Einführung in RAG in der KI-Entwicklung
Dieser Artikel ist eine Einführung in die Retrieval Augmented Generation (RAG): worum es sich handelt, die Funktionsweise und wichtige Konzepte.
Was ist Retrieval Augmented Generation?
Bei RAG handelt es sich um eine Technik, mit der ein großes Sprachmodell (LLM) angereicherte Antworten generieren kann, indem ein Benutzerprompt mit unterstützenden Daten aus einer externen Informationsquelle erweitert wird. Durch Einbinden dieser abgerufenen Informationen ermöglicht RAG dem LLM, genauere, qualitativ hochwertige Antworten zu generieren, als wenn der Prompt nicht mit zusätzlichem Kontext erweitert worden wäre.
Angenommen, Sie erstellen einen Frage- und Antwort-Chatbot, um Mitarbeitern beim Beantworten von Fragen zu den proprietären Dokumenten Ihres Unternehmens zu helfen. Ein eigenständiges LLM kann keine genauen Fragen zum Inhalt dieser Dokumente beantworten, wenn es nicht speziell darauf trainiert wurde. Das LLM könnte aufgrund fehlender Informationen keine Antwort liefern oder sogar eine falsche Antwort generieren.
RAG behebt dieses Problem, indem zuerst basierend auf der Abfrage eines Benutzers relevante Informationen aus den Unternehmensdokumenten abgerufen und diese dann dem LLM als zusätzlicher Kontext bereitgestellt werden. Dies ermöglicht es dem LLM, mit den Details aus den relevanten Dokumenten eine genauere Antwort zu generieren. Im Prinzip ermöglicht RAG es dem LLM, die abgerufenen Informationen zu „konsultieren“, um eine Antwort zu formulieren.
Kernkomponenten einer RAG-Anwendung
Eine RAG-Anwendung ist ein Beispiel für ein zusammengesetztes KI-System: Sie erweitert die Sprachfunktionen des Modells, indem sie es mit anderen Tools und Verfahren kombiniert.
Beim Verwenden eines eigenständigen LLM sendet ein Benutzer eine Anforderung, z. B. eine Frage, an das LLM. Dieses reagiert dann mit einer Antwort, die ausschließlich auf seinen Trainingsdaten basiert.
Bei der grundlegendsten RAG-Anwendung laufen die folgenden Schritte ab:
- Retrieval (Abrufen): Die Anforderung des Benutzers wird verwendet, um einige externe Informationsquellen abzufragen. Dazu kann das Abfragen eines Vektorspeichers, das Durchführen einer Stichwortsuche mithilfe von Text oder das Abfragen einer SQL-Datenbank gehören. Das Ziel des Abrufschritts besteht darin, zusätzliche Daten zu erhalten, mit denen das LLM eine nützliche Antwort bereitstellen kann.
- Augmentation (Erweitern): Die abgerufenen Daten werden mit der Anforderung des Benutzers kombiniert, wobei oft eine Vorlage mit zusätzlicher Formatierung und Anweisungen für das LLM verwendet wird, um einen Prompt zu erstellen.
- Generation (Generieren): Der resultierende Prompt wird an das LLM übergeben, und es generiert eine Antwort auf die Anforderung des Benutzers.
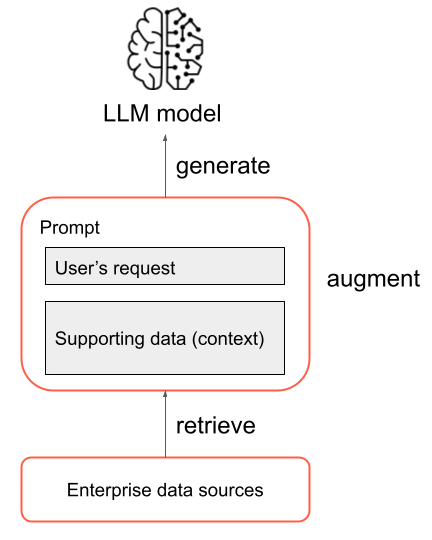
Dies ist eine vereinfachte Übersicht über den RAG-Prozess, aber das Implementieren einer RAG-Anwendung umfasst viele komplexe Aufgaben. Das Vorverarbeiten von Quelldaten für das Verwenden in RAG, das effektive Abrufen von Daten, das Formatieren des erweitertes Prompts und das Auswertender generierten Antworten erfordern sorgfältige Überlegungen und Arbeitsaufwand. Diese Themen werden in nachfolgenden Abschnitten dieses Leitfadens ausführlicher behandelt.
