Schnellstart: Erkennen von Absichten mit Conversational Language Understanding
Referenzdokumentation | Paket (NuGet) | Zusätzliche Beispiele auf GitHub
In diesem Schnellstart verwenden Sie Speech- und Sprachdienste, um Absichten aus Audiodaten zu erkennen, die von einem Mikrofon aufgezeichnet wurden. Insbesondere verwenden Sie den Speech-Dienst, um Sprache zu erkennen, und ein Conversational Language Understanding (CLU)-Modell, um Absichten zu identifizieren.
Wichtig
Conversational Language Understanding (CLU) ist für C# und C++ mit dem Speech-SDK Version 1.25 oder höher verfügbar.
Voraussetzungen
- Ein Azure-Abonnement. Sie können ein kostenloses Konto erstellen.
- Erstellen einer Sprachressource im Azure-Portal.
- Abrufen des Sprachressourcenschlüssels und des Endpunkts. Wählen Sie nach der Bereitstellung Ihrer Sprachressource Zu Ressource wechseln aus, um Schlüssel anzuzeigen und zu verwalten.
- Erstellen Sie eine Speech-Ressource im Azure-Portal.
- Abrufen des Speech-Ressourcenschlüssel und des Endpunkts. Wählen Sie nach der Bereitstellung Ihrer Speech-Ressource Zu Ressource wechseln aus, um Schlüssel anzuzeigen und zu verwalten.
Einrichten der Umgebung
Das Speech SDK ist als NuGet-Paket verfügbar und implementiert .NET Standard 2.0. Sie installieren das Speech SDK im weiteren Verlauf dieses Leitfadens. Überprüfen Sie jedoch zunächst im SDK-Installationsleitfaden, ob weitere Anforderungen gelten.
Festlegen von Umgebungsvariablen
In diesem Beispiel sind Umgebungsvariablen mit den Namen LANGUAGE_KEY, LANGUAGE_ENDPOINT, SPEECH_KEY und SPEECH_REGION erforderlich.
Ihre Anwendung muss authentifiziert werden, um auf die Azure KI Services-Ressourcen zugreifen zu können. In diesem Artikel wird erläutert, wie Sie Umgebungsvariablen verwenden, um Ihre Anmeldeinformationen zu speichern. Anschließend können Sie von Ihrem Code aus auf die Umgebungsvariablen zugreifen, um Ihre Anwendung zu authentifizieren. Verwenden Sie in der Produktion eine sicherere Methode, Ihre Anmeldeinformationen zu speichern und darauf zuzugreifen.
Wichtig
Es wird empfohlen, die Microsoft Entra ID-Authentifizierung mit verwalteten Identitäten für Azure-Ressourcen zu kombinieren, um das Speichern von Anmeldeinformationen mit den in der Cloud ausgeführten Anwendungen zu vermeiden.
Wenn Sie einen API-Schlüssel verwenden, speichern Sie ihn an einer anderen Stelle sicher, z. B. in Azure Key Vault. Fügen Sie den API-Schlüssel nicht direkt in Ihren Code ein, und machen Sie ihn nicht öffentlich zugänglich.
Weitere Informationen zur Sicherheit von KI Services finden Sie unter Authentifizieren von Anforderungen an Azure KI Services.
Zum Festlegen der Umgebungsvariable für Ihren Ressourcenschlüssel öffnen Sie ein Konsolenfenster und befolgen die Anweisungen für Ihr Betriebssystem und Ihre Entwicklungsumgebung.
- Zum Festlegen der Umgebungsvariablen
LANGUAGE_KEYersetzen Sieyour-language-keydurch einen der Schlüssel für Ihre Ressource. - Zum Festlegen der Umgebungsvariablen
LANGUAGE_ENDPOINTersetzen Sieyour-language-endpointdurch eine der Regionen für Ihre Ressource. - Zum Festlegen der Umgebungsvariablen
SPEECH_KEYersetzen Sieyour-speech-keydurch einen der Schlüssel für Ihre Ressource. - Zum Festlegen der Umgebungsvariablen
SPEECH_REGIONersetzen Sieyour-speech-regiondurch eine der Regionen für Ihre Ressource.
setx LANGUAGE_KEY your-language-key
setx LANGUAGE_ENDPOINT your-language-endpoint
setx SPEECH_KEY your-speech-key
setx SPEECH_REGION your-speech-region
Hinweis
Wenn Sie nur in der aktuell ausgeführten Konsole auf die Umgebungsvariable zugreifen müssen, können Sie die Umgebungsvariable mit set anstelle von setx festlegen.
Nachdem Sie die Umgebungsvariablen hinzugefügt haben, müssen Sie unter Umständen alle ausgeführten Programme neu starten, die die Umgebungsvariablen lesen müssen, einschließlich des Konsolenfensters. Wenn Sie beispielsweise Visual Studio als Editor verwenden, müssen Sie Visual Studio neu starten, bevor Sie das Beispiel ausführen.
Erstellen eines Conversational Language Understanding-Projekts
Sobald Sie eine Sprachressource erstellt haben, erstellen Sie ein Conversational Language Understanding-Projekt im Sprachstudio. Ein Projekt ist ein Arbeitsbereich zum Erstellen Ihrer benutzerdefinierten ML-Modelle auf der Grundlage Ihrer Daten. Auf Ihr Projekt können nur Sie und andere Personen zugreifen, die Zugriff auf die verwendete Sprachressource haben.
Wechseln Sie zu Language Studio, und melden Sie sich mit Ihrem Azure-Konto an.
Erstellen eines Conversational Language Understanding-Projekts
Für die Zwecke dieser Schnellstartanleitung können Sie dieses Beispielprojekt zur Hausautomatisierung herunterladen und es importieren. Dieses Projekt kann die beabsichtigten Befehle von Benutzereingaben vorhersagen, z. B. das Ein- und Ausschalten des Lichts.
Suchen Sie in Language Studio den Abschnitt Understand questions and conversational language (Fragen und Unterhaltungssprache verstehen), und wählen Sie Conversational Language Understanding (Language Understanding für Unterhaltungen) aus.

Dadurch gelangen Sie zur Seite Conversational Language Understanding-Projekte. Wählen Sie neben der Schaltfläche Neues Projekt erstellen die Option Importieren aus.
