So überwachen Sie die Qualität Ihres Agenten beim Produktionsdatenverkehr
Wichtig
Dieses Feature befindet sich in der Public Preview.
In diesem Artikel wird beschrieben, wie Sie die Qualität der bereitgestellten Agenten im Produktionsverkehr mithilfe der Mosaik AI Agent Evaluation überwachen.
Die Onlineüberwachung ist ein wichtiger Aspekt, um sicherzustellen, dass Ihr Agent mit realen Anforderungen funktioniert. Mithilfe des unten bereitgestellten Notizbuchs können Sie die Agent-Auswertung kontinuierlich für die Anforderungen ausführen, die über einen Agent-Dienstendpunkt bereitgestellt werden. Das Notizbuch generiert ein Dashboard, das Qualitätsmetriken👎. Dieses Feedback kann über die Rezensions-App von Projektbeteiligten oder die Feedback-API für Produktionsendpunkte übermittelt werden, mit denen Sie Endbenutzerreaktionen erfassen können. Das Dashboard ermöglicht es Ihnen, die Metriken nach verschiedenen Dimensionen zu segmentieren, z. B. nach Zeit, Benutzerfeedback, Pass-/Fail-Status und Thema der Eingabeanforderung (z. B. um zu verstehen, ob bestimmte Themen mit Ausgaben niedrigerer Qualität korreliert werden). Darüber hinaus können Sie tiefer in einzelne Anforderungen mit antworten