Schnellstart: Erkennen von Sprache und Konvertieren von Sprache in Text
Wichtig
Die in diesem Artikel markierten Elemente (Vorschau) sind aktuell als öffentliche Vorschau verfügbar. Diese Vorschauversion wird ohne Vereinbarung zum Servicelevel bereitgestellt und sollte nicht für Produktionsworkloads verwendet werden. Manche Features werden möglicherweise nicht unterstützt oder sind nur eingeschränkt verwendbar. Weitere Informationen finden Sie unter Zusätzliche Nutzungsbestimmungen für Microsoft Azure-Vorschauen.
In diesem Schnellstart probieren Sie die Spracherkennung in Echtzeit in Azure KI Foundry aus.
Voraussetzungen
- Azure-Abonnement – Erstellen eines kostenlosen Kontos
- Einige Azure KI Services-Features können Sie im Azure KI Foundry-Portal kostenlos ausprobieren. Für den Zugriff auf alle in diesem Artikel beschriebenen Funktionen müssen Sie KI-Dienste in Azure KI Foundry verbinden.
Testen der Spracherkennung in Echtzeit
Wechseln Sie zu Ihrem Azure KI Foundry-Projekt. Wenn Sie ein Projekt erstellen müssen, lesen Sie Erstellen eines Azure KI Foundry-Projekts.
Wählen Sie im linken Bereich Playgrounds aus, und wählen Sie dann einen zu verwendenden Playground aus. Wählen Sie in diesem Beispiel Speech-Playground ausprobieren aus.
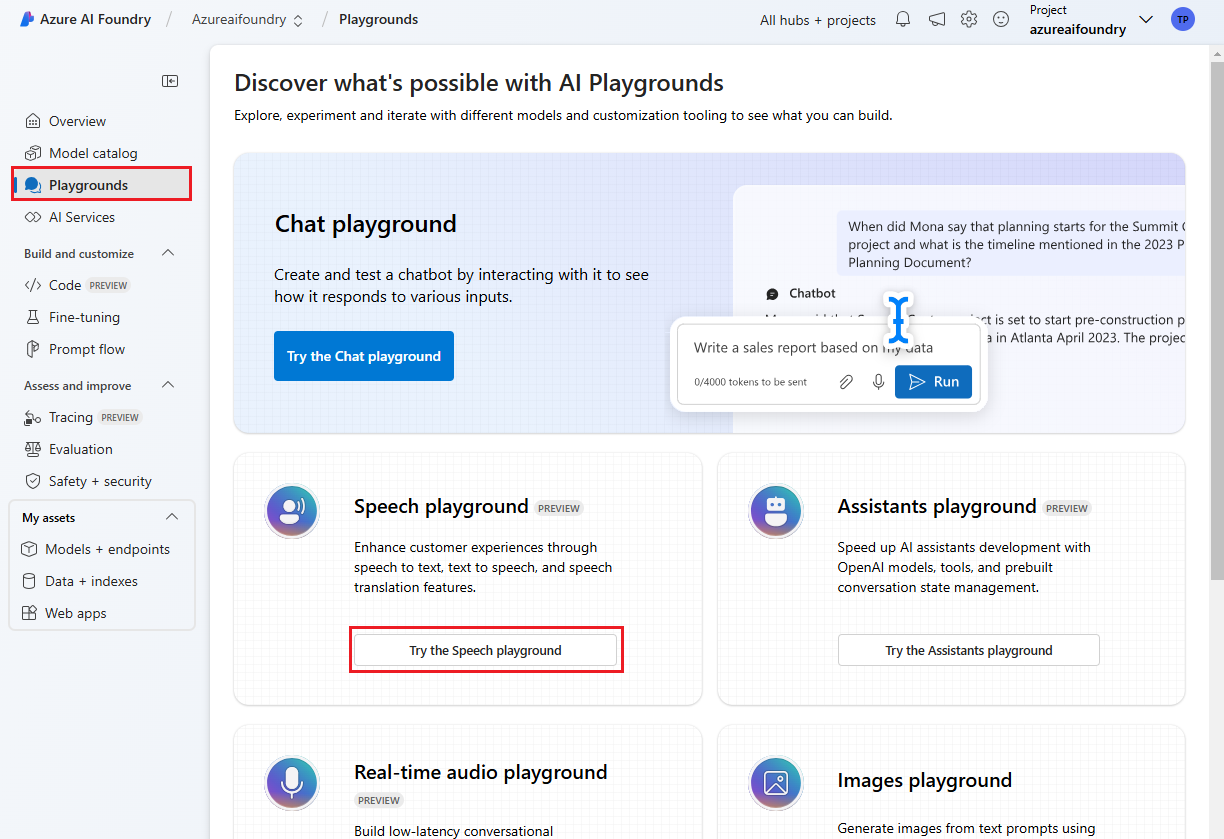
Optional können Sie eine andere Verbindung auswählen, die im Playground verwendet werden soll. Im Speech-Playground können Sie eine Verbindung mit Azure KI Services-Ressourcen mit mehreren Diensten oder Speech-Dienstressourcen herstellen.
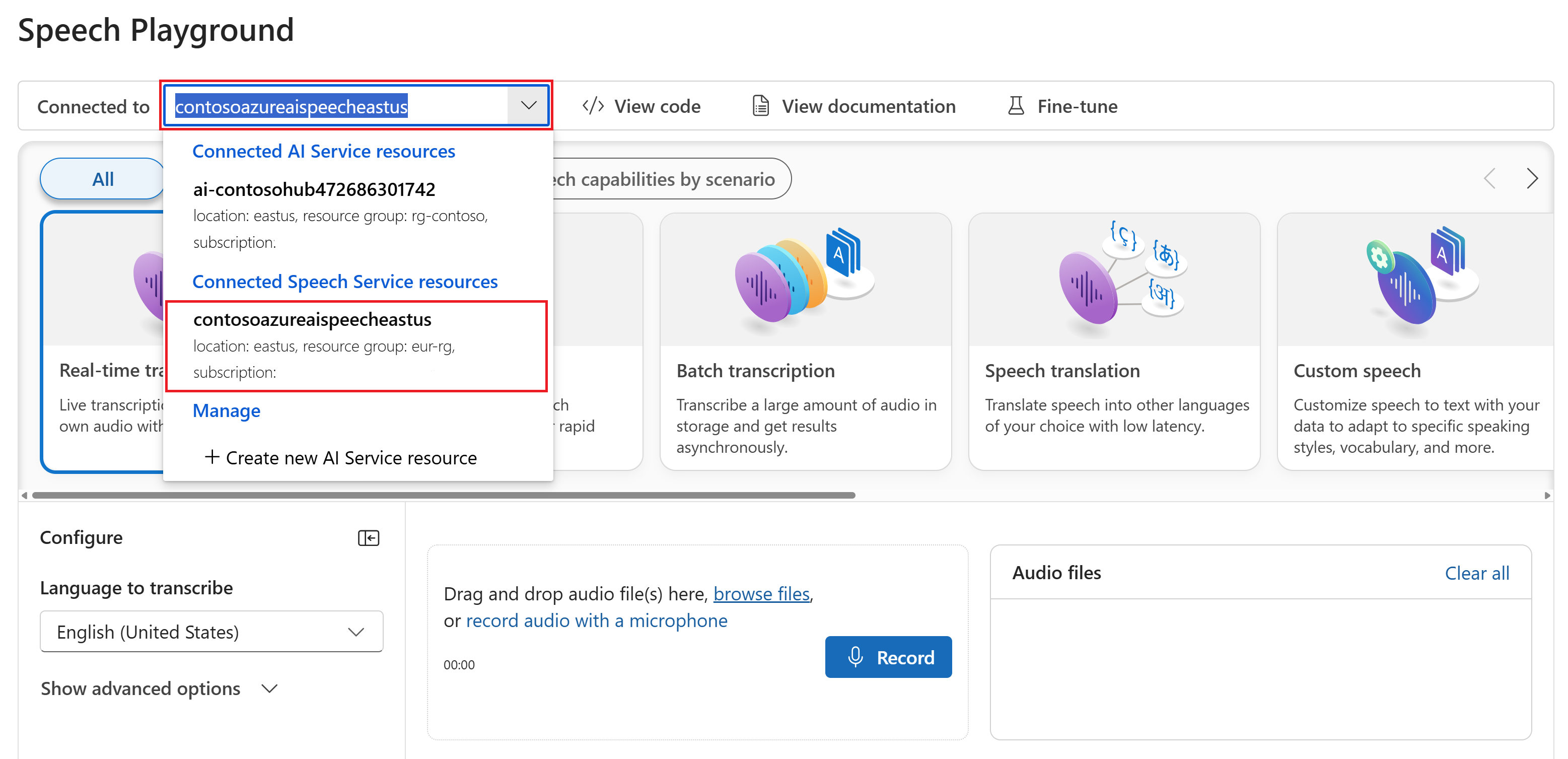
Wählen Sie Echtzeittranskription aus.
Wählen Sie Erweiterte Optionen anzeigen aus, um Spracherkennungsoptionen wie die folgenden zu konfigurieren:
- Spracherkennung: wird verwendet, um anhand einer Liste unterstützter Sprachen die in der Audioquelle gesprochenen Sprachen zu identifizieren. Weitere Informationen zu den Optionen für Spracherkennung wie Erkennung beim Start und kontinuierliche Erkennung finden Sie unter Spracherkennung.
- Sprecherdiarisierung: wird verwendet, um Sprecher in Audio zu identifizieren und zu trennen. Die Diarisierung unterscheidet zwischen den verschiedenen Sprechern, die an der Unterhaltung teilnehmen. Der Speech-Dienst stellt Informationen darüber bereit, welcher Sprecher einen bestimmten Teil der transkribierten Sprache sprach. Weitere Informationen zur Diarisierung von Sprechern finden Sie in der Schnellstartanleitung Spracherkennung in Echtzeit mit Sprecherdiarisierung.
- Benutzerdefinierter Endpunkt: Verwenden Sie ein bereitgestelltes Modell aus benutzerdefinierter Sprache, um die Erkennungsgenauigkeit zu verbessern. Um das Basismodell von Microsoft zu verwenden, behalten Sie die Einstellung „Keine“ bei. Weitere Informationen zu benutzerdefinierter Sprache finden Sie unter Custom Speech.
- Ausgabeformat: Wählen Sie zwischen einfachen und detaillierten Ausgabeformaten aus. Die einfache Ausgabe umfasst Anzeigeformat und Zeitstempeln. Die detaillierte Ausgabe enthält weitere Formate (z. B. Anzeige, Lexikalisch, ITN und maskierte ITN), Zeitstempel und N-beste-Listen.
- Ausdrucksliste: Verbessern Sie die Transkriptionsgenauigkeit, indem Sie eine Liste bekannter Ausdrücke bereitstellen, z. B. Namen von Personen oder bestimmten Orten. Verwenden Sie Kommas oder Semikolons, um jeden Wert in der Ausdrucksliste zu trennen. Weitere Informationen zu Ausdruckslisten finden Sie unter Ausdruckslisten.