Laden Sie im angezeigten Fenster die JSON-Datei hoch, die Sie importieren möchten. Vergewissern Sie sich, dass Ihre Datei dem unterstützten JSON-Format entspricht.


Sobald der Upload abgeschlossen ist, landen Sie auf der Seite Schemadefinition. Für diese Schnellstartanleitung wurde das Schema bereits erstellt, und die Ausdrücke wurden bereits mit Absichten und Entitäten bezeichnet.
Trainieren Ihres Modells
Normalerweise sollten Sie nach dem Erstellen eines Projekts ein Schema erstellen und Äußerungen mit Bezeichnungen versehen. Für diese Schnellstartanleitung haben wir bereits ein fertiges Projekt mit erstelltem Schema und bezeichneten Äußerungen importiert.
Um ein Modell zu trainieren, müssen Sie einen Trainingsauftrag starten. Die Ausgabe eines erfolgreichen Trainingsauftrags ist Ihr trainiertes Modell.
So beginnen Sie das Training Ihres Modells über Language Studio:
Wählen Sie im Menü auf der linken Seite Modell testen aus.
Wählen Sie im oberen Menü Trainingsauftrag starten aus.
Wählen Sie Neues Modell trainieren aus, und geben Sie im Textfeld einen neuen Modellnamen ein. Um andernfalls ein vorhandenes Modell durch ein Modell zu ersetzen, das mit den neuen Daten trainiert wurde, wählen Sie Ein vorhandenes Modell überschreiben und dann ein vorhandenes Modell aus. Das Überschreiben eines trainierten Modells kann nicht rückgängig gemacht werden, wirkt sich jedoch erst auf Ihre bereitgestellten Modelle aus, wenn Sie das neue Modell bereitstellen.
Wählen Sie den Trainingsmodus aus. Sie können Standardtraining für schnelleres Training auswählen, dies ist aber nur für Englisch verfügbar. Alternativ können Sie Erweitertes Training auswählen, das für andere Sprachen und mehrsprachige Projekte unterstützt wird, dies bringt aber eine längere Trainingsdauer mit sich. Erfahren Sie mehr über Trainingsmodi.
Wählen Sie eine Methode zur Datenaufteilung aus. Sie können Automatically splitting the testing set from training data (Automatisches Abspalten des Testdatasets aus den Trainingsdaten) auswählen. Dabei teilt das System Ihre Äußerungen gemäß den angegebenen Prozentsätzen zwischen den Trainings- und Testdatasets auf. Alternativ können Sie Manuelle Aufteilung von Trainings- und Testdaten verwenden nutzen. Diese Option ist nur aktiviert, wenn Sie Ihrem Testdatensatz Äußerungen während des Bezeichnens von Äußerungen hinzugefügt haben.
Wählen Sie die Schaltfläche Train (Trainieren) aus.
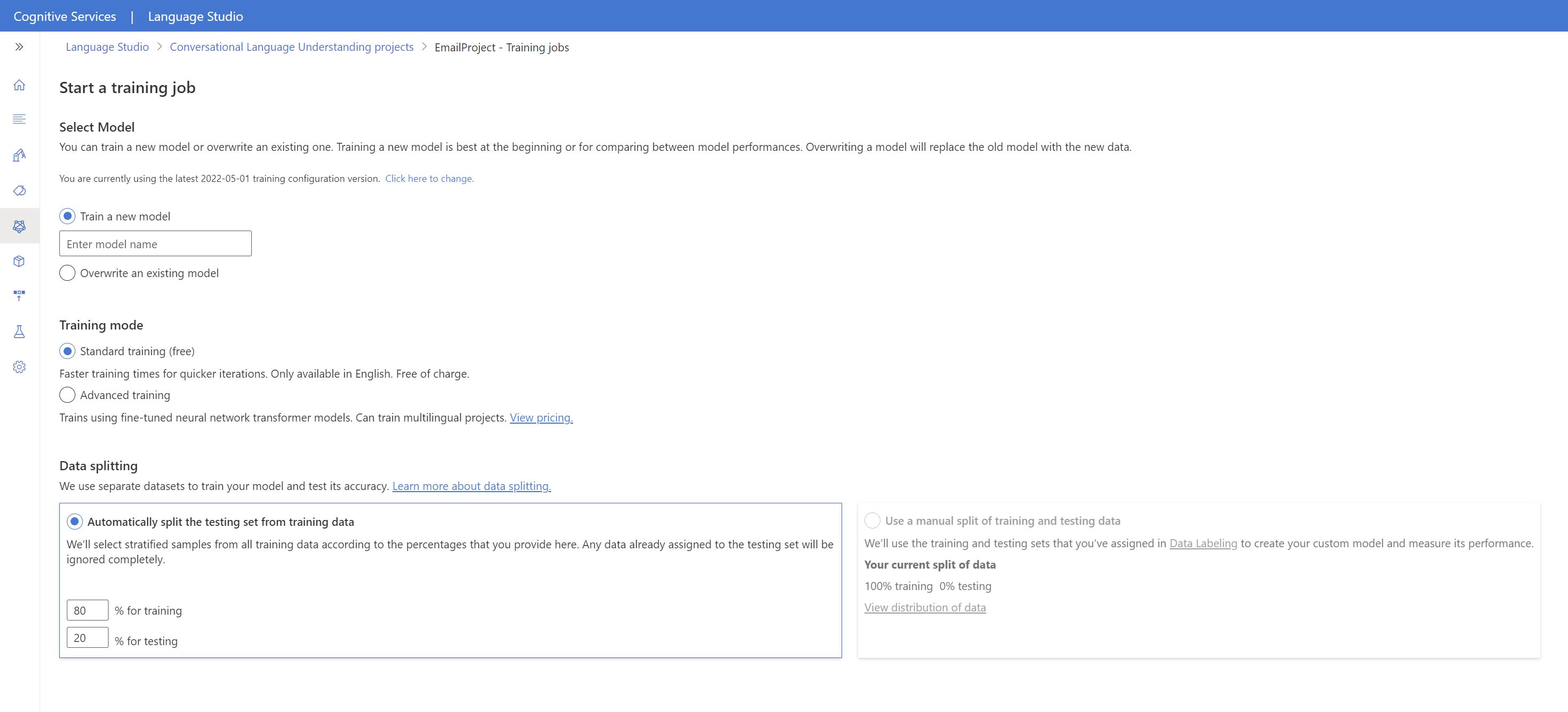
Wählen Sie in der Liste die ID des Trainingsauftrags aus. Ein Bereich wird angezeigt, in dem Sie den Trainingsfortschritt, den Auftragsstatus und andere Details für diesen Auftrag überprüfen können.
