Überwachen der Qualität und Tokennutzung bereitgestellter Prompt Flow-Anwendungen
Wichtig
Die in diesem Artikel markierten Elemente (Vorschau) sind aktuell als öffentliche Vorschau verfügbar. Diese Vorschauversion wird ohne Vereinbarung zum Servicelevel bereitgestellt und sollte nicht für Produktionsworkloads verwendet werden. Manche Features werden möglicherweise nicht unterstützt oder sind nur eingeschränkt verwendbar. Weitere Informationen finden Sie unter Zusätzliche Nutzungsbestimmungen für Microsoft Azure-Vorschauen.
Das Überwachen von Anwendungen, die in der Produktion bereitgestellt werden, ist ein wesentlicher Bestandteil des Lebenszyklus von Anwendungen mit generativer KI. Änderungen an Daten und Consumerverhalten können Ihre Anwendung im Laufe der Zeit beeinflussen, was zu veralteten Systemen führt, die sich negativ auf die Geschäftsergebnisse auswirken und Organisationen Compliance-, Wirtschafts- und Reputationsrisiken aussetzen.
Hinweis
Um eine verbesserte Möglichkeit zur kontinuierlichen Überwachung bereitgestellter Anwendungen (außer prompt flow) durchzuführen, sollten Sie die Verwendung der Azure KI-Onlinebewertung in Betracht ziehen.
Die Azure KI-Überwachung für Anwendungen mit generativer KI ermöglicht es Ihnen, Ihre Anwendungen in der Produktion im Hinblick auf die Tokennutzung, die Generierungsqualität und die betriebstechnischen Metriken zu überwachen.
Integrationen für die Überwachung einer Prompt Flow-Bereitstellung ermöglichen Folgendes:
- Erfassen von Produktionsrückschlussdaten aus Ihrer bereitgestellten Prompt Flow-Anwendung.
- Anwenden von Auswertungsmetriken für verantwortungsvolle KI wie Groundedness, Kohärenz, Fluss und Relevanz, die mit Prompt Flow-Auswertungsmetriken interoperabel sind.
- Überwachen von Prompts, Vervollständigung und Gesamttokennutzung in jeder Modellbereitstellung in Ihrem Prompt Flow.
- Überwachen von betriebstechnischen Metriken, z. B. Anforderungsanzahl, Latenz und Fehlerrate.
- Verwenden von vorkonfigurierten Warnungen und Standardwerten für die Ausführung der Überwachung auf wiederkehrender Basis.
- Nutzen von Datenvisualisierungen und Konfigurieren von komplexem Verhalten im Azure KI Foundry-Portal.
Voraussetzungen
Stellen Sie vor dem Ausführen der Schritte in diesem Artikel sicher, dass Sie über die folgenden erforderlichen Komponenten verfügen:
Ein Azure-Abonnement mit einer gültigen Zahlungsmethode. Kostenlose Abonnements oder Testabonnements für Azure werden für dieses Szenario nicht unterstützt. Wenn Sie noch kein Azure-Abonnement haben, erstellen Sie zunächst ein kostenpflichtiges Azure-Konto.
Ein Prompt Flow, der für die Bereitstellung bereit ist. Wenn Sie keinen haben, lesen Sie den Artikel zum Entwickeln eines Prompt Flow.
Die rollenbasierten Zugriffssteuerungen in Azure (Azure RBAC) werden verwendet, um Zugriff auf Vorgänge im Azure KI Foundry-Portal zu gewähren. Um die Schritte in diesem Artikel auszuführen, muss Ihrem Benutzerkonto die Azure KI-Entwicklerrolle in der Ressourcengruppe zugewiesen sein. Weitere Informationen zu Berechtigungen finden Sie unter Rollenbasierte Zugriffssteuerung im Azure KI Foundry-Portal.
Anforderungen für das Überwachen von Metriken
Überwachungsmetriken werden durch bestimmte moderne GPT-Sprachmodelle generiert, die mit spezifischen Auswertungsanweisungen (Promptvorlagen) konfiguriert sind. Diese Modelle dienen als Auswertungsmodelle für Sequenz-zu-Sequenz-Vorgänge. Diese Technik zum Generieren von Überwachungsmetriken liefert im Vergleich zu standardmäßigen generativen KI-Auswertungsmetriken aussagekräftige empirische Ergebnisse und hat eine hohe Korrelation mit dem menschlichen Urteilsvermögen. Weitere Informationen zur Prompt Flow-Auswertung finden Sie unter Übermitteln von Massentests und Auswerten eines Flows und Auswertung und Überwachung von Metriken für generative KI.
Die folgenden GPT-Modelle generieren Überwachungsmetriken. Diese GPT-Modelle werden durch Überwachung unterstützt und als Ihre Azure OpenAI-Ressource konfiguriert:
- GPT-3.5-Turbo
- GPT-4
- GPT-4-32k
Unterstützte Metriken für die Überwachung
Folgende Metriken werden für die Überwachung unterstützt:
| Metrik | Beschreibung |
|---|---|
| Quellenübereinstimmung | Wertet aus, wie gut die vom Modell generierten Antworten mit den Informationen aus den Quelldaten (benutzerdefinierter Kontext) zusammenpassen. |
| Relevance | Misst das Ausmaß, in dem die vom Modell generierten Antworten relevant sind und in direktem Zusammenhang mit den gestellten Fragen stehen. |
| Kohärenz | Misst, inwieweit die generierten Antworten des Modells logisch konsistent und miteinander verbunden sind. |
| Geläufigkeit | Bewertet die grammatikalische Korrektheit der vorhergesagten Antwort einer generativen KI. |
Spaltennamenzuordnung
Beim Erstellen des Flows müssen Sie sicherstellen, dass die Spaltennamen zugeordnet sind. Es werden die folgenden Spaltennamen für Eingabedaten verwendet, um die Qualität der Erzeugungssicherheit und -qualität zu messen:
| Name der Eingabespalte | Definition | Erforderlich/Optional |
|---|---|---|
| Frage | Der ursprüngliche Prompt (auch als „Eingaben“ oder „Frage“ bezeichnet) | Erforderlich |
| Antwort | Die endgültige Vervollständigung des zurückgegebenen API-Aufrufs (auch als „Ausgaben“ oder „Antwort“ bezeichnet) | Erforderlich |
| Kontext | Alle Kontextdaten, die zusammen mit dem ursprünglichen Prompt an den API-Aufruf gesendet werden. Wenn Sie beispielsweise nur Suchergebnisse von bestimmten zertifizierten Informationsquellen/Websites erhalten möchten, können Sie diesen Kontext in den Auswertungsschritten definieren. | Optional |
Für Metriken erforderliche Parameter
Welche Parameter in Ihrer Datenressource konfiguriert sind, bestimmt, welche Metriken Sie gemäß dieser Tabelle erstellen können:
| Metrik | Frage | Antwort | Kontext |
|---|---|---|---|
| Kohärenz | Erforderlich | Erforderlich | - |
| Geläufigkeit | Erforderlich | Erforderlich | - |
| Quellenübereinstimmung | Erforderlich | Erforderlich | Erforderlich |
| Relevance | Erforderlich | Erforderlich | Erforderlich |
Weitere Informationen zu den spezifischen Datenzuordnungsanforderungen für jede Metrik finden Sie unter Anforderungen für Abfrage- und Antwortmetriken.
