Verwenden des Microsoft Cognitive Toolkit-Modells für intensives Lernen mit einem Azure HDInsight Spark-Cluster
In diesem Artikel führen Sie die folgenden Schritte aus.
Führen Sie ein benutzerdefiniertes Skript aus, um Microsoft Cognitive Toolkit in einem Azure HDInsight Spark-Cluster zu installieren.
Laden Sie ein Jupyter Notebook in den Apache Spark-Cluster hoch, um zu erfahren, wie ein trainiertes Deep Learning-Modell von Microsoft Cognitive Toolkit mit der Spark Python-API (PySpark) auf Dateien in einem Azure Blob Storage-Konto angewendet wird.
Voraussetzungen
Ein Apache Spark-Cluster unter HDInsight. Weitere Informationen finden Sie unter Erstellen eines Apache Spark-Clusters.
Kenntnisse im Umgang mit Jupyter Notebooks mit Spark in HDInsight. Weitere Informationen finden Sie unter Tutorial: Laden von Daten und Ausführen von Abfragen auf einem Apache Spark-Cluster in Azure HDInsight.
Wir läuft diese Lösung ab?
Diese Lösung ist auf diesen Artikel und ein Jupyter Notebook aufgeteilt, das Sie als Teil dieses Artikels hochladen können. In diesem Artikel führen Sie die folgenden Schritte aus:
- Ausführen einer Skriptaktion in einem HDInsight Spark-Cluster zum Installieren von Microsoft Cognitive Toolkit und Python-Paketen.
- Hochladen des Jupyter Notebooks, das die Lösung im HDInsight Spark-Cluster ausführt.
Die folgenden übrigen Schritte werden vom Jupyter Notebook abgedeckt.
- Laden von Beispielimages in ein Spark Resilient Distributed Dataset oder RDD
- Laden von Modulen und Definieren von Voreinstellungen
- Lokales Herunterladen des Datasets in den Spark-Cluster
- Konvertieren des Datasets in ein RDD
- Bewerten der Images mithilfe eines trainierten Cognitive Toolkit-Modells
- Herunterladen des trainierten Cognitive Toolkit-Modells in den Spark-Cluster
- Definieren von Funktionen, die von Workerknoten verwendet werden sollen
- Bewerten der Images auf Workerknoten
- Auswerten der Modellgenauigkeit
Installieren von Microsoft Cognitive Toolkit
Sie können Microsoft Cognitive Toolkit mithilfe einer Skriptaktion in einem Spark-Cluster installieren. Von Skriptaktionen werden benutzerdefinierte Skripts zum Installieren von Komponenten im Cluster verwendet, die nicht standardmäßig verfügbar sind. Sie können das benutzerdefinierte Skript aus dem Azure-Portal verwenden. Verwenden Sie dazu das HDInsight .NET SDK oder Azure PowerShell. Sie können das Skript auch verwenden, um das Toolkit entweder als Teil der Clustererstellung zu installieren, oder sobald der Cluster ausgeführt wird.
In diesem Artikel verwenden wir das Portal, um das Toolkit installieren, nachdem der Cluster erstellt wurde. Andere Möglichkeiten zum Ausführen des benutzerdefinierten Skripts finden Sie unter Anpassen Linux-basierter HDInsight-Cluster mithilfe von Skriptaktionen.