Wählen Sie eine Audiodatei aus, die hochgeladen werden soll, oder zeichnen Sie Audio in Echtzeit auf. In diesem Beispiel verwenden wir die Datei
Call1_separated_16k_health_insurance.wav, die im Speech SDK-Repository auf GitHub verfügbar ist. Sie können die Datei herunterladen oder Ihre eigene Audiodatei verwenden.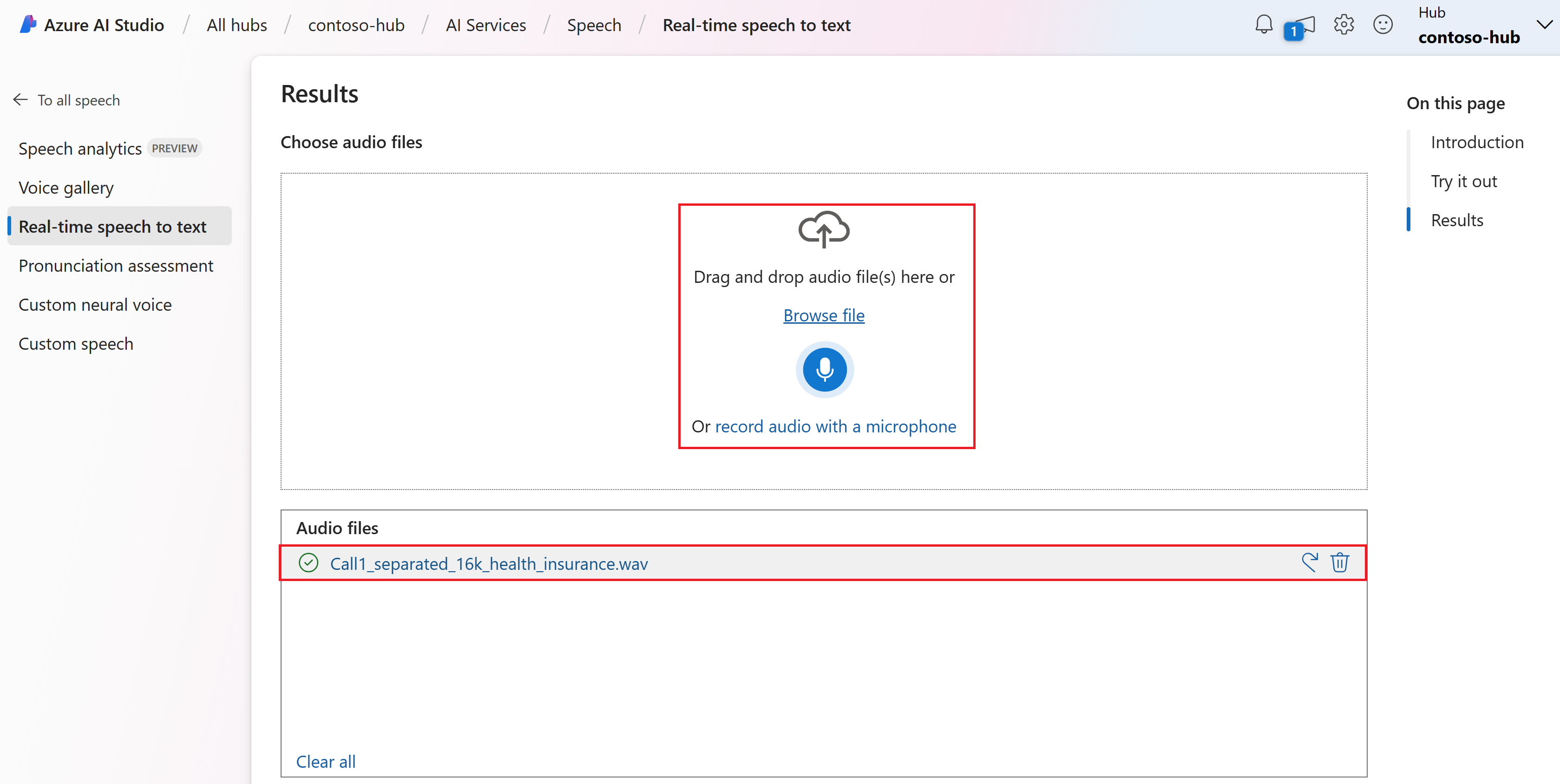
Sie können die Echtzeittranskription unten auf der Seite ansehen.

Sie können die Registerkarte JSON auswählen, um die JSON-Ausgabe der Transkription anzuzeigen. Zu den Eigenschaften zählen
Offset,Duration,RecognitionStatus,Display,Lexical,ITNund weitere.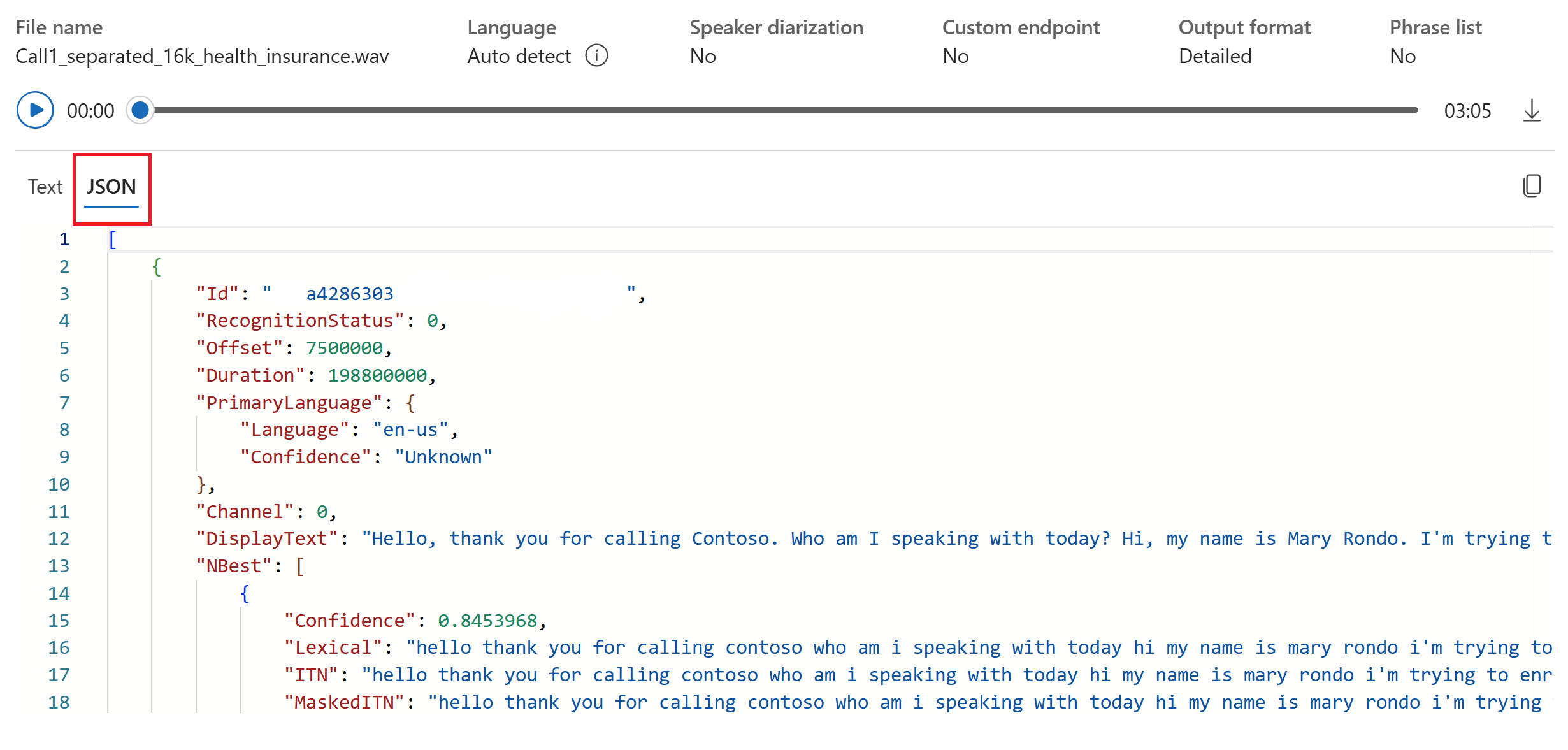





Referenzdokumentation | Paket (NuGet) | Zusätzliche Beispiele auf GitHub
In dieser Schnellstartanleitung erstellen und führen Sie eine Anwendung zum Erkennen und Transkribieren von Sprache in Text in Echtzeit aus.
Weitere Informationen zum asynchronen Transkribieren von Audiodateien finden Sie unter Was ist die Batch-Transkription?. Wenn Sie nicht sicher sind, welche Spracherkennungslösung für Sie geeignet ist, finden Sie unter Was ist Spracherkennung? weitere Informationen.
Voraussetzungen
- Ein Azure-Abonnement. Sie können ein kostenloses Konto erstellen.
- Erstellen Sie eine Speech-Ressource im Azure-Portal.
- Abrufen des Speech-Ressourcenschlüssel und des Endpunkts. Wählen Sie nach der Bereitstellung Ihrer Speech-Ressource Zu Ressource wechseln aus, um Schlüssel anzuzeigen und zu verwalten.
Einrichten der Umgebung
Das Speech SDK ist als NuGet-Paket verfügbar und implementiert .NET Standard 2.0. Sie installieren das Speech SDK weiter unten in diesem Leitfaden. Alle weiteren Anforderungen finden Sie unter Installieren des Speech SDK.
Festlegen von Umgebungsvariablen
Sie müssen Ihre Anwendung authentifizieren, um auf Azure KI Services zuzugreifen. In diesem Artikel wird erläutert, wie Sie Umgebungsvariablen verwenden, um Ihre Anmeldeinformationen zu speichern. Anschließend können Sie von Ihrem Code aus auf die Umgebungsvariablen zugreifen, um Ihre Anwendung zu authentifizieren. Verwenden Sie in der Produktion eine sicherere Methode, Ihre Anmeldeinformationen zu speichern und darauf zuzugreifen.
Wichtig
Es wird empfohlen, die Microsoft Entra ID-Authentifizierung mit verwalteten Identitäten für Azure-Ressourcen zu kombinieren, um das Speichern von Anmeldeinformationen mit den in der Cloud ausgeführten Anwendungen zu vermeiden.
Wenn Sie einen API-Schlüssel verwenden, speichern Sie ihn an einer anderen Stelle sicher, z. B. in Azure Key Vault. Fügen Sie den API-Schlüssel nicht direkt in Ihren Code ein, und machen Sie ihn nicht öffentlich zugänglich.
Weitere Informationen zur Sicherheit von KI Services finden Sie unter Authentifizieren von Anforderungen an Azure KI Services.
Um die Umgebungsvariable für Ihren Speech-Ressourcenschlüssel und die Region festzulegen, öffnen Sie ein Konsolenfenster, und befolgen Sie die Anweisungen für Ihr Betriebssystem und Ihre Entwicklungsumgebung.
