Eine Big Data-Architektur ist für die Verarbeitung, Verarbeitung und Analyse von Daten konzipiert, die für herkömmliche Datenbanksysteme zu groß oder komplex sind.

Big Data-Lösungen umfassen in der Regel eine oder mehrere der folgenden Arten von Workload:
- Batchverarbeitung von ruhenden Big Data-Quellen.
- Echtzeitverarbeitung von Big Data in Bewegung.
- Interaktive Erkundung von Big Data.
- Predictive Analytics und maschinelles Lernen.
Die meisten Big Data-Architekturen umfassen einige oder alle der folgenden Komponenten:
Datenquellen: Alle Big Data-Lösungen beginnen mit einer oder mehreren Datenquellen. Beispiele sind:
- Anwendungsdatenspeicher, z. B. relationale Datenbanken.
- Statische Dateien, die von Anwendungen erstellt werden, z. B. Webserverprotokolldateien.
- Echtzeitdatenquellen, z. B. IoT-Geräte.
Datenspeicher: Daten für Batchverarbeitungsvorgänge werden in der Regel in einem verteilten Dateispeicher gespeichert, der große Datenmengen in verschiedenen Formaten enthalten kann. Diese Art von Speicher wird oft als Data Lakebezeichnet. Zu den Optionen für die Implementierung dieses Speichers gehören Azure Data Lake Store oder BLOB-Container in Azure Storage.
Batchverarbeitung: Da die Datasets so groß sind, muss häufig eine Big Data-Lösung Datendateien mithilfe langer Batchaufträge verarbeiten, um die Daten zu filtern, zu aggregieren und andernfalls für die Analyse vorzubereiten. In der Regel umfassen diese Aufträge das Lesen von Quelldateien, die Verarbeitung und das Schreiben der Ausgabe in neue Dateien. Zu den Optionen gehören die Verwendung von Datenflüssen, Datenpipelines in Microsoft Fabric.
Echtzeitnachrichtenaufnahme: Wenn die Lösung Echtzeitquellen enthält, muss die Architektur eine Möglichkeit zum Erfassen und Speichern von Echtzeitnachrichten für die Datenstromverarbeitung enthalten. Dies kann ein einfacher Datenspeicher sein, in dem eingehende Nachrichten zur Verarbeitung in einen Ordner abgelegt werden. Viele Lösungen benötigen jedoch einen Nachrichtenaufnahmespeicher, um als Puffer für Nachrichten zu fungieren und die Skalierungsverarbeitung, zuverlässige Zustellung und andere Nachrichtenwarteschlangensemantik zu unterstützen. Zu den Optionen gehören Azure Event Hubs, Azure IoT Hubs und Kafka.
Streamverarbeitung: Nach dem Erfassen von Echtzeitnachrichten muss die Lösung diese verarbeiten, indem sie filtern, aggregieren und andernfalls die Daten für die Analyse vorbereiten. Die verarbeiteten Datenstromdaten werden dann in eine Ausgabesenke geschrieben. Azure Stream Analytics bietet einen verwalteten Datenstromverarbeitungsdienst basierend auf unbefristeten SQL-Abfragen, die auf ungebundenen Datenströmen ausgeführt werden. Eine weitere Option ist die Verwendung von Echtzeitintelligenz in Microsoft Fabric, mit der Sie KQL-Abfragen ausführen können, während die Daten aufgenommen werden.
Analytischen Datenspeicher: Viele Big Data-Lösungen bereiten Daten für die Analyse vor und dienen dann den verarbeiteten Daten in einem strukturierten Format, das mithilfe von Analysetools abgefragt werden kann. Der analysebasierte Datenspeicher, der für diese Abfragen verwendet wird, kann ein relationales Data Warehouse im Kimball-Stil sein, wie in den meisten herkömmlichen Business Intelligence -Lösungen (BI) oder einem Lakehouse mit Medallion-Architektur (Bronze, Silber und Gold) zu sehen ist. Azure Synapse Analytics bietet einen verwalteten Dienst für umfangreiches, cloudbasiertes Data Warehouse. Alternativ bietet Microsoft Fabric beide Optionen – Lagerhaus und Lakehouse – die mit SQL bzw. Spark abgefragt werden können.