Hinweis
- Nur erfolgreich abgeschlossene Trainingsaufträge generieren Modelle.
- Je nach Anzahl der Äußerungen kann das Training wenige Minuten oder mehrere Stunden dauern.
- Es kann jeweils nur ein Trainingsauftrag ausgeführt werden. Sie können keinen anderen Trainingsauftrag innerhalb desselben Projekts starten, bis der laufende Auftrag abgeschlossen ist.
- Das maschinelle Lernen, das zum Trainieren von Modellen verwendet wird, wird regelmäßig aktualisiert. Um mit einer früheren Konfigurationsversion zu trainieren, wählen Sie die Option Hier zum ändern auswählen auf der Seite Trainingsauftrag starten aus und wählen Sie eine frühere Version aus.

Bereitstellen Ihres Modells
Im Allgemeinen überprüfen Sie nach dem Trainieren eines Modells seine Auswertungsdetails. In diesem Schnellstart stellen Sie einfach Ihr Modell bereit und stellen es zur Verfügung, um es in Language Studio auszuprobieren, oder Sie können die Vorhersage-API aufrufen.
So stellen Sie Ihr Modell über Language Studio bereit:
Wählen Sie im Menü auf der linken Seite Bereitstellen eines Modells aus.
Wählen Sie Bereitstellung hinzufügen aus, um den Assistenten zum Hinzufügen einer Bereitstellung zu starten.

Wählen Sie Neuen Bereitstellungsnamen erstellen aus, um eine neue Bereitstellung zu erstellen und ein trainiertes Modell aus der Dropdownliste unten zuzuweisen. Andernfalls können Sie einen vorhandenen Bereitstellungsnamen überschreiben auswählen, um effektiv das Modell zu ersetzen, das von einer vorhandenen Bereitstellung verwendet wird.
Hinweis
Das Überschreiben einer vorhandenen Bereitstellung erfordert keine Änderungen an Ihrem Aufruf der Vorhersage-API, aber die Ergebnisse, die Sie erhalten, basieren auf dem neu zugewiesenen Modell.
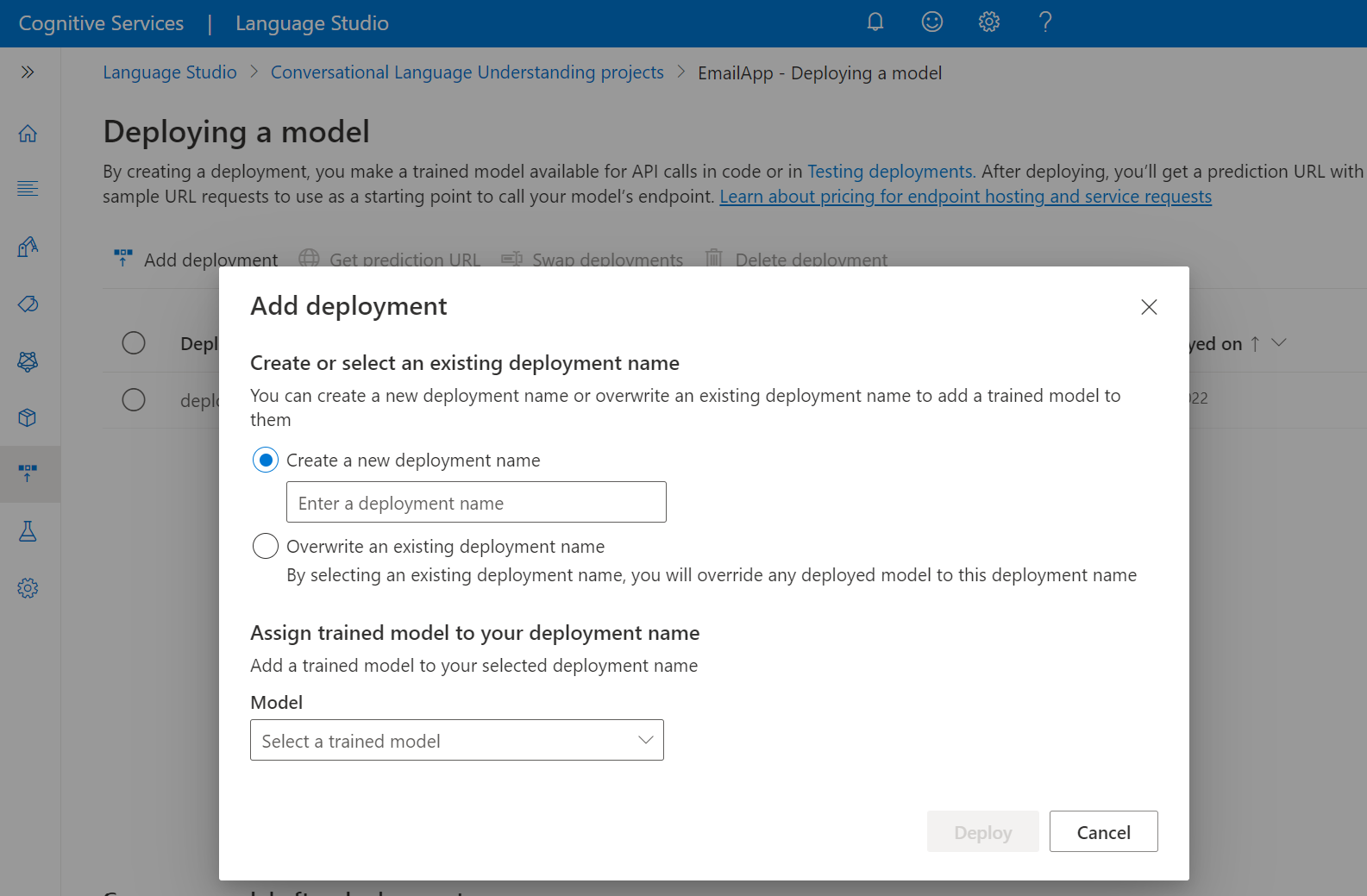
Wählen Sie in der Dropdownliste Modell ein trainiertes Modell aus.