- Zum Festlegen der Umgebungsvariablen
SPEECH_KEYersetzen Sie your-key durch einen der Schlüssel für Ihre Ressource. - Zum Festlegen der Umgebungsvariablen
SPEECH_REGIONersetzen Sie your-region durch eine der Regionen für Ihre Ressource.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Hinweis
Wenn Sie nur in der aktuellen Konsole auf die Umgebungsvariable zugreifen müssen, können Sie die Variable mit set anstatt setx festlegen.
Nachdem Sie die Umgebungsvariablen hinzugefügt haben, müssen Sie möglicherweise alle Programme neu starten, die die Umgebungsvariablen lesen müssen, einschließlich des Konsolenfensters. Wenn Sie beispielsweise Visual Studio als Editor verwenden, starten Sie Visual Studio neu, bevor Sie das Beispiel ausführen.
Erkennen von Spracheingaben per Mikrofon
Tipp
Probieren Sie das Azure KI Speech-Toolkit aus, um einfach Beispiele in Visual Studio Code zu erstellen und auszuführen.
Führen Sie die folgenden Schritte aus, um eine Konsolenanwendung zu erstellen und das Speech SDK zu installieren.
Öffnen Sie ein Eingabeaufforderungsfenster in dem Ordner, in dem das neue Projekt angezeigt werden soll. Führen Sie diesen Befehl aus, um eine Konsolenanwendung mit der .NET CLI zu erstellen.
dotnet new consoleMit diesem Befehl wird die Program.cs-Datei im Projektverzeichnis erstellt.
Installieren Sie das Speech SDK mit der .NET-CLI in Ihrem neuen Projekt.
dotnet add package Microsoft.CognitiveServices.SpeechErsetzen Sie den Inhalt von Program.cs durch den folgenden Code:
using System; using System.IO; using System.Threading.Tasks; using Microsoft.CognitiveServices.Speech; using Microsoft.CognitiveServices.Speech.Audio; class Program { // This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" static string speechKey = Environment.GetEnvironmentVariable("SPEECH_KEY"); static string speechRegion = Environment.GetEnvironmentVariable("SPEECH_REGION"); static void OutputSpeechRecognitionResult(SpeechRecognitionResult speechRecognitionResult) { switch (speechRecognitionResult.Reason) { case ResultReason.RecognizedSpeech: Console.WriteLine($"RECOGNIZED: Text={speechRecognitionResult.Text}"); break; case ResultReason.NoMatch: Console.WriteLine($"NOMATCH: Speech could not be recognized."); break; case ResultReason.Canceled: var cancellation = CancellationDetails.FromResult(speechRecognitionResult); Console.WriteLine($"CANCELED: Reason={cancellation.Reason}"); if (cancellation.Reason == CancellationReason.Error) { Console.WriteLine($"CANCELED: ErrorCode={cancellation.ErrorCode}"); Console.WriteLine($"CANCELED: ErrorDetails={cancellation.ErrorDetails}"); Console.WriteLine($"CANCELED: Did you set the speech resource key and region values?"); } break; } } async static Task Main(string[] args) { var speechConfig = SpeechConfig.FromSubscription(speechKey, speechRegion); speechConfig.SpeechRecognitionLanguage = "en-US"; using var audioConfig = AudioConfig.FromDefaultMicrophoneInput(); using var speechRecognizer = new SpeechRecognizer(speechConfig, audioConfig); Console.WriteLine("Speak into your microphone."); var speechRecognitionResult = await speechRecognizer.RecognizeOnceAsync(); OutputSpeechRecognitionResult(speechRecognitionResult); } }Um die Sprache für die Spracherkennung zu ändern, ersetzen Sie
en-USdurch eine andereen-US. Verwenden Sie für Spanisch (Spanien) z. B.es-ES. Wenn Sie keine Sprache angeben, lautet der Standardwerten-US. Ausführliche Informationen zum Identifizieren einer von mehreren Sprachen, die gesprochen werden können, finden Sie unter Sprachenerkennung.Führen Sie die neue Konsolenanwendung aus, um die Spracherkennung über ein Mikrofon zu starten:
dotnet runWichtig
Stellen Sie sicher, dass Sie die Umgebungsvariablen
SPEECH_KEYundSPEECH_REGIONfestlegen. Wenn Sie diese Variablen nicht festlegen, wird für das Beispiel eine Fehlermeldung ausgegeben.Sprechen Sie in Ihr Mikrofon, wenn Sie dazu aufgefordert werden. Die Wörter, die Sie sprechen, sollten als Text angezeigt werden:
Speak into your microphone. RECOGNIZED: Text=I'm excited to try speech to text.
Hinweise
Im Folgenden finden Sie einige weitere Überlegungen dazu:
In diesem Beispiel wird der Vorgang
RecognizeOnceAsyncverwendet, um Äußerungen von bis zu 30 Sekunden oder bis zur Erkennung von Stille zu transkribieren. Informationen zur kontinuierlichen Erkennung längerer Audiodaten, einschließlich mehrsprachiger Konversationen, finden Sie unter Erkennen von Sprache.Verwenden Sie
FromWavFileInputanstelle vonFromDefaultMicrophoneInput, um Sprache aus einer Audiodatei zu erkennen:using var audioConfig = AudioConfig.FromWavFileInput("YourAudioFile.wav");Wenn Sie komprimierte Audiodateien wie beispielsweise MP4 verwenden, installieren Sie GStreamer, und verwenden Sie
PullAudioInputStreamoderPushAudioInputStream. Weitere Informationen finden Sie unter Verwenden von komprimierten Eingabeaudiodaten.
Bereinigen von Ressourcen
Sie können das Azure-Portal oder die Azure-Befehlszeilenschnittstelle (CLI) verwenden, um die erstellte Speech-Ressource zu entfernen.
Referenzdokumentation | Paket (NuGet) | Zusätzliche Beispiele auf GitHub
In dieser Schnellstartanleitung erstellen und führen Sie eine Anwendung zum Erkennen und Transkribieren von Sprache in Text in Echtzeit aus.
Weitere Informationen zum asynchronen Transkribieren von Audiodateien finden Sie unter Was ist die Batch-Transkription?. Wenn Sie nicht sicher sind, welche Spracherkennungslösung für Sie geeignet ist, finden Sie unter Was ist Spracherkennung? weitere Informationen.
Voraussetzungen
- Ein Azure-Abonnement. Sie können ein kostenloses Konto erstellen.
- Erstellen Sie eine Speech-Ressource im Azure-Portal.
- Abrufen des Speech-Ressourcenschlüssel und des Endpunkts. Wählen Sie nach der Bereitstellung Ihrer Speech-Ressource Zu Ressource wechseln aus, um Schlüssel anzuzeigen und zu verwalten.
Einrichten der Umgebung
Das Speech SDK ist als NuGet-Paket verfügbar und implementiert .NET Standard 2.0. Sie installieren das Speech SDK weiter unten in diesem Leitfaden. Weitere Anforderungen finden Sie unter Installieren des Speech SDK.
Festlegen von Umgebungsvariablen
Sie müssen Ihre Anwendung authentifizieren, um auf Azure KI Services zuzugreifen. In diesem Artikel wird erläutert, wie Sie Umgebungsvariablen verwenden, um Ihre Anmeldeinformationen zu speichern. Anschließend können Sie von Ihrem Code aus auf die Umgebungsvariablen zugreifen, um Ihre Anwendung zu authentifizieren. Verwenden Sie in der Produktion eine sicherere Methode, Ihre Anmeldeinformationen zu speichern und darauf zuzugreifen.
Wichtig
Es wird empfohlen, die Microsoft Entra ID-Authentifizierung mit verwalteten Identitäten für Azure-Ressourcen zu kombinieren, um das Speichern von Anmeldeinformationen mit den in der Cloud ausgeführten Anwendungen zu vermeiden.
Wenn Sie einen API-Schlüssel verwenden, speichern Sie ihn an einer anderen Stelle sicher, z. B. in Azure Key Vault. Fügen Sie den API-Schlüssel nicht direkt in Ihren Code ein, und machen Sie ihn nicht öffentlich zugänglich.
Weitere Informationen zur Sicherheit von KI Services finden Sie unter Authentifizieren von Anforderungen an Azure KI Services.
Um die Umgebungsvariable für Ihren Speech-Ressourcenschlüssel und die Region festzulegen, öffnen Sie ein Konsolenfenster, und befolgen Sie die Anweisungen für Ihr Betriebssystem und Ihre Entwicklungsumgebung.
- Zum Festlegen der Umgebungsvariablen
SPEECH_KEYersetzen Sie your-key durch einen der Schlüssel für Ihre Ressource. - Zum Festlegen der Umgebungsvariablen
SPEECH_REGIONersetzen Sie your-region durch eine der Regionen für Ihre Ressource.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Hinweis
Wenn Sie nur in der aktuellen Konsole auf die Umgebungsvariable zugreifen müssen, können Sie die Variable mit set anstatt setx festlegen.
Nachdem Sie die Umgebungsvariablen hinzugefügt haben, müssen Sie möglicherweise alle Programme neu starten, die die Umgebungsvariablen lesen müssen, einschließlich des Konsolenfensters. Wenn Sie beispielsweise Visual Studio als Editor verwenden, starten Sie Visual Studio neu, bevor Sie das Beispiel ausführen.
Erkennen von Spracheingaben per Mikrofon
Tipp
Probieren Sie das Azure KI Speech-Toolkit aus, um einfach Beispiele in Visual Studio Code zu erstellen und auszuführen.
Führen Sie die folgenden Schritte aus, um eine Konsolenanwendung zu erstellen und das Speech SDK zu installieren.
Erstellen Sie in Visual Studio Community in neues C++-Konsolenprojekt mit dem Namen
SpeechRecognition.Klicken Sie auf Tools>NuGet-Paket-Manager>Paket-Manager-Konsole. Führen Sie diesen Befehl in der Paket-Manager-Konsole aus:
Install-Package Microsoft.CognitiveServices.SpeechErsetzen Sie den Inhalt von
SpeechRecognition.cppdurch den folgenden Code.#include <iostream> #include <stdlib.h> #include <speechapi_cxx.h> using namespace Microsoft::CognitiveServices::Speech; using namespace Microsoft::CognitiveServices::Speech::Audio; std::string GetEnvironmentVariable(const char* name); int main() { // This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" auto speechKey = GetEnvironmentVariable("SPEECH_KEY"); auto speechRegion = GetEnvironmentVariable("SPEECH_REGION"); if ((size(speechKey) == 0) || (size(speechRegion) == 0)) { std::cout << "Please set both SPEECH_KEY and SPEECH_REGION environment variables." << std::endl; return -1; } auto speechConfig = SpeechConfig::FromSubscription(speechKey, speechRegion); speechConfig->SetSpeechRecognitionLanguage("en-US"); auto audioConfig = AudioConfig::FromDefaultMicrophoneInput(); auto speechRecognizer = SpeechRecognizer::FromConfig(speechConfig, audioConfig); std::cout << "Speak into your microphone.\n"; auto result = speechRecognizer->RecognizeOnceAsync().get(); if (result->Reason == ResultReason::RecognizedSpeech) { std::cout << "RECOGNIZED: Text=" << result->Text << std::endl; } else if (result->Reason == ResultReason::NoMatch) { std::cout << "NOMATCH: Speech could not be recognized." << std::endl; } else if (result->Reason == ResultReason::Canceled) { auto cancellation = CancellationDetails::FromResult(result); std::cout << "CANCELED: Reason=" << (int)cancellation->Reason << std::endl; if (cancellation->Reason == CancellationReason::Error) { std::cout << "CANCELED: ErrorCode=" << (int)cancellation->ErrorCode << std::endl; std::cout << "CANCELED: ErrorDetails=" << cancellation->ErrorDetails << std::endl; std::cout << "CANCELED: Did you set the speech resource key and region values?" << std::endl; } } } std::string GetEnvironmentVariable(const char* name) { #if defined(_MSC_VER) size_t requiredSize = 0; (void)getenv_s(&requiredSize, nullptr, 0, name); if (requiredSize == 0) { return ""; } auto buffer = std::make_unique<char[]>(requiredSize); (void)getenv_s(&requiredSize, buffer.get(), requiredSize, name); return buffer.get(); #else auto value = getenv(name); return value ? value : ""; #endif }Um die Sprache für die Spracherkennung zu ändern, ersetzen Sie
en-USdurch eine andereen-US. Verwenden Sie für Spanisch (Spanien) z. B.es-ES. Wenn Sie keine Sprache angeben, lautet der Standardwerten-US. Ausführliche Informationen zum Identifizieren einer von mehreren Sprachen, die gesprochen werden können, finden Sie unter Sprachenerkennung.Erstellen Sie die neue Konsolenanwendung, und führen Sie sie aus, um die Spracherkennung über ein Mikrofon zu starten.
Wichtig
Stellen Sie sicher, dass Sie die Umgebungsvariablen
SPEECH_KEYundSPEECH_REGIONfestlegen. Wenn Sie diese Variablen nicht festlegen, wird für das Beispiel eine Fehlermeldung ausgegeben.Sprechen Sie in Ihr Mikrofon, wenn Sie dazu aufgefordert werden. Die Wörter, die Sie sprechen, sollten als Text angezeigt werden:
Speak into your microphone. RECOGNIZED: Text=I'm excited to try speech to text.
Hinweise
Im Folgenden finden Sie einige weitere Überlegungen dazu:
In diesem Beispiel wird der Vorgang
RecognizeOnceAsyncverwendet, um Äußerungen von bis zu 30 Sekunden oder bis zur Erkennung von Stille zu transkribieren. Informationen zur kontinuierlichen Erkennung längerer Audiodaten, einschließlich mehrsprachiger Konversationen, finden Sie unter Erkennen von Sprache.Verwenden Sie
FromWavFileInputanstelle vonFromDefaultMicrophoneInput, um Sprache aus einer Audiodatei zu erkennen:auto audioConfig = AudioConfig::FromWavFileInput("YourAudioFile.wav");Wenn Sie komprimierte Audiodateien wie beispielsweise MP4 verwenden, installieren Sie GStreamer, und verwenden Sie
PullAudioInputStreamoderPushAudioInputStream. Weitere Informationen finden Sie unter Verwenden von komprimierten Eingabeaudiodaten.
Bereinigen von Ressourcen
Sie können das Azure-Portal oder die Azure-Befehlszeilenschnittstelle (CLI) verwenden, um die erstellte Speech-Ressource zu entfernen.
Referenzdokumentation | Paket (Go) | Zusätzliche Beispiele auf GitHub
In dieser Schnellstartanleitung erstellen und führen Sie eine Anwendung zum Erkennen und Transkribieren von Sprache in Text in Echtzeit aus.
Weitere Informationen zum asynchronen Transkribieren von Audiodateien finden Sie unter Was ist die Batch-Transkription?. Wenn Sie nicht sicher sind, welche Spracherkennungslösung für Sie geeignet ist, finden Sie unter Was ist Spracherkennung? weitere Informationen.
Voraussetzungen
- Ein Azure-Abonnement. Sie können ein kostenloses Konto erstellen.
- Erstellen Sie eine Speech-Ressource im Azure-Portal.
- Abrufen des Speech-Ressourcenschlüssel und des Endpunkts. Wählen Sie nach der Bereitstellung Ihrer Speech-Ressource Zu Ressource wechseln aus, um Schlüssel anzuzeigen und zu verwalten.
Einrichten der Umgebung
Installieren Sie das Speech SDK für Go. Weitere Informationen zu Anforderungen und Anweisungen finden Sie unter Installieren des Speech SDK.
Festlegen von Umgebungsvariablen
Sie müssen Ihre Anwendung authentifizieren, um auf Azure KI Services zuzugreifen. In diesem Artikel wird erläutert, wie Sie Umgebungsvariablen verwenden, um Ihre Anmeldeinformationen zu speichern. Anschließend können Sie von Ihrem Code aus auf die Umgebungsvariablen zugreifen, um Ihre Anwendung zu authentifizieren. Verwenden Sie in der Produktion eine sicherere Methode, Ihre Anmeldeinformationen zu speichern und darauf zuzugreifen.
Wichtig
Es wird empfohlen, die Microsoft Entra ID-Authentifizierung mit verwalteten Identitäten für Azure-Ressourcen zu kombinieren, um das Speichern von Anmeldeinformationen mit den in der Cloud ausgeführten Anwendungen zu vermeiden.
Wenn Sie einen API-Schlüssel verwenden, speichern Sie ihn an einer anderen Stelle sicher, z. B. in Azure Key Vault. Fügen Sie den API-Schlüssel nicht direkt in Ihren Code ein, und machen Sie ihn nicht öffentlich zugänglich.
Weitere Informationen zur Sicherheit von KI Services finden Sie unter Authentifizieren von Anforderungen an Azure KI Services.
Um die Umgebungsvariable für Ihren Speech-Ressourcenschlüssel und die Region festzulegen, öffnen Sie ein Konsolenfenster, und befolgen Sie die Anweisungen für Ihr Betriebssystem und Ihre Entwicklungsumgebung.
- Zum Festlegen der Umgebungsvariablen
SPEECH_KEYersetzen Sie your-key durch einen der Schlüssel für Ihre Ressource. - Zum Festlegen der Umgebungsvariablen
SPEECH_REGIONersetzen Sie your-region durch eine der Regionen für Ihre Ressource.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Hinweis
Wenn Sie nur in der aktuellen Konsole auf die Umgebungsvariable zugreifen müssen, können Sie die Variable mit set anstatt setx festlegen.
Nachdem Sie die Umgebungsvariablen hinzugefügt haben, müssen Sie möglicherweise alle Programme neu starten, die die Umgebungsvariablen lesen müssen, einschließlich des Konsolenfensters. Wenn Sie beispielsweise Visual Studio als Editor verwenden, starten Sie Visual Studio neu, bevor Sie das Beispiel ausführen.
Erkennen von Spracheingaben per Mikrofon
Führen Sie die folgenden Schritte aus, um ein GO-Modul zu erstellen.
Öffnen Sie ein Eingabeaufforderungsfenster in dem Ordner, in dem das neue Projekt angezeigt werden soll. Erstellen Sie eine neue Datei namens speech-recognition.go.
Kopieren Sie den folgenden Code in die Datei speech-recognition.go:
package main import ( "bufio" "fmt" "os" "github.com/Microsoft/cognitive-services-speech-sdk-go/audio" "github.com/Microsoft/cognitive-services-speech-sdk-go/speech" ) func sessionStartedHandler(event speech.SessionEventArgs) { defer event.Close() fmt.Println("Session Started (ID=", event.SessionID, ")") } func sessionStoppedHandler(event speech.SessionEventArgs) { defer event.Close() fmt.Println("Session Stopped (ID=", event.SessionID, ")") } func recognizingHandler(event speech.SpeechRecognitionEventArgs) { defer event.Close() fmt.Println("Recognizing:", event.Result.Text) } func recognizedHandler(event speech.SpeechRecognitionEventArgs) { defer event.Close() fmt.Println("Recognized:", event.Result.Text) } func cancelledHandler(event speech.SpeechRecognitionCanceledEventArgs) { defer event.Close() fmt.Println("Received a cancellation: ", event.ErrorDetails) fmt.Println("Did you set the speech resource key and region values?") } func main() { // This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" speechKey := os.Getenv("SPEECH_KEY") speechRegion := os.Getenv("SPEECH_REGION") audioConfig, err := audio.NewAudioConfigFromDefaultMicrophoneInput() if err != nil { fmt.Println("Got an error: ", err) return } defer audioConfig.Close() speechConfig, err := speech.NewSpeechConfigFromSubscription(speechKey, speechRegion) if err != nil { fmt.Println("Got an error: ", err) return } defer speechConfig.Close() speechRecognizer, err := speech.NewSpeechRecognizerFromConfig(speechConfig, audioConfig) if err != nil { fmt.Println("Got an error: ", err) return } defer speechRecognizer.Close() speechRecognizer.SessionStarted(sessionStartedHandler) speechRecognizer.SessionStopped(sessionStoppedHandler) speechRecognizer.Recognizing(recognizingHandler) speechRecognizer.Recognized(recognizedHandler) speechRecognizer.Canceled(cancelledHandler) speechRecognizer.StartContinuousRecognitionAsync() defer speechRecognizer.StopContinuousRecognitionAsync() bufio.NewReader(os.Stdin).ReadBytes('\n') }Führen Sie die folgenden Befehle aus, um eine Datei namens go.mod zu erstellen, die mit auf GitHub gehosteten Komponenten verknüpft ist:
go mod init speech-recognition go get github.com/Microsoft/cognitive-services-speech-sdk-goWichtig
Stellen Sie sicher, dass Sie die Umgebungsvariablen
SPEECH_KEYundSPEECH_REGIONfestlegen. Wenn Sie diese Variablen nicht festlegen, wird für das Beispiel eine Fehlermeldung ausgegeben.Erstellen Sie den Code, und führen Sie ihn aus:
go build go run speech-recognition
Bereinigen von Ressourcen
Sie können das Azure-Portal oder die Azure-Befehlszeilenschnittstelle (CLI) verwenden, um die erstellte Speech-Ressource zu entfernen.
Referenzdokumentation | Zusätzliche Beispiele auf GitHub
In dieser Schnellstartanleitung erstellen und führen Sie eine Anwendung zum Erkennen und Transkribieren von Sprache in Text in Echtzeit aus.
Weitere Informationen zum asynchronen Transkribieren von Audiodateien finden Sie unter Was ist die Batch-Transkription?. Wenn Sie nicht sicher sind, welche Spracherkennungslösung für Sie geeignet ist, finden Sie unter Was ist Spracherkennung? weitere Informationen.
Voraussetzungen
- Ein Azure-Abonnement. Sie können ein kostenloses Konto erstellen.
- Erstellen Sie eine Speech-Ressource im Azure-Portal.
- Abrufen des Speech-Ressourcenschlüssel und des Endpunkts. Wählen Sie nach der Bereitstellung Ihrer Speech-Ressource Zu Ressource wechseln aus, um Schlüssel anzuzeigen und zu verwalten.
Einrichten der Umgebung
Um Ihre Umgebung einzurichten, installieren Sie das Speech SDK. Das Beispiel in diesem Schnellstart funktioniert mit der Java-Runtime.
Installieren Sie Apache Maven. Führen Sie dann
mvn -vaus, um die erfolgreiche Installation zu bestätigen.Erstellen Sie im Stammverzeichnis Ihres Projekts eine neue Datei
pom.xml, und kopieren Sie folgende Code in diese Datei:<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.microsoft.cognitiveservices.speech.samples</groupId> <artifactId>quickstart-eclipse</artifactId> <version>1.0.0-SNAPSHOT</version> <build> <sourceDirectory>src</sourceDirectory> <plugins> <plugin> <artifactId>maven-compiler-plugin</artifactId> <version>3.7.0</version> <configuration> <source>1.8</source> <target>1.8</target> </configuration> </plugin> </plugins> </build> <dependencies> <dependency> <groupId>com.microsoft.cognitiveservices.speech</groupId> <artifactId>client-sdk</artifactId> <version>1.42.0</version> </dependency> </dependencies> </project>Installieren Sie das Speech SDK und Abhängigkeiten.
mvn clean dependency:copy-dependencies
Festlegen von Umgebungsvariablen
Sie müssen Ihre Anwendung authentifizieren, um auf Azure KI Services zuzugreifen. In diesem Artikel wird erläutert, wie Sie Umgebungsvariablen verwenden, um Ihre Anmeldeinformationen zu speichern. Anschließend können Sie von Ihrem Code aus auf die Umgebungsvariablen zugreifen, um Ihre Anwendung zu authentifizieren. Verwenden Sie in der Produktion eine sicherere Methode, Ihre Anmeldeinformationen zu speichern und darauf zuzugreifen.
Wichtig
Es wird empfohlen, die Microsoft Entra ID-Authentifizierung mit verwalteten Identitäten für Azure-Ressourcen zu kombinieren, um das Speichern von Anmeldeinformationen mit den in der Cloud ausgeführten Anwendungen zu vermeiden.
Wenn Sie einen API-Schlüssel verwenden, speichern Sie ihn an einer anderen Stelle sicher, z. B. in Azure Key Vault. Fügen Sie den API-Schlüssel nicht direkt in Ihren Code ein, und machen Sie ihn nicht öffentlich zugänglich.
Weitere Informationen zur Sicherheit von KI Services finden Sie unter Authentifizieren von Anforderungen an Azure KI Services.
Um die Umgebungsvariable für Ihren Speech-Ressourcenschlüssel und die Region festzulegen, öffnen Sie ein Konsolenfenster, und befolgen Sie die Anweisungen für Ihr Betriebssystem und Ihre Entwicklungsumgebung.
- Zum Festlegen der Umgebungsvariablen
SPEECH_KEYersetzen Sie your-key durch einen der Schlüssel für Ihre Ressource. - Zum Festlegen der Umgebungsvariablen
SPEECH_REGIONersetzen Sie your-region durch eine der Regionen für Ihre Ressource.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Hinweis
Wenn Sie nur in der aktuellen Konsole auf die Umgebungsvariable zugreifen müssen, können Sie die Variable mit set anstatt setx festlegen.
Nachdem Sie die Umgebungsvariablen hinzugefügt haben, müssen Sie möglicherweise alle Programme neu starten, die die Umgebungsvariablen lesen müssen, einschließlich des Konsolenfensters. Wenn Sie beispielsweise Visual Studio als Editor verwenden, starten Sie Visual Studio neu, bevor Sie das Beispiel ausführen.
Erkennen von Spracheingaben per Mikrofon
Führen Sie die folgenden Schritte aus, um eine Konsolenanwendung für die Spracherkennung zu erstellen.
Erstellen Sie im gleichen Projektstammverzeichnis eine Datei namens SpeechRecognition.java.
Kopieren Sie den folgenden Code in die Datei SpeechRecognition.java:
import com.microsoft.cognitiveservices.speech.*; import com.microsoft.cognitiveservices.speech.audio.AudioConfig; import java.util.concurrent.ExecutionException; import java.util.concurrent.Future; public class SpeechRecognition { // This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" private static String speechKey = System.getenv("SPEECH_KEY"); private static String speechRegion = System.getenv("SPEECH_REGION"); public static void main(String[] args) throws InterruptedException, ExecutionException { SpeechConfig speechConfig = SpeechConfig.fromSubscription(speechKey, speechRegion); speechConfig.setSpeechRecognitionLanguage("en-US"); recognizeFromMicrophone(speechConfig); } public static void recognizeFromMicrophone(SpeechConfig speechConfig) throws InterruptedException, ExecutionException { AudioConfig audioConfig = AudioConfig.fromDefaultMicrophoneInput(); SpeechRecognizer speechRecognizer = new SpeechRecognizer(speechConfig, audioConfig); System.out.println("Speak into your microphone."); Future<SpeechRecognitionResult> task = speechRecognizer.recognizeOnceAsync(); SpeechRecognitionResult speechRecognitionResult = task.get(); if (speechRecognitionResult.getReason() == ResultReason.RecognizedSpeech) { System.out.println("RECOGNIZED: Text=" + speechRecognitionResult.getText()); } else if (speechRecognitionResult.getReason() == ResultReason.NoMatch) { System.out.println("NOMATCH: Speech could not be recognized."); } else if (speechRecognitionResult.getReason() == ResultReason.Canceled) { CancellationDetails cancellation = CancellationDetails.fromResult(speechRecognitionResult); System.out.println("CANCELED: Reason=" + cancellation.getReason()); if (cancellation.getReason() == CancellationReason.Error) { System.out.println("CANCELED: ErrorCode=" + cancellation.getErrorCode()); System.out.println("CANCELED: ErrorDetails=" + cancellation.getErrorDetails()); System.out.println("CANCELED: Did you set the speech resource key and region values?"); } } System.exit(0); } }Um die Sprache für die Spracherkennung zu ändern, ersetzen Sie
en-USdurch eine andereen-US. Verwenden Sie für Spanisch (Spanien) z. B.es-ES. Wenn Sie keine Sprache angeben, lautet der Standardwerten-US. Ausführliche Informationen zum Identifizieren einer von mehreren Sprachen, die gesprochen werden können, finden Sie unter Sprachenerkennung.Führen Sie die neue Konsolenanwendung aus, um die Spracherkennung über ein Mikrofon zu starten:
javac SpeechRecognition.java -cp ".;target\dependency\*" java -cp ".;target\dependency\*" SpeechRecognitionWichtig
Stellen Sie sicher, dass Sie die Umgebungsvariablen
SPEECH_KEYundSPEECH_REGIONfestlegen. Wenn Sie diese Variablen nicht festlegen, wird für das Beispiel eine Fehlermeldung ausgegeben.Sprechen Sie in Ihr Mikrofon, wenn Sie dazu aufgefordert werden. Die Wörter, die Sie sprechen, sollten als Text angezeigt werden:
Speak into your microphone. RECOGNIZED: Text=I'm excited to try speech to text.
Hinweise
Im Folgenden finden Sie einige weitere Überlegungen dazu:
In diesem Beispiel wird der Vorgang
RecognizeOnceAsyncverwendet, um Äußerungen von bis zu 30 Sekunden oder bis zur Erkennung von Stille zu transkribieren. Informationen zur kontinuierlichen Erkennung längerer Audiodaten, einschließlich mehrsprachiger Konversationen, finden Sie unter Erkennen von Sprache.Verwenden Sie
fromWavFileInputanstelle vonfromDefaultMicrophoneInput, um Sprache aus einer Audiodatei zu erkennen:AudioConfig audioConfig = AudioConfig.fromWavFileInput("YourAudioFile.wav");Wenn Sie komprimierte Audiodateien wie beispielsweise MP4 verwenden, installieren Sie GStreamer, und verwenden Sie
PullAudioInputStreamoderPushAudioInputStream. Weitere Informationen finden Sie unter Verwenden von komprimierten Eingabeaudiodaten.
Bereinigen von Ressourcen
Sie können das Azure-Portal oder die Azure-Befehlszeilenschnittstelle (CLI) verwenden, um die erstellte Speech-Ressource zu entfernen.
Referenzdokumentation | Paket (npm) | Zusätzliche Beispiele auf GitHub | Quellcode der Bibliothek
In dieser Schnellstartanleitung erstellen und führen Sie eine Anwendung zum Erkennen und Transkribieren von Sprache in Text in Echtzeit aus.
Weitere Informationen zum asynchronen Transkribieren von Audiodateien finden Sie unter Was ist die Batch-Transkription?. Wenn Sie nicht sicher sind, welche Spracherkennungslösung für Sie geeignet ist, finden Sie unter Was ist Spracherkennung? weitere Informationen.
Voraussetzungen
- Ein Azure-Abonnement. Sie können ein kostenloses Konto erstellen.
- Erstellen Sie eine Speech-Ressource im Azure-Portal.
- Abrufen des Speech-Ressourcenschlüssel und des Endpunkts. Wählen Sie nach der Bereitstellung Ihrer Speech-Ressource Zu Ressource wechseln aus, um Schlüssel anzuzeigen und zu verwalten.
Sie benötigen auch eine WAV-Audiodatei auf Ihrem lokalen Computer. Sie können Ihre eigene WAV-Datei (bis zu 30 Sekunden) verwenden oder die Beispieldatei https://crbn.us/whatstheweatherlike.wav herunterladen.
Einrichten der Umgebung
Um Ihre Umgebung einzurichten, installieren Sie das Speech SDK für JavaScript. Führen Sie den folgenden Befehl aus: npm install microsoft-cognitiveservices-speech-sdk. Anweisungen zu einer geführten Installation finden Sie unter Installieren des Speech SDK.
Festlegen von Umgebungsvariablen
Sie müssen Ihre Anwendung authentifizieren, um auf Azure KI Services zuzugreifen. In diesem Artikel wird erläutert, wie Sie Umgebungsvariablen verwenden, um Ihre Anmeldeinformationen zu speichern. Anschließend können Sie von Ihrem Code aus auf die Umgebungsvariablen zugreifen, um Ihre Anwendung zu authentifizieren. Verwenden Sie in der Produktion eine sicherere Methode, Ihre Anmeldeinformationen zu speichern und darauf zuzugreifen.
Wichtig
Es wird empfohlen, die Microsoft Entra ID-Authentifizierung mit verwalteten Identitäten für Azure-Ressourcen zu kombinieren, um das Speichern von Anmeldeinformationen mit den in der Cloud ausgeführten Anwendungen zu vermeiden.
Wenn Sie einen API-Schlüssel verwenden, speichern Sie ihn an einer anderen Stelle sicher, z. B. in Azure Key Vault. Fügen Sie den API-Schlüssel nicht direkt in Ihren Code ein, und machen Sie ihn nicht öffentlich zugänglich.
Weitere Informationen zur Sicherheit von KI Services finden Sie unter Authentifizieren von Anforderungen an Azure KI Services.
Um die Umgebungsvariable für Ihren Speech-Ressourcenschlüssel und die Region festzulegen, öffnen Sie ein Konsolenfenster, und befolgen Sie die Anweisungen für Ihr Betriebssystem und Ihre Entwicklungsumgebung.
- Zum Festlegen der Umgebungsvariablen
SPEECH_KEYersetzen Sie your-key durch einen der Schlüssel für Ihre Ressource. - Zum Festlegen der Umgebungsvariablen
SPEECH_REGIONersetzen Sie your-region durch eine der Regionen für Ihre Ressource.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Hinweis
Wenn Sie nur in der aktuellen Konsole auf die Umgebungsvariable zugreifen müssen, können Sie die Variable mit set anstatt setx festlegen.
Nachdem Sie die Umgebungsvariablen hinzugefügt haben, müssen Sie möglicherweise alle Programme neu starten, die die Umgebungsvariablen lesen müssen, einschließlich des Konsolenfensters. Wenn Sie beispielsweise Visual Studio als Editor verwenden, starten Sie Visual Studio neu, bevor Sie das Beispiel ausführen.
Erkennen von Sprache aus einer Datei
Tipp
Probieren Sie das Azure KI Speech-Toolkit aus, um einfach Beispiele in Visual Studio Code zu erstellen und auszuführen.
Führen Sie die folgenden Schritte aus, um eine Node.js-Konsolenanwendung für die Spracherkennung zu erstellen.
Öffnen Sie ein Eingabeaufforderungsfenster, in dem Sie das neue Projekt anlegen möchten und erstellen Sie eine neue Datei namens SpeechRecognition.js.
Installieren Sie das Speech SDK für JavaScript:
npm install microsoft-cognitiveservices-speech-sdkKopieren Sie den folgenden Code in die Datei SpeechRecognition.js:
const fs = require("fs"); const sdk = require("microsoft-cognitiveservices-speech-sdk"); // This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" const speechConfig = sdk.SpeechConfig.fromSubscription(process.env.SPEECH_KEY, process.env.SPEECH_REGION); speechConfig.speechRecognitionLanguage = "en-US"; function fromFile() { let audioConfig = sdk.AudioConfig.fromWavFileInput(fs.readFileSync("YourAudioFile.wav")); let speechRecognizer = new sdk.SpeechRecognizer(speechConfig, audioConfig); speechRecognizer.recognizeOnceAsync(result => { switch (result.reason) { case sdk.ResultReason.RecognizedSpeech: console.log(`RECOGNIZED: Text=${result.text}`); break; case sdk.ResultReason.NoMatch: console.log("NOMATCH: Speech could not be recognized."); break; case sdk.ResultReason.Canceled: const cancellation = sdk.CancellationDetails.fromResult(result); console.log(`CANCELED: Reason=${cancellation.reason}`); if (cancellation.reason == sdk.CancellationReason.Error) { console.log(`CANCELED: ErrorCode=${cancellation.ErrorCode}`); console.log(`CANCELED: ErrorDetails=${cancellation.errorDetails}`); console.log("CANCELED: Did you set the speech resource key and region values?"); } break; } speechRecognizer.close(); }); } fromFile();Ersetzen Sie in SpeechRecognition.js den Dateinamen YourAudioFile.wav durch Ihre eigene WAV-Datei. In diesem Beispiel wird nur die Sprache aus einer WAV-Datei erkannt. Informationen zu anderen Audioformaten finden Sie unter Verwenden von komprimierten Eingabeaudiodaten. In diesem Beispiel werden bis zu 30 Sekunden an Audiodaten unterstützt.
Um die Sprache für die Spracherkennung zu ändern, ersetzen Sie
en-USdurch eine andereen-US. Verwenden Sie für Spanisch (Spanien) z. B.es-ES. Wenn Sie keine Sprache angeben, lautet der Standardwerten-US. Ausführliche Informationen zum Identifizieren einer von mehreren Sprachen, die gesprochen werden können, finden Sie unter Sprachenerkennung.Führen Sie die neue Konsolenanwendung aus, um die Spracherkennung aus einer Datei zu starten:
node.exe SpeechRecognition.jsWichtig
Stellen Sie sicher, dass Sie die Umgebungsvariablen
SPEECH_KEYundSPEECH_REGIONfestlegen. Wenn Sie diese Variablen nicht festlegen, wird für das Beispiel eine Fehlermeldung ausgegeben.Die Sprache aus der Audiodatei sollte als Text ausgegeben werden:
RECOGNIZED: Text=I'm excited to try speech to text.
Hinweise
In diesem Beispiel wird der Vorgang recognizeOnceAsync verwendet, um Äußerungen von bis zu 30 Sekunden oder bis zur Erkennung von Stille zu transkribieren. Informationen zur kontinuierlichen Erkennung längerer Audiodaten, einschließlich mehrsprachiger Konversationen, finden Sie unter Erkennen von Sprache.
Hinweis
Die Spracherkennung über ein Mikrofon wird in Node.js nicht unterstützt. Sie wird nur in einer browserbasierten JavaScript-Umgebung unterstützt. Weitere Informationen finden Sie im React-Beispiel und unter Implementierung der Spracherkennung über ein Mikrofon auf GitHub.
Das React-Beispiel zeigt Entwurfsmuster für den Austausch und die Verwaltung von Authentifizierungstoken. Außerdem wird die Erfassung von Audiodaten über ein Mikrofon oder aus einer Datei für die Konvertierung von Sprache in Text veranschaulicht.
Bereinigen von Ressourcen
Sie können das Azure-Portal oder die Azure-Befehlszeilenschnittstelle (CLI) verwenden, um die erstellte Speech-Ressource zu entfernen.
Referenzdokumentation | Paket (PyPi) | Zusätzliche Beispiele auf GitHub
In dieser Schnellstartanleitung erstellen und führen Sie eine Anwendung zum Erkennen und Transkribieren von Sprache in Text in Echtzeit aus.
Weitere Informationen zum asynchronen Transkribieren von Audiodateien finden Sie unter Was ist die Batch-Transkription?. Wenn Sie nicht sicher sind, welche Spracherkennungslösung für Sie geeignet ist, finden Sie unter Was ist Spracherkennung? weitere Informationen.
Voraussetzungen
- Ein Azure-Abonnement. Sie können ein kostenloses Konto erstellen.
- Erstellen Sie eine Speech-Ressource im Azure-Portal.
- Abrufen des Speech-Ressourcenschlüssel und des Endpunkts. Wählen Sie nach der Bereitstellung Ihrer Speech-Ressource Zu Ressource wechseln aus, um Schlüssel anzuzeigen und zu verwalten.
Einrichten der Umgebung
Das Speech SDK für Python ist als PyPI-Modul (Python Package Index) verfügbar. Das Speech SDK für Python ist mit Windows, Linux und macOS kompatibel.
- Installieren Sie unter Windows das Microsoft Visual C++ Redistributable für Visual Studio 2015, 2017, 2019 und 2022 für Ihre Plattform. Bei der Erstinstallation dieses Pakets ist möglicherweise ein Neustart erforderlich.
- Unter Linux müssen Sie die x64-Zielarchitektur verwenden.
Installieren Sie eine Python-Version ab 3.7. Weitere Anforderungen finden Sie unter Installieren des Speech SDK.
Festlegen von Umgebungsvariablen
Sie müssen Ihre Anwendung authentifizieren, um auf Azure KI Services zuzugreifen. In diesem Artikel wird erläutert, wie Sie Umgebungsvariablen verwenden, um Ihre Anmeldeinformationen zu speichern. Anschließend können Sie von Ihrem Code aus auf die Umgebungsvariablen zugreifen, um Ihre Anwendung zu authentifizieren. Verwenden Sie in der Produktion eine sicherere Methode, Ihre Anmeldeinformationen zu speichern und darauf zuzugreifen.
Wichtig
Es wird empfohlen, die Microsoft Entra ID-Authentifizierung mit verwalteten Identitäten für Azure-Ressourcen zu kombinieren, um das Speichern von Anmeldeinformationen mit den in der Cloud ausgeführten Anwendungen zu vermeiden.
Wenn Sie einen API-Schlüssel verwenden, speichern Sie ihn an einer anderen Stelle sicher, z. B. in Azure Key Vault. Fügen Sie den API-Schlüssel nicht direkt in Ihren Code ein, und machen Sie ihn nicht öffentlich zugänglich.
Weitere Informationen zur Sicherheit von KI Services finden Sie unter Authentifizieren von Anforderungen an Azure KI Services.
Um die Umgebungsvariable für Ihren Speech-Ressourcenschlüssel und die Region festzulegen, öffnen Sie ein Konsolenfenster, und befolgen Sie die Anweisungen für Ihr Betriebssystem und Ihre Entwicklungsumgebung.
- Zum Festlegen der Umgebungsvariablen
SPEECH_KEYersetzen Sie your-key durch einen der Schlüssel für Ihre Ressource. - Zum Festlegen der Umgebungsvariablen
SPEECH_REGIONersetzen Sie your-region durch eine der Regionen für Ihre Ressource.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Hinweis
Wenn Sie nur in der aktuellen Konsole auf die Umgebungsvariable zugreifen müssen, können Sie die Variable mit set anstatt setx festlegen.
Nachdem Sie die Umgebungsvariablen hinzugefügt haben, müssen Sie möglicherweise alle Programme neu starten, die die Umgebungsvariablen lesen müssen, einschließlich des Konsolenfensters. Wenn Sie beispielsweise Visual Studio als Editor verwenden, starten Sie Visual Studio neu, bevor Sie das Beispiel ausführen.
Erkennen von Spracheingaben per Mikrofon
Tipp
Probieren Sie das Azure KI Speech-Toolkit aus, um einfach Beispiele in Visual Studio Code zu erstellen und auszuführen.
Führen Sie die folgenden Schritte aus, um eine Konsolenanwendung zu erstellen.
Öffnen Sie ein Eingabeaufforderungsfenster in dem Ordner, in dem das neue Projekt angezeigt werden soll. Erstellen Sie eine neue Datei namens speech_recognition.py.
