Analysieren von Websiteprotokollen mithilfe einer benutzerdefinierten Python-Bibliothek mit Apache Spark-Cluster unter HDInsight
Dieses Notebook veranschaulicht das Analysieren von Protokolldaten unter Verwendung einer benutzerdefinierten Bibliothek mit Apache Spark unter HDInsight. Als benutzerdefinierte Bibliothek verwenden wir eine Python-Bibliothek namens iislogparser.py.
Voraussetzungen
Ein Apache Spark-Cluster unter HDInsight. Eine Anleitung finden Sie unter Erstellen von Apache Spark-Clustern in Azure HDInsight.
Speichern von Rohdaten als RDD
In diesem Abschnitt verwenden Sie das Jupyter-Notebook, das einem Apache Spark-Cluster in HDInsight zugeordnet ist, zum Ausführen von Aufträgen, bei denen Ihre Beispielrohdaten verarbeitet und dann als Hive-Tabelle gespeichert werden. Die Beispieldaten sind in einer CSV-Datei (hvac.csv) enthalten, die standardmäßig auf allen Clustern verfügbar ist.
Nachdem Ihre Daten als Apache Hive-Tabelle gespeichert wurden, können wir im nächsten Abschnitt eine Verbindung mit der Hive-Tabelle herstellen. Hierzu verwenden wir BI-Tools wie Power BI und Tableau.
Navigieren Sie in einem Webbrowser zu
https://CLUSTERNAME.azurehdinsight.net/jupyter, wobeiCLUSTERNAMEder Name Ihres Clusters ist.Erstellen Sie ein neues Notebook. Wählen Sie Neu und dann PySpark aus.
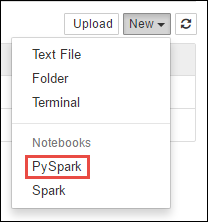 Notebook" border="true":::
Notebook" border="true":::Ein neues Notebook mit dem Namen „Untitled.pynb“ wird erstellt und geöffnet. Wählen Sie oben den Namen des Notebooks aus, und geben Sie einen Anzeigenamen ein.
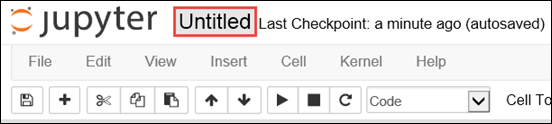
Da Sie ein Notebook mit dem PySpark-Kernel erstellt haben, müssen Sie keine Kontexte explizit erstellen. Die Spark- und Hive-Kontexte werden automatisch für Sie erstellt, wenn Sie die erste Codezelle ausführen. Sie können zunächst die Typen importieren, die für dieses Szenario erforderlich sind. Fügen Sie den folgenden Codeausschnitt in eine leere Zelle ein, und drücken Sie UMSCHALT+EINGABETASTE.
from pyspark.sql import Row from pyspark.sql.types import *Erstellen Sie unter Verwendung der bereits im Cluster verfügbaren Beispielprotokolldaten ein RDD. Sie können auf die Daten im Standardspeicherkonto, das dem Cluster zugeordnet ist, unter
\HdiSamples\HdiSamples\WebsiteLogSampleData\SampleLog\909f2b.logzugreifen. Führen Sie den folgenden Code aus:logs = sc.textFile('wasbs:///HdiSamples/HdiSamples/WebsiteLogSampleData/SampleLog/909f2b.log')Rufen Sie einen Beispielprotokollsatz ab, um sich zu vergewissern, dass der vorherige Schritt erfolgreich ausgeführt wurde.