Einrichten der Überwachung für den Promptflow
Um die Überwachung für Ihre Prompt Flow-Anwendung einzurichten, müssen Sie die Prompt Flow-Anwendung zuerst mit der Rückschlussdatensammlung bereitstellen. Dann können Sie die Überwachung für die bereitgestellte Anwendung konfigurieren.
Bereitstellen der Prompt Flow-Anwendung mit Rückschlussdatensammlung
In diesem Abschnitt erfahren Sie, wie Sie Ihren Prompt Flow mit aktivierter Rückschlussdatensammlung bereitstellen. Ausführliche Informationen zum Bereitstellen des Prompt Flow finden Sie unter Bereitstellen eines Flow für echtzeitbasierte Rückschlüsse.
Melden Sie sich bei Azure KI Foundry an.
Wenn Sie sich noch nicht in Ihrem Projekt befinden, wählen Sie es aus.
Wählen Sie prompt flow aus der linken Navigationsleiste aus.
Wählen Sie den zuvor erstellten Prompt Flow aus.
Hinweis
In diesem Artikel wird davon ausgegangen, dass Sie bereits einen Prompt Flow erstellt haben, der für die Bereitstellung bereit ist. Wenn Sie keinen haben, lesen Sie den Artikel zum Entwickeln eines Prompt Flow.
Vergewissern Sie sich, dass ihr Flow erfolgreich ausgeführt wird und die erforderlichen Eingaben und Ausgaben für die auszuwertenden Metriken konfiguriert sind.
Das Bereitstellen der minimal erforderlichen Parameter (Fragen/Eingaben und Antwort/Ausgaben) bietet nur zwei Metriken: Kohärenz und Fluss. Sie müssen Ihren Flow wie im Abschnitt zu Anforderungen für Überwachungsmetriken beschrieben konfigurieren. In diesem Beispiel werden
question(Frage) undchat_history(Kontext) als Floweingaben verwendet, undanswer(Antwort) als Flowausgabe.Wählen Sie Bereitstellen aus, um mit der Bereitstellung Ihres Flows zu beginnen.
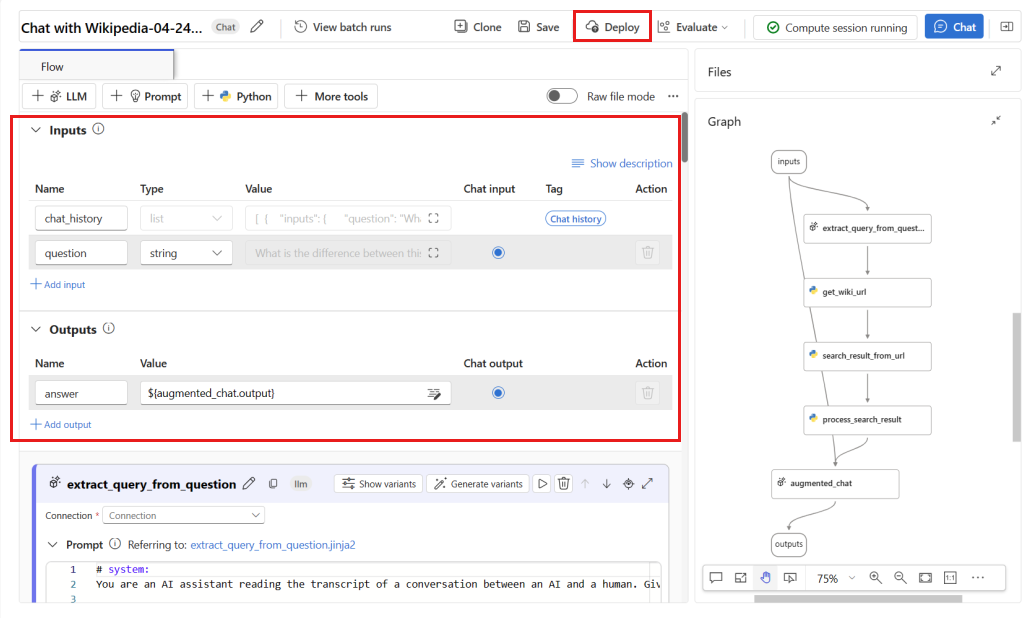
Stellen Sie im Bereitstellungsfenster sicher, dass Inferencing data collection aktiviert ist, wodurch die Daten Ihrer Anwendung nahtlos in Blob Storage erfasst werden. Diese Datensammlung ist für die Überwachung erforderlich.