Wählen Sie Bereitstellen aus, um die Bereitstellungsauftrag zu starten.
Nachdem die Bereitstellung ausgeführt wurde, wird ein Ablaufdatum neben dem Vorgang angezeigt. Die Bereitstellung läuft ab, wenn Ihr bereitgestelltes Modell für die Prognose nicht verfügbar ist, was in der Regel zwölf Monate nach Ablauf einer Trainingskonfiguration erfolgt.


Sie werden im nächsten Abschnitt den Projektnamen und den Bereitstellungsnamen verwenden.
Erkennen von Absichten über ein Mikrofon
Führen Sie die folgenden Schritte aus, um eine neue Konsolenanwendung zu erstellen und das Speech SDK zu installieren.
Öffnen Sie am Speicherort, an dem Sie das neue Projekt erstellen möchten, eine Eingabeaufforderung, und erstellen Sie mit der .NET-CLI eine Konsolenanwendung. Die Datei
Program.cssollte im Projektverzeichnis erstellt werden.dotnet new consoleInstallieren Sie das Speech SDK mit der .NET-CLI in Ihrem neuen Projekt.
dotnet add package Microsoft.CognitiveServices.SpeechErsetzen Sie den Inhalt von
Program.csdurch den folgenden Code.using Microsoft.CognitiveServices.Speech; using Microsoft.CognitiveServices.Speech.Audio; using Microsoft.CognitiveServices.Speech.Intent; class Program { // This example requires environment variables named: // "LANGUAGE_KEY", "LANGUAGE_ENDPOINT", "SPEECH_KEY", and "SPEECH_REGION" static string languageKey = Environment.GetEnvironmentVariable("LANGUAGE_KEY"); static string languageEndpoint = Environment.GetEnvironmentVariable("LANGUAGE_ENDPOINT"); static string speechKey = Environment.GetEnvironmentVariable("SPEECH_KEY"); static string speechRegion = Environment.GetEnvironmentVariable("SPEECH_REGION"); // Your CLU project name and deployment name. static string cluProjectName = "YourProjectNameGoesHere"; static string cluDeploymentName = "YourDeploymentNameGoesHere"; async static Task Main(string[] args) { var speechConfig = SpeechConfig.FromSubscription(speechKey, speechRegion); speechConfig.SpeechRecognitionLanguage = "en-US"; using var audioConfig = AudioConfig.FromDefaultMicrophoneInput(); // Creates an intent recognizer in the specified language using microphone as audio input. using (var intentRecognizer = new IntentRecognizer(speechConfig, audioConfig)) { var cluModel = new ConversationalLanguageUnderstandingModel( languageKey, languageEndpoint, cluProjectName, cluDeploymentName); var collection = new LanguageUnderstandingModelCollection(); collection.Add(cluModel); intentRecognizer.ApplyLanguageModels(collection); Console.WriteLine("Speak into your microphone."); var recognitionResult = await intentRecognizer.RecognizeOnceAsync().ConfigureAwait(false); // Checks result. if (recognitionResult.Reason == ResultReason.RecognizedIntent) { Console.WriteLine($"RECOGNIZED: Text={recognitionResult.Text}"); Console.WriteLine($" Intent Id: {recognitionResult.IntentId}."); Console.WriteLine($" Language Understanding JSON: {recognitionResult.Properties.GetProperty(PropertyId.LanguageUnderstandingServiceResponse_JsonResult)}."); } else if (recognitionResult.Reason == ResultReason.RecognizedSpeech) { Console.WriteLine($"RECOGNIZED: Text={recognitionResult.Text}"); Console.WriteLine($" Intent not recognized."); } else if (recognitionResult.Reason == ResultReason.NoMatch) { Console.WriteLine($"NOMATCH: Speech could not be recognized."); } else if (recognitionResult.Reason == ResultReason.Canceled) { var cancellation = CancellationDetails.FromResult(recognitionResult); Console.WriteLine($"CANCELED: Reason={cancellation.Reason}"); if (cancellation.Reason == CancellationReason.Error) { Console.WriteLine($"CANCELED: ErrorCode={cancellation.ErrorCode}"); Console.WriteLine($"CANCELED: ErrorDetails={cancellation.ErrorDetails}"); Console.WriteLine($"CANCELED: Did you update the subscription info?"); } } } } }Legen Sie in
Program.csdiecluProjectName- undcluDeploymentName-Variablen auf die Namen Ihres Projekts und Ihrer Bereitstellung fest. Informationen zum Erstellen eines CLU-Projekts und dessen Bereitstellung finden Sie unter Erstellen eines Conversational Language Understanding-Projekts.Um die Sprache für die Spracherkennung zu ändern, ersetzen Sie
en-USdurch eine andereen-US. Beispiel:es-ESfür Spanisch (Spanien). Die Standardsprache isten-US, wenn Sie keine Sprache angeben. Ausführliche Informationen zum Identifizieren einer von mehreren Sprachen, die gesprochen werden können, finden Sie unter Sprachenerkennung.
Führen Sie die neue Konsolenanwendung aus, um die Spracherkennung über ein Mikrofon zu starten:
dotnet run
Wichtig
Stellen Sie sicher, dass Sie die Umgebungsvariablen LANGUAGE_KEY, LANGUAGE_ENDPOINT, SPEECH_KEY und SPEECH_REGION wie oben beschrieben festlegen. Wenn Sie diese Variablen nicht festlegen, wird für das Beispiel eine Fehlermeldung ausgegeben.
Sprechen Sie in Ihr Mikrofon, wenn Sie dazu aufgefordert werden. Die Wörter, die Sie sprechen, sollten als Text ausgegeben werden:
Speak into your microphone.
RECOGNIZED: Text=Turn on the lights.
Intent Id: HomeAutomation.TurnOn.