logs.take(5)Es sollte eine Ausgabe angezeigt werden, die dem folgenden Text ähnelt:
[u'#Software: Microsoft Internet Information Services 8.0', u'#Fields: date time s-sitename cs-method cs-uri-stem cs-uri-query s-port cs-username c-ip cs(User-Agent) cs(Cookie) cs(Referer) cs-host sc-status sc-substatus sc-win32-status sc-bytes cs-bytes time-taken', u'2014-01-01 02:01:09 SAMPLEWEBSITE GET /blogposts/mvc4/step2.png X-ARR-LOG-ID=2ec4b8ad-3cf0-4442-93ab-837317ece6a1 80 - 1.54.23.196 Mozilla/5.0+(Windows+NT+6.3;+WOW64)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Chrome/31.0.1650.63+Safari/537.36 - http://weblogs.asp.net/sample/archive/2007/12/09/asp-net-mvc-framework-part-4-handling-form-edit-and-post-scenarios.aspx www.sample.com 200 0 0 53175 871 46', u'2014-01-01 02:01:09 SAMPLEWEBSITE GET /blogposts/mvc4/step3.png X-ARR-LOG-ID=9eace870-2f49-4efd-b204-0d170da46b4a 80 - 1.54.23.196 Mozilla/5.0+(Windows+NT+6.3;+WOW64)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Chrome/31.0.1650.63+Safari/537.36 - http://weblogs.asp.net/sample/archive/2007/12/09/asp-net-mvc-framework-part-4-handling-form-edit-and-post-scenarios.aspx www.sample.com 200 0 0 51237 871 32', u'2014-01-01 02:01:09 SAMPLEWEBSITE GET /blogposts/mvc4/step4.png X-ARR-LOG-ID=4bea5b3d-8ac9-46c9-9b8c-ec3e9500cbea 80 - 1.54.23.196 Mozilla/5.0+(Windows+NT+6.3;+WOW64)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Chrome/31.0.1650.63+Safari/537.36 - http://weblogs.asp.net/sample/archive/2007/12/09/asp-net-mvc-framework-part-4-handling-form-edit-and-post-scenarios.aspx www.sample.com 200 0 0 72177 871 47']
Analysieren von Protokolldaten mithilfe einer benutzerdefinierten Python-Bibliothek
Die ersten Zeilen der oben gezeigten Ausgabe enthalten die Headerinformationen. Die restlichen Zeilen entsprechen jeweils dem im Header beschriebenen Schema. Die Analyse solcher Protokolle ist nicht immer ganz einfach. Daher verwenden wir eine benutzerdefinierte Python-Bibliothek (iislogparser.py), um Protokolle dieser Art leichter analysieren zu können. Standardmäßig ist diese Bibliothek in Ihrem Spark-Cluster auf HDInsight unter
/HdiSamples/HdiSamples/WebsiteLogSampleData/iislogparser.pyenthalten.Da sie jedoch nicht in
PYTHONPATHenthalten ist, können wir sie nicht mithilfe einer Importanweisung wieimport iislogparserverwenden. Zur Verwendung dieser Bibliothek müssen wir sie an alle Workerknoten verteilen. Führen Sie den folgenden Codeausschnitt aus:sc.addPyFile('wasbs:///HdiSamples/HdiSamples/WebsiteLogSampleData/iislogparser.py')iislogparserstellt die Funktionparse_log_linebereit, dieNonezurückgibt, wenn es sich bei einer Protokollzeile um eine Kopfzeile handelt. Handelt es sich dagegen um eine Protokollzeile, gibt die Funktion eine Instanz der KlasseLogLinezurück. Verwenden Sie die KlasseLogLine, um nur die Protokollzeilen aus dem RDD zu extrahieren:def parse_line(l): import iislogparser return iislogparser.parse_log_line(l) logLines = logs.map(parse_line).filter(lambda p: p is not None).cache()Rufen Sie einige extrahierte Protokollzeilen ab, um sich zu vergewissern, dass der Schritt erfolgreich ausgeführt wurde.