Analyse und Berichterstellung: Das Ziel der meisten Big Data-Lösungen besteht darin, Einblicke in die Daten durch Analyse und Berichterstellung zu liefern. Um Benutzern die Analyse der Daten zu ermöglichen, kann die Architektur eine Datenmodellierungsebene umfassen, z. B. einen mehrdimensionalen OLAP-Cube oder ein tabellarisches Datenmodell in Azure Analysis Services. Es kann auch Self-Service BI unterstützen, indem die Modellierungs- und Visualisierungstechnologien in Microsoft Power BI oder Microsoft Excel verwendet werden. Analysen und Berichte können auch in Form einer interaktiven Datenerkundung durch Datenwissenschaftler oder Datenanalysten erfolgen. Für diese Szenarien bietet Microsoft Fabric Tools wie Notizbücher, mit denen der Benutzer entweder SQL oder eine Programmiersprache seiner Wahl auswählen kann.
Orchestrierung: Die meisten Big Data-Lösungen bestehen aus wiederholten Datenverarbeitungsvorgängen, gekapselt in Workflows, die Quelldaten transformieren, Daten zwischen mehreren Quellen und Senken verschieben, die verarbeiteten Daten in einen analytischen Datenspeicher laden oder die Ergebnisse direkt an einen Bericht oder Dashboard übertragen. Um diese Workflows zu automatisieren, können Sie eine Orchestrierungstechnologie wie Azure Data Factory oder Microsoft Fabric-Pipelines verwenden.
Azure umfasst viele Dienste, die in einer Big Data-Architektur verwendet werden können. Sie fallen ungefähr in zwei Kategorien:
- Verwaltete Dienste, einschließlich Microsoft Fabric, Azure Data Lake Store, Azure Synapse Analytics, Azure Stream Analytics, Azure Event Hubs, Azure IoT Hub und Azure Data Factory.
- Open Source-Technologien, die auf der Apache Hadoop-Plattform basieren, einschließlich HDFS, HBase, Hive, Spark und Kafka. Diese Technologien sind in Azure im Azure HDInsight-Dienst verfügbar.
Diese Optionen schließen sich nicht gegenseitig aus, und viele Lösungen kombinieren Open Source-Technologien mit Azure-Diensten.
Wann diese Architektur verwendet werden soll
Berücksichtigen Sie diesen Architekturstil, wenn Sie Folgendes benötigen:
- Speichern und verarbeiten Sie Daten in Volumes zu groß für eine herkömmliche Datenbank.
- Transformieren Sie unstrukturierte Daten für Analyse und Berichterstellung.
- Erfassen, Verarbeiten und Analysieren ungebundener Datenströme in Echtzeit oder mit geringer Latenz.
- Verwenden Sie Azure Machine Learning oder Azure Cognitive Services.
Nützt
- Technologieauswahl. Sie können verwaltete Azure-Dienste und Apache-Technologien in HDInsight-Clustern kombinieren und abgleichen, um vorhandene Fähigkeiten oder Technologieinvestitionen zu nutzen.
- Leistung durch Parallelität. Big Data-Lösungen nutzen Parallelität und ermöglichen leistungsstarke Lösungen, die auf große Datenmengen skaliert werden.
- elastisch skaliert. Alle Komponenten in der Big Data-Architektur unterstützen die Skalierungsbereitstellung, sodass Sie Ihre Lösung auf kleine oder große Workloads anpassen und nur für die von Ihnen verwendeten Ressourcen bezahlen können.
- Interoperabilität mit vorhandenen Lösungen. Die Komponenten der Big Data-Architektur werden auch für IoT-Verarbeitungs- und Enterprise BI-Lösungen verwendet, sodass Sie eine integrierte Lösung über Datenworkloads hinweg erstellen können.
Herausforderungen
- Komplexität. Big Data-Lösungen können extrem komplex sein, mit zahlreichen Komponenten zum Verarbeiten von Daten aus mehreren Datenquellen. Es kann schwierig sein, Big Data-Prozesse zu erstellen, zu testen und zu beheben. Darüber hinaus kann es eine große Anzahl von Konfigurationseinstellungen über mehrere Systeme hinweg geben, die verwendet werden müssen, um die Leistung zu optimieren.
- Skillset. Viele Big Data-Technologien sind hoch spezialisiert und verwenden Frameworks und Sprachen, die nicht typisch für allgemeinere Anwendungsarchitekturen sind. Andererseits entwickeln Big Data-Technologien neue APIs, die auf etablierten Sprachen aufbauen.