Language Understanding JSON: {"kind":"ConversationResult","result":{"query":"turn on the lights","prediction":{"topIntent":"HomeAutomation.TurnOn","projectKind":"Conversation","intents":[{"category":"HomeAutomation.TurnOn","confidenceScore":0.97712576},{"category":"HomeAutomation.TurnOff","confidenceScore":0.8431633},{"category":"None","confidenceScore":0.782861}],"entities":[{"category":"HomeAutomation.DeviceType","text":"lights","offset":12,"length":6,"confidenceScore":1,"extraInformation":[{"extraInformationKind":"ListKey","key":"light"}]}]}}}.
Hinweis
Unterstützung für die JSON-Antwort für CLU über die Eigenschaft LanguageUnderstandingServiceResponse_JsonResult wurde in Speech SDK Version 1.26 hinzugefügt.
Die Absichten werden in der Wahrscheinlichkeitsreihenfolge von höchstwahrscheinlich bis am wenigsten wahrscheinlich zurückgegeben. Dies ist eine formatierte Version der JSON-Ausgabe, bei der topIntent der HomeAutomation.TurnOn ist, mit einem Konfidenzwert von 0,97712576 (97,71 %) Die zweitwahrscheinlichste Absicht könnte HomeAutomation.TurnOff mit einem Konfidenzscore von 0,8985081 (84,31 %) sein.
{
"kind": "ConversationResult",
"result": {
"query": "turn on the lights",
"prediction": {
"topIntent": "HomeAutomation.TurnOn",
"projectKind": "Conversation",
"intents": [
{
"category": "HomeAutomation.TurnOn",
"confidenceScore": 0.97712576
},
{
"category": "HomeAutomation.TurnOff",
"confidenceScore": 0.8431633
},
{
"category": "None",
"confidenceScore": 0.782861
}
],
"entities": [
{
"category": "HomeAutomation.DeviceType",
"text": "lights",
"offset": 12,
"length": 6,
"confidenceScore": 1,
"extraInformation": [
{
"extraInformationKind": "ListKey",
"key": "light"
}
]
}
]
}
}
}
Bemerkungen
Nachdem Sie die Schnellstartanleitung abgeschlossen haben, finden Sie hier einige zusätzliche Überlegungen:
- In diesem Beispiel wird der Vorgang
RecognizeOnceAsyncverwendet, um Äußerungen von bis zu 30 Sekunden oder bis zur Erkennung von Stille zu transkribieren. Informationen zur kontinuierlichen Erkennung längerer Audiodaten, einschließlich mehrsprachiger Konversationen, finden Sie unter Erkennen von Sprache. - Verwenden Sie
FromWavFileInputanstelle vonFromDefaultMicrophoneInput, um Sprache aus einer Audiodatei zu erkennen:using var audioConfig = AudioConfig.FromWavFileInput("YourAudioFile.wav"); - Wenn Sie komprimierte Audiodateien wie beispielsweise MP4 verwenden, installieren Sie GStreamer, und verwenden Sie
PullAudioInputStreamoderPushAudioInputStream. Weitere Informationen finden Sie unter Verwenden von komprimierten Eingabeaudiodaten.
Bereinigen von Ressourcen
Sie können das Azure-Portal oder die Azure-Befehlszeilenschnittstelle (Command Line Interface, CLI) verwenden, um die erstellten Sprach- und Speech-Ressourcen zu entfernen.
Referenzdokumentation | Paket (NuGet) | Zusätzliche Beispiele auf GitHub
In diesem Schnellstart verwenden Sie Speech- und Sprachdienste, um Absichten aus Audiodaten zu erkennen, die von einem Mikrofon aufgezeichnet wurden. Insbesondere verwenden Sie den Speech-Dienst, um Sprache zu erkennen, und ein Conversational Language Understanding (CLU)-Modell, um Absichten zu identifizieren.
Wichtig
Conversational Language Understanding (CLU) ist für C# und C++ mit dem Speech-SDK Version 1.25 oder höher verfügbar.
Voraussetzungen
- Ein Azure-Abonnement. Sie können ein kostenloses Konto erstellen.
- Erstellen einer Sprachressource im Azure-Portal.
- Abrufen des Sprachressourcenschlüssels und des Endpunkts. Wählen Sie nach der Bereitstellung Ihrer Sprachressource Zu Ressource wechseln aus, um Schlüssel anzuzeigen und zu verwalten.
- Erstellen Sie eine Speech-Ressource im Azure-Portal.
- Abrufen des Speech-Ressourcenschlüssel und des Endpunkts. Wählen Sie nach der Bereitstellung Ihrer Speech-Ressource Zu Ressource wechseln aus, um Schlüssel anzuzeigen und zu verwalten.
Einrichten der Umgebung
Das Speech SDK ist als NuGet-Paket verfügbar und implementiert .NET Standard 2.0. Sie installieren das Speech SDK im weiteren Verlauf dieses Leitfadens. Überprüfen Sie jedoch zunächst im SDK-Installationsleitfaden, ob weitere Anforderungen gelten.
Festlegen von Umgebungsvariablen
In diesem Beispiel sind Umgebungsvariablen mit den Namen LANGUAGE_KEY, LANGUAGE_ENDPOINT, SPEECH_KEY und SPEECH_REGION erforderlich.
Ihre Anwendung muss authentifiziert werden, um auf die Azure KI Services-Ressourcen zugreifen zu können. In diesem Artikel wird erläutert, wie Sie Umgebungsvariablen verwenden, um Ihre Anmeldeinformationen zu speichern. Anschließend können Sie von Ihrem Code aus auf die Umgebungsvariablen zugreifen, um Ihre Anwendung zu authentifizieren. Verwenden Sie in der Produktion eine sicherere Methode, Ihre Anmeldeinformationen zu speichern und darauf zuzugreifen.
Wichtig
Es wird empfohlen, die Microsoft Entra ID-Authentifizierung mit verwalteten Identitäten für Azure-Ressourcen zu kombinieren, um das Speichern von Anmeldeinformationen mit den in der Cloud ausgeführten Anwendungen zu vermeiden.
Wenn Sie einen API-Schlüssel verwenden, speichern Sie ihn an einer anderen Stelle sicher, z. B. in Azure Key Vault. Fügen Sie den API-Schlüssel nicht direkt in Ihren Code ein, und machen Sie ihn nicht öffentlich zugänglich.
Weitere Informationen zur Sicherheit von KI Services finden Sie unter Authentifizieren von Anforderungen an Azure KI Services.
Zum Festlegen der Umgebungsvariable für Ihren Ressourcenschlüssel öffnen Sie ein Konsolenfenster und befolgen die Anweisungen für Ihr Betriebssystem und Ihre Entwicklungsumgebung.
- Zum Festlegen der Umgebungsvariablen
LANGUAGE_KEYersetzen Sieyour-language-keydurch einen der Schlüssel für Ihre Ressource. - Zum Festlegen der Umgebungsvariablen
LANGUAGE_ENDPOINTersetzen Sieyour-language-endpointdurch eine der Regionen für Ihre Ressource. - Zum Festlegen der Umgebungsvariablen
SPEECH_KEYersetzen Sieyour-speech-keydurch einen der Schlüssel für Ihre Ressource. - Zum Festlegen der Umgebungsvariablen
SPEECH_REGIONersetzen Sieyour-speech-regiondurch eine der Regionen für Ihre Ressource.
setx LANGUAGE_KEY your-language-key
setx LANGUAGE_ENDPOINT your-language-endpoint
setx SPEECH_KEY your-speech-key
setx SPEECH_REGION your-speech-region
Hinweis
Wenn Sie nur in der aktuell ausgeführten Konsole auf die Umgebungsvariable zugreifen müssen, können Sie die Umgebungsvariable mit set anstelle von setx festlegen.
Nachdem Sie die Umgebungsvariablen hinzugefügt haben, müssen Sie unter Umständen alle ausgeführten Programme neu starten, die die Umgebungsvariablen lesen müssen, einschließlich des Konsolenfensters. Wenn Sie beispielsweise Visual Studio als Editor verwenden, müssen Sie Visual Studio neu starten, bevor Sie das Beispiel ausführen.
Erstellen eines Conversational Language Understanding-Projekts
Sobald Sie eine Sprachressource erstellt haben, erstellen Sie ein Conversational Language Understanding-Projekt im Sprachstudio. Ein Projekt ist ein Arbeitsbereich zum Erstellen Ihrer benutzerdefinierten ML-Modelle auf der Grundlage Ihrer Daten. Auf Ihr Projekt können nur Sie und andere Personen zugreifen, die Zugriff auf die verwendete Sprachressource haben.
Wechseln Sie zu Language Studio, und melden Sie sich mit Ihrem Azure-Konto an.
Erstellen eines Conversational Language Understanding-Projekts
Für die Zwecke dieser Schnellstartanleitung können Sie dieses Beispielprojekt zur Hausautomatisierung herunterladen und es importieren. Dieses Projekt kann die beabsichtigten Befehle von Benutzereingaben vorhersagen, z. B. das Ein- und Ausschalten des Lichts.
Suchen Sie in Language Studio den Abschnitt Understand questions and conversational language (Fragen und Unterhaltungssprache verstehen), und wählen Sie Conversational Language Understanding (Language Understanding für Unterhaltungen) aus.
Dadurch gelangen Sie zur Seite Conversational Language Understanding-Projekte. Wählen Sie neben der Schaltfläche Neues Projekt erstellen die Option Importieren aus.
Laden Sie im angezeigten Fenster die JSON-Datei hoch, die Sie importieren möchten. Vergewissern Sie sich, dass Ihre Datei dem unterstützten JSON-Format entspricht.
Sobald der Upload abgeschlossen ist, landen Sie auf der Seite Schemadefinition. Für diese Schnellstartanleitung wurde das Schema bereits erstellt, und die Ausdrücke wurden bereits mit Absichten und Entitäten bezeichnet.
Trainieren Ihres Modells
Normalerweise sollten Sie nach dem Erstellen eines Projekts ein Schema erstellen und Äußerungen mit Bezeichnungen versehen. Für diese Schnellstartanleitung haben wir bereits ein fertiges Projekt mit erstelltem Schema und bezeichneten Äußerungen importiert.
Um ein Modell zu trainieren, müssen Sie einen Trainingsauftrag starten. Die Ausgabe eines erfolgreichen Trainingsauftrags ist Ihr trainiertes Modell.
So beginnen Sie das Training Ihres Modells über Language Studio:
Wählen Sie im Menü auf der linken Seite Modell testen aus.
Wählen Sie im oberen Menü Trainingsauftrag starten aus.
Wählen Sie Neues Modell trainieren aus, und geben Sie im Textfeld einen neuen Modellnamen ein. Um andernfalls ein vorhandenes Modell durch ein Modell zu ersetzen, das mit den neuen Daten trainiert wurde, wählen Sie Ein vorhandenes Modell überschreiben und dann ein vorhandenes Modell aus. Das Überschreiben eines trainierten Modells kann nicht rückgängig gemacht werden, wirkt sich jedoch erst auf Ihre bereitgestellten Modelle aus, wenn Sie das neue Modell bereitstellen.
Wählen Sie den Trainingsmodus aus. Sie können Standardtraining für schnelleres Training auswählen, dies ist aber nur für Englisch verfügbar. Alternativ können Sie Erweitertes Training auswählen, das für andere Sprachen und mehrsprachige Projekte unterstützt wird, dies bringt aber eine längere Trainingsdauer mit sich. Erfahren Sie mehr über Trainingsmodi.
Wählen Sie eine Methode zur Datenaufteilung aus. Sie können Automatically splitting the testing set from training data (Automatisches Abspalten des Testdatasets aus den Trainingsdaten) auswählen. Dabei teilt das System Ihre Äußerungen gemäß den angegebenen Prozentsätzen zwischen den Trainings- und Testdatasets auf. Alternativ können Sie Manuelle Aufteilung von Trainings- und Testdaten verwenden nutzen. Diese Option ist nur aktiviert, wenn Sie Ihrem Testdatensatz Äußerungen während des Bezeichnens von Äußerungen hinzugefügt haben.
Wählen Sie die Schaltfläche Train (Trainieren) aus.