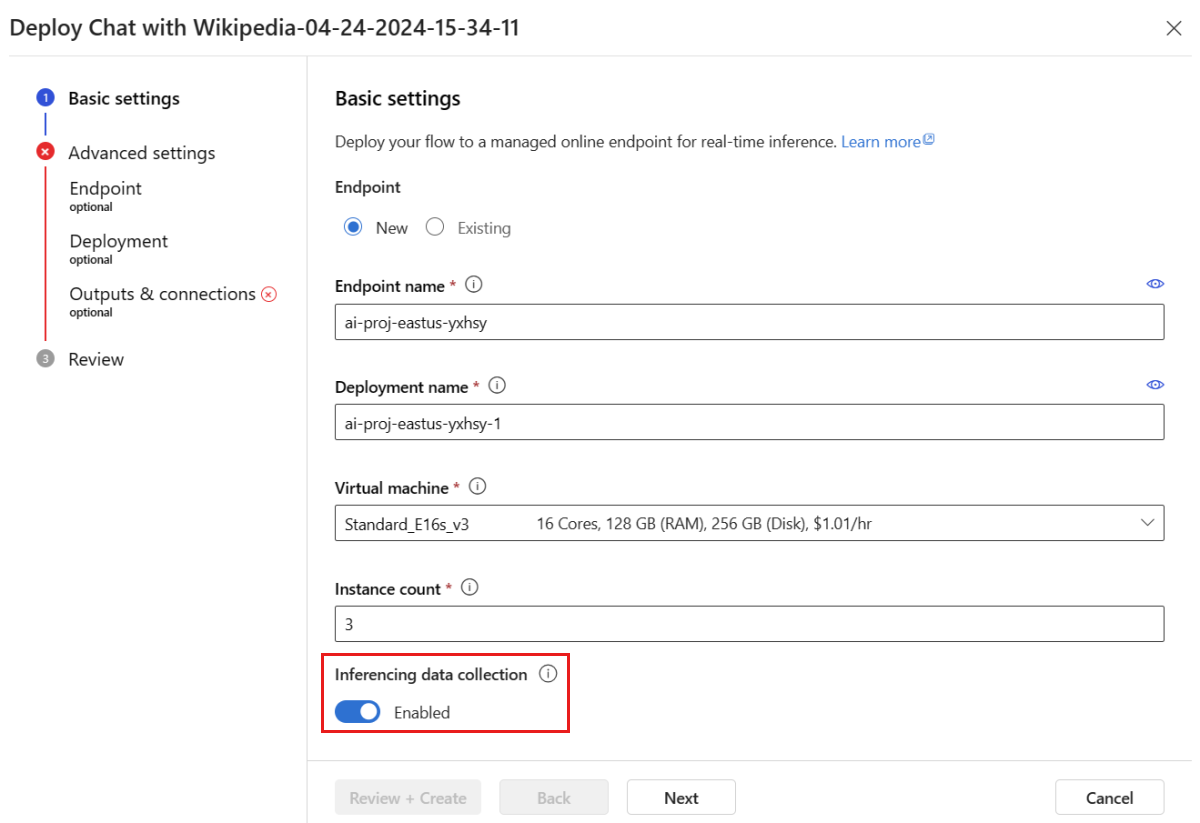
Führen Sie die Schritte im Bereitstellungsfenster aus, um die erweiterten Einstellungen festzulegen.
Überprüfen Sie auf der Seite „Überprüfung“ die Bereitstellungskonfiguration, und wählen Sie Erstellen aus, um Ihren Flow bereitzustellen.
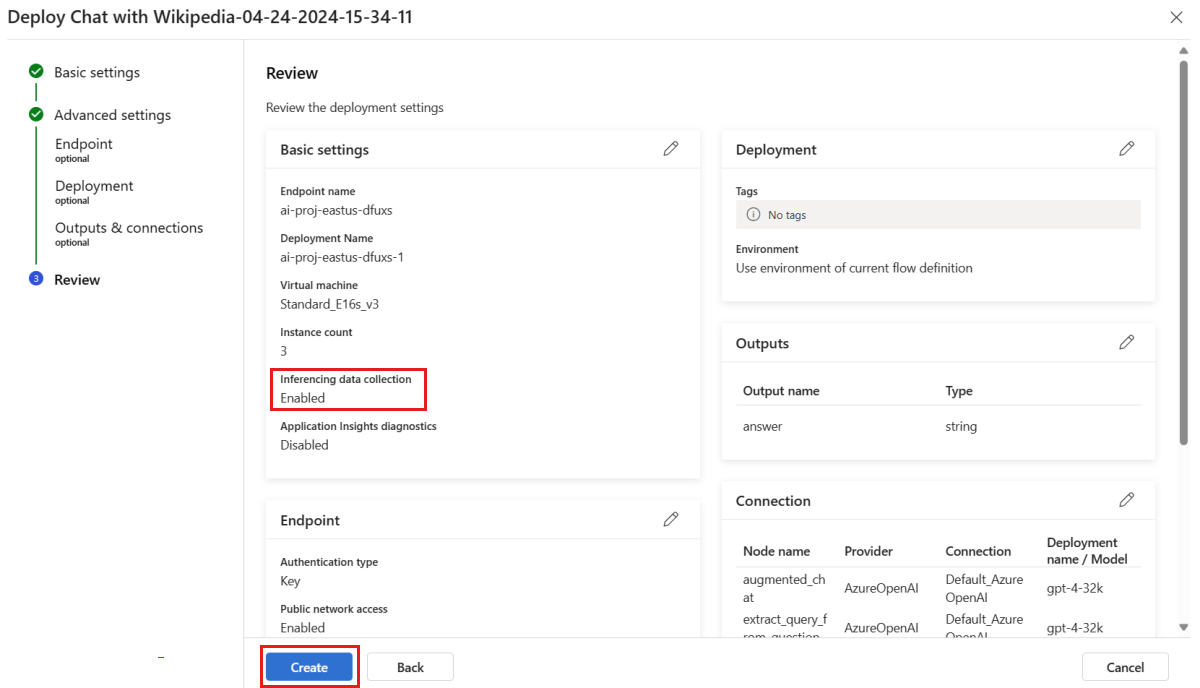
Hinweis
Standardmäßig werden alle Eingaben und Ausgaben Ihrer bereitgestellten Prompt Flow-Anwendung in Ihrem Blob Storage erfasst. Wenn die Bereitstellung von Benutzern aufgerufen wird, werden die Daten gesammelt, die von Ihrem Monitor verwendet werden.