logLines.take(2)Die Ausgabe sollte in etwa wie der folgende Text aussehen:
[2014-01-01 02:01:09 SAMPLEWEBSITE GET /blogposts/mvc4/step2.png X-ARR-LOG-ID=2ec4b8ad-3cf0-4442-93ab-837317ece6a1 80 - 1.54.23.196 Mozilla/5.0+(Windows+NT+6.3;+WOW64)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Chrome/31.0.1650.63+Safari/537.36 - http://weblogs.asp.net/sample/archive/2007/12/09/asp-net-mvc-framework-part-4-handling-form-edit-and-post-scenarios.aspx www.sample.com 200 0 0 53175 871 46, 2014-01-01 02:01:09 SAMPLEWEBSITE GET /blogposts/mvc4/step3.png X-ARR-LOG-ID=9eace870-2f49-4efd-b204-0d170da46b4a 80 - 1.54.23.196 Mozilla/5.0+(Windows+NT+6.3;+WOW64)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Chrome/31.0.1650.63+Safari/537.36 - http://weblogs.asp.net/sample/archive/2007/12/09/asp-net-mvc-framework-part-4-handling-form-edit-and-post-scenarios.aspx www.sample.com 200 0 0 51237 871 32]Die Klasse
LogLinebietet ihrerseits einige hilfreiche Methoden. Hierzu zählt beispielsweiseis_error(), um zu ermitteln, ob ein Protokolleintrag einen Fehlercode besitzt. Verwenden Sie diese Klasse, um die Anzahl von Fehlern in den extrahierten Protokollzeilen zu berechnen und anschließend alle Fehler in einer anderen Datei zu protokollieren.errors = logLines.filter(lambda p: p.is_error()) numLines = logLines.count() numErrors = errors.count() print 'There are', numErrors, 'errors and', numLines, 'log entries' errors.map(lambda p: str(p)).saveAsTextFile('wasbs:///HdiSamples/HdiSamples/WebsiteLogSampleData/SampleLog/909f2b-2.log')Die Ausgabe sollte
There are 30 errors and 646 log entriesbesagen.Sie können auch Matplotlib verwenden, um eine Visualisierung der Daten zu erstellen. Wenn Sie also beispielsweise die Ursache von Anforderungen mit hoher Ausführungsdauer isolieren möchten, empfiehlt es sich unter Umständen, die Dateien zu ermitteln, deren Bereitstellung im Schnitt am längsten dauert. Der folgende Codeausschnitt ruft die 25 Ressourcen mit der höchsten Anforderungsabwicklungsdauer ab.
def avgTimeTakenByKey(rdd): return rdd.combineByKey(lambda line: (line.time_taken, 1), lambda x, line: (x[0] + line.time_taken, x[1] + 1), lambda x, y: (x[0] + y[0], x[1] + y[1]))\ .map(lambda x: (x[0], float(x[1][0]) / float(x[1][1]))) avgTimeTakenByKey(logLines.map(lambda p: (p.cs_uri_stem, p))).top(25, lambda x: x[1])Die Ausgabe sollte wie der folgende Text aussehen:
[(u'/blogposts/mvc4/step13.png', 197.5), (u'/blogposts/mvc2/step10.jpg', 179.5), (u'/blogposts/extractusercontrol/step5.png', 170.0), (u'/blogposts/mvc4/step8.png', 159.0), (u'/blogposts/mvcrouting/step22.jpg', 155.0), (u'/blogposts/mvcrouting/step3.jpg', 152.0), (u'/blogposts/linqsproc1/step16.jpg', 138.75), (u'/blogposts/linqsproc1/step26.jpg', 137.33333333333334), (u'/blogposts/vs2008javascript/step10.jpg', 127.0), (u'/blogposts/nested/step2.jpg', 126.0), (u'/blogposts/adminpack/step1.png', 124.0), (u'/BlogPosts/datalistpaging/step2.png', 118.0), (u'/blogposts/mvc4/step35.png', 117.0), (u'/blogposts/mvcrouting/step2.jpg', 116.5), (u'/blogposts/aboutme/basketball.jpg', 109.0), (u'/blogposts/anonymoustypes/step11.jpg', 109.0), (u'/blogposts/mvc4/step12.png', 106.0), (u'/blogposts/linq8/step0.jpg', 105.5), (u'/blogposts/mvc2/step18.jpg', 104.0), (u'/blogposts/mvc2/step11.jpg', 104.0), (u'/blogposts/mvcrouting/step1.jpg', 104.0), (u'/blogposts/extractusercontrol/step1.png', 103.0), (u'/blogposts/sqlvideos/sqlvideos.jpg', 102.0), (u'/blogposts/mvcrouting/step21.jpg', 101.0), (u'/blogposts/mvc4/step1.png', 98.0)]Die Informationen können auch als Grafik dargestellt werden. Als ersten Schritt beim Erstellen einer Grafik erstellen wir zunächst eine temporäre Tabelle AverageTime. Die Tabelle gruppiert die Protokolle nach Zeit, um zu ermitteln, ob ungewöhnliche Latenzspitzen vorlagen.