Führen Sie diesen Befehl aus, um das Speech SDK zu installieren:
pip install azure-cognitiveservices-speechKopieren Sie den folgenden Code in die Datei speech_recognition.py:
import os import azure.cognitiveservices.speech as speechsdk def recognize_from_microphone(): # This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" speech_config = speechsdk.SpeechConfig(subscription=os.environ.get('SPEECH_KEY'), region=os.environ.get('SPEECH_REGION')) speech_config.speech_recognition_language="en-US" audio_config = speechsdk.audio.AudioConfig(use_default_microphone=True) speech_recognizer = speechsdk.SpeechRecognizer(speech_config=speech_config, audio_config=audio_config) print("Speak into your microphone.") speech_recognition_result = speech_recognizer.recognize_once_async().get() if speech_recognition_result.reason == speechsdk.ResultReason.RecognizedSpeech: print("Recognized: {}".format(speech_recognition_result.text)) elif speech_recognition_result.reason == speechsdk.ResultReason.NoMatch: print("No speech could be recognized: {}".format(speech_recognition_result.no_match_details)) elif speech_recognition_result.reason == speechsdk.ResultReason.Canceled: cancellation_details = speech_recognition_result.cancellation_details print("Speech Recognition canceled: {}".format(cancellation_details.reason)) if cancellation_details.reason == speechsdk.CancellationReason.Error: print("Error details: {}".format(cancellation_details.error_details)) print("Did you set the speech resource key and region values?") recognize_from_microphone()Um die Sprache für die Spracherkennung zu ändern, ersetzen Sie
en-USdurch eine andereen-US. Verwenden Sie für Spanisch (Spanien) z. B.es-ES. Wenn Sie keine Sprache angeben, lautet der Standardwerten-US. Ausführliche Informationen zum Identifizieren einer von mehreren Sprachen, die gesprochen werden können, finden Sie unter Sprachenerkennung.Führen Sie die neue Konsolenanwendung aus, um die Spracherkennung über ein Mikrofon zu starten:
python speech_recognition.pyWichtig
Stellen Sie sicher, dass Sie die Umgebungsvariablen
SPEECH_KEYundSPEECH_REGIONfestlegen. Wenn Sie diese Variablen nicht festlegen, wird für das Beispiel eine Fehlermeldung ausgegeben.Sprechen Sie in Ihr Mikrofon, wenn Sie dazu aufgefordert werden. Die Wörter, die Sie sprechen, sollten als Text angezeigt werden:
Speak into your microphone. RECOGNIZED: Text=I'm excited to try speech to text.
Hinweise
Im Folgenden finden Sie einige weitere Überlegungen dazu:
In diesem Beispiel wird der Vorgang
recognize_once_asyncverwendet, um Äußerungen von bis zu 30 Sekunden oder bis zur Erkennung von Stille zu transkribieren. Informationen zur kontinuierlichen Erkennung längerer Audiodaten, einschließlich mehrsprachiger Konversationen, finden Sie unter Erkennen von Sprache.Verwenden Sie
filenameanstelle vonuse_default_microphone, um Sprache aus einer Audiodatei zu erkennen:audio_config = speechsdk.audio.AudioConfig(filename="YourAudioFile.wav")Wenn Sie komprimierte Audiodateien wie beispielsweise MP4 verwenden, installieren Sie GStreamer, und verwenden Sie
PullAudioInputStreamoderPushAudioInputStream. Weitere Informationen finden Sie unter Verwenden von komprimierten Eingabeaudiodaten.
Bereinigen von Ressourcen
Sie können das Azure-Portal oder die Azure-Befehlszeilenschnittstelle (CLI) verwenden, um die erstellte Speech-Ressource zu entfernen.
Referenzdokumentation | Paket (Download) | Zusätzliche Beispiele auf GitHub
In dieser Schnellstartanleitung erstellen und führen Sie eine Anwendung zum Erkennen und Transkribieren von Sprache in Text in Echtzeit aus.
Weitere Informationen zum asynchronen Transkribieren von Audiodateien finden Sie unter Was ist die Batch-Transkription?. Wenn Sie nicht sicher sind, welche Spracherkennungslösung für Sie geeignet ist, finden Sie unter Was ist Spracherkennung? weitere Informationen.
Voraussetzungen
- Ein Azure-Abonnement. Sie können ein kostenloses Konto erstellen.
- Erstellen Sie eine Speech-Ressource im Azure-Portal.
- Abrufen des Speech-Ressourcenschlüssel und des Endpunkts. Wählen Sie nach der Bereitstellung Ihrer Speech-Ressource Zu Ressource wechseln aus, um Schlüssel anzuzeigen und zu verwalten.
Einrichten der Umgebung
Das Speech SDK für Swift wird als Frameworkpaket verteilt. Das Framework unterstützt sowohl Objective-C als auch Swift unter iOS und macOS.
Das Speech SDK kann in Xcode-Projekten als CocoaPod verwendet oder direkt heruntergeladen und manuell verknüpft werden. In dieser Anleitung wird ein CocoaPod verwendet. Installieren Sie den CocoaPod-Abhängigkeits-Manager entsprechend den Anweisungen in der Installationsanleitung.
Festlegen von Umgebungsvariablen
Sie müssen Ihre Anwendung authentifizieren, um auf Azure KI Services zuzugreifen. In diesem Artikel wird erläutert, wie Sie Umgebungsvariablen verwenden, um Ihre Anmeldeinformationen zu speichern. Anschließend können Sie von Ihrem Code aus auf die Umgebungsvariablen zugreifen, um Ihre Anwendung zu authentifizieren. Verwenden Sie in der Produktion eine sicherere Methode, Ihre Anmeldeinformationen zu speichern und darauf zuzugreifen.
Wichtig
Es wird empfohlen, die Microsoft Entra ID-Authentifizierung mit verwalteten Identitäten für Azure-Ressourcen zu kombinieren, um das Speichern von Anmeldeinformationen mit den in der Cloud ausgeführten Anwendungen zu vermeiden.
Wenn Sie einen API-Schlüssel verwenden, speichern Sie ihn an einer anderen Stelle sicher, z. B. in Azure Key Vault. Fügen Sie den API-Schlüssel nicht direkt in Ihren Code ein, und machen Sie ihn nicht öffentlich zugänglich.
Weitere Informationen zur Sicherheit von KI Services finden Sie unter Authentifizieren von Anforderungen an Azure KI Services.
Um die Umgebungsvariable für Ihren Speech-Ressourcenschlüssel und die Region festzulegen, öffnen Sie ein Konsolenfenster, und befolgen Sie die Anweisungen für Ihr Betriebssystem und Ihre Entwicklungsumgebung.
- Zum Festlegen der Umgebungsvariablen
SPEECH_KEYersetzen Sie your-key durch einen der Schlüssel für Ihre Ressource. - Zum Festlegen der Umgebungsvariablen
SPEECH_REGIONersetzen Sie your-region durch eine der Regionen für Ihre Ressource.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Hinweis
Wenn Sie nur in der aktuellen Konsole auf die Umgebungsvariable zugreifen müssen, können Sie die Variable mit set anstatt setx festlegen.
Nachdem Sie die Umgebungsvariablen hinzugefügt haben, müssen Sie möglicherweise alle Programme neu starten, die die Umgebungsvariablen lesen müssen, einschließlich des Konsolenfensters. Wenn Sie beispielsweise Visual Studio als Editor verwenden, starten Sie Visual Studio neu, bevor Sie das Beispiel ausführen.
Erkennen von Spracheingaben per Mikrofon
Führen Sie die folgenden Schritte aus, um Sprache in einer macOS-Anwendung zu erkennen.
Klonen Sie das Repository Azure-Samples/cognitive-services-speech-sdk, um das Beispielprojekt zum Erkennen von Spracheingaben per Mikrofon in Swift unter macOS abzurufen. Das Repository enthält auch iOS-Beispiele.
Navigieren Sie in einem Terminal zum Verzeichnis der heruntergeladenen Beispiel-App (
helloworld).Führen Sie den Befehl
pod installaus. Mit diesem Befehl wird ein Xcode-Arbeitsbereichhelloworld.xcworkspacegeneriert, der die Beispiel-App und das Speech SDK als Abhängigkeit enthält.Öffnen Sie den Arbeitsbereich
helloworld.xcworkspacein Xcode.Öffnen Sie die Datei AppDelegate.swift, und suchen Sie wie hier gezeigt nach den Methoden
applicationDidFinishLaunchingundrecognizeFromMic.import Cocoa @NSApplicationMain class AppDelegate: NSObject, NSApplicationDelegate { var label: NSTextField! var fromMicButton: NSButton! var sub: String! var region: String! @IBOutlet weak var window: NSWindow! func applicationDidFinishLaunching(_ aNotification: Notification) { print("loading") // load subscription information sub = ProcessInfo.processInfo.environment["SPEECH_KEY"] region = ProcessInfo.processInfo.environment["SPEECH_REGION"] label = NSTextField(frame: NSRect(x: 100, y: 50, width: 200, height: 200)) label.textColor = NSColor.black label.lineBreakMode = .byWordWrapping label.stringValue = "Recognition Result" label.isEditable = false self.window.contentView?.addSubview(label) fromMicButton = NSButton(frame: NSRect(x: 100, y: 300, width: 200, height: 30)) fromMicButton.title = "Recognize" fromMicButton.target = self fromMicButton.action = #selector(fromMicButtonClicked) self.window.contentView?.addSubview(fromMicButton) } @objc func fromMicButtonClicked() { DispatchQueue.global(qos: .userInitiated).async { self.recognizeFromMic() } } func recognizeFromMic() { var speechConfig: SPXSpeechConfiguration? do { try speechConfig = SPXSpeechConfiguration(subscription: sub, region: region) } catch { print("error \(error) happened") speechConfig = nil } speechConfig?.speechRecognitionLanguage = "en-US" let audioConfig = SPXAudioConfiguration() let reco = try! SPXSpeechRecognizer(speechConfiguration: speechConfig!, audioConfiguration: audioConfig) reco.addRecognizingEventHandler() {reco, evt in print("intermediate recognition result: \(evt.result.text ?? "(no result)")") self.updateLabel(text: evt.result.text, color: .gray) } updateLabel(text: "Listening ...", color: .gray) print("Listening...") let result = try! reco.recognizeOnce() print("recognition result: \(result.text ?? "(no result)"), reason: \(result.reason.rawValue)") updateLabel(text: result.text, color: .black) if result.reason != SPXResultReason.recognizedSpeech { let cancellationDetails = try! SPXCancellationDetails(fromCanceledRecognitionResult: result) print("cancelled: \(result.reason), \(cancellationDetails.errorDetails)") print("Did you set the speech resource key and region values?") updateLabel(text: "Error: \(cancellationDetails.errorDetails)", color: .red) } } func updateLabel(text: String?, color: NSColor) { DispatchQueue.main.async { self.label.stringValue = text! self.label.textColor = color } } }Verwenden Sie in AppDelegate.m die zuvor festgelegten Umgebungsvariablen für den Speech-Ressourcenschlüssel und die Region.
sub = ProcessInfo.processInfo.environment["SPEECH_KEY"] region = ProcessInfo.processInfo.environment["SPEECH_REGION"]Um die Sprache für die Spracherkennung zu ändern, ersetzen Sie
en-USdurch eine andereen-US. Verwenden Sie für Spanisch (Spanien) z. B.es-ES. Wenn Sie keine Sprache angeben, lautet der Standardwerten-US. Ausführliche Informationen zum Identifizieren einer von mehreren Sprachen, die gesprochen werden können, finden Sie unter Sprachenerkennung.Um die Debugausgabe anzuzeigen, wählen Sie Ansicht>Debugbereich>Konsole aktivieren aus.
