Rückschlusstabellen zum Überwachen und Debuggen von Modellen
Wichtig
Dieses Feature befindet sich in der Public Preview.
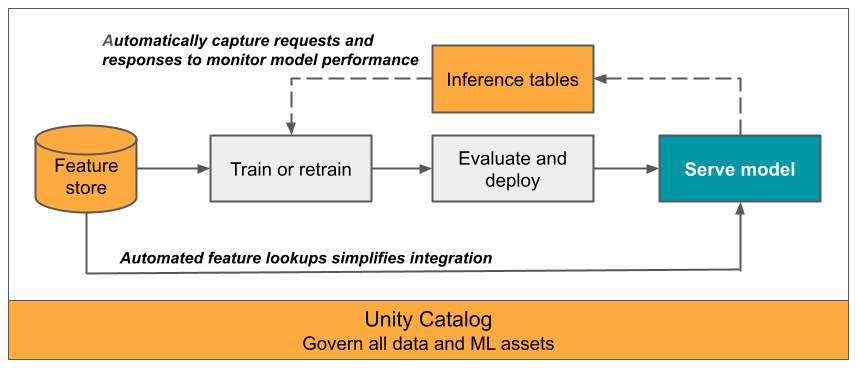
Dieser Artikel beschreibt Rückschlusstabellen zum Überwachen bereitgestellter Modelle. Die folgende Abbildung zeigt einen typischen Workflow mit Rückschlusstabellen. Die Rückschlusstabelle erfasst automatisch eingehende Anforderungen und ausgehende Antworten für einen Modellbereitstellungsendpunkt und protokolliert diese als Delta-Tabellen in Unity Catalog. Sie können die Daten in dieser Tabelle verwenden, um ML-Modelle zu überwachen, zu debuggen und zu verbessern.
Bei Endpunkten, die Modelle bereitstellen und externe Modelle hosten, können Sie Rückschlusstabellen nur über das KI-Gateway aktivieren.
Was sind Rückschlusstabellen?
Das Überwachen der Leistung von Modellen in Produktionsworkflows ist ein wichtiger Bestandteil des KI- und ML-Modelllebenszyklus. Rückschlusstabellen vereinfachen die Überwachung und Diagnose für Modellen, indem die Anforderungseingaben und -antworten (Vorhersagen) von Mosaic AI Model Serving-Endpunkten kontinuierlich protokolliert und in einer Delta-Tabelle in Unity Catalog gespeichert werden. Anschließend können Sie alle Funktionen der Databricks-Plattform wie etwa Databricks-SQL-Abfragen, Notebooks und Lakehouse Monitoring verwenden, um Ihre Modelle zu überwachen, zu debuggen und zu optimieren.
Sie können Rückschlusstabellen für alle vorhandenen oder neu erstellten Modellbereitstellungsendpunkte aktivieren. Anforderungen an solche Endpunkte werden dann automatisch in einer Tabelle in Unity Catalog protokolliert.
Nachfolgend finden Sie einige gängige Anwendungen für Rückschlusstabellen:
- Überwachen von Daten- und Modellqualität: Sie können die Leistung Ihres Modells sowie Datenabweichungen mithilfe von Lakehouse Monitoring kontinuierlich überwachen. Lakehouse Monitoring generiert automatisch Dashboard zur Daten- und Modellqualität, die Sie mit Projektbeteiligten teilen können. Darüber hinaus können Sie Benachrichtigungen aktivieren, um zu erfahren, ob Sie Ihr Modell aufgrund von Veränderungen bei den eingehenden Daten oder verringerter Modellleistung neu trainieren müssen.
- Debuggen von Problemen im Rahmen der Produktion: Rückschlusstabellen protokollieren Daten wie HTTP-Statuscodes, Modellausführungszeiten und JSON-Anforderungs- und Antwortcode. Sie können diese Leistungsdaten für Debuggingzwecke verwenden. Sie können auch die Verlaufsdaten Rückschlusstabellen verwenden, um die Modellleistung auf Basis früherer Anforderungen zu vergleichen.
- Erstellen eines Trainingskorpus: Indem Sie Rückschlusstabellen mit Grundwahrheitsbezeichnungen verknüpfen, können Sie einen Trainingskorpus erstellen, mit dessen Hilfe Sie Ihr Modell neu trainieren oder verbessern und optimieren können. Mithilfe von Databricks-Aufträgen können Sie eine kontinuierliche Feedbackschleife einrichten und das erneute Training automatisieren.
Anforderungen
- Ihr Arbeitsbereich muss für Unity Catalog aktiviert sein.
- Sowohl der Ersteller des Endpunkts als auch der Modifizierer müssen über die Berechtigung Kann verwalten für den Endpunkt verfügen. Siehe Zugriffssteuerungslisten.
- Sowohl der Ersteller des Endpunkts als auch der Modifizierer müssen über die folgenden Berechtigungen im Unity-Katalog verfügen:
USE CATALOG-Berechtigungen für den angegebenen Katalog.USE SCHEMA-Berechtigungen für das angegebene Schema.CREATE TABLE-Berechtigungen im Schema.
Aktivieren und Deaktivieren von Rückschlusstabellen
In diesem Abschnitt erfahren Sie, wie Sie Rückschlusstabellen mithilfe der Databricks-Benutzeroberfläche aktivieren oder deaktivieren. Sie können auch die API verwenden. Anweisungen finden Sie unter Aktivieren von Rückschlusstabellen für Modellbereitstellungsendpunkte mithilfe der API-.
Der Besitzer der Rückschlusstabellen ist der Benutzer, der den Endpunkt erstellt hat. Alle Zugriffssteuerungslisten (Access Control Lists, ACLs) in der Tabelle folgen den Standardberechtigungen des Unity-Catalogs und können vom Tabellenbesitzer geändert werden.
Warnung
Die Rückschlusstabelle kann beschädigt werden, wenn Sie eine der folgenden Aktionen ausführen:
- Ändern des Tabellenschemas.
- Ändern des Tabellennamens.
- Löschen der Tabelle.
- die Berechtigungen für den Unity Catalog oder das Unity Catalog-Schema verlieren.
In diesem Fall zeigt die auto_capture_config des Endpunktstatus für die Nutzlasttabelle einen FAILED-Status an. Wenn dies geschieht, müssen Sie zur weiteren Verwendung von Rückschlusstabellen einen neuen Endpunkt erstellen.
Führen Sie die folgenden Schritte aus, um Rückschlusstabellen während der Endpunkterstellung zu aktivieren:
Klicken Sie in der Benutzeroberfläche Databricks Mosaik AI auf Bereitstellung.
Klicken Sie auf Bereitstellungsendpunkt erstellen.
Wählen Sie Rückschlusstabelle aktivieren aus.
Wählen Sie im Dropdownmenü den gewünschten Katalog und das gewünschte Schema für die Positionierung der Tabelle aus.
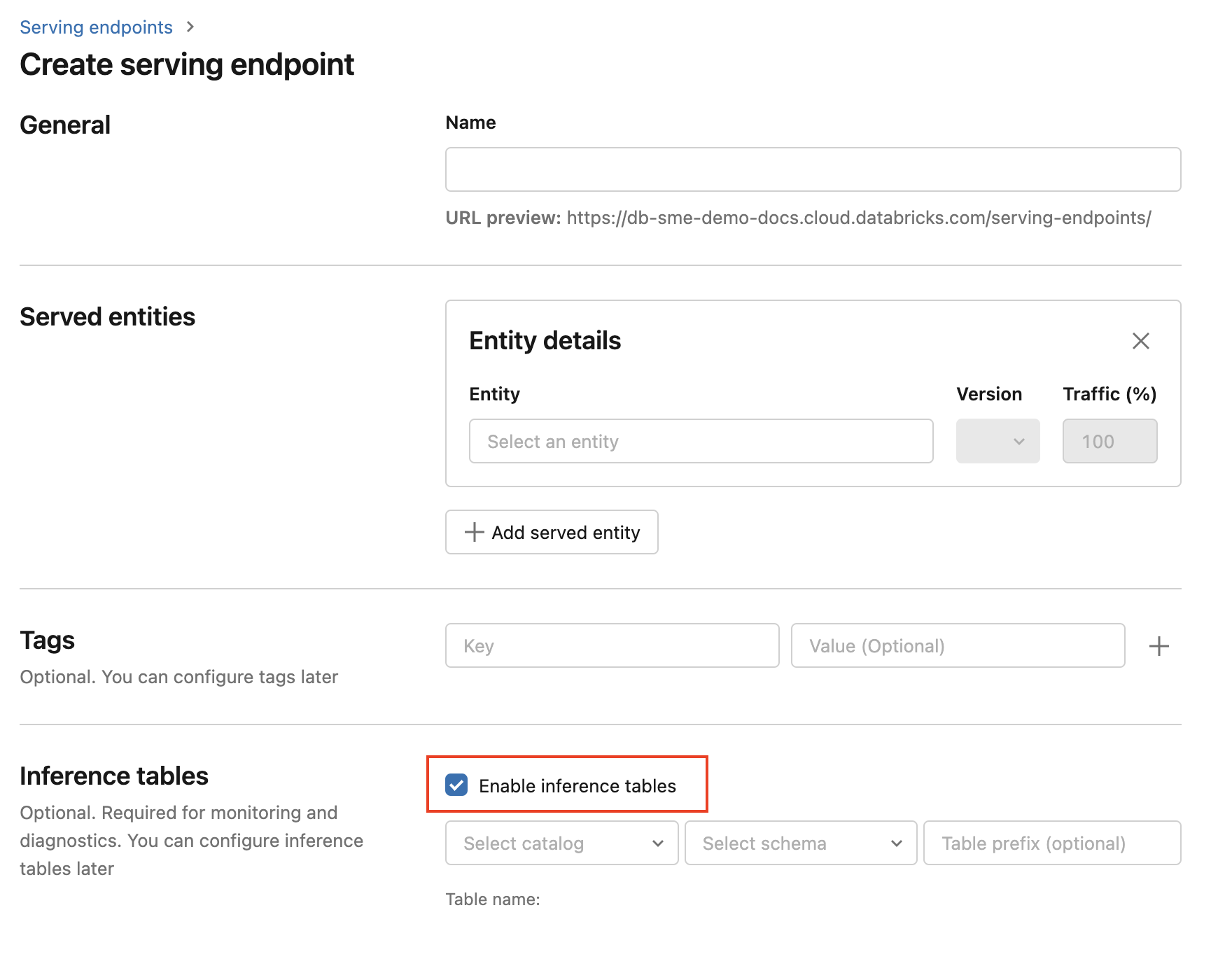
Der Standardtabellenname lautet
<catalog>.<schema>.<endpoint-name>_payload. Wenn Sie möchten, können Sie ein benutzerdefiniertes Tabellenpräfix eingeben.Klicken Sie auf Bereitstellungsendpunkt erstellen.
Sie können Rückschlusstabellen auch für einen vorhandenen Endpunkt aktivieren. Gehen Sie wie folgt vor, um eine vorhandene Endpunktkonfiguration zu bearbeiten:
- Navigieren zur Seite „Endpunkt“.
- Klicken Sie auf Konfiguration bearbeiten.
- Folgen Sie den vorherigen Anweisungen, beginnend mit Schritt 3.
- Wenn Sie fertig sind, klicken Sie auf Bereitstellungsendpunkt aktualisieren.
Führen Sie die folgenden Anweisungen aus, um Rückschlusstabellen zu deaktivieren:
- Navigieren zur Seite „Endpunkt“.
- Klicken Sie auf Konfiguration bearbeiten.
- Klicken Sie auf Rückschlusstabelle aktivieren, um das Häkchen zu entfernen.
- Sobald Sie mit den Endpunktspezifikationen zufrieden sind, klicken Sie auf Aktualisieren.
Workflow: Überwachen der Modellleistung mithilfe von Rückschlusstabellen
Führen Sie die folgenden Schritte aus, um die Modellleistung mithilfe von Rückschlusstabellen zu überwachen:
- Aktivieren Sie Rückschlusstabellen auf Ihrem Endpunkt – entweder während der Endpunkterstellung oder durch anschließende Aktualisierung.
- Planen Sie einen Workflow, um die JSON-Nutzdaten in der Rückschlusstabelle zu verarbeiten, indem Sie sie gemäß dem Schema des Endpunkts entpacken.
- (Optional:) Verbinden Sie die entpackten Anforderungen und Antworten mit Grundwahrheitsbezeichnungen, um die Berechnung von Modellqualitätsmetriken zu ermöglichen.
- Erstellen Sie einen Monitor für die resultierende Delta-Tabelle, und aktualisieren Sie die Metriken.
Die Starternotebooks implementieren diesen Workflow.
Starternotebook für die Überwachung einer Rückschlusstabelle
Im folgenden Notebook werden die oben beschriebenen Schritte ausgeführt, um Anforderungen aus einer Lakehouse Monitoring-Rückschlusstabelle zu entpacken. Das Notebook kann bei Bedarf oder nach einem wiederkehrenden Zeitplan mit Databricks-Aufträgen ausgeführt werden.
Lakehouse Monitoring-Starternotebook für eine Rückschlusstabelle
Starternotebook zur Überwachung der Textqualität von Endpunkten, die LLMs bereitstellen
Das folgende Notebook entpackt Anforderungen aus einer Rückschlusstabelle, berechnet eine Reihe von Textauswertungsmetriken (z. B. Lesbarkeit und Toxizität), und ermöglicht die Überwachung mithilfe dieser Metriken. Das Notebook kann bei Bedarf oder nach einem wiederkehrenden Zeitplan mit Databricks-Aufträgen ausgeführt werden.
Lakehouse Monitoring-Starternotebook für eine LLM-Rückschlusstabelle
Abfragen und Analysieren von Ergebnissen in der Rückschlusstabelle
Nachdem Ihre bereitgestellten Modelle fertig sind, werden alle Anforderungen an sie zusammen mit den Antworten automatisch in der Rückschlusstabelle protokolliert. Sie können die Tabelle auf der Benutzeroberfläche anzeigen oder sie aus DBSQL oder einem Notizbuch oder mithilfe der REST-API abfragen.
Zum Anzeigen der Tabelle auf der Benutzeroberfläche: Klicken Sie auf der Seite „Endpunkt“ pauf den Namen der Rückschlusstabelle, um sie im Katalog-Explorer zu öffnen.

Zum Abfragen der Tabelle aus DBSQL oder einem Databricks-Notebook: Sie können Code ähnlich der folgenden Abfrage ausführen, um die Rückschlusstabelle abzufragen.
SELECT * FROM <catalog>.<schema>.<payload_table>
Wenn Sie Rückschlusstabellen mithilfe der Benutzeroberfläche aktiviert haben, ist payload_table der Tabellenname, den Sie beim Erstellen des Endpunkts zugewiesen haben. Wenn Sie Rückschlusstabellen mithilfe der API aktiviert haben, wird payload_table im Abschnitt state der Antwort auto_capture_config gemeldet. Ein Beispiel finden Sie unter Aktivieren von Rückschlusstabellen für Modellbereitstellungsendpunkte mithilfe der API.
Hinweis zur Leistung
Nach dem Aufrufen des Endpunkts wird Ihnen eine Stunde nach dem Senden einer Bewertungsanforderung der protokollierte Aufruf in Ihrer Rückschlusstabelle angezeigt. Darüber hinaus garantiert Azure Databricks, dass die Protokollübermittlung mindestens einmal erfolgt, sodass es möglich (wenn auch unwahrscheinlich) ist, dass duplizierte Protokolle gesendet werden.
Unity Catalog-Rückschlusstabellenschema
Jede Anforderung und Antwort, die in einer Rückschlusstabelle protokolliert wird, wird in eine Delta-Tabelle mit dem folgenden Schema geschrieben:
Hinweis
Wenn Sie den Endpunkt mit einem Eingabebatch aufrufen, wird der gesamte Batch als eine Zeile protokolliert.
| Spaltenname | Beschreibung | Typ |
|---|---|---|
databricks_request_id |
Ein von Azure Databricks generierter Anforderungsbezeichner, der an alle Modellbereitstellungsanforderungen angefügt ist | STRING |
client_request_id |
Ein optionaler von einem Client generierter Anforderungsbezeichner, der im Anforderungstext der Modellbereitstellung angegeben werden kann. Weitere Informationen finden Sie unter Angeben der client_request_id. |
STRING |
date |
Das UTC-Datum, an dem die Modellbereitstellungsanforderung empfangen wurde | DATE |
timestamp_ms |
Der Zeitstempel in Epochenmillisekunden, zu dem die Anforderung zur Modellbereitstellung empfangen wurde. | LONG |
status_code |
Der HTTP-Statuscode, der vom Modell zurückgegeben wurde | INT |
sampling_fraction |
Der Stichprobenanteil, der für den Fall verwendet wird, dass die Anforderung reduziert wurde. Dieser Wert liegt zwischen 0 und 1, wobei 1 angibt, dass 100 % der eingehenden Anforderungen einbezogen wurden. | DOUBLE |
execution_time_ms |
Die Ausführungszeit in Millisekunden, in der das Modell einen Rückschluss ausgeführt hat. Diese schließt keine Netzwerkwartezeiten für einen Mehraufwand ein und stellt lediglich die Zeit dar, die das Modell zum Generieren von Vorhersagen benötigt hat. | LONG |
request |
Der JSON-Textkörper der unformatierten Anforderung, der an den Modellbereitstellungsendpunkt gesendet wurde | STRING |
response |
Der JSON-Textkörper der unformatierten Antwort, der vom Modellbereitstellungsendpunkt zurückgegeben wurde | STRING |
request_metadata |
Eine Metadatenzuordnung im Zusammenhang mit dem Modellbereitstellungsendpunkt, der der Anforderung zugeordnet ist. Diese Zuordnung enthält den Namen des Endpunkts und des Modells sowie die Modellversion, die für Ihren Endpunkt verwendet wird. | MAP<STRING, STRING> |
Geben Sie client_request_id an.
Das Feld client_request_id ist ein optionaler Wert, den der Benutzer im Anforderungstext des Modells angeben kann. Auf diese Weise kann der Benutzer einen eigenen Bezeichner für eine Anforderung bereitstellen, die in der endgültigen Rückschlusstabelle unter der client_request_id angezeigt wird und für die Verknüpfung Ihrer Anforderung mit anderen Tabellen verwendet werden kann, die die client_request_id verwenden, z. B. zum Verknüpfen von Grundwahrheitsbezeichnungen. Um eine client_request_id anzugeben, schließen Sie sie als Schlüssel der Anforderungsnutzlast auf oberster Ebene ein. Wenn Sie keine client_request_id angeben, wird der Wert in der Zeile, die der Anforderung entspricht, als NULL angezeigt.
{
"client_request_id": "<user-provided-id>",
"dataframe_records": [
{
"sepal length (cm)": 5.1,
"sepal width (cm)": 3.5,
"petal length (cm)": 1.4,
"petal width (cm)": 0.2
},
{
"sepal length (cm)": 4.9,
"sepal width (cm)": 3,
"petal length (cm)": 1.4,
"petal width (cm)": 0.2
},
{
"sepal length (cm)": 4.7,
"sepal width (cm)": 3.2,
"petal length (cm)": 1.3,
"petal width (cm)": 0.2
}
]
}
Die client_request_id kann später zum Verknüpfen von Grundwahrheitsbezeichnungen verwendet werden, wenn es andere Tabellen mit Bezeichnungen gibt, die der client_request_idzugeordnet sind.
Begrenzungen
- Kundenseitig verwaltete Schlüssel werden nicht unterstützt.
- Für Endpunkte, die Foundationmodelle hosten, werden Inference-Tabellen nur für bereitgestellte Durchsatzworkloads unterstützt.
- Azure Firewall kann zu Fehlern beim Erstellen einer Delta-Tabelle in Unity Catalog führen und wird daher nicht standardmäßig unterstützt. Wenden Sie sich an Ihr Databricks-Kontoteam, um dies zu aktivieren.
- Wenn Inferencetabellen aktiviert sind, beträgt der Grenzwert für die maximale Parallelität aller bereitgestellten Modelle in einem einzelnen Endpunkt 128. Wenden Sie sich an Ihr Azure Databricks-Kontoteam, um eine Erhöhung dieses Grenzwerts anzufordern.
- Wenn eine Rückschlusstabelle mehr als 500.000 Dateien enthält, werden keine weiteren Daten protokolliert. Um die Überschreitung dieses Grenzwerts zu vermeiden, führen Sie OPTIMIZE aus, oder richten Sie die Datenaufbewahrung für Ihre Tabelle ein, indem Sie ältere Daten löschen. Führen Sie
DESCRIBE DETAIL <catalog>.<schema>.<payload_table>aus, um die Anzahl von Dateien in Ihrer Tabelle zu überprüfen. - Die Bereitstellung der Protokolle für die Inferenztabellen erfolgt derzeit nach bestem Bemühen, aber Sie können davon ausgehen, dass die Protokolle innerhalb von 1 Stunde nach einer Anfrage verfügbar sind. Wenden Sie sich an Ihr Databricks-Kontoteam, um weitere Informationen zu erfahren.
Allgemeine Endpunkteinschränkungen finden Sie unter Modellbereitstellungseinschränkungen und Regionen.