avgTimeTakenByMinute = avgTimeTakenByKey(logLines.map(lambda p: (p.datetime.minute, p))).sortByKey() schema = StructType([StructField('Minutes', IntegerType(), True), StructField('Time', FloatType(), True)]) avgTimeTakenByMinuteDF = sqlContext.createDataFrame(avgTimeTakenByMinute, schema) avgTimeTakenByMinuteDF.registerTempTable('AverageTime')Sie können dann die folgende SQL-Abfrage ausführen, um alle Datensätze in der Tabelle AverageTime abzurufen.
%%sql -o averagetime SELECT * FROM AverageTimeDurch den Befehl
%%sqlgefolgt von-o averagetimewird sichergestellt, dass die Ausgabe der Abfrage lokal auf dem Jupyter-Server (in der Regel der Hauptknoten des Clusters) beibehalten wird. Die Ausgabe wird als Pandas -Dataframe mit dem angegebenen Namen averagetimebeibehalten.Die Ausgabe sollte wie das folgende Bild aussehen:
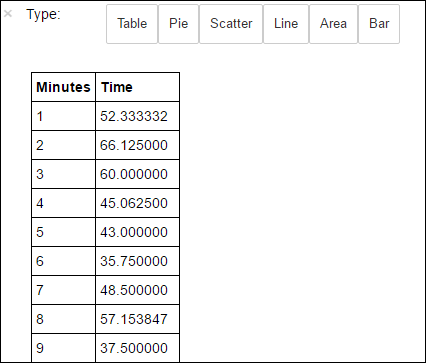 yter sql query output" border="true":::
yter sql query output" border="true":::Weitere Informationen zur
%%sql-Magic finden Sie unter Mit %%sql-Magic unterstützte Parameter.Sie können nun Matplotlib verwenden, eine Bibliothek zur Visualisierung von Daten, um eine Grafik zu erstellen. Da die Grafik aus dem lokal gespeicherten averagetime-Dataframe erstellt werden muss, muss der Codeausschnitt mit der
%%local-Magic beginnen. Dadurch wird sichergestellt, dass der Code lokal auf dem Jupyter-Server ausgeführt wird.%%local %matplotlib inline import matplotlib.pyplot as plt plt.plot(averagetime['Minutes'], averagetime['Time'], marker='o', linestyle='--') plt.xlabel('Time (min)') plt.ylabel('Average time taken for request (ms)')Die Ausgabe sollte wie das folgende Bild aussehen:
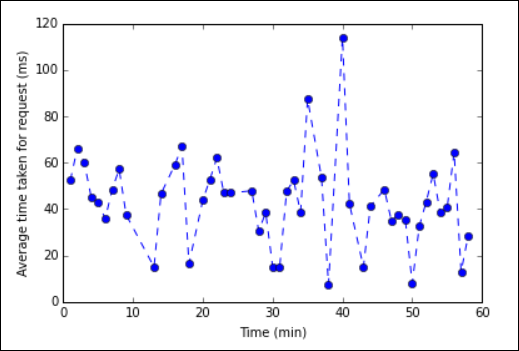 eb log analysis plot" border="true":::
eb log analysis plot" border="true":::Nach dem Ausführen der Anwendung empfiehlt es sich, das Notebook herunterzufahren, um die Ressourcen freizugeben. Wählen Sie hierzu im Menü Datei des Notebooks die Option Schließen und Anhalten aus. Durch diese Aktion wird das Notebook heruntergefahren und geschlossen.
Nächste Schritte
Machen Sie sich mit den folgenden Artikeln vertraut: