwendung, um Qualität, Kosten und Wartezeit zu ermitteln und sicherzustellen, dass sie Ihren geschäftlichen Anforderungen entspricht
- Governance und LLMOps: Nachverfolgen und Verwalten des Lebenszyklus jeder Komponente, einschließlich Datenherkunft und Governance (Zugriffskontrollen).