Wählen Sie auf der Bereitstellungsseite die Registerkarte Test aus, und testen Sie die Bereitstellung, um sicherzustellen, dass sie ordnungsgemäß funktioniert.
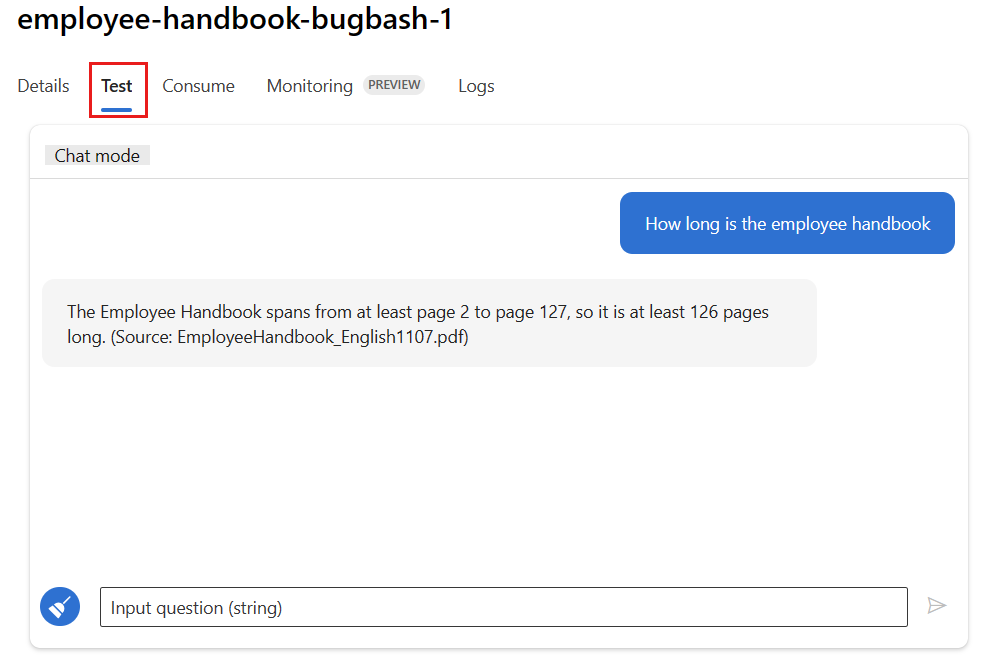
Hinweis
Die Überwachung erfordert, dass mindestens ein Datenpunkt aus einer anderen Quelle als der Registerkarte Test in der Bereitstellung stammt. Wir empfehlen die Verwendung der REST-API, die auf der Registerkarte Consume verfügbar ist, um Beispielanforderungen an Ihre Bereitstellung zu senden. Weitere Informationen zum Senden von Beispielanforderungen an Ihre Bereitstellung finden Sie unter Erstellen einer Online-Bereitstellung.




Konfigurieren der Überwachung
In diesem Abschnitt erfahren Sie, wie Sie die Überwachung für Ihre bereitgestellte Prompt Flow-Anwendung konfigurieren.
Wechseln Sie auf der linken Navigationsleiste zu Meine Ressource>Modelle + Endpunkte.
Wählen Sie die erstellte prompt flow-Bereitstellung aus.
Wählen Sie Enable im Feld Enable generation quality monitoring aus.
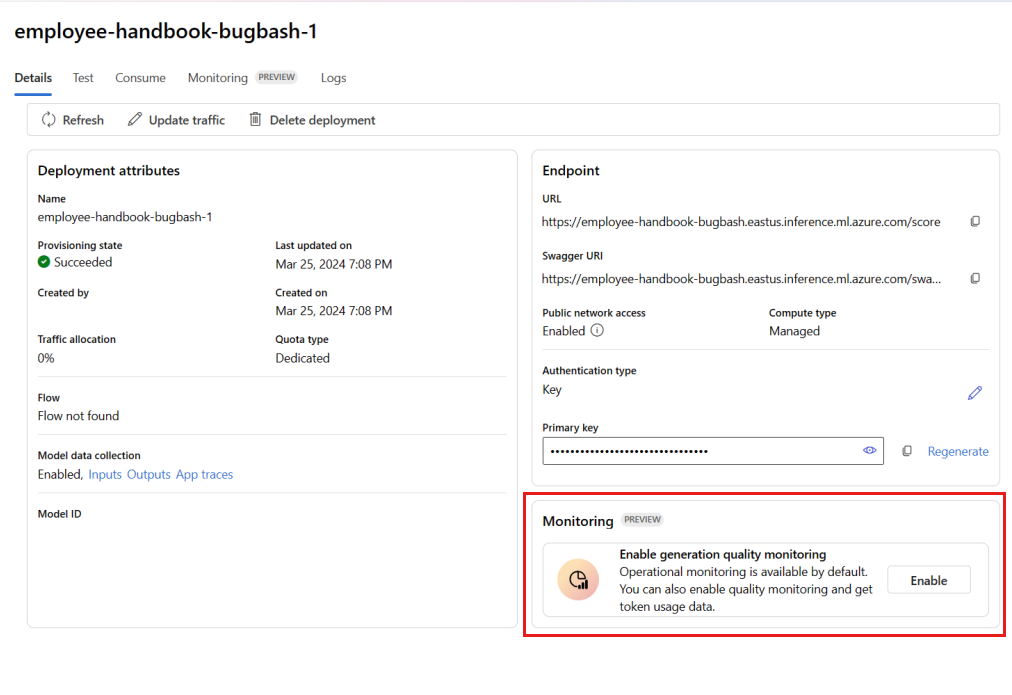
Beginnen Sie mit der Konfiguration der Überwachung, indem Sie die gewünschten Metriken auswählen.
Vergewissern Sie sich, dass die Spaltennamen aus dem Flow zugeordnet sind, wie in Spaltennamenzuordnung definiert.
Wählen Sie die Azure OpenAI-Verbindung und Bereitstellung aus, die Sie verwenden möchten, um die Überwachung für Ihre Prompt Flow-Anwendung auszuführen.