- Technologiereife. Viele der Technologien, die in Big Data verwendet werden, entwickeln sich weiter. Während sich die Kern-Hadoop-Technologien wie Hive und Spark stabilisiert haben, führen neue Technologien wie Delta oder Eisberg umfangreiche Änderungen und Verbesserungen ein. Verwaltete Dienste wie Microsoft Fabric sind im Vergleich zu anderen Azure-Diensten relativ jung und werden sich wahrscheinlich im Laufe der Zeit weiterentwickeln.
- Security. Big Data-Lösungen basieren in der Regel darauf, alle statischen Daten in einem zentralen Datensee zu speichern. Das Sichern des Zugriffs auf diese Daten kann eine Herausforderung darstellen, insbesondere, wenn die Daten von mehreren Anwendungen und Plattformen aufgenommen und genutzt werden müssen.
Bewährte Methoden
Nutzen von Parallelität. Die meisten Big Data-Verarbeitungstechnologien verteilen die Arbeitsauslastung über mehrere Verarbeitungseinheiten. Dies erfordert, dass statische Datendateien erstellt und in einem geteilten Format gespeichert werden. Verteilte Dateisysteme wie HDFS können die Lese- und Schreibleistung optimieren und die tatsächliche Verarbeitung wird von mehreren Clusterknoten parallel durchgeführt, wodurch die Gesamtarbeitszeiten reduziert werden. Die Verwendung von aufspaltbaren Datenformaten wird dringend empfohlen, z. B. Parkett.
Partitionsdaten. Die Batchverarbeitung erfolgt in der Regel in einem terminserien Zeitplan , z. B. wöchentlich oder monatlich. Partitionieren von Datendateien und Datenstrukturen wie Tabellen basierend auf zeitlichen Zeiträumen, die dem Verarbeitungszeitplan entsprechen. Dies vereinfacht die Datenaufnahme und Auftragsplanung und erleichtert das Beheben von Fehlern. Außerdem können Partitionierungstabellen, die in Hive-, Spark- oder SQL-Abfragen verwendet werden, die Abfrageleistung erheblich verbessern.
Anwenden von Schema-on-Read-Semantik. Mithilfe eines Data Lake können Sie den Speicher für Dateien in mehreren Formaten kombinieren, ob strukturiert, halbstrukturiert oder unstrukturiert. Verwenden Sie Schema-on-Read- Semantik, die ein Schema auf die Daten projizieren, wenn die Daten verarbeitet werden, und nicht, wenn die Daten gespeichert werden. Dies schafft Flexibilität in der Lösung und verhindert Engpässe bei der Datenaufnahme, die durch die Datenüberprüfung und Typüberprüfung verursacht werden.
Verarbeiten von Daten. Herkömmliche BI-Lösungen verwenden häufig einen Extrakt-, Transformations- und Ladeprozess (ETL), um Daten in ein Data Warehouse zu verschieben. Bei größeren Volumes und einer größeren Vielfalt von Formaten verwenden Big Data-Lösungen im Allgemeinen Variationen von ETL, z. B. Transformieren, Extrahieren und Laden (TEL). Bei diesem Ansatz werden die Daten innerhalb des verteilten Datenspeichers verarbeitet und in die erforderliche Struktur transformiert, bevor die transformierten Daten in einen analytischen Datenspeicher verschoben werden.
Ausgeglichene Auslastung und Zeitkosten. Bei Batchverarbeitungsaufträgen ist es wichtig, zwei Faktoren zu berücksichtigen: die Kosten pro Einheit der Computeknoten und die Kosten pro Minute für die Verwendung dieser Knoten zum Abschließen des Auftrags. Beispielsweise kann ein Batchauftrag acht Stunden mit vier Clusterknoten dauern. Es kann sich jedoch herausstellen, dass der Auftrag alle vier Knoten nur während der ersten zwei Stunden verwendet, und danach sind nur zwei Knoten erforderlich. In diesem Fall würde das Ausführen des gesamten Auftrags auf zwei Knoten die Gesamtauftragszeit erhöhen, würde dies jedoch nicht verdoppeln, sodass die Gesamtkosten geringer wären. In einigen Geschäftsszenarien kann eine längere Verarbeitungszeit den höheren Kosten für die Verwendung von nicht genutzten Clusterressourcen vorzuziehen sein.
Trennen von Ressourcen. Zielen Sie nach Möglichkeit darauf ab, Ressourcen basierend auf den Workloads zu trennen, um Szenarien wie eine Arbeitsauslastung mit allen Ressourcen zu vermeiden, während andere warten.