mit niedriger Qualität eintauchen, um sie weiter zu debuggen. Alle Artefakte, z. B. das Dashboard, können vollständig angepasst werden.
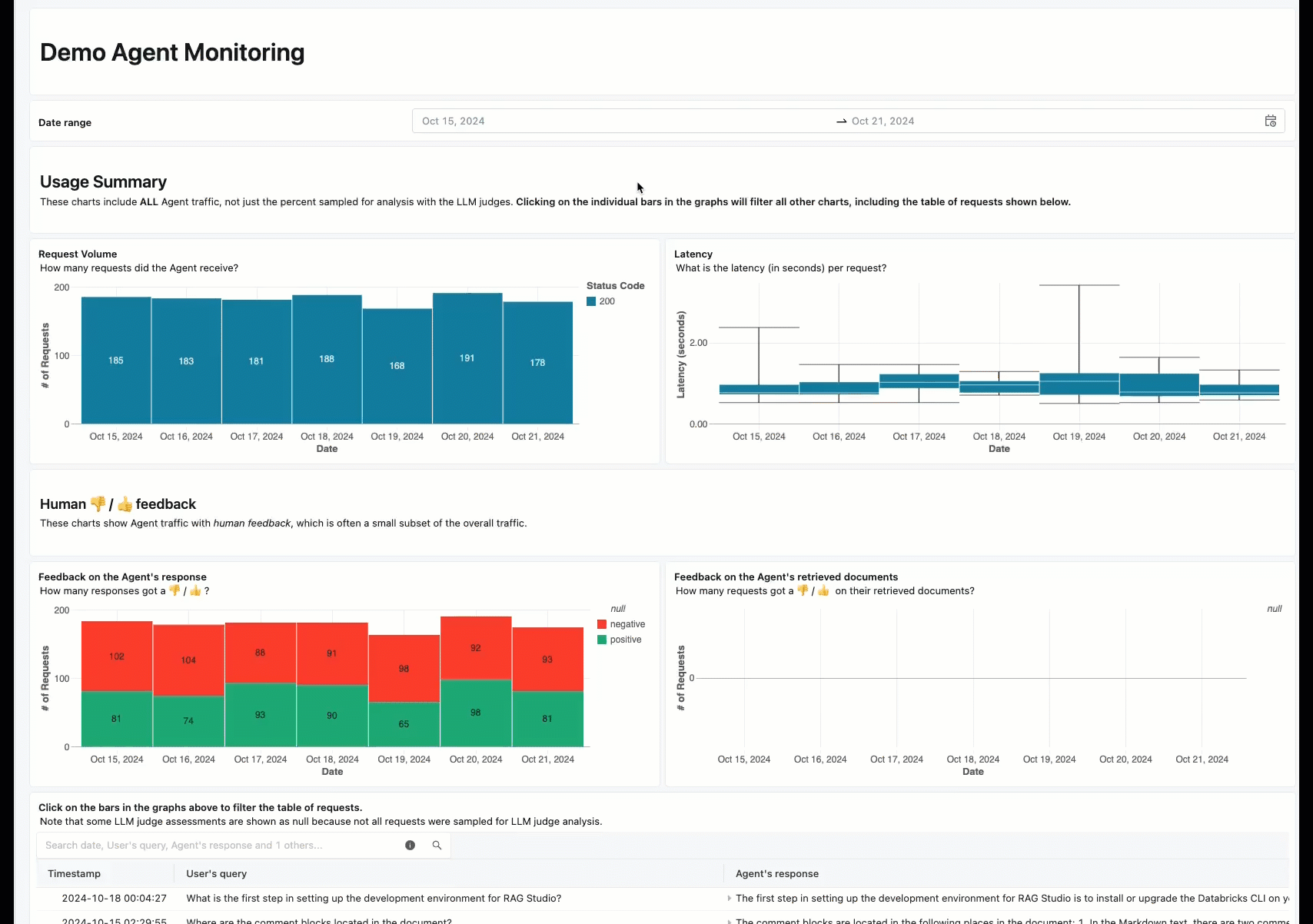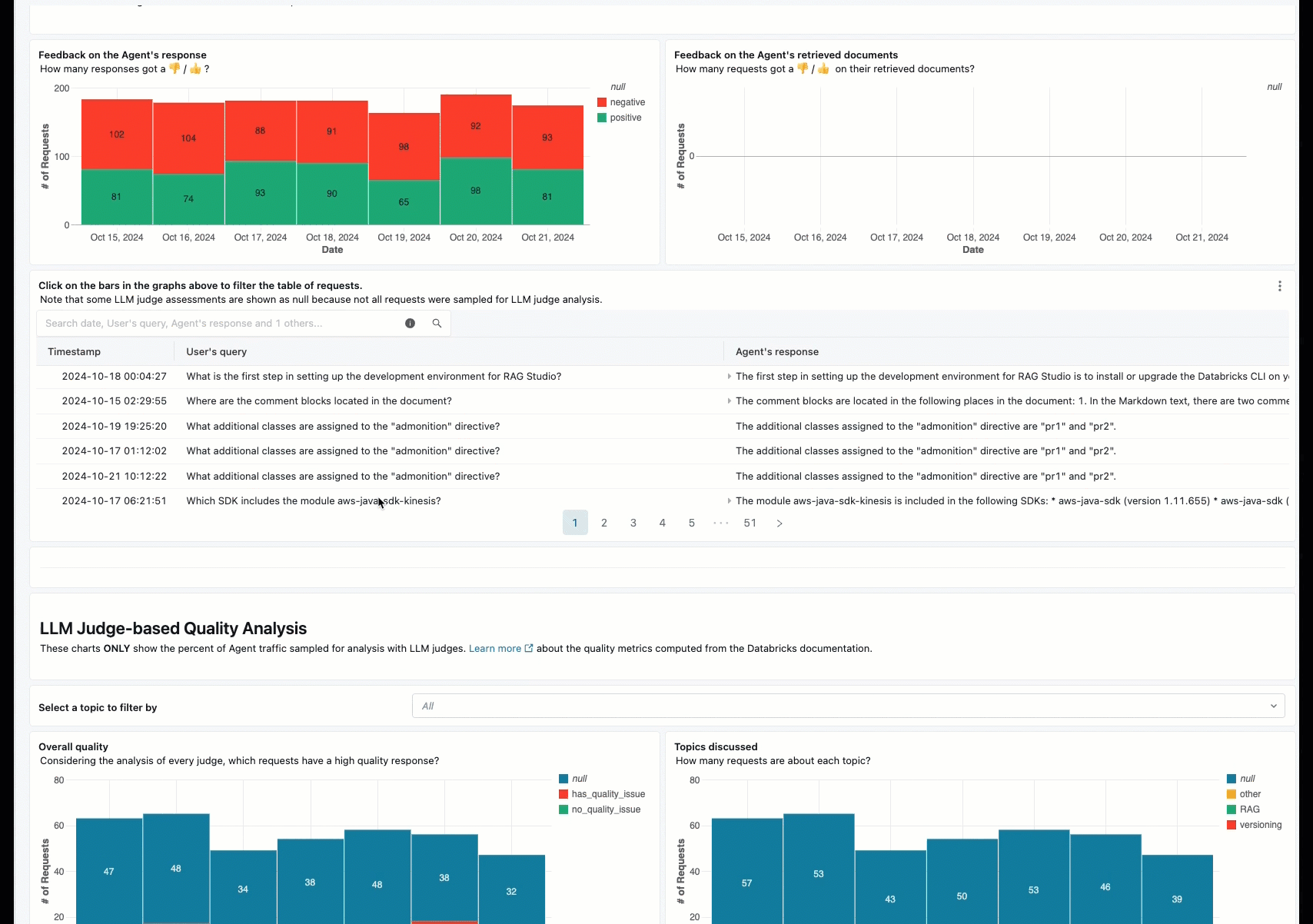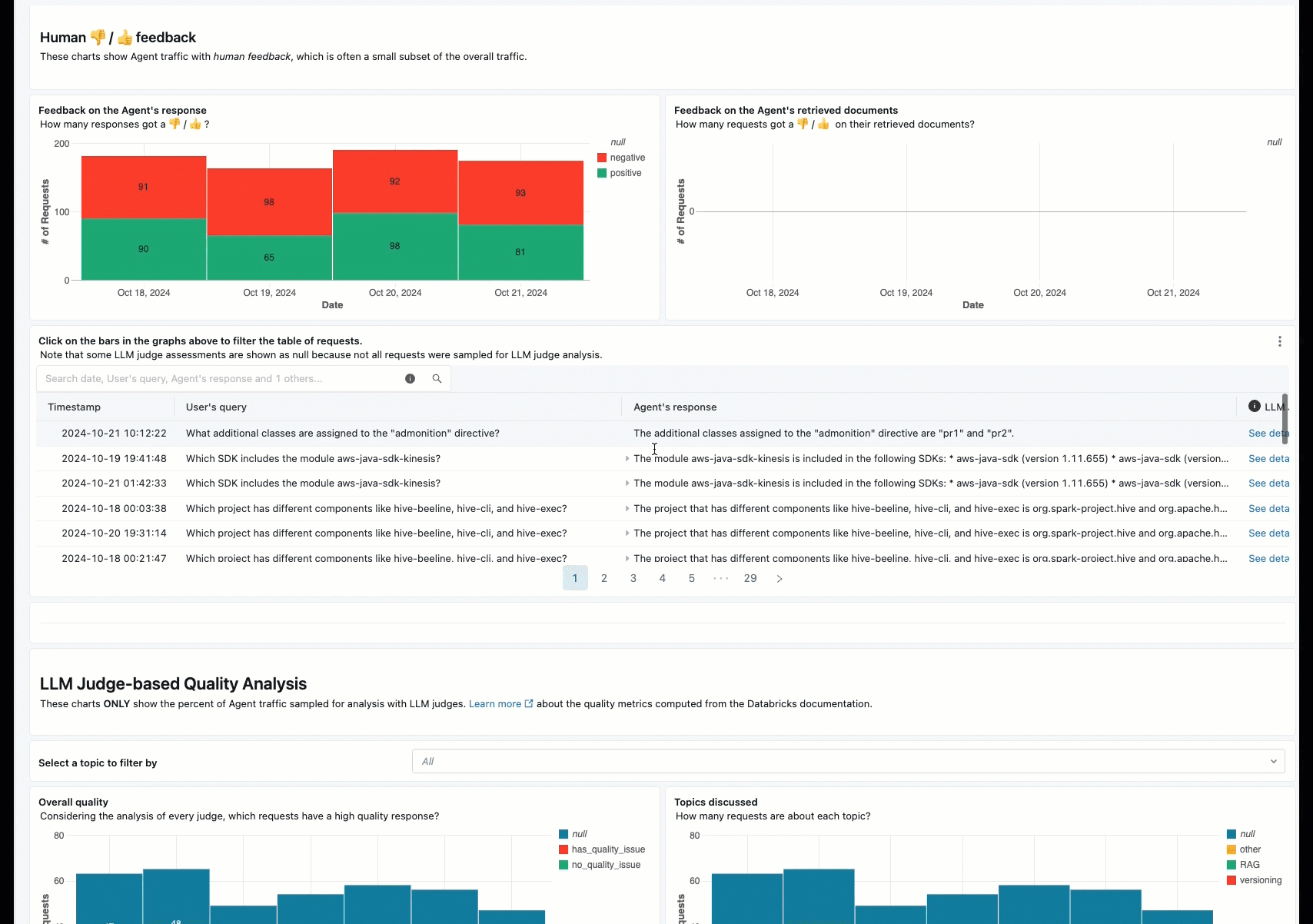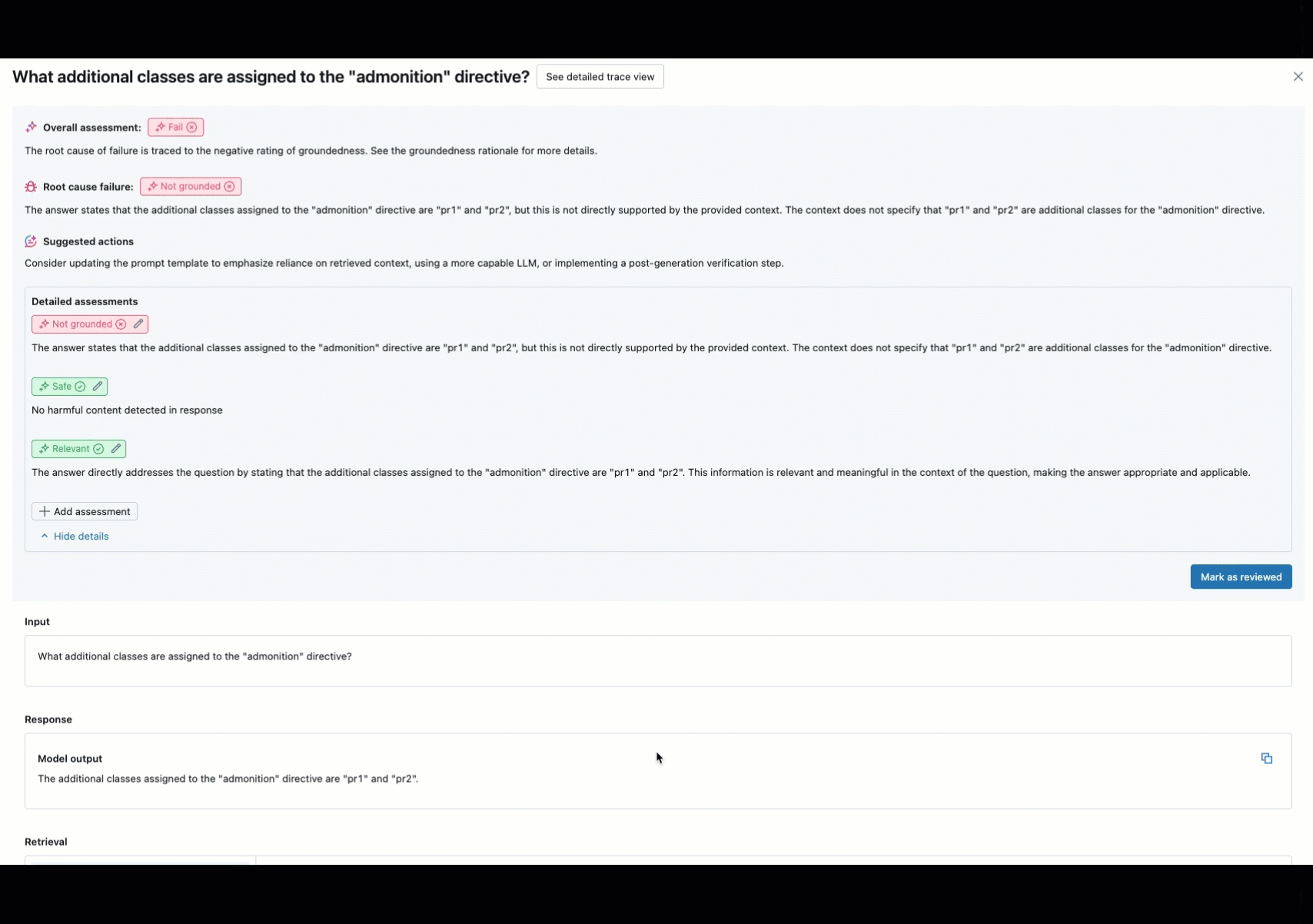
Anforderungen
- Azure KI-gesteuerte KI-Hilfsfunktionen müssen für Ihren Arbeitsbereich aktiviert sein.