Verwenden des Azure-Portals
Eine Anleitung zur Verwendung des Azure-Portals zum Ausführen der Skriptaktion finden Sie unter Anpassen von HDInsight-Clustern mithilfe von Skriptaktion. Stellen Sie sicher, dass Sie die folgenden Eingaben zum Installieren von Microsoft Cognitive Toolkit bereitstellen. Verwenden Sie die folgenden Werte für die Skriptaktion:
| Eigenschaft | Wert |
|---|---|
| Skripttyp | --Benutzerdefiniert |
| Name | Installieren von MCT |
| Bash-Skript-URI | https://raw.githubusercontent.com/Azure-Samples/hdinsight-pyspark-cntk-integration/master/cntk-install.sh |
| Knotentyp(en): | Hauptknoten, Workerknoten |
| Parameter | Keine |
Hochladen des Jupyter Notebooks in den Azure HDInsight Spark-Cluster
Um das Microsoft Cognitive Toolkit mit dem Azure HDInsight Spark-Cluster zu verwenden, müssen Sie das Jupyter Notebook CNTK_model_scoring_on_Spark_walkthrough.ipynb in den Azure HDInsight Spark-Cluster hochladen. Dieses Notebook ist unter https://github.com/Azure-Samples/hdinsight-pyspark-cntk-integration auf GitHub verfügbar.
Laden Sie https://github.com/Azure-Samples/hdinsight-pyspark-cntk-integration herunter, und entzippen Sie es.
Navigieren Sie in einem Webbrowser zu
https://CLUSTERNAME.azurehdinsight.net/jupyter, wobeiCLUSTERNAMEder Name Ihres Clusters ist.Wählen Sie oben rechts im Jupyter Notebook die Option Upload (Hochladen) aus, navigieren Sie dann zum Download, und wählen Sie die Datei
CNTK_model_scoring_on_Spark_walkthrough.ipynbaus.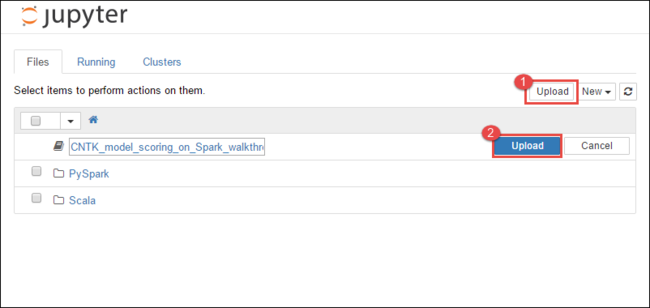
Wählen Sie erneut Upload (Hochladen) aus.
Sobald das Notebook hochgeladen ist, klicken Sie auf den Namen des Notebooks, folgen Sie den Anweisungen im Notebook zum Laden des Datasets, und gehen Sie dem Artikel gemäß vor.
Weitere Informationen
Szenarien
- Apache Spark mit BI: Durchführen interaktiver Datenanalysen mithilfe von Spark in HDInsight mit BI-Tools
- Apache Spark mit Machine Learning: Analysieren von Gebäudetemperaturen mithilfe von Spark in HDInsight und HVAC-Daten
- Apache Spark mit Machine Learning: Vorhersage von Lebensmittelkontrollergebnissen mithilfe von Spark in HDInsight
- Websiteprotokollanalyse mithilfe von Apache Spark in HDInsight
- Analysieren von Application Insights-Telemetriedaten mit Apache Spark in HDInsight
Erstellen und Ausführen von Anwendungen
- Erstellen einer eigenständigen Anwendung mit Scala
- Ausführen von Remoteaufträgen in einem Apache Spark-Cluster mithilfe von Apache Livy
Tools und Erweiterungen
- Verwenden des HDInsight-Tools-Plug-Ins für IntelliJ IDEA zum Erstellen und Übermitteln von Spark Scala-Anwendungen
- Verwenden des HDInsight-Tools-Plug-Ins für IntelliJ IDEA zum Remotedebuggen von Apache Spark-Anwendungen
- Verwenden von Apache Zeppelin Notebooks mit einem Apache Spark-Cluster unter HDInsight
- Kernel für Jupyter Notebook in Apache Spark-Clustern für HDInsight
- Verwenden von externen Paketen mit Jupyter Notebooks
- Installieren von Jupyter Notebook auf Ihrem Computer und Herstellen einer Verbindung zum Apache Spark-Cluster in Azure HDInsight (Vorschau)