Wählen Sie in der Liste die ID des Trainingsauftrags aus. Ein Bereich wird angezeigt, in dem Sie den Trainingsfortschritt, den Auftragsstatus und andere Details für diesen Auftrag überprüfen können.
Hinweis
- Nur erfolgreich abgeschlossene Trainingsaufträge generieren Modelle.
- Je nach Anzahl der Äußerungen kann das Training wenige Minuten oder mehrere Stunden dauern.
- Es kann jeweils nur ein Trainingsauftrag ausgeführt werden. Sie können keinen anderen Trainingsauftrag innerhalb desselben Projekts starten, bis der laufende Auftrag abgeschlossen ist.
- Das maschinelle Lernen, das zum Trainieren von Modellen verwendet wird, wird regelmäßig aktualisiert. Um mit einer früheren Konfigurationsversion zu trainieren, wählen Sie die Option Hier zum ändern auswählen auf der Seite Trainingsauftrag starten aus und wählen Sie eine frühere Version aus.
Bereitstellen Ihres Modells
Im Allgemeinen überprüfen Sie nach dem Trainieren eines Modells seine Auswertungsdetails. In diesem Schnellstart stellen Sie einfach Ihr Modell bereit und stellen es zur Verfügung, um es in Language Studio auszuprobieren, oder Sie können die Vorhersage-API aufrufen.
So stellen Sie Ihr Modell über Language Studio bereit:
Wählen Sie im Menü auf der linken Seite Bereitstellen eines Modells aus.
Wählen Sie Bereitstellung hinzufügen aus, um den Assistenten zum Hinzufügen einer Bereitstellung zu starten.
Wählen Sie Neuen Bereitstellungsnamen erstellen aus, um eine neue Bereitstellung zu erstellen und ein trainiertes Modell aus der Dropdownliste unten zuzuweisen. Andernfalls können Sie einen vorhandenen Bereitstellungsnamen überschreiben auswählen, um effektiv das Modell zu ersetzen, das von einer vorhandenen Bereitstellung verwendet wird.
Hinweis
Das Überschreiben einer vorhandenen Bereitstellung erfordert keine Änderungen an Ihrem Aufruf der Vorhersage-API, aber die Ergebnisse, die Sie erhalten, basieren auf dem neu zugewiesenen Modell.
Wählen Sie in der Dropdownliste Modell ein trainiertes Modell aus.
Wählen Sie Bereitstellen aus, um die Bereitstellungsauftrag zu starten.
Nachdem die Bereitstellung ausgeführt wurde, wird ein Ablaufdatum neben dem Vorgang angezeigt. Die Bereitstellung läuft ab, wenn Ihr bereitgestelltes Modell für die Prognose nicht verfügbar ist, was in der Regel zwölf Monate nach Ablauf einer Trainingskonfiguration erfolgt.
Sie werden im nächsten Abschnitt den Projektnamen und den Bereitstellungsnamen verwenden.
Erkennen von Absichten über ein Mikrofon
Führen Sie die folgenden Schritte aus, um eine neue Konsolenanwendung zu erstellen und das Speech SDK zu installieren.
Erstellen Sie in Visual Studio Community 2022 ein neues C++-Konsolenprojekt mit dem Namen
SpeechRecognition.Installieren Sie das Speech SDK mit dem NuGet-Paket-Manager in Ihrem neuen Projekt.
Install-Package Microsoft.CognitiveServices.SpeechErsetzen Sie den Inhalt von
SpeechRecognition.cppdurch den folgenden Code.#include <iostream> #include <stdlib.h> #include <speechapi_cxx.h> using namespace Microsoft::CognitiveServices::Speech; using namespace Microsoft::CognitiveServices::Speech::Audio; using namespace Microsoft::CognitiveServices::Speech::Intent; std::string GetEnvironmentVariable(const char* name); int main() { // This example requires environment variables named: // "LANGUAGE_KEY", "LANGUAGE_ENDPOINT", "SPEECH_KEY", and "SPEECH_REGION" auto languageKey = GetEnvironmentVariable("LANGUAGE_KEY"); auto languageEndpoint = GetEnvironmentVariable("LANGUAGE_ENDPOINT"); auto speechKey = GetEnvironmentVariable("SPEECH_KEY"); auto speechRegion = GetEnvironmentVariable("SPEECH_REGION"); auto cluProjectName = "YourProjectNameGoesHere"; auto cluDeploymentName = "YourDeploymentNameGoesHere"; if ((size(languageKey) == 0) || (size(languageEndpoint) == 0) || (size(speechKey) == 0) || (size(speechRegion) == 0)) { std::cout << "Please set LANGUAGE_KEY, LANGUAGE_ENDPOINT, SPEECH_KEY, and SPEECH_REGION environment variables." << std::endl; return -1; } auto speechConfig = SpeechConfig::FromSubscription(speechKey, speechRegion); speechConfig->SetSpeechRecognitionLanguage("en-US"); auto audioConfig = AudioConfig::FromDefaultMicrophoneInput(); auto intentRecognizer = IntentRecognizer::FromConfig(speechConfig, audioConfig); std::vector<std::shared_ptr<LanguageUnderstandingModel>> models; auto cluModel = ConversationalLanguageUnderstandingModel::FromResource( languageKey, languageEndpoint, cluProjectName, cluDeploymentName); models.push_back(cluModel); intentRecognizer->ApplyLanguageModels(models); std::cout << "Speak into your microphone.\n"; auto result = intentRecognizer->RecognizeOnceAsync().get(); if (result->Reason == ResultReason::RecognizedIntent) { std::cout << "RECOGNIZED: Text=" << result->Text << std::endl; std::cout << " Intent Id: " << result->IntentId << std::endl; std::cout << " Intent Service JSON: " << result->Properties.GetProperty(PropertyId::LanguageUnderstandingServiceResponse_JsonResult) << std::endl; } else if (result->Reason == ResultReason::RecognizedSpeech) { std::cout << "RECOGNIZED: Text=" << result->Text << " (intent could not be recognized)" << std::endl; } else if (result->Reason == ResultReason::NoMatch) { std::cout << "NOMATCH: Speech could not be recognized." << std::endl; } else if (result->Reason == ResultReason::Canceled) { auto cancellation = CancellationDetails::FromResult(result); std::cout << "CANCELED: Reason=" << (int)cancellation->Reason << std::endl; if (cancellation->Reason == CancellationReason::Error) { std::cout << "CANCELED: ErrorCode=" << (int)cancellation->ErrorCode << std::endl; std::cout << "CANCELED: ErrorDetails=" << cancellation->ErrorDetails << std::endl; std::cout << "CANCELED: Did you update the subscription info?" << std::endl; } } } std::string GetEnvironmentVariable(const char* name) { #if defined(_MSC_VER) size_t requiredSize = 0; (void)getenv_s(&requiredSize, nullptr, 0, name); if (requiredSize == 0) { return ""; } auto buffer = std::make_unique<char[]>(requiredSize); (void)getenv_s(&requiredSize, buffer.get(), requiredSize, name); return buffer.get(); #else auto value = getenv(name); return value ? value : ""; #endif }Legen Sie in
SpeechRecognition.cppdiecluProjectName- undcluDeploymentName-Variablen auf die Namen Ihres Projekts und Ihrer Bereitstellung fest. Informationen zum Erstellen eines CLU-Projekts und dessen Bereitstellung finden Sie unter Erstellen eines Conversational Language Understanding-Projekts.Um die Sprache für die Spracherkennung zu ändern, ersetzen Sie
en-USdurch eine andereen-US. Beispiel:es-ESfür Spanisch (Spanien). Die Standardsprache isten-US, wenn Sie keine Sprache angeben. Ausführliche Informationen zum Identifizieren einer von mehreren Sprachen, die gesprochen werden können, finden Sie unter Sprachenerkennung.
Erstellen Sie die neue Konsolenanwendung, und führen Sie sie aus, um die Spracherkennung über ein Mikrofon zu starten.
Wichtig
Stellen Sie sicher, dass Sie die Umgebungsvariablen LANGUAGE_KEY, LANGUAGE_ENDPOINT, SPEECH_KEY und SPEECH_REGION wie oben beschrieben festlegen. Wenn Sie diese Variablen nicht festlegen, wird für das Beispiel eine Fehlermeldung ausgegeben.
Sprechen Sie in Ihr Mikrofon, wenn Sie dazu aufgefordert werden. Die Wörter, die Sie sprechen, sollten als Text ausgegeben werden:
Speak into your microphone.
RECOGNIZED: Text=Turn on the lights.
Intent Id: HomeAutomation.TurnOn.
Language Understanding JSON: {"kind":"ConversationResult","result":{"query":"turn on the lights","prediction":{"topIntent":"HomeAutomation.TurnOn","projectKind":"Conversation","intents":[{"category":"HomeAutomation.TurnOn","confidenceScore":0.97712576},{"category":"HomeAutomation.TurnOff","confidenceScore":0.8431633},{"category":"None","confidenceScore":0.782861}],"entities":[{"category":"HomeAutomation.DeviceType","text":"lights","offset":12,"length":6,"confidenceScore":1,"extraInformation":[{"extraInformationKind":"ListKey","key":"light"}]}]}}}.
Hinweis
Unterstützung für die JSON-Antwort für CLU über die Eigenschaft LanguageUnderstandingServiceResponse_JsonResult wurde in Speech SDK Version 1.26 hinzugefügt.
Die Absichten werden in der Wahrscheinlichkeitsreihenfolge von höchstwahrscheinlich bis am wenigsten wahrscheinlich zurückgegeben. Dies ist eine formatierte Version der JSON-Ausgabe, bei der topIntent der HomeAutomation.TurnOn ist, mit einem Konfidenzwert von 0,97712576 (97,71 %) Die zweitwahrscheinlichste Absicht könnte HomeAutomation.TurnOff mit einem Konfidenzscore von 0,8985081 (84,31 %) sein.
{
"kind": "ConversationResult",
"result": {
"query": "turn on the lights",
"prediction": {
"topIntent": "HomeAutomation.TurnOn",
"projectKind": "Conversation",
"intents": [
{
"category": "HomeAutomation.TurnOn",
"confidenceScore": 0.97712576
},
{
"category": "HomeAutomation.TurnOff",
"confidenceScore": 0.8431633
},
{
"category": "None",
"confidenceScore": 0.782861
}
],
"entities": [
{
"category": "HomeAutomation.DeviceType",
"text": "lights",
"offset": 12,
"length": 6,
"confidenceScore": 1,
"extraInformation": [
{
"extraInformationKind": "ListKey",
"key": "light"
}
]
}
]
}
}
}
Bemerkungen
Nachdem Sie die Schnellstartanleitung abgeschlossen haben, finden Sie hier einige zusätzliche Überlegungen:
- In diesem Beispiel wird der Vorgang
RecognizeOnceAsyncverwendet, um Äußerungen von bis zu 30 Sekunden oder bis zur Erkennung von Stille zu transkribieren. Informationen zur kontinuierlichen Erkennung längerer Audiodaten, einschließlich mehrsprachiger Konversationen, finden Sie unter Erkennen von Sprache. - Verwenden Sie
FromWavFileInputanstelle vonFromDefaultMicrophoneInput, um Sprache aus einer Audiodatei zu erkennen:auto audioInput = AudioConfig::FromWavFileInput("YourAudioFile.wav"); - Wenn Sie komprimierte Audiodateien wie beispielsweise MP4 verwenden, installieren Sie GStreamer, und verwenden Sie
PullAudioInputStreamoderPushAudioInputStream. Weitere Informationen finden Sie unter Verwenden von komprimierten Eingabeaudiodaten.
Bereinigen von Ressourcen
Sie können das Azure-Portal oder die Azure-Befehlszeilenschnittstelle (Command Line Interface, CLI) verwenden, um die erstellten Sprach- und Speech-Ressourcen zu entfernen.
Referenzdokumentation | Zusätzliche Beispiele auf GitHub
Das Speech-SDK für Java unterstützt keine Absichtserkennung mit Conversational Language Understanding (CLU). Bitte wählen Sie eine andere Programmiersprache aus, oder verwenden Sie die Java-Referenz und Beispiele, die am Anfang dieses Artikels verknüpft sind.