- Rückschlusstabellen müssen auf dem Endpunkt aktiviert werden, der den Agent bedient.
Kontinuierlicher Prozess des Produktionsdatenverkehrs durch Agent-Auswertung
Das folgende Beispielnotizbuch veranschaulicht, wie Die Agent-Auswertung in den Anforderungsprotokollen von einem Agent ausgeführt wird, der Endpunkt bedient. Gehen Sie folgendermaßen vor, um das Notizbuch auszuführen:
- Importieren Sie das Notizbuch in Ihrem Arbeitsbereich (Anweisungen). Sie können unten auf die Schaltfläche "Link zum Importieren kopieren" klicken, um eine URL für den Import abzurufen.
- Füllen Sie die erforderlichen Parameter oben im importierten Notizbuch aus.
- Der Name des bereitgestellten Agent-Dienstendpunkts.
- Eine Abtastrate zwischen 0,0 und 1,0 für Beispielanforderungen. Verwenden Sie eine niedrigere Rate für Endpunkte mit hohen Datenverkehrsmengen.
- (Optional) Ein Arbeitsbereichsordner zum Speichern von generierten Artefakten (z. B. Dashboards). Der Standard ist der Startordner.
- (Optional) Eine Liste der Themen zum Kategorisieren der Eingabeanforderungen. Der Standardwert ist eine Liste, die aus einem einzigen Catch-All-Thema besteht.
- Klicken Sie im importierten Notizbuch auf "Alle ausführen". Dies führt eine anfängliche Verarbeitung Ihrer Produktionsprotokolle innerhalb eines 30-Tage-Fensters durch und initialisiert das Dashboard, das die Qualitätsmetriken zusammenfasst.
- Klicken Sie auf "Zeitplan" , um einen Auftrag zu erstellen, um das Notizbuch regelmäßig auszuführen. Der Auftrag verarbeitet ihre Produktionsprotokolle inkrementell und hält das Dashboard auf dem neuesten Stand.
Das Notizbuch erfordert entweder serverlose Berechnung oder einen Cluster mit Databricks Runtime 15.2 oder höher. Wenn Der Produktionsdatenverkehr auf Endpunkten mit einer großen Anzahl von Anforderungen kontinuierlich überwacht wird, empfehlen wir, einen häufigeren Zeitplan festzulegen. Beispielsweise würde ein Stundenplan für einen Endpunkt mit mehr als 10.000 Anforderungen pro Stunde und einer Stichprobenrate von 10 % gut funktionieren.
Agentauswertung für Produktionsdatenverkehr-Notizbuch ausführen
Erzwingen Sie Richtlinien für die Antworten Ihres Agenten
Die Richtlinien-Einhaltungsrichter stellen sicher, dass die Ausgaben Ihres Modells den angegebenen Richtlinien entsprechen. Sie können diese globalen Richtlinien wie im oben angegebenen Notizbuch oder wie folgt schreiben:
mlflow.evaluate(
...,
evaluator_config={
"databricks-agent": {
"global_guidelines": [
"The response must be in English",
"The response must be clear, coherent, and concise",
],
}
}
)
Die Ergebnisse dieses Richters werden in der vom Beispielnotizbuch generierten Tabelle mit den ausgewerteten Anforderungsprotokollen (eval_requests_log_table_name im Notizbuch) ausgefüllt, und das Dashboard kann angepasst werden, um die Ergebnisse des Richters im Laufe der Zeit anzuzeigen.