Erstellen Sie den Beispielcode, und führen Sie ihn aus, indem Sie im Menü Produkt>Ausführen auswählen oder auf die Schaltfläche Wiedergeben klicken.
Wichtig
Stellen Sie sicher, dass Sie die Umgebungsvariablen
SPEECH_KEYundSPEECH_REGIONfestlegen. Wenn Sie diese Variablen nicht festlegen, wird für das Beispiel eine Fehlermeldung ausgegeben.
Nachdem Sie die Schaltfläche in der Anwendung ausgewählt und ein paar Worte gesagt haben, sollten Sie den von Ihnen gesprochenen Text im unteren Teil des Bildschirms sehen. Wenn Sie die Anwendung zum ersten Mal starten, werden Sie aufgefordert, der Anwendung Zugriff auf das Mikrofon Ihres Computers zu gewähren.
Hinweise
In diesem Beispiel wird der Vorgang recognizeOnce verwendet, um Äußerungen von bis zu 30 Sekunden oder bis zur Erkennung von Stille zu transkribieren. Informationen zur kontinuierlichen Erkennung längerer Audiodaten, einschließlich mehrsprachiger Konversationen, finden Sie unter Erkennen von Sprache.
Objective-C
Das Speech SDK für Objective-C teilt sich Clientbibliotheken und die Referenzdokumentation mit dem Speech SDK für Swift. Codebeispiele für Objective-C finden Sie im Beispielprojekt Erkennen von Spracheingaben per Mikrofon in Objective-C unter macOS in GitHub.
Bereinigen von Ressourcen
Sie können das Azure-Portal oder die Azure-Befehlszeilenschnittstelle (CLI) verwenden, um die erstellte Speech-Ressource zu entfernen.
REST-API-Referenz für die Spracherkennung | REST-API-Referenz für die Spracherkennung für kurze Audiodateien | Zusätzliche Beispiele auf GitHub
In dieser Schnellstartanleitung erstellen und führen Sie eine Anwendung zum Erkennen und Transkribieren von Sprache in Text in Echtzeit aus.
Weitere Informationen zum asynchronen Transkribieren von Audiodateien finden Sie unter Was ist die Batch-Transkription?. Wenn Sie nicht sicher sind, welche Spracherkennungslösung für Sie geeignet ist, finden Sie unter Was ist Spracherkennung? weitere Informationen.
Voraussetzungen
- Ein Azure-Abonnement. Sie können ein kostenloses Konto erstellen.
- Erstellen Sie eine Speech-Ressource im Azure-Portal.
- Abrufen des Speech-Ressourcenschlüssel und des Endpunkts. Wählen Sie nach der Bereitstellung Ihrer Speech-Ressource Zu Ressource wechseln aus, um Schlüssel anzuzeigen und zu verwalten.
Sie benötigen auch eine WAV-Audiodatei auf Ihrem lokalen Computer. Sie können Ihre eigene WAV-Datei (bis zu 60 Sekunden) verwenden oder die Beispieldatei https://crbn.us/whatstheweatherlike.wav herunterladen.
Festlegen von Umgebungsvariablen
Sie müssen Ihre Anwendung authentifizieren, um auf Azure KI Services zuzugreifen. In diesem Artikel wird erläutert, wie Sie Umgebungsvariablen verwenden, um Ihre Anmeldeinformationen zu speichern. Anschließend können Sie von Ihrem Code aus auf die Umgebungsvariablen zugreifen, um Ihre Anwendung zu authentifizieren. Verwenden Sie in der Produktion eine sicherere Methode, Ihre Anmeldeinformationen zu speichern und darauf zuzugreifen.
Wichtig
Es wird empfohlen, die Microsoft Entra ID-Authentifizierung mit verwalteten Identitäten für Azure-Ressourcen zu kombinieren, um das Speichern von Anmeldeinformationen mit den in der Cloud ausgeführten Anwendungen zu vermeiden.
Wenn Sie einen API-Schlüssel verwenden, speichern Sie ihn an einer anderen Stelle sicher, z. B. in Azure Key Vault. Fügen Sie den API-Schlüssel nicht direkt in Ihren Code ein, und machen Sie ihn nicht öffentlich zugänglich.
Weitere Informationen zur Sicherheit von KI Services finden Sie unter Authentifizieren von Anforderungen an Azure KI Services.
Um die Umgebungsvariable für Ihren Speech-Ressourcenschlüssel und die Region festzulegen, öffnen Sie ein Konsolenfenster, und befolgen Sie die Anweisungen für Ihr Betriebssystem und Ihre Entwicklungsumgebung.
- Zum Festlegen der Umgebungsvariablen
SPEECH_KEYersetzen Sie your-key durch einen der Schlüssel für Ihre Ressource. - Zum Festlegen der Umgebungsvariablen
SPEECH_REGIONersetzen Sie your-region durch eine der Regionen für Ihre Ressource.
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
Hinweis
Wenn Sie nur in der aktuellen Konsole auf die Umgebungsvariable zugreifen müssen, können Sie die Variable mit set anstatt setx festlegen.
Nachdem Sie die Umgebungsvariablen hinzugefügt haben, müssen Sie möglicherweise alle Programme neu starten, die die Umgebungsvariablen lesen müssen, einschließlich des Konsolenfensters. Wenn Sie beispielsweise Visual Studio als Editor verwenden, starten Sie Visual Studio neu, bevor Sie das Beispiel ausführen.
Erkennen von Sprache aus einer Datei
Öffnen Sie ein Konsolenfenster, und führen Sie den folgenden cURL-Befehl aus. Ersetzen Sie YourAudioFile.wav durch den Pfad und den Namen Ihrer Audiodatei.
curl --location --request POST "https://%SPEECH_REGION%.stt.speech.microsoft.com/speech/recognition/conversation/cognitiveservices/v1?language=en-US&format=detailed" ^
--header "Ocp-Apim-Subscription-Key: %SPEECH_KEY%" ^
--header "Content-Type: audio/wav" ^
--data-binary "@YourAudioFile.wav"
Wichtig
Stellen Sie sicher, dass Sie die Umgebungsvariablen SPEECH_KEY und SPEECH_REGION festlegen. Wenn Sie diese Variablen nicht festlegen, wird für das Beispiel eine Fehlermeldung ausgegeben.
Sie sollten eine Antwort empfangen, die in etwa wie das folgende Beispiel aussieht. DisplayText sollte der Text sein, der aus Ihrer Audiodatei erkannt wurde. Der Befehl erkennt bis zu 60 Sekunden Audiodaten und konvertiert sie in Text.
{
"RecognitionStatus": "Success",
"DisplayText": "My voice is my passport, verify me.",
"Offset": 6600000,
"Duration": 32100000
}
Weitere Informationen finden Sie unter Spracherkennung-REST-API für kurze Audiodaten.
Bereinigen von Ressourcen
Sie können das Azure-Portal oder die Azure-Befehlszeilenschnittstelle (CLI) verwenden, um die erstellte Speech-Ressource zu entfernen.
In dieser Schnellstartanleitung erstellen und führen Sie eine Anwendung zum Erkennen und Transkribieren von Sprache in Text in Echtzeit aus.
Weitere Informationen zum asynchronen Transkribieren von Audiodateien finden Sie unter Was ist die Batch-Transkription?. Wenn Sie nicht sicher sind, welche Spracherkennungslösung für Sie geeignet ist, finden Sie unter Was ist Spracherkennung? weitere Informationen.
Voraussetzungen
- Ein Azure-Abonnement. Sie können ein kostenloses Konto erstellen.
- Erstellen Sie eine Speech-Ressource im Azure-Portal.
- Abrufen des Speech-Ressourcenschlüssel und des Endpunkts. Wählen Sie nach der Bereitstellung Ihrer Speech-Ressource Zu Ressource wechseln aus, um Schlüssel anzuzeigen und zu verwalten.
Einrichten der Umgebung
Befolgen Sie diese Schritte und lesen Sie die Schnellstartanleitung für Speech CLI, um weitere Anforderungen für Ihre Plattform zu erfahren.
Führen Sie den folgenden .NET CLI-Befehl aus, um die Speech CLI zu installieren:
dotnet tool install --global Microsoft.CognitiveServices.Speech.CLIFühren Sie die folgenden Befehle aus, um Ihren Speech-Ressourcenschlüssel und Ihre Region zu konfigurieren. Ersetzen Sie
SUBSCRIPTION-KEYdurch den Schlüssel Ihrer Speech-Ressource undREGIONdurch die Region Ihrer Speech-Ressource.spx config @key --set SUBSCRIPTION-KEY spx config @region --set REGION
Erkennen von Spracheingaben per Mikrofon
Führen Sie den folgenden Befehl aus, um die Spracherkennung über ein Mikrofon zu starten:
spx recognize --microphone --source en-USSprechen Sie in das Mikrofon, und Sie sehen in Echtzeit die Transkription Ihrer Worte in Text. Die Speech CLI wird angehalten, wenn 30 Sekunden lang Stille herrscht oder Sie STRG+C drücken.
Connection CONNECTED... RECOGNIZED: I'm excited to try speech to text.
Hinweise
Im Folgenden finden Sie einige weitere Überlegungen dazu:
Verwenden Sie
--fileanstelle von--microphone, um Sprache aus einer Audiodatei zu erkennen. Wenn Sie komprimierte Audiodateien wie beispielsweise MP4 verwenden, installieren Sie GStreamer, und verwenden Sie--format. Weitere Informationen finden Sie unter Verwenden von komprimierten Eingabeaudiodaten.spx recognize --file YourAudioFile.wav spx recognize --file YourAudioFile.mp4 --format anyVerwenden Sie eine Ausdrucksliste, um die Erkennungsgenauigkeit bestimmter Wörter oder Äußerungen zu verbessern. Sie fügen eine Phrasenliste linear oder mit einer Textdatei zusammen mit dem
recognize-Befehl ein:spx recognize --microphone --phrases "Contoso;Jessie;Rehaan;" spx recognize --microphone --phrases @phrases.txtUm die Sprache für die Spracherkennung zu ändern, ersetzen Sie
en-USdurch eine andereen-US. Verwenden Sie für Spanisch (Spanien) z. B.es-ES. Wenn Sie keine Sprache angeben, lautet der Standardwerten-US.spx recognize --microphone --source es-ESUm eine kontinuierliche Erkennung von Audiodaten zu erreichen, die länger als 30 Sekunden dauern, fügen Sie
--continuousan:spx recognize --microphone --source es-ES --continuousFühren Sie diesen Befehl aus, um weitere Informationen zu zusätzlichen Spracherkennungsoptionen wie Dateieingabe und -ausgabe zu erhalten:
spx help recognize
Bereinigen von Ressourcen
Sie können das Azure-Portal oder die Azure-Befehlszeilenschnittstelle (CLI) verwenden, um die erstellte Speech-Ressource zu entfernen.