Trainieren Ihres Conversational Language Understanding-Modells
Nachdem Sie die Beschriftung Ihrer Äußerungen abgeschlossen haben, können Sie Ihr Modell trainieren. Beim Trainieren gewinnt das Modell Erkenntnisse aus Ihren beschrifteten Äußerungen.
Um ein Modell zu trainieren, müssen Sie einen Trainingsauftrag starten. Ein Modell wird nur bei erfolgreich abgeschlossenen Aufträgen erstellt. Trainingsaufträge laufen nach sieben Tagen ab. Danach können die Auftragsdetails nicht mehr abgerufen werden. Wenn Ihr Trainingsauftrag erfolgreich abgeschlossen und ein Modell erstellt wurde, ist es vom Auftragsablauf nicht betroffen. Es kann jeweils nur ein Trainingsauftrag ausgeführt werden, und Sie können keine anderen Aufträge im selben Projekt starten.
Die Trainingszeiten können zwischen wenigen Sekunden (bei einfachen Projekten) und mehreren Stunden liegen, wenn Sie die Obergrenze für Äußerungen erreichen.
Die Modellauswertung wird automatisch ausgelöst, nachdem das Training erfolgreich abgeschlossen wurde. Beim Auswertungsprozess werden zunächst auf der Grundlage des trainierten Modells Vorhersagen für die Äußerungen im Testsatz generiert und die vorhergesagten Ergebnisse mit den bereitgestellten Bezeichnungen verglichen, um eine Wahrheitsbaseline zu erhalten.
Voraussetzungen
- Ein erfolgreich erstelltes Projekt mit einem konfigurierten Azure Blob Storage-Konto
- Bezeichnete Äußerungen
Ausgewogene Trainingsdaten
Wenn es um Trainingsdaten geht, sollten Sie versuchen, Ihr Schema möglichst ausgewogen zu halten. Die Einbeziehung großer Mengen in Bezug auf eine Absicht und nur geringe Mengen zu einer anderen führt zu einem Modell, das einseitig auf bestimmte Absichten ausgerichtet ist.
Um dieses Szenario zu beheben, müssen Sie möglicherweise Ihren Trainingssatz komprimieren. Oder Sie fügen ihm Knoten hinzu. Zum Komprimieren können Sie folgende Aktionen ausführen:
- Entfernen Sie einen bestimmten Prozentsatz der Trainingsdaten zufällig.
- Analysieren Sie den Datensatz, und entfernen Sie überrepräsentierte doppelte Einträge, was ein systematischerer Ansatz ist.
Um den Trainingssatz hinzuzufügen, wählen Sie in Language Studio auf der Registerkarte Datenbezeichnung die Option Äußerungen vorschlagen aus. Conversational Language Understanding sendet einen Aufruf an Azure OpenAI, um ähnliche Äußerungen zu generieren.

Sie sollten auch nach unbeabsichtigten „Mustern“ im Trainingssatz suchen. Solche Muster können beispielsweise vorliegen, wenn der Trainingssatz für eine bestimmte Absicht nur Kleinbuchstaben enthält oder mit einem bestimmten Ausdruck beginnt. In solchen Fällen lernt das von Ihnen trainierte Modell möglicherweise diese unbeabsichtigten Verzerrungen im Trainingssatz und kann nicht verallgemeinern.
Es empfiehlt sich, im Trainingssatz Groß- und Kleinschreibung und verschiedene Satzzeichen zu verwenden. Wenn Ihr Modell Variationen verarbeiten soll, stellen Sie sicher, dass Sie über einen Trainingssatz verfügen, der diese Vielfalt auch widerspiegelt. Fügen Sie beispielsweise einige Äußerungen in richtiger Groß- und Kleinschreibung und einige nur in Kleinbuchstaben ein.
Datenteilung
Bevor Sie den Trainingsprozess starten, werden beschriftete Äußerungen in Ihrem Projekt in einen Trainings- und in einen Testsatz unterteilt. Beide haben unterschiedliche Funktion. Der Trainingssatz wird beim Trainieren des Modells verwendet. Anhand dieses Satzes lernt das Modell die beschrifteten Äußerungen. Der Testsatz ist ein blinder Satz, der dem Modell nicht während des Trainings, sondern erst während der Auswertung präsentiert wird.
Nachdem das Modell erfolgreich trainiert wurde, kann es verwendet werden, um Vorhersagen auf der Grundlage der Äußerungen im Testsatz zu generieren. Diese Vorhersagen werden zum Berechnen der Auswertungsmetriken verwendet. Achten Sie möglichst darauf, dass alle Ihre Absichten und Entitäten sowohl im Trainings- als auch im Testsatz angemessen dargestellt sind.
Conversational Language Understanding unterstützt zwei Methoden zum Teilen von Daten:
- Automatisches Aufteilen des Testsatzes aus den Trainingsdaten: Das System teilt Ihre markierten Daten gemäß den von Ihnen ausgewählten Prozentsätzen zwischen dem Trainings- und dem Testsatz auf. Empfohlen wird eine prozentuale Aufteilung von 80 Prozent für das Training und 20 Prozent für die Tests.
Hinweis
Wenn Sie die Option Automatisches Abspalten des Testdatensatzes aus den Trainingsdaten auswählen, werden nur die dem Trainingsdatensatz zugewiesenen Daten gemäß den angegebenen Prozentsätzen aufgeteilt.
- Verwenden einer manuellen Aufteilung von Trainings- und Testdaten: Mit dieser Methode können Benutzer definieren, welche Äußerungen zu welchem Satz gehören sollen. Dieser Schritt ist nur aktiviert, wenn Sie Ihrem Testsatz im Rahmen der Beschriftung Äußerungen hinzugefügt haben.
Trainingsmodi
CLU unterstützt zwei Modi für das Training Ihrer Modelle
Standardtraining verwendet schnelle Machine Learning-Algorithmen, um Ihre Modelle relativ schnell zu trainieren. Dies ist derzeit nur für Englisch verfügbar und ist für jedes Projekt deaktiviert, das Englisch (USA) oder Englisch (UK) nicht als primäre Sprache verwendet. Diese Trainingsoption ist kostenlos. Standardtraining ermöglicht es Ihnen, Äußerungen hinzuzufügen und sie schnell kostenlos zu testen. Die gezeigten Scores der Auswertung sollten Ihnen aufzeigen, wo Sie Änderungen in Ihrem Projekt vornehmen und weitere Äußerungen hinzufügen können. Sobald Sie nach ein paar Iterationen inkrementelle Verbesserungen vorgenommen haben, können Sie das erweiterte Training verwenden, um eine andere Version Ihres Modells zu trainieren.
Erweitertes Training verwendet die neueste Technologie für maschinelles Lernen, um Modelle mit Ihren Daten anzupassen. Es wird davon ausgegangen, dass damit bessere Scores für die Leistung Ihrer Modelle angezeigt werden, und Sie können die mehrsprachigen Funktionen von CLU nutzen. Für das erweiterte Training gelten unterschiedliche Preise. Einzelheiten finden Sie in den Preisinformationen.
Richten Sie sich bei Ihren Entscheidungen nach den Scores der Auswertung. Es kann vorkommen, dass ein bestimmtes Beispiel im Gegensatz zum Einsatz im Standardtraining im erweiterten Training falsch vorhergesagt wird. Wenn die Ergebnisse der Auswertung jedoch im erweiterten Training insgesamt besser ausfallen, sollten Sie Ihr endgültiges Modell verwenden. Wenn das nicht der Fall ist und Sie keine mehrsprachigen Funktionen verwenden möchten, können Sie das Modell weiterhin im Standardmodus trainieren.
Hinweis
Sie sollten damit rechnen, dass die Trainingsmodi sich bei den Zuverlässigkeitsbewertungen für Absichten unterschiedlich verhalten, da jeder Algorithmus seine Bewertungen anders kalibriert.
Trainieren des Modells
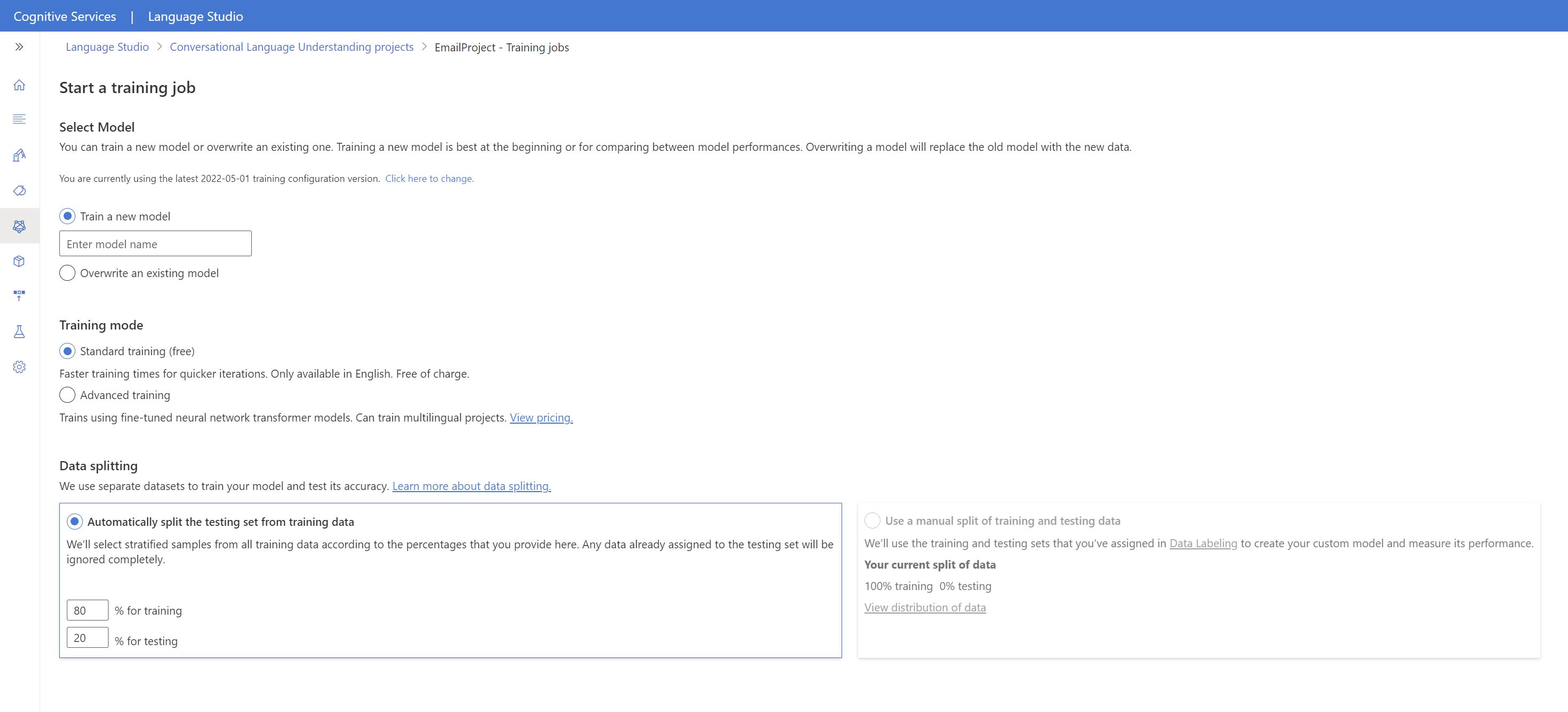
So beginnen Sie das Training Ihres Modells über Language Studio:
Wählen Sie im Menü auf der linken Seite Modell testen aus.