Orchestrierung der Datenaufnahme. In einigen Fällen können vorhandene Geschäftsanwendungen Datendateien für die Batchverarbeitung direkt in Azure Storage Blob-Container schreiben, in denen sie von nachgelagerten Diensten wie Microsoft Fabric genutzt werden können. Sie müssen jedoch häufig die Erfassung von Daten aus lokalen oder externen Datenquellen in den Datensee koordinieren. Verwenden Sie einen Orchestrierungsworkflow oder eine Pipeline, z. B. solche, die von Azure Data Factory oder Microsoft Fabric unterstützt werden, um dies in vorhersehbarer und zentral verwaltbarer Weise zu erreichen.
Bereinigung vertraulicher Daten frühzeitig. Der Datenaufnahmeworkflow sollte sensible Daten frühzeitig im Prozess berbern, um zu vermeiden, dass er im Datensee gespeichert wird.
IoT-Architektur
Internet of Things (IoT) ist eine spezialisierte Teilmenge von Big Data-Lösungen. Das folgende Diagramm zeigt eine mögliche logische Architektur für IoT. Das Diagramm hebt die Ereignisstreamingkomponenten der Architektur hervor.
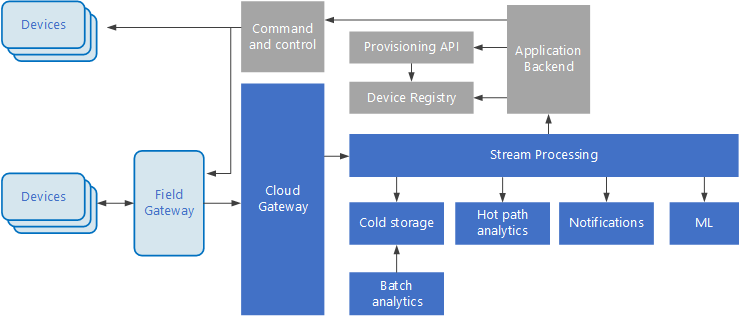
Das Cloudgateway Geräteereignisse an der Cloudgrenze aufnehmen und dabei ein zuverlässiges Messagingsystem mit geringer Latenz verwenden.
Geräte senden Ereignisse möglicherweise direkt an das Cloudgateway oder über ein Feldgateway. Ein Feldgateway ist ein spezielles Gerät oder eine spezielle Software, in der Regel mit den Geräten, die Ereignisse empfängt und an das Cloudgateway weiterleitet. Das Feldgateway kann auch die Rohgeräteereignisse vorverarbeitet und Funktionen wie Filtern, Aggregation oder Protokolltransformation ausführen.
Nach der Erfassung durchlaufen Ereignisse einen oder mehrere Datenstromprozessoren, die die Daten (z. B. an den Speicher) weiterleiten oder Analysen und andere Verarbeitungen durchführen können.
Im Folgenden finden Sie einige gängige Verarbeitungstypen. (Diese Liste ist sicherlich nicht erschöpfend.)
Schreiben von Ereignisdaten in Kaltspeicher, für Archivierungs- oder Batchanalysen.
Hot Path Analytics, Analyse des Ereignisdatenstroms in (nahezu) Echtzeit, um Anomalien zu erkennen, Muster über Rollzeitfenster zu erkennen oder Warnungen auszulösen, wenn eine bestimmte Bedingung im Datenstrom auftritt.
Behandeln spezieller Arten von Nicht-Telemetrienachrichten von Geräten, z. B. Benachrichtigungen und Alarme.
Maschinelles Lernen.
Die Felder, die grau schattiert sind, zeigen Komponenten eines IoT-Systems an, die nicht direkt mit dem Ereignisstreaming zusammenhängen, aber hier zur Vollständigkeit enthalten sind.
Die Geräteregistrierung ist eine Datenbank der bereitgestellten Geräte, einschließlich der Geräte-IDs und in der Regel Gerätemetadaten, z. B. Standort.
Die Bereitstellungs-API ist eine gemeinsame externe Schnittstelle für die Bereitstellung und Registrierung neuer Geräte.
Bei einigen IoT-Lösungen können Nachrichten an Geräte gesendet werden.
Dieser Abschnitt hat eine sehr allgemeine Ansicht von IoT vorgestellt, und es gibt viele Feinheiten und Herausforderungen zu berücksichtigen. Weitere Informationen finden Sie unter IoT-Architekturen.
Nächste Schritte
- Erfahren Sie mehr über Big Data-Architekturen.
- Erfahren Sie mehr über IoT-Architekturen.