Wählen Sie Erweiterte Optionen aus, um weitere zu konfigurierende Optionen anzuzeigen.
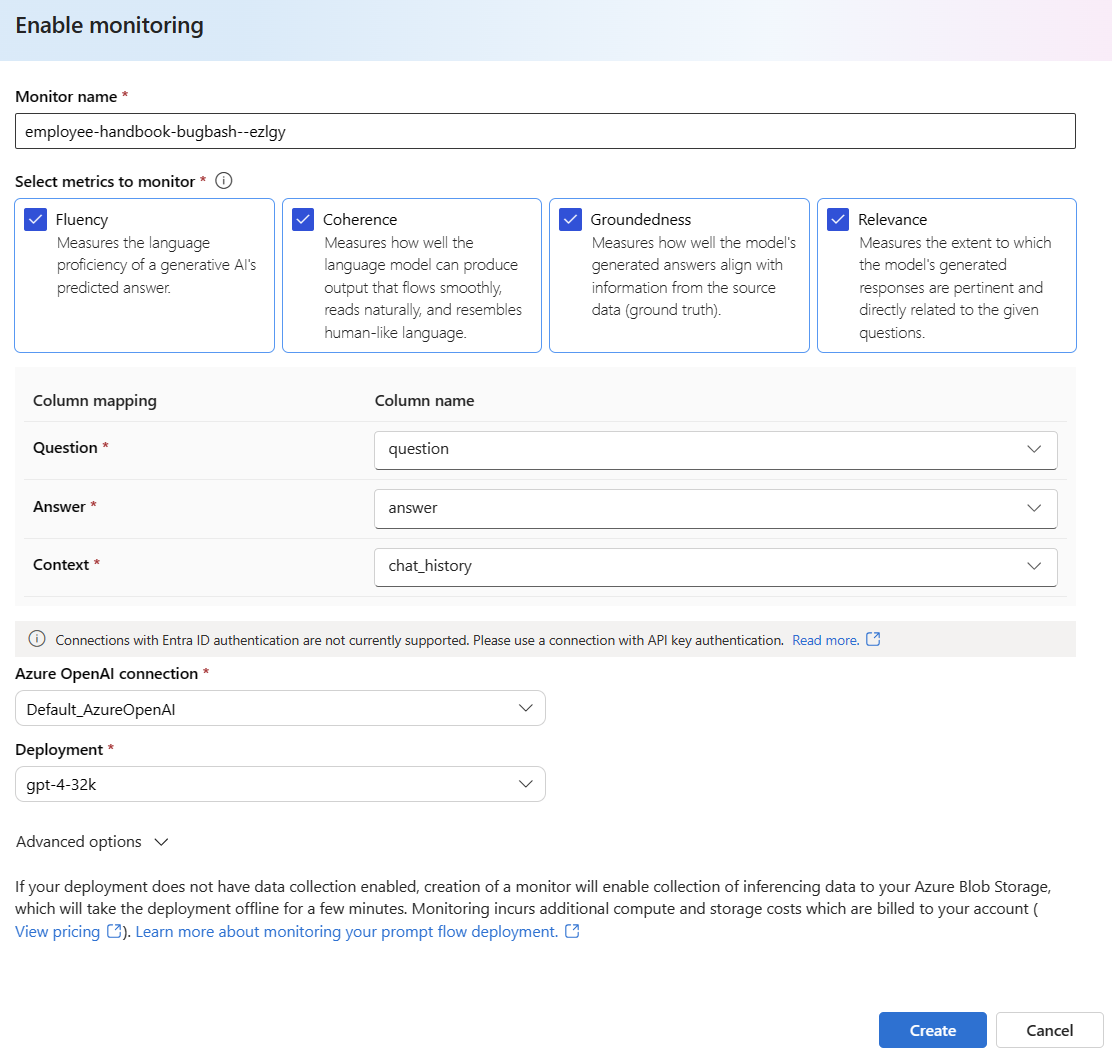
Passen Sie die Stichprobenrate und Schwellenwerte für Ihre konfigurierten Metriken an, und geben Sie die E-Mail-Adressen an, die Warnungen erhalten sollen, wenn die durchschnittliche Bewertung für eine bestimmte Metrik unter den Schwellenwert fällt.

Hinweis
Wenn für Ihre Bereitstellung keine Datensammlung aktiviert ist, ermöglicht die Erstellung eines Monitors die Erfassung von Rückschlussdaten in Azure Blob Storage, wodurch die Bereitstellung einige Minuten lang offline ist.
Wählen Sie Erstellen aus, um den Monitor zu erstellen.



Nutzen von Überwachungsergebnissen
Nachdem Sie Ihren Monitor erstellt haben, wird er täglich ausgeführt, um die Metriken zu Tokennutzung und Generierungsqualität zu berechnen.
Wechseln Sie in der Bereitstellung zur Registerkarte Überwachung (Vorschau), um die Überwachungsergebnisse anzuzeigen. Hier sehen Sie eine Übersicht über die Überwachungsergebnisse während des ausgewählten Zeitfensters. Sie können die Datumsauswahl verwenden, um das Zeitfenster der Daten zu ändern, die Sie überwachen. In dieser Übersicht sind die folgenden Metriken verfügbar:
- Total request count: Die Gesamtanzahl der Anforderungen, die während des ausgewählten Zeitfensters an die Bereitstellung gesendet wurden.
- Total token count: Die Gesamtanzahl der Token, die während des ausgewählten Zeitfensters von der Bereitstellung verwendet wurden.
- Prompt token count: Die Anzahl der Prompttoken, die während des ausgewählten Zeitfensters von der Bereitstellung verwendet wurden.
- Completion token count: Die Anzahl der Vervollständigungstoken, die während des ausgewählten Zeitfensters von der Bereitstellung verwendet wurden.
Zeigen Sie die Metriken auf der Registerkarte Tokennutzung an (diese Registerkarte ist standardmäßig ausgewählt). Hier können Sie die Tokennutzung Ihrer Anwendung im Laufe der Zeit anzeigen. Sie können auch die Verteilung von Prompt- und Vervollständigungstoken im Laufe der Zeit anzeigen. Sie können den Trendlinienbereich ändern, um alle Token in der gesamten Anwendung oder die Tokennutzung für eine bestimmte Bereitstellung (z. B. gpt-4) zu überwachen, die in Ihrer Anwendung verwendet wird.