Wählen Sie im oberen Menü Trainingsauftrag starten aus.
Wählen Sie Neues Modell trainieren aus, und geben Sie im Textfeld einen neuen Modellnamen ein. Um andernfalls ein vorhandenes Modell durch ein Modell zu ersetzen, das mit den neuen Daten trainiert wurde, wählen Sie Ein vorhandenes Modell überschreiben und dann ein vorhandenes Modell aus. Das Überschreiben eines trainierten Modells kann nicht rückgängig gemacht werden, wirkt sich jedoch erst auf Ihre bereitgestellten Modelle aus, wenn Sie das neue Modell bereitstellen.
Wählen Sie den Trainingsmodus aus. Sie können Standardtraining für schnelleres Training auswählen, dies ist aber nur für Englisch verfügbar. Alternativ können Sie Erweitertes Training auswählen, das für andere Sprachen und mehrsprachige Projekte unterstützt wird, dies bringt aber eine längere Trainingsdauer mit sich. Erfahren Sie mehr über Trainingsmodi.
Wählen Sie eine Methode zur Datenaufteilung aus. Sie können Automatically splitting the testing set from training data (Automatisches Abspalten des Testdatasets aus den Trainingsdaten) auswählen. Dabei teilt das System Ihre Äußerungen gemäß den angegebenen Prozentsätzen zwischen den Trainings- und Testdatasets auf. Alternativ können Sie Manuelle Aufteilung von Trainings- und Testdaten verwenden nutzen. Diese Option ist nur aktiviert, wenn Sie Ihrem Testdatensatz Äußerungen während des Bezeichnens von Äußerungen hinzugefügt haben.
Wählen Sie die Schaltfläche Train (Trainieren) aus.
Wählen Sie in der Liste die ID des Trainingsauftrags aus. Ein Bereich wird angezeigt, in dem Sie den Trainingsfortschritt, den Auftragsstatus und andere Details für diesen Auftrag überprüfen können.
Hinweis
- Nur erfolgreich abgeschlossene Trainingsaufträge generieren Modelle.
- Je nach Anzahl der Äußerungen kann das Training wenige Minuten oder mehrere Stunden dauern.
- Es kann jeweils nur ein Trainingsauftrag ausgeführt werden. Sie können keinen anderen Trainingsauftrag innerhalb desselben Projekts starten, bis der laufende Auftrag abgeschlossen ist.
- Das maschinelle Lernen, das zum Trainieren von Modellen verwendet wird, wird regelmäßig aktualisiert. Um mit einer früheren Konfigurationsversion zu trainieren, wählen Sie die Option Hier zum ändern auswählen auf der Seite Trainingsauftrag starten aus und wählen Sie eine frühere Version aus.

Abbrechen eines Trainingsauftrags
So brechen Sie einen Trainingsauftrag in Language Studio ab
- Wählen Sie auf der Seite Modell trainieren den Trainingsauftrag aus, den Sie abbrechen möchten, und wählen Sie im oberen Menü Abbrechen aus.