Gründe für die Verwendung von RAG
In der folgenden Tabelle werden die Vorteile von RAG im Vergleich zu einem eigenständigen LLM beschrieben:
| Nur mit einem LLM | Mit LLMs mit RAG |
|---|---|
| Keine proprietären Kenntnisse: LLMs werden in der Regel mit öffentlich verfügbare Daten trainiert, sodass sie Fragen zu internen oder proprietären Daten eines Unternehmens nicht genau beantworten können. | RAG-Anwendungen können proprietäre Daten enthalten: Eine RAG-Anwendung kann proprietäre Dokumente wie Memos, E-Mails und Entwurfsdokumente für ein LLM bereitstellen, sodass es Fragen zu diesen Dokumenten beantworten kann. |
| Wissen wird nicht in Echtzeit aktualisiert: LLMs haben keinen Zugriff auf Informationen zu Ereignissen, die nach ihrem Training stattgefunden haben. Ein eigenständiges LLM kann Ihnen z. B. nichts über Warenbewegungen am heutigen Tag sagen. | RAG-Anwendungen können auf Echtzeitdaten zugreifen: Eine RAG-Anwendung kann dem LLM Informationen aus einer aktualisierten Datenquelle bereitstellen, sodass es nützliche Antworten zu Ereignissen liefern kann, die nach seinem Training stattgefunden haben. |
| Fehlende Zitate: LLMs können beim Antworten keine spezifischen Informationsquellen zitieren, sodass Benutzer nicht überprüfen können, ob die Antwort inhaltlich korrekt ist. | RAG kann Quellen zitieren: Wenn ein LLM als Teil einer RAG-Anwendung verwendet wird, kann es auf Anfrage seine Quellen zitieren. |
| Fehlende Kontrolle über den Datenzugriff (ACLs): LLMs können basierend auf bestimmten Benutzerberechtigungen nicht zuverlässig unterschiedliche Antworten für verschiedene Benutzer bereitstellen. | RAG ermöglicht Datensicherheit/ACLs: Der Abrufschritt kann so konzipiert werden, dass nur die Informationen gefunden werden, auf die der Benutzer zugreifen darf. So kann eine RAG-Anwendung persönliche oder proprietäre Informationen selektiv abrufen. |
Arten von RAG
Die RAG-Architektur kann mit zwei Arten von unterstützenden Daten arbeiten:
| Strukturierte Daten | Unstrukturierte Daten | |
|---|---|---|
| Definition | Tabellendaten, die in Zeilen und Spalten mit einem bestimmten Schema angeordnet sind, z. B. Tabellen in einer Datenbank | Daten ohne eine bestimmte Struktur oder Ordnung, z. B. Dokumente mit Text und Bildern oder Multimediainhalte wie Audio oder Video. |
| Beispieldatenquellen | – Kundendatensätze in einem BI- oder Data Warehouse-System – Transaktionsdaten aus einer SQL-Datenbank – Daten aus Anwendungs-APIs, z. B. SAP, Salesforce usw. |
– Kundendatensätze in einem BI- oder Data Warehouse-System – Transaktionsdaten aus einer SQL-Datenbank – Daten aus Anwendungs-APIs, z. B. SAP, Salesforce usw. – PDFs – Google- oder Microsoft Office-Dokumente – Wikis – Bilder – Videos |
Ihre Datenauswahl für RAG hängt von Ihrem Anwendungsfall ab. Im Rest des Cookbooks liegt der Fokus auf RAG für unstrukturierte Daten.