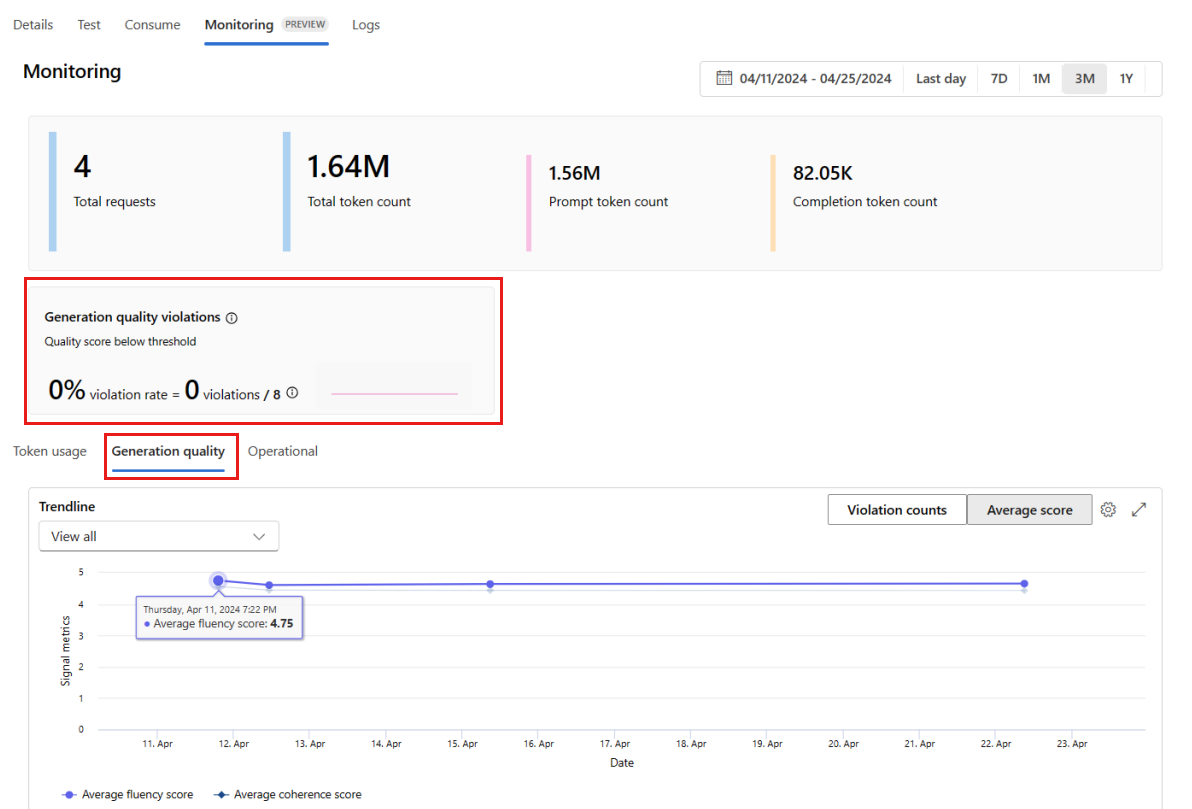
Wechseln Sie zur Registerkarte Generation quality, um die Qualität Ihrer Anwendung im Laufe der Zeit zu überwachen. Die folgenden Metriken werden im Zeitdiagramm angezeigt:
- Verletzungsanzahl: Die Anzahl der Verletzungen für eine angegebene Metrik (z. B. Fluss) ist die Summe der Verletzungen über das ausgewählte Zeitfenster. Eine Verletzung tritt für eine Metrik auf, wenn die Metriken berechnet werden (standardmäßig täglich) und der berechnete Wert für die Metrik unter den festgelegten Schwellenwert fällt.
- Average score: Die durchschnittliche Bewertung für eine angegebene Metrik (z. B. Fluss) ist die Summe der Bewertungen für alle Instanzen (oder Anforderungen), dividiert durch die Anzahl der Instanzen (oder Anforderungen) über das ausgewählte Zeitfenster.
Die Karte Generation quality violations zeigt die Verletzungsrate über das ausgewählte Zeitfenster an. Die Verletzungsrate ist die Anzahl der Verletzungen dividiert durch die Gesamtzahl möglicher Verletzungen. Sie können die Schwellenwerte für Metriken in den Einstellungen anpassen. Standardmäßig werden Metriken täglich berechnet. Diese Häufigkeit kann auch in den Einstellungen angepasst werden.
Auf der Registerkarte Überwachung (Vorschau) können Sie auch eine umfassende Tabelle aller geprüften Anforderungen anzeigen, die während des ausgewählten Zeitfensters an die Bereitstellung gesendet wurden.
Hinweis
Die Überwachung legt die Standardstichprobenrate auf 10 % fest. Dies bedeutet, dass bei 100 an Ihre Bereitstellung gesendeten Anforderungen 10 als Stichprobe genommen und verwendet werden, um die Qualitätsmetriken für die Generierung zu berechnen. Sie können die Stichprobenrate in den Einstellungen anpassen.
