Überwachen des Azure-Daten-Explorers
Azure Monitor sammelt und aggregiert Metriken und Protokolle von Ihrem System, um Die Verfügbarkeit, Leistung und Resilienz zu überwachen und Sie über Probleme zu informieren, die sich auf Ihr System auswirken. Sie können das Azure-Portal, PowerShell, Azure CLI, REST-API oder Clientbibliotheken verwenden, um Überwachungsdaten einzurichten und anzuzeigen.
Für unterschiedliche Ressourcentypen stehen unterschiedliche Metriken und Protokolle zur Verfügung. In diesem Artikel werden die Arten von Überwachungsdaten beschrieben, die Sie für diesen Dienst sammeln können, und Methoden zum Analysieren dieser Daten.
Sammeln von Daten mit Azure Monitor
In dieser Tabelle wird beschrieben, wie Sie Daten sammeln können, um Ihren Dienst zu überwachen, und was Sie mit den Daten tun können, sobald sie gesammelt wurden:
| Zu erfassende Daten | Beschreibung | Wie man Daten sammelt und weiterleitet | Wo die Daten angezeigt werden sollen | Unterstützte Daten |
|---|---|---|---|---|
| Metrikdaten | Metriken sind numerische Werte, die einen Aspekt eines Systems zu einem bestimmten Zeitpunkt beschreiben. Metriken können mithilfe von Algorithmen aggregiert und im Vergleich zu anderen Metriken auf Trends im Laufe der Zeit analysiert werden. | – Automatisch in regelmäßigen Abständen gesammelt. – Sie können einige Plattformmetriken an einen Log Analytics-Arbeitsbereich weiterleiten, um andere Daten abzufragen. Überprüfen Sie die DS-Exporteinstellung für jede Metrik, um festzustellen, ob Sie eine Diagnoseeinstellung verwenden können, um die Metrikdaten weiterzuleiten. |
Metrik-Explorer | Azure Data Explorer-Metriken, die von Azure Monitor unterstützt werden |
| Ressourcenprotokolldaten | Systemereignisse mit einem Zeitstempel werden als Protokolle aufgezeichnet. Protokolle können unterschiedliche Datentypen enthalten und aus strukturiertem oder frei formatiertem Text bestehen. Sie können Ressourcenprotokolldaten an Log Analytics-Arbeitsbereiche zur Abfrage und Analyse weiterleiten. | Erstellen Sie eine Diagnoseeinstellung zum Sammeln und Weiterleiten von Ressourcenprotokolldaten. | Log Analytics | Von Azure Monitor unterstützte Azure Data Explorer-Ressourcenprotokolldaten |
| Aktivitätsprotokolldaten | Das Azure Monitor-Aktivitätsprotokoll bietet Einblicke in Ereignisse auf Abonnementebene. Das Aktivitätsprotokoll enthält Informationen darüber, wann eine Ressource geändert wird oder wann ein virtueller Computer gestartet wird. | - Automatisch gesammelt. - Erstellen Sie eine Diagnoseeinstellung kostenlos in einem Log Analytics-Arbeitsbereich. |
Aktivitätsprotokoll |
Eine Liste aller von Azure Monitor unterstützten Daten finden Sie unter:
Integrierte Überwachung für Azure Data Explorer
Azure Data Explorer bietet Metriken und Protokolle zur Überwachung des Diensts.
Überwachen Sie die Leistung, den Zustand und die Nutzung von Azure Data Explorer mit Metriken
Azure Data Explorer-Metriken stellen wichtige Indikatoren für die Integrität und Leistung der Azure Data Explorer-Clusterressourcen bereit. Verwenden Sie die Metriken, um die Azure Data Explorer-Clusternutzung, -integrität und -leistung in Ihrem spezifischen Szenario als eigenständige Metriken zu überwachen. Sie können Metriken auch als Basis für den Betrieb von Azure-Dashboards und Azure-Warnungen verwenden.
So verwenden Sie Metriken, um Ihre Azure Data Explorer-Ressourcen im Azure-Portal zu überwachen:
- Melden Sie sich beim Azure-Portal an.
- Suchen Sie im linken Bereich Ihres Azure Data Explorer-Clusters nach Metriken.
- Wählen Sie Metriken aus, um den Bereich „Metriken“ zu öffnen und mit der Analyse Ihres Clusters zu beginnen.
Wählen Sie im Bereich "Metriken" bestimmte Metriken aus, die nachverfolgt werden sollen, wählen Sie aus, wie Ihre Daten aggregiert werden sollen, und erstellen Sie Metrikdiagramme, die im Dashboard angezeigt werden sollen.
Die Auswahlen Ressource und Metriknamespace werden für Ihren Azure Data Explorer-Cluster vorab ausgewählt. Die Zahlen in der folgenden Abbildung entsprechen der nummerierten Liste. Sie führen Sie durch verschiedene Möglichkeiten beim Einrichten und Anzeigen Ihrer Messwerte.
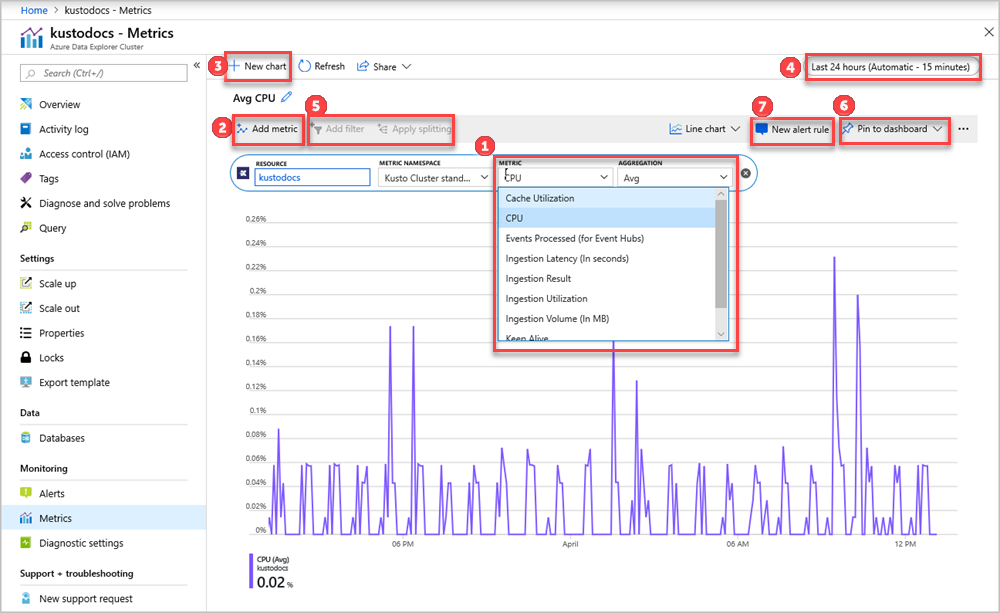
- Wählen Sie zum Erstellen eines Metrikdiagramms den Namen der Metrik und die relevante Aggregation pro Metrik aus. Weitere Informationen zu verschiedenen Metriken finden Sie unter unterstützte Azure Data Explorer-Metriken.
- Wählen Sie aus und fügen Sie Metrik hinzu, um mehrere Metriken im selben Diagramm darzustellen.
- Wählen Sie + Neues Diagramm aus, um mehrere Diagramme in einer Ansicht anzuzeigen.
- Verwenden Sie die Zeitauswahl, um den Zeitraum zu ändern (Standard: letzte 24 Stunden).
- Verwenden Sie Filter hinzufügen und Trennung anwenden für Metriken, die über Dimensionen verfügen.
- Wählen Sie die Option An Dashboard anheften, um Ihre Diagrammkonfiguration den Dashboards hinzuzufügen, damit Sie die Anzeige erneut verwenden können.
- Legen Sie die Option Neue Warnungsregel fest, um Ihre Metriken mit den festgelegten Kriterien zu visualisieren. Die neue Warnungsregel umfasst die Zielressourcen-, Metrik-, Trennungs- und Filterdimensionen aus Ihrem Diagramm. Ändern Sie diese Einstellungen im Bereich für die Erstellung von Warnungsregeln.
Überwachen der Erfassung, Befehle, Abfragen und Tabellen von Azure Data Explorer mithilfe von Diagnoseprotokollen
Azure Data Explorer ist ein schneller, vollständig verwalteter Data Analytics-Dienst für Echtzeitanalysen für große Datenmengen, die von Anwendungen, Websites, IoT-Geräten und mehr gestreamt werden. Azure Monitor-Diagnoseprotokolle enthalten Daten zum Betrieb von Azure-Ressourcen. In Azure Data Explorer werden Diagnoseprotokolle verwendet, um Erkenntnisse zu Erfassung, Befehlen, Abfragen und Tabellen zu gewinnen. Sie können Vorgangsprotokolle in Azure Storage, Event Hub oder Log Analytics exportieren, um den Ingestion-, Befehls- und Abfragestatus zu überwachen. Protokolle von Azure Storage und Azure Event Hubs können zur weiteren Analyse an eine Tabelle in Ihrem Azure Data Explorer-Cluster weitergeleitet werden.
Wichtig
Diagnoseprotokolldaten können vertrauliche Daten enthalten. Schränken Sie die Berechtigungen des Protokollziels gemäß Ihren Überwachungsanforderungen ein.
Anmerkung
Im Azure-Portal werden die unformatierten (rohen) Metrikdaten für die Seiten Metriken und Erkenntnisse in Azure Monitor gespeichert. Die Abfragen auf diesen Seiten abfragen die Rohmetrikendaten direkt, um die genauesten Ergebnisse bereitzustellen. Wenn Sie die Diagnostikeinstellungen verwenden, können Sie die Metrikdaten in den Log Analytics-Arbeitsbereich migrieren. Während der Migration gehen aufgrund von Rundungen möglicherweise einige Datengenauigkeit verloren; Daher können abfrageergebnisse geringfügig von den ursprünglichen Daten abweichen. Der Fehlerrand ist kleiner als ein Prozent.
Diagnoseprotokolle können verwendet werden, um die Sammlung der folgenden Protokolldaten zu konfigurieren:
Anmerkung
- Erfassungsprotokolle werden für die Erfassung in der Warteschlange für den Datenerfassungs-URI mithilfe von Kusto-Clientbibliotheken und Datenconnectors unterstützt.
- Erfassungsprotokolle werden nicht für die Streamingerfassung, die direkte Erfassung an den Cluster-URI sowie die Erfassung aus Abfragen oder
.set-or-append-Befehlen unterstützt.
Anmerkung
Fehlerhafte Erfassungsprotokolle werden nur für den endgültigen Status eines Erfassungsvorgangs gemeldet. Dies steht im Gegensatz zur Metrik Erfassungsergebnis, die für intern wiederholte vorübergehende Fehler ausgegeben wird.
- Erfolgreiche Erfassungsoperationen: Diese Protokolle enthalten Informationen zu erfolgreich abgeschlossenen Erfassungsoperationen.
- Fehlgeschlagene Erfassungsvorgänge: Diese Protokolle enthalten detaillierte Informationen zu fehlgeschlagenen Erfassungsvorgängen einschließlich Fehlerdetails.
- Batchverarbeitungsvorgänge für die Datenerfassung: Diese Protokolle enthalten ausführliche Statistiken zu Batches, die für die Erfassung bereit sind (Dauer, Batchgröße, Blobanzahl und Batchverarbeitungstypen).
Sie können die Protokolldaten an einen Log Analytics-Arbeitsbereich, ein Speicherkonto oder an einen Event Hub streamen.
Diagnoseprotokolle sind standardmäßig deaktiviert. Führen Sie die folgenden Schritte aus, um Diagnoseprotokolle für Ihren Cluster zu aktivieren:
Wählen Sie im Azure-Portaldie Clusterressource aus, die Sie überwachen möchten.
Wählen Sie unter Überwachung die Option Diagnoseeinstellungen aus.
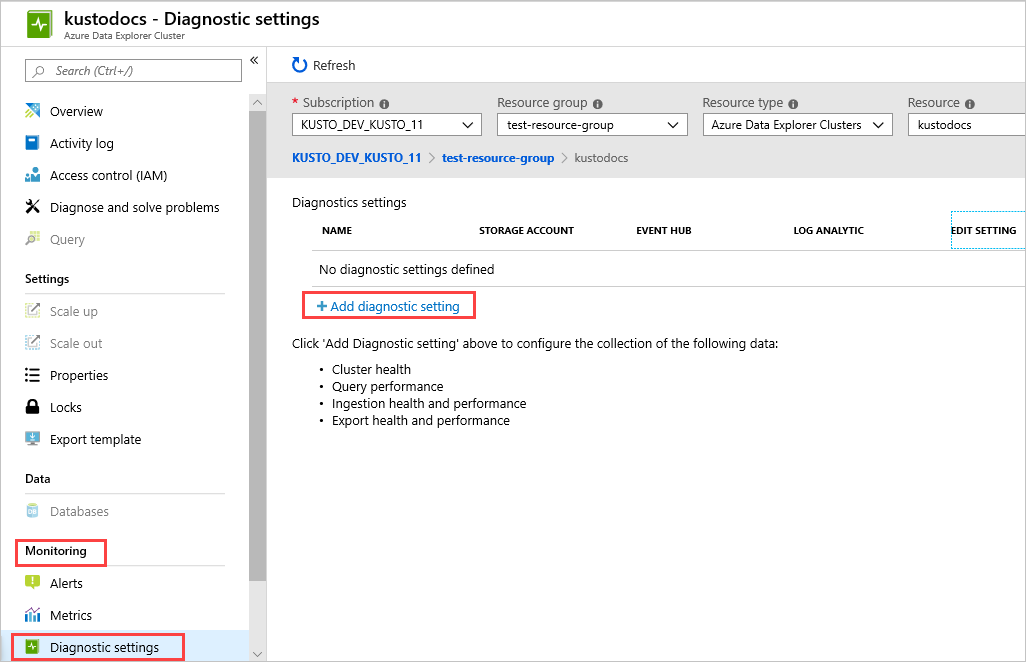
Klicken Sie auf Diagnoseeinstellung hinzufügen.
Gehen Sie im Fenster Diagnoseeinstellungen wie folgt vor:
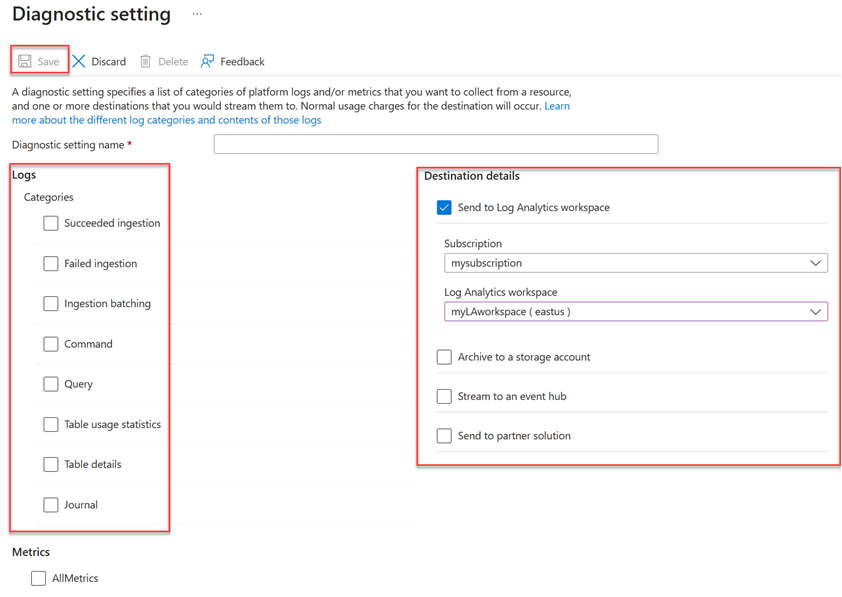
- Geben Sie unter Name der Diagnoseeinstellung einen Namen ein.
- Wählen Sie ein oder mehrere Zielziele aus: einen Log Analytics-Arbeitsbereich, ein Speicherkonto oder einen Event Hub.
- Wählen Sie zu erfassende Protokolle aus: Erfolgreiche Erfassung, Fehlgeschlagene Erfassung, Batchverarbeitung der Datenerfassung, Befehl, Abfrage, Tabellennutzungsstatistiken, Tabellendetails oder Journal.
- Wählen Sie die zu sammelnden Metriken aus (optional).
- Wählen Sie Speichern aus, um die neuen Diagnoseprotokolleinstellungen und Metriken zu speichern.
Sobald die Einstellungen konfiguriert sind, werden die Protokolle in den konfigurierten Zielen angezeigt: einem Speicherkonto, einem Event Hub oder einem Log Analytics-Arbeitsbereich.
Anmerkung
Wenn Sie Protokolle an einen Log Analytics-Arbeitsbereich senden, werden die SucceededIngestion, FailedIngestion, IngestionBatching, Command, Query, TableUsageStatistics, TableDetailsund Journal Protokolle in Log Analytics-Tabellen gespeichert: SucceededIngestion, FailedIngestion, ADXIngestionBatching, ADXCommand, ADXQuery, ADXTableUsageStatistics, ADXTableDetailsund ADXJournal.
Verwenden von Azure Monitor-Tools zum Analysieren der Daten
Diese Azure Monitor-Tools stehen im Azure-Portal zur Verfügung, um Überwachungsdaten zu analysieren:
Einige Azure-Dienste verfügen über ein integriertes Überwachungsdashboard im Azure-Portal. Diese Dashboards werden als Insightsbezeichnet, und Sie finden sie im Abschnitt Insights von Azure Monitor im Azure-Portal.
Metrik-Explorer ermöglicht es Ihnen, Metriken für Azure-Ressourcen anzuzeigen und zu analysieren. Weitere Informationen finden Sie unter Analysieren von Metriken mit dem Azure Monitor-Metrik-Explorer.
Log Analytics ermöglicht Ihnen, Logdaten mithilfe der Kusto-Abfragesprache (KQL)abzufragen und zu analysieren. Weitere Informationen finden Sie unter Erste Schritte mit Protokollabfragen in Azure Monitor.
Das Azure-Portal hat eine Benutzeroberfläche, mit der Sie das Aktivitätsprotokoll anzeigen und darin suchen können. Um ausführlichere Analysen durchzuführen, leiten Sie die Daten an Azure Monitor-Protokolle weiter und führen Sie komplexere Abfragen in Log Analytics aus.
Application Insights überwacht die Verfügbarkeit, Leistung und Nutzung Ihrer Webanwendungen, sodass Sie Fehler identifizieren und diagnostizieren können, ohne darauf zu warten, dass ein Benutzer sie meldet.
Application Insights umfasst Verbindungspunkte zu verschiedenen Entwicklungstools und ist in Visual Studio integriert, um Ihre DevOps-Prozesse zu unterstützen. Weitere Informationen finden Sie unter Anwendungsüberwachung für App Service.
Zu den Tools, die eine komplexere Visualisierung ermöglichen, gehören:
- Dashboards, mit denen Sie verschiedene Typen von Daten in einen einzelnen Bereich im Azure-Portal kombinieren können.
- Arbeitsmappen, anpassbare Berichte, die Sie im Azure-Portal erstellen können. Arbeitsmappen können Text-, Metrik- und Protokollabfragen enthalten.
- Grafana, ein offenes Plattform-Tool, das sich hervorragend für operative Dashboards eignet. Sie können Grafana verwenden, um Dashboards zu erstellen, die Daten aus mehreren anderen Quellen als Azure Monitor enthalten.
- Power BI, einem Business Analytics-Dienst, der interaktive Visualisierungen in verschiedenen Datenquellen bereitstellt. Sie können Power BI so konfigurieren, dass Protokolldaten automatisch aus Azure Monitor importiert werden, um diese Visualisierungen nutzen zu können.
Exportieren von Azure Monitor-Daten
Sie können Daten aus Azure Monitor in andere Tools exportieren:
Metriken: Verwenden Sie die REST-API für Metriken, um Metrikdaten aus der Azure Monitor-Metrikdatenbank zu extrahieren. Weitere Informationen finden Sie unter Azure Monitor-REST-API-Referenz.
Protokolle: Verwenden Sie die REST-API oder die zugeordneten Clientbibliotheken.
Um mit der Azure Monitor-REST-API zu beginnen, lesen Sie den Leitfaden zur Azure Monitor REST-API.
Verwenden von Kusto-Abfragen zum Analysieren von Protokolldaten
Sie können Azure Monitor Log-Daten mithilfe der Kusto-Abfragesprache (KQL) analysieren. Weitere Informationen finden Sie unter Protokollabfragen in Azure Monitor.
Verwenden Sie Azure Monitor-Warnungen, um sich über Probleme benachrichtigen zu lassen.
Azure Monitor-Warnungen ermöglichen es Ihnen, Probleme in Ihrem System zu identifizieren und zu beheben, sowie Sie proaktiv zu benachrichtigen, wenn bestimmte Bedingungen in Ihren Überwachungsdaten gefunden werden, bevor Ihre Kunden sie bemerken. Sie können zu jeder Metrik oder Protokolldatenquelle der Azure Monitor-Datenplattform Warnungen erhalten. Es gibt verschiedene Typen von Azure Monitor-Warnungen, abhängig von den Diensten, die Sie überwachen, und den Überwachungsdaten, die Sie sammeln. Weitere Informationen finden Sie unter Auswählen des richtigen Warnungsregeltyps.
Beispiele für häufige Warnungen für Azure-Ressourcen finden Sie unter Beispielabfragen für Protokollwarnungen.
Implementieren von Warnungen im großen Stil
Bei einigen Diensten können Sie die Skalierung überwachen, indem Sie dieselbe Metrik-Warnungsregel auf mehrere Ressourcen desselben Typs anwenden, die in derselben Azure-Region vorhanden sind. Azure Monitor-Baselinewarnungen (AMBA) stellen eine halbautomatisierte Methode für die Implementierung wichtiger Metrikwarnungen der Plattform, Dashboards und Richtlinien im großen Stil bereit.
Erhalten Sie personalisierte Empfehlungen mithilfe von Azure Advisor
Wenn in einigen Diensten während eines Ressourcenvorgangs kritische Bedingungen oder unmittelbar bevorstehende Änderungen auftreten, wird auf der Dienstseite Übersicht im Portal eine Warnung angezeigt. Weitere Informationen und empfohlene Korrekturen für die Warnung finden Sie in den Beraterempfehlungen unter Überwachung im linken Menü. Während des normalen Betriebs werden keine Advisor-Empfehlungen angezeigt.
Weitere Informationen zu Azure Advisor finden Sie unter Azure Advisor -Übersicht.