Erstellen von Warnungen zu Auswertungsmetriken
Nachdem Sie die Ausführung des Notizbuchs in regelmäßigen Abständen geplant haben, können Sie Benachrichtigungen hinzufügen, die benachrichtigt werden sollen, wenn Qualitätsmetriken niedriger als erwartet ausfallen. Diese Warnungen werden erstellt und auf die gleiche Weise wie andere Databricks SQL-Warnungen verwendet. Erstellen Sie zunächst eine SQL-Abfrage von Databricks in der Vom Beispielnotizbuch generierten Protokolltabelle für Auswertungsanforderungen. Der folgende Code zeigt eine Beispielabfrage über die Tabelle mit Auswertungsanforderungen und filtert Anforderungen aus der letzten Stunde:
SELECT
`date`,
AVG(pass_indicator) as avg_pass_rate
FROM (
SELECT
*,
CASE
WHEN `response/overall_assessment/rating` = 'yes' THEN 1
WHEN `response/overall_assessment/rating` = 'no' THEN 0
ELSE NULL
END AS pass_indicator
-- The eval requests log table is generated by the example notebook
FROM {eval_requests_log_table_name}
WHERE `date` >= CURRENT_TIMESTAMP() - INTERVAL 1 DAY
)
GROUP BY ALL
Erstellen Sie dann eine SQL-Warnung für Databricks, um die Abfrage mit einer gewünschten Häufigkeit auszuwerten, und senden Sie eine Benachrichtigung, wenn die Warnung ausgelöst wird. Die folgende Abbildung zeigt eine Beispielkonfiguration zum Senden einer Warnung, wenn die Gesamtdurchlaufrate unter 80 % fällt.
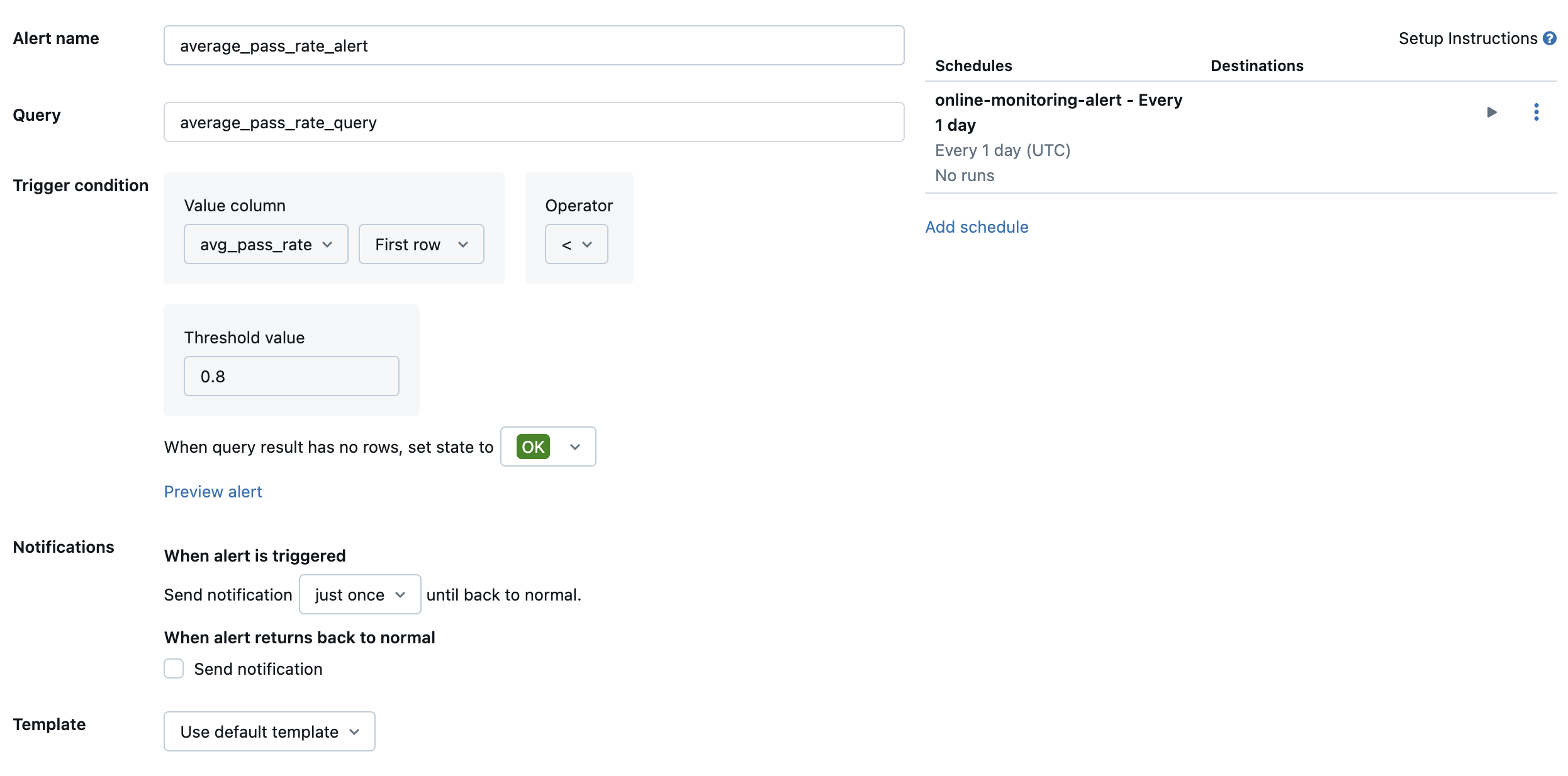
Standardmäßig wird eine E-Mail-Benachrichtigung gesendet. Sie können auch einen Webhook einrichten oder Benachrichtigungen an andere Anwendungen wie Slack oder PagerDuty senden.
Hinzufügen ausgewählter Produktionsprotokolle zur Prüf-App für die menschliche Überprüfung
Wenn Benutzer Feedback zu Ihren Anforderungen geben, können Sie Experten bitten, Anfragen mit negativem Feedback zu überprüfen (Anfragen mit Daumen nach unten auf die Antwort oder Abrufe). Dazu fügen Sie der Prüf-App spezifische Protokolle hinzu, um eine Expertenüberprüfung anzufordern.
Der folgende Code zeigt eine Beispielabfrage über die Bewertungsprotokolltabelle, um die neueste Bewertung pro Anforderungs-ID und Quell-ID abzurufen:
with ranked_logs as (
select
`timestamp`,
request_id,
source.id as source_id,
text_assessment.ratings["answer_correct"]["value"] as text_rating,
retrieval_assessment.ratings["answer_correct"]["value"] as retrieval_rating,
retrieval_assessment.position as retrieval_position,
row_number() over (
partition by request_id, source.id, retrieval_assessment.position order by `timestamp` desc
) as rank
from {assessment_log_table_name}
)
select
request_id,
source_id,
text_rating,
retrieval_rating
from ranked_logs
where rank = 1
order by `timestamp` desc
Ersetzen Sie ... im folgenden Code in der Zeile human_ratings_query = "..." eine Abfrage, die der obigen Abfrage ähnelt. Der folgende Code extrahiert dann Anforderungen mit negativem Feedback und fügt sie der Rezensions-App hinzu:
from databricks import agents
human_ratings_query = "..."
human_ratings_df = spark.sql(human_ratings_query).toPandas()
# Filter out the positive ratings, leaving only negative and "IDK" ratings
negative_ratings_df = human_ratings_df[
(human_ratings_df["text_rating"] != "positive") | (human_ratings_df["retrieval_rating"] != "positive")
]
negative_ratings_request_ids = negative_ratings_df["request_id"].drop_duplicates().to_list()
agents.enable_trace_reviews(
model_name=YOUR_MODEL_NAME,
request_ids=negative_ratings_request_ids,
)
Weitere Details zur Rezensions-App finden Sie unter "Feedback zur Qualität einer agentischen Anwendung".