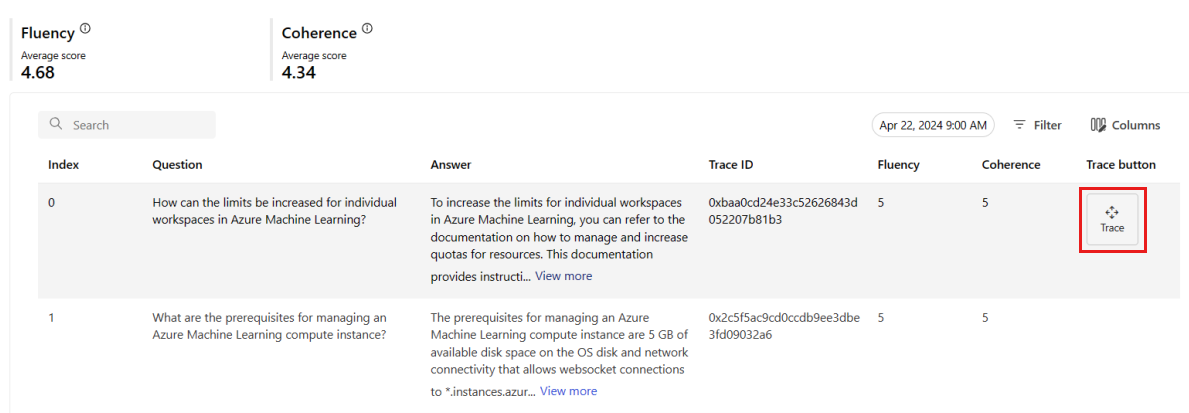
Wählen Sie auf der rechten Seite einer Zeile in der Tabelle die Schaltfläche Überwachung aus, um Ablaufverfolgungsdetails für eine bestimmte Anforderung anzuzeigen. Diese Ansicht enthält umfassende Ablaufverfolgungsdetails für die Anforderung an Ihre Anwendung.
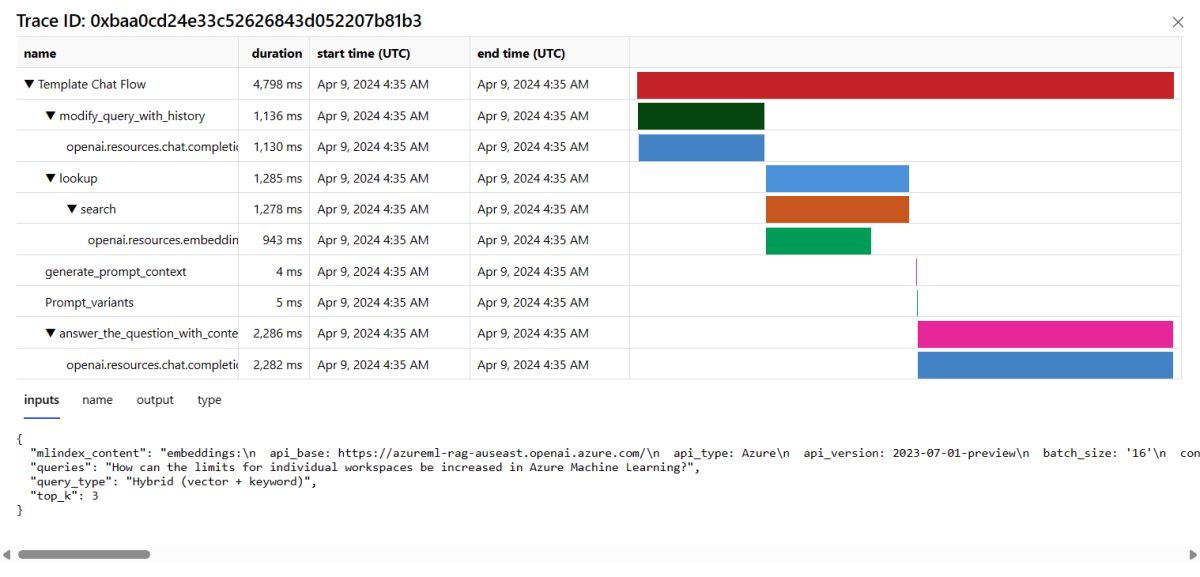
Schließen Sie die Ablaufverfolgungsansicht.
Wechseln Sie zur Registerkarte Operational, um die Betriebsmetriken für die Bereitstellung in Quasi-Echtzeit anzuzeigen. Wir unterstützen die folgenden betriebsbezogenen Metriken:
- Anforderungsanzahl
- Latency
- Fehlerrate





Die Ergebnisse auf der Registerkarte Überwachung (Vorschau) Ihrer Bereitstellung bieten Einblicke, die Ihnen helfen, die Leistung Ihrer Prompt Flow-Anwendung proaktiv zu verbessern.
Erweiterte Überwachungskonfiguration mit SDK v2
Die Überwachung unterstützt auch erweiterte Konfigurationsoptionen mit dem SDK v2. Die folgenden Szenarien werden unterstützt:
Aktivieren der Überwachung auf Tokennutzung
Wenn Sie nur die Überwachung der Tokennutzung für Ihre bereitgestellte Prompt Flow-Anwendung aktivieren möchten, können Sie das folgende Skript an Ihr Szenario anpassen:
from azure.ai.ml import MLClient
from azure.ai.ml.entities import (
MonitorSchedule,
CronTrigger,
MonitorDefinition,
ServerlessSparkCompute,
MonitoringTarget,
AlertNotification,
GenerationTokenStatisticsSignal,
)
from azure.ai.ml.entities._inputs_outputs import Input
from azure.ai.ml.constants import MonitorTargetTasks, MonitorDatasetContext
# Authentication package
from azure.identity import DefaultAzureCredential
credential = DefaultAzureCredential()
# Update your azure resources details
subscription_id = "INSERT YOUR SUBSCRIPTION ID"
resource_group = "INSERT YOUR RESOURCE GROUP NAME"
project_name = "INSERT YOUR PROJECT NAME" # This is the same as your Azure AI Foundry project name
endpoint_name = "INSERT YOUR ENDPOINT NAME" # This is your deployment name without the suffix (e.g., deployment is "contoso-chatbot-1", endpoint is "contoso-chatbot")
deployment_name = "INSERT YOUR DEPLOYMENT NAME"
# These variables can be renamed but it is not necessary
monitor_name ="gen_ai_monitor_tokens"
defaulttokenstatisticssignalname ="token-usage-signal"
# Determine the frequency to run the monitor, and the emails to recieve email alerts
trigger_schedule = CronTrigger(expression="15 10 * * *")
notification_emails_list = ["test@example.com", "def@example.com"]
ml_client = MLClient(
credential=credential,
subscription_id=subscription_id,
resource_group_name=resource_group,
workspace_name=project_name,
)
spark_compute = ServerlessSparkCompute(instance_type="standard_e4s_v3", runtime_version="3.3")
monitoring_target = MonitoringTarget(
ml_task=MonitorTargetTasks.QUESTION_ANSWERING,
endpoint_deployment_id=f"azureml:{endpoint_name}:{deployment_name}",
)
# Create an instance of token statistic signal
token_statistic_signal = GenerationTokenStatisticsSignal()
monitoring_signals = {
defaulttokenstatisticssignalname: token_statistic_signal,
}
monitor_settings = MonitorDefinition(
compute=spark_compute,
monitoring_target=monitoring_target,
monitoring_signals = monitoring_signals,
alert_notification=AlertNotification(emails=notification_emails_list),
)
model_monitor = MonitorSchedule(
name = monitor_name,
trigger=trigger_schedule,
create_monitor=monitor_settings
)
ml_client.schedules.begin_create_or_update(model_monitor)
Aktivieren der Überwachung der Qualität der Generierung
Wenn Sie nur die Überwachung der Generierungsqualität für Ihre bereitgestellte Prompt Flow-Anwendung aktivieren möchten, können Sie das folgende Skript an Ihr Szenario anpassen:
from azure.ai.ml import MLClient
from azure.ai.ml.entities import (
MonitorSchedule,
CronTrigger,
MonitorDefinition,
ServerlessSparkCompute,
MonitoringTarget,
AlertNotification,
GenerationSafetyQualityMonitoringMetricThreshold,
GenerationSafetyQualitySignal,
BaselineDataRange,
LlmData,
)
from azure.ai.ml.entities._inputs_outputs import Input
from azure.ai.ml.constants import MonitorTargetTasks, MonitorDatasetContext
# Authentication package
from azure.identity import DefaultAzureCredential
credential = DefaultAzureCredential()
# Update your azure resources details
subscription_id = "INSERT YOUR SUBSCRIPTION ID"
resource_group = "INSERT YOUR RESOURCE GROUP NAME"
project_name = "INSERT YOUR PROJECT NAME" # This is the same as your Azure AI Foundry project name
endpoint_name = "INSERT YOUR ENDPOINT NAME" # This is your deployment name without the suffix (e.g., deployment is "contoso-chatbot-1", endpoint is "contoso-chatbot")
deployment_name = "INSERT YOUR DEPLOYMENT NAME"
aoai_deployment_name ="INSERT YOUR AOAI DEPLOYMENT NAME"
aoai_connection_name = "INSERT YOUR AOAI CONNECTION NAME"
# These variables can be renamed but it is not necessary
app_trace_name = "app_traces"
app_trace_Version = "1"
monitor_name ="gen_ai_monitor_generation_quality"
defaultgsqsignalname ="gsq-signal"
# Determine the frequency to run the monitor, and the emails to recieve email alerts
trigger_schedule = CronTrigger(expression="15 10 * * *")
notification_emails_list = ["test@example.com", "def@example.com"]
ml_client = MLClient(
credential=credential,
subscription_id=subscription_id,
resource_group_name=resource_group,
workspace_name=project_name,
)
spark_compute = ServerlessSparkCompute(instance_type="standard_e4s_v3", runtime_version="3.3")
monitoring_target = MonitoringTarget(
ml_task=MonitorTargetTasks.QUESTION_ANSWERING,
endpoint_deployment_id=f"azureml:{endpoint_name}:{deployment_name}",
)
# Set thresholds for passing rate (0.7 = 70%)
aggregated_groundedness_pass_rate = 0.7
aggregated_relevance_pass_rate = 0.7
aggregated_coherence_pass_rate = 0.7
aggregated_fluency_pass_rate = 0.7
# Create an instance of gsq signal
generation_quality_thresholds = GenerationSafetyQualityMonitoringMetricThreshold(
groundedness = {"aggregated_groundedness_pass_rate": aggregated_groundedness_pass_rate},
relevance={"aggregated_relevance_pass_rate": aggregated_relevance_pass_rate},
coherence={"aggregated_coherence_pass_rate": aggregated_coherence_pass_rate},
fluency={"aggregated_fluency_pass_rate": aggregated_fluency_pass_rate},
)
input_data = Input(
type="uri_folder",
path=f"{endpoint_name}-{deployment_name}-{app_trace_name}:{app_trace_Version}",
)
data_window = BaselineDataRange(lookback_window_size="P7D", lookback_window_offset="P0D")
production_data = LlmData(
data_column_names={"prompt_column": "question", "completion_column": "answer", "context_column": "context"},
input_data=input_data,
data_window=data_window,
)
gsq_signal = GenerationSafetyQualitySignal(
connection_id=f"/subscriptions/{subscription_id}/resourceGroups/{resource_group}/providers/Microsoft.MachineLearningServices/workspaces/{project_name}/connections/{aoai_connection_name}",
metric_thresholds=generation_quality_thresholds,
production_data=[production_data],
sampling_rate=1.0,
properties={
"aoai_deployment_name": aoai_deployment_name,
"enable_action_analyzer": "false",
"azureml.modelmonitor.gsq_thresholds": '[{"metricName":"average_fluency","threshold":{"value":4}},{"metricName":"average_coherence","threshold":{"value":4}}]',
},
)
monitoring_signals = {
defaultgsqsignalname: gsq_signal,
}
monitor_settings = MonitorDefinition(
compute=spark_compute,
monitoring_target=monitoring_target,
monitoring_signals = monitoring_signals,
alert_notification=AlertNotification(emails=notification_emails_list),
)
model_monitor = MonitorSchedule(
name = monitor_name,
trigger=trigger_schedule,
create_monitor=monitor_settings
)
ml_client.schedules.begin_create_or_update(model_monitor)
Nachdem Sie Ihren Monitor über das SDK erstellt haben, können Sie die Überwachungsergebnisse im Azure KI Foundry-Portal nutzen.
Zugehöriger Inhalt
- Erfahren Sie mehr über die Möglichkeiten, die Ihnen Azure KI Foundry bietet.
- Erhalten Sie Antworten auf häufig gestellte Fragen im Artikel zu häufig gestellten Fragen zu Azure KI.