Debuggen von Apache Spark-Aufträgen, die in HDInsight ausgeführt werden
In diesem Artikel erfahren Sie, wie Sie Apache Spark-Aufträge, die auf HDInsight-Clustern ausgeführt werden, nachverfolgