Die analytische Onlineverarbeitung (Online Analytical Processing, OLAP) ist eine Technologie, die große Geschäftsdatenbanken organisiert und komplexe Analysen unterstützt. OLAP kann genutzt werden, um komplexe analytische Abfragen durchzuführen, ohne dass Transaktionssysteme negativ beeinträchtigt werden.
Die Datenbanken, die von einem Unternehmen zum Speichern aller Transaktionen und Datensätze verwendet werden, werden als Datenbanken mit Onlinetransaktionsverarbeitung (Online Transaction Processing, OLTP) bezeichnet. Diese Datenbanken enthalten normalerweise Datensätze, die einzeln eingegeben werden. Häufig befinden sich darin viele Informationen, die nützlich für die Organisation sind. Die Datenbanken, die für OLTP genutzt werden, wurden dagegen nicht für Analysezwecke entworfen. Daher ist das Abrufen von Antworten aus diesen Datenbanken sehr zeitintensiv und aufwändig. OLAP-Systeme sind dafür ausgelegt, diese Business Intelligence-Informationen mit hoher Leistung aus den Daten zu extrahieren. Der Grund ist, dass OLAP-Datenbanken für Workloads mit hohem Lese- und geringem Schreibaufwand optimiert sind.
Semantische Modellierung
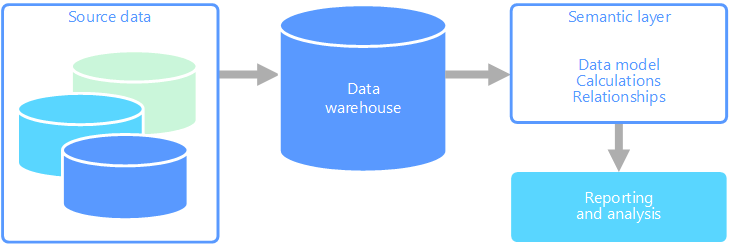
Ein semantisches Datenmodell ist ein konzeptionelles Modell, mit dem die Bedeutung der darin enthaltenen Datenelemente beschrieben wird. In Organisationen werden häufig eigene Begriffe verwendet, bei denen es sich um Synonyme handeln kann oder die für denselben Begriff unterschiedliche Bedeutungen haben. Beispiel: In einer Bestandsdatenbank wird ein Ausrüstungsteil anhand einer Asset-ID und einer Seriennummer nachverfolgt, während in einer Vertriebsdatenbank die Seriennummer als Asset-ID bezeichnet wird. Es gibt keine einfache Möglichkeit, diese Werte miteinander in Beziehung zu setzen, ohne dass ein Modell verwendet wird, mit dem die Beziehung beschrieben wird.
Die semantische Modellierung ermöglicht ein bestimmtes Maß an Abstraktion für das Datenbankschema, damit Benutzer nicht über die zugrunde liegenden Datenstrukturen informiert sein müssen. Dies erleichtert Endbenutzern das Abfragen von Daten ohne Durchführung von Aggregierungs- und Verknüpfungsvorgängen für das zugrunde liegende Schema. Außerdem erhalten Spalten normalerweise benutzerfreundlichere Namen, damit der Kontext und die Bedeutung der Daten besser erkennbar ist.
Die semantische Modellierung wird hauptsächlich für Szenarien mit hohem Leseaufwand verwendet, beispielsweise für Analytics und Business Intelligence (OLAP), und nicht für die transaktionale Datenverarbeitung (OLTP) mit hohem Schreibaufwand. Dies liegt vor allem an der Art einer typischen semantischen Ebene:
- Das Aggregierungsverhalten ist so festgelegt, dass es von Tools für die Berichterstellung richtig angezeigt werden.
- Die Geschäftslogik und die Berechnungen sind definiert.
- Zeitabhängige Berechnungen sind enthalten.
- Daten werden häufig aus mehreren Quellen integriert.
Aus diesen Gründen wird die semantische Ebene meist über einem Data Warehouse angeordnet.
Es gibt zwei Hauptarten von Semantikmodellen:
- Tabellarisch: Hierfür werden Konstrukte der relationalen Modellierung verwendet (Modell, Tabellen, Spalten). Intern werden Metadaten von Konstrukten der OLAP-Modellierung geerbt (Cubes, Dimensionen, Measures). Für den Code und Skripts werden OLAP-Metadaten genutzt.
- Mehrdimensional: Hierfür werden herkömmliche Konstrukte der OLAP-Modellierung verwendet (Cubes, Dimensionen, Measures).
In Frage kommender Azure-Dienst:
Beispiel eines Anwendungsfalls
In einer Organisation werden Daten in einer großen Datenbank gespeichert. Diese Daten sollen für geschäftliche Benutzer und Kunden verfügbar gemacht werden, damit diese eigene Berichte erstellen und Analysen durchführen können. Eine Option besteht darin, diesen Benutzern direkten Zugriff auf die Datenbank zu gewähren. Dieser Ansatz ist aber mit mehreren Nachteilen verbunden, z.B. dem Aufwand für die Verwaltung der Sicherheit und Steuerung des Zugriffs. Außerdem kann das Design der Datenbank, z.B. Namen von Tabellen und Spalten, für Benutzer schwer verständlich sein. Benutzer müssen wissen, welche Tabellen abgefragt werden sollen, wie diese Tabellen verknüpft werden müssen und wie es sich mit der weiteren Geschäftslogik verhält, die angewendet werden muss, um die richtigen Ergebnisse zu erhalten. Benutzer müssen sich zudem mit einer Abfragesprache, z.B. SQL, auskennen, um beginnen zu können. Normalerweise führt dies dazu, dass mehrere Benutzer die gleichen Metriken melden, aber mit unterschiedlichen Ergebnissen.
Eine andere Option besteht darin, alle Informationen, die Benutzer benötigen, in einem Semantikmodell zusammenzufassen. Das Semantikmodell kann von Benutzern mit einem Berichterstellungstool ihrer Wahl einfacher abgefragt werden. Die vom Semantikmodell bereitgestellten Daten werden per Pullvorgang aus einem Data Warehouse abgerufen, um sicherzustellen, dass alle Benutzer die einzige und richtige Version angezeigt bekommen. Darüber hinaus werden über das Semantikmodell auch Anzeigenamen für Tabellen und Spalten, Beziehungen zwischen Tabellen, Beschreibungen, Berechnungen und die Sicherheit auf Zeilenebene bereitgestellt.
Typische Merkmale der semantischen Modellierung
Für die semantische Modellierung und analytische Verarbeitung gelten in der Regel die folgenden Merkmale:
| Anforderung | Beschreibung |
|---|---|
| Schema | Schema beim Schreiben, strikte Erzwingung |
| Nutzung von Transaktionen | No |
| Sperrstrategie | Keine |
| Aktualisierbar | Nein (normalerweise Neuberechnung des Cubes erforderlich) |
| Erweiterbar | Nein (normalerweise Neuberechnung des Cubes erforderlich) |
| Workload | Hoher Leseaufwand, schreibgeschützt |
| Indizierung | Mehrdimensionale Indizierung |
| Bezugsgröße | Kleine bis mittlere Größe |
| Modell | Mehrdimensional |
| Datenform: | Cube oder Stern/Schneeflockenschema |
| Abfrageflexibilität | Sehr flexibel |
| Skalierung: | Groß (Dutzende bis mehrere Hundert GB) |
Verwendung dieser Lösung
Erwägen Sie in den folgenden Szenarien die Verwendung von OLAP:
- Sie müssen schnell komplexe Analyse- und Ad-hoc-Abfragen durchführen können, ohne dass sich negative Auswirkungen auf Ihre OLTP-Systeme ergeben.
- Sie möchten geschäftlichen Benutzern das einfache Erstellen von Berichten aus Ihren Daten ermöglichen.
- Sie möchten eine Reihe von Aggregationen bereitstellen, damit Benutzer schnelle, einheitliche Ergebnisse erhalten.
OLAP ist besonders nützlich zum Anwenden von Aggregatberechnungen auf große Datenmengen. OLAP-Systeme sind für Szenarien mit hohem Leseaufwand optimiert, z.B. Analytics und Business Intelligence. OLAP ermöglicht Benutzern das Segmentieren von mehrdimensionalen Daten in Slices, die in zwei Dimensionen (z.B. einer PivotTable) angezeigt werden können, oder das Filtern der Daten nach bestimmten Werten. Dieser Prozess wird im Englischen auch als „Slicing & Dicing“ der Daten bezeichnet und kann unabhängig davon erfolgen, ob die Daten über mehrere Datenquellen hinweg partitioniert sind. Benutzer können Trends ermitteln, Muster erkennen und die Daten untersuchen, ohne die Details der herkömmlichen Datenanalyse kennen zu müssen.
Semantikmodelle können Benutzern als Unterstützung beim Abstrahieren von komplexen Beziehungen dienen und das schnelle Analysieren von Daten vereinfachen.
Herausforderungen
Neben den vielen Vorteilen von OLAP-Systemen sind auch einige Herausforderungen zu bewältigen:
- Während Daten in OLTP-Systemen aufgrund der eingehenden Transaktionen aus verschiedenen Quellen ständig aktualisiert werden, werden OLAP-Datenquellen meist in deutlich längeren Abständen aktualisiert. Dies richtet sich nach den geschäftlichen Anforderungen. OLAP-Systeme sind also besser für strategische Geschäftsentscheidungen und nicht so sehr für direkte Reaktionen auf Veränderungen geeignet. Außerdem muss ein bestimmtes Maß an Bereinigung und Orchestrierung eingeplant werden, um die OLAP-Datenspeicher auf dem neuesten Stand zu halten.
- Im Gegensatz zu herkömmlichen, normalisierten, relationalen Tabellen in OLTP-Systemen sind OLAP-Datenmodelle eher mehrdimensional. Hierdurch wird es schwierig oder sogar unmöglich, eine direkte Zuordnung zu Entitätsbeziehungs- oder objektorientierten Modellen vorzunehmen, bei denen jedes Attribut einer Spalte zugeordnet wird. Für OLAP-Systeme wird anstelle der herkömmlichen Normalisierung stattdessen normalerweise ein Stern- oder Schneeflockenschema verwendet.
OLAP in Azure
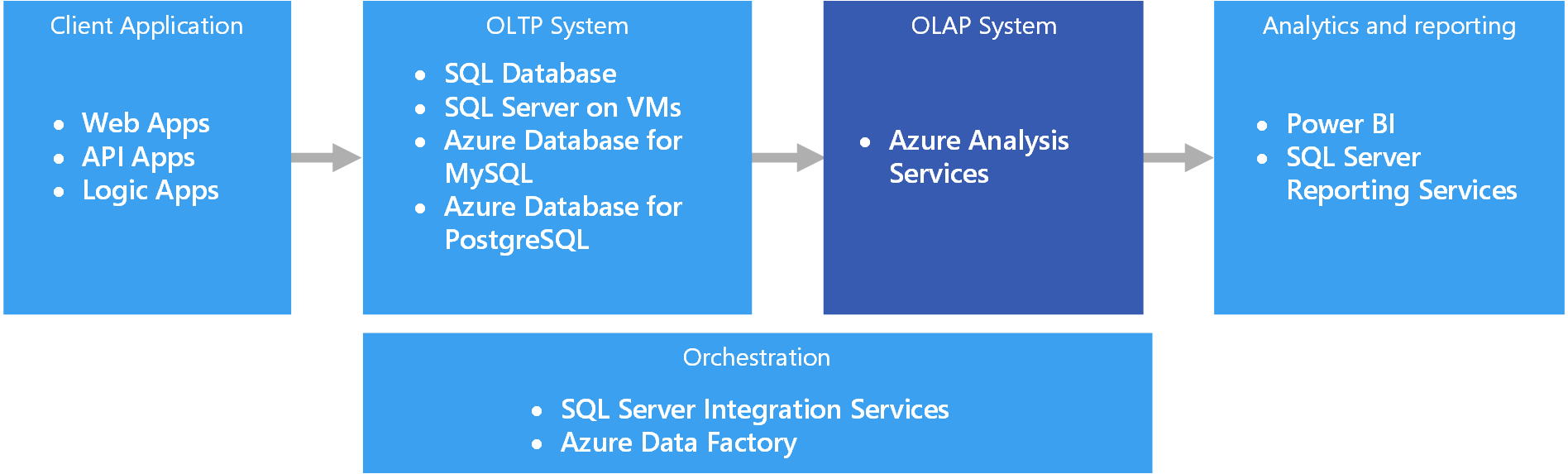
In Azure werden Daten, die in OLTP-Systemen vorgehalten werden, z.B. Azure SQL-Datenbank, in das OLAP-System kopiert, z.B. Azure Analysis Services. Tools für die Datenuntersuchung und Visualisierung, z.B. Power BI, Excel und Drittanbieteroptionen, stellen eine Verbindung mit Analysis Services-Servern her und ermöglichen Benutzern extrem interaktive und visuell umfassende Einblicke in die modellierten Daten. Der Datenfluss von OLTP-Daten zu OLAP wird normalerweise über SQL Server Integration Services orchestriert, die mit Azure Data Factory ausgeführt werden können.
In Azure erfüllen alle folgenden Datenspeicher die grundlegenden Anforderungen für OLAP:
SQL Server Analysis Services (SSAS) bietet OLAP- und Data Mining-Funktionen für Business Intelligence-Anwendungen. Sie können SSAS auf lokalen Servern installieren oder auf einer VM in Azure hosten. Azure Analysis Services ist ein vollständig verwalteter Dienst, der die gleichen Hauptfunktionen wie SSAS bereitstellt. Azure Analysis Services unterstützt das Herstellen von Verbindungen mit verschiedenen Datenquellen in der Cloud und lokalen Datenquellen in der Organisation.
Gruppierte Columnstore-Indizes sind in SQL Server 2014 und höher sowie Azure SQL-Datenbank verfügbar und eignen sich ideal für OLAP-Workloads. Ab SQL Server 2016 (einschließlich Azure SQL-Datenbank) können Sie jedoch mithilfe von aktualisierbaren nicht gruppierten Columnstore-Indizes die hybride Verarbeitung von Transaktionen und Analysen (Hybrid Transactional and Analytical Processing, HTAP) nutzen. HTAP ermöglicht Ihnen die OLTP- und OLAP-Verarbeitung auf der gleichen Plattform. Dadurch entfällt die Notwendigkeit, mehrere Kopien Ihrer Daten zu speichern sowie separate OLTP- und OLAP-Systeme zu verwenden. Weitere Informationen finden Sie unter Erste Schritte mit Columnstore für operative Echtzeitanalyse.
Wichtige Auswahlkriterien
Beantworten Sie die folgenden Fragen, um die Auswahl einzuschränken:
Möchten Sie einen verwalteten Dienst verwenden, anstatt Ihre eigenen Server zu verwalten?
Benötigen Sie eine sichere Authentifizierung mit Microsoft Entra ID?
Möchten Sie Echtzeitanalysen ausführen? Ist dies der Fall, beschränken Sie sich auf die Optionen, die Echtzeitanalysen unterstützten.
Echtzeitanalyse bezieht sich in diesem Kontext auf eine einzelne Datenquelle, beispielsweise eine ERP-Anwendung (Enterprise Resource Planning), die sowohl auf einer operativen als auch einer analytischen Workload ausgeführt wird. Wenn Sie Daten aus mehreren Quellen integrieren müssen oder eine sehr hohe Analyseleistung durch Verwendung von vorab aggregierten Daten wie Cubes erforderlich ist, benötigen Sie möglicherweise trotzdem ein separates Data Warehouse.
Müssen Sie vorab aggregierte Daten verwenden, beispielsweise zum Bereitstellen von semantischen Modellen, die Geschäftsbenutzern die Verwendung von Analysen erleichtern? Ist dies der Fall, wählen Sie eine Option aus, die mehrdimensionale Cubes oder tabellarische Semantikmodelle unterstützt.
Die Bereitstellung von Aggregaten kann Benutzern die konsistente Berechnung von Datenaggregaten ermöglichen. Bei der Arbeit mit mehreren Spalten und vielen Zeilen können vorab aggregierte Daten zudem die Leistung erheblich steigern. Daten können in mehrdimensionalen Cubes oder tabellarischen Semantikmodellen vorab aggregiert werden.
Müssen Sie Daten aus mehreren Quellen (abgesehen von Ihrem OLTP-Datenspeicher) integrieren? Ist dies der Fall, sollten Sie Optionen erwägen, die eine einfache Integration mehrerer Datenquellen ermöglichen.
Funktionsmatrix
In den folgenden Tabellen sind die Hauptunterschiede der Funktionen zusammengefasst:
Allgemeine Funktionen
| Funktion | Azure Analysis Services | SQL Server Analysis Services | SQL Server mit Columnstore-Indizes | Azure SQL-Datenbank mit Columnstore-Indizes |
|---|---|---|---|---|
| Verwalteter Dienst | Ja | Nr. | Nein | Ja |
| Unterstützung mehrdimensionaler Cubes | Nein | Ja | Nr. | Nein |
| Unterstützung tabellarischer Semantikmodelle | Ja | Ja | Nr. | Nein |
| Einfache Integration mehrerer Datenquellen | Ja | Ja | Nein 1 | Nein 1 |
| Unterstützung von Echtzeitanalysen | Nein | Nein | Ja | Ja |
| Erfordert einen Prozess zum Kopieren von Daten aus Quellen | Ja | Ja | Nr. | Nein |
| Microsoft Entra-Integration | Ja | Nein | Nein2 | Yes |
[1] Obwohl SQL Server und Azure SQL-Datenbank nicht zum Abfragen und Integrieren mehrerer externer Datenquellen verwendet werden können, können Sie zu diesem Zweck eine Pipeline mit SSIS oder Azure Data Factory erstellen. Eine auf einer Azure-VM gehostete SQL Server-Instanz bietet zusätzliche Optionen, beispielsweise Verbindungsserver und PolyBase. Weitere Informationen finden Sie unter Pipeline orchestration, control flow, and data movement (Pipelineorchestrierung, Ablaufsteuerung und Datenverschiebung).
[2] Das Herstellen einer Verbindung mit einer SQL Server-Instanz, die auf einer Azure-VM ausgeführt wird, wird mit Microsoft Entra-Konten nicht unterstützt. Verwenden Sie stattdessen ein Active Directory-Domänenkonto.
Skalierbarkeitsfunktionen
| Funktion | Azure Analysis Services | SQL Server Analysis Services | SQL Server mit Columnstore-Indizes | Azure SQL-Datenbank mit Columnstore-Indizes |
|---|---|---|---|---|
| Redundante regionale Server für Hochverfügbarkeit | Ja | Keine | Ja | Ja |
| Unterstützung des Aufskalierens von Abfragen | Ja | Keine | Ja | Ja |
| Dynamische Skalierbarkeit (Hochskalieren) | Ja | Keine | Ja | Ja |
Nächste Schritte
- Columnstore-Indizes: Übersicht
- Erstellen eines Analysis Services-Servers
- Was ist Azure Data Factory?
- Was ist Power BI?