Beschreibung und Verarbeitungsschritte der RAG-Datenpipeline
In diesem Artikel erfahren Sie, wie Sie unstrukturierte Daten für die Verwendung in RAG-Anwendungen vorbereiten. Der Begriff „unstrukturierte Daten“ bezieht sich auf Daten ohne eine bestimmte Struktur oder Organisation, z. B. PDF-Dokumente, die Text und Bilder enthalten können, oder Multimediainhalte wie Audio- oder Videodateien.
Unstrukturierte Daten verfügen nicht über ein vordefiniertes Datenmodell oder -schema, sodass es nicht möglich ist, sie nur anhand von Struktur und Metadaten abzufragen. Daher sind für unstrukturierte Daten Techniken erforderlich, die die semantische Bedeutung von Rohtext, Bildern, Audiodaten oder anderen Inhalten verstehen und daraus extrahieren können.
Während der Datenaufbereitung übernimmt die Datenpipeline der RAG-Anwendung unstrukturierte Rohdaten und transformiert sie in einzelne Blöcke, die basierend auf ihrer Relevanz für die Abfrage eines Benutzers abgefragt werden können. Die wichtigsten Schritte in der Datenvorverarbeitung sind unten beschrieben. Jeder Schritt verfügt über eine Vielzahl von Optionen, die optimiert werden können. Eine ausführlichere Erläuterung diese Optionen finden Sie unter Verbessern der RAG-Anwendungsqualität.
Vorbereiten unstrukturierter Daten für den Abruf
Im restlichen Teil dieses Abschnitts wird der Prozess zur Vorbereitung unstrukturierter Daten für den Abruf mithilfe der semantischen Suche beschrieben. Die semantische Suche versteht die kontextbezogene Bedeutung und Absicht einer Benutzerabfrage, um relevantere Suchergebnisse bereitzustellen.
Die semantische Suche ist einer von mehreren Ansätzen, die bei der Implementierung der Abrufkomponente einer RAG-Anwendung für unstrukturierte Daten verwendet werden können. Diese Dokumente decken alternative Abrufstrategien im Abschnitt für Abrufoptionen ab.
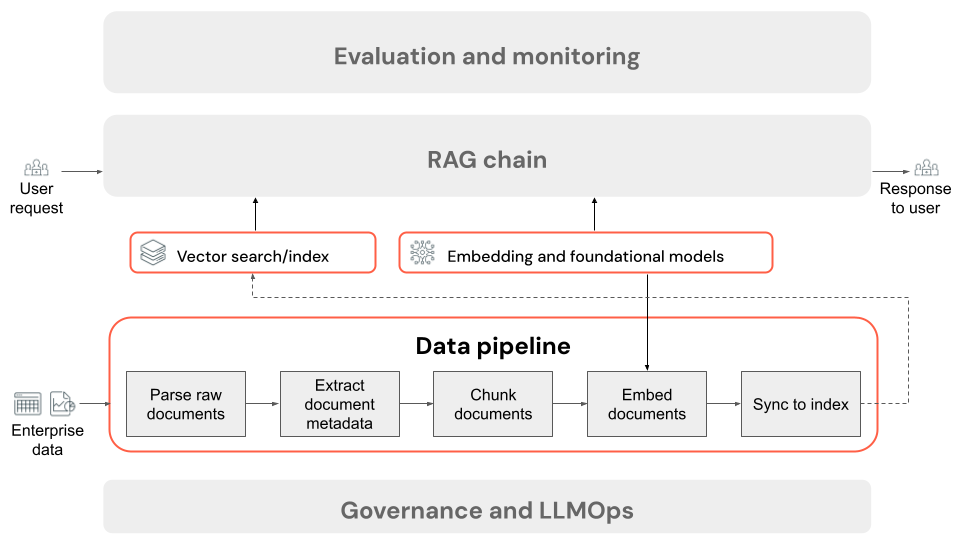
Schritte der Datenpipeline einer RAG-Anwendung
Im Folgenden sind die typischen Schritte einer Datenpipeline in einer RAG-Anwendung mit unstrukturierten Daten aufgeführt:
- Analysieren der Rohdokumente: Der erste Schritt umfasst das Transformieren von Rohdaten in ein verwendbares Format. Dies kann das Extrahieren von Text, Tabellen und Bildern aus einer Sammlung von PDF-Dateien oder die Verwendung von Techniken zur optischen Zeichenerkennung (Optical Character Recognition, OCR) beinhalten, um Text aus Bildern zu extrahieren.
- Extrahieren von Dokumentmetadaten (optional): In einigen Fällen kann das Extrahieren und Verwenden von Dokumentmetadaten wie Dokumenttiteln, Seitenzahlen, URLs oder anderen Informationen dazu beitragen, dass im Abrufschritt die richtigen Daten genauer abgefragt werden.
- Aufteilen von Dokumenten in Blöcke: Um sicherzustellen, dass die geparsten Dokumente in das Einbettungsmodell und das Kontextfenster des LLM passen, werden die geparsten Dokumente in kleinere, einzelne Blöcke unterteilt. Durch das Abrufen dieser fokussierten Blöcke statt vollständiger Dokumente erhält das LLM gezielteren Kontext zum Generieren von Antworten.
- Einbetten von Blöcken: In einer RAG-Anwendung, die die semantische Suche verwendet, transformiert ein spezieller Sprachmodelltyp, der als Einbettungsmodell bezeichnet wird, die einzelnen Blöcke aus dem vorherigen Schritt in numerische Vektoren oder Zahlenlisten, die die Bedeutung der einzelnen Inhaltselemente kapseln. Wichtig: Diese Vektoren stellen die semantische Bedeutung des Texts dar, nicht nur Schlüsselwörter auf Oberflächenebene. Dies ermöglicht die Suche auf der Grundlage der Bedeutung anstelle von wörtlichen Textübereinstimmungen.
- Indexblöcke in einer Vektordatenbank: Der letzte Schritt besteht darin, die Vektordarstellungen der Blöcke zusammen mit dem Text des Blocks in eine Vektordatenbank zu laden. Eine Vektordatenbank ist ein spezieller Datenbanktyp, der zum effizienten Speichern von und Suchen nach Vektordaten wie Einbettungen entwickelt wurde. Um die Leistung bei einer großen Anzahl von Blöcken aufrechtzuerhalten, enthalten Vektordatenbanken häufig einen Vektorindex, der verschiedene Algorithmen verwendet, um die Vektoreinbettungen so zu organisieren und zuzuordnen, dass die Sucheffizienz optimiert wird. Zur Abfragezeit wird die Anforderung eines Benutzers in einen Vektor eingebettet, und die Datenbank nutzt den Vektorindex, um die ähnlichsten Blockvektoren zu finden. Dabei werden die entsprechenden ursprünglichen Textblöcke zurückgegeben.
Der Prozess zum Berechnen von Ähnlichkeiten kann rechenintensiv sein. Vektorindizes wie die Databricks-Vektorsuche beschleunigen diesen Prozess, indem ein Mechanismus zum effizienten Organisieren von und Navigieren in Einbettungen bereitgestellt wird, häufig über komplexe Annäherungsmethoden. Dies ermöglicht die schnelle Bewertung der relevantesten Ergebnisse, ohne jede Einbettung einzeln mit der Abfrage des Benutzers zu vergleichen.
Jeder Schritt in der Datenpipeline umfasst technische Entscheidungen, die sich auf die Qualität der RAG-Anwendung auswirken. Wenn Sie z. B. die richtige Blockgröße in Schritt 3 auswählen, wird sichergestellt, dass das LLM spezifische, aber kontextbezogene Informationen erhält, während beim Auswählen eines geeigneten Einbettungsmodells in Schritt 4 die Genauigkeit der während des Abrufs zurückgegebenen Blöcke bestimmt wird.
Dieser Datenaufbereitungsvorgang wird als Offlinedatenaufbereitung bezeichnet, da er vor der Systemantwort auf Abfragen erfolgt, im Gegensatz zu den Onlineschritten, die beim Übermitteln einer Abfrage durch einen Benutzer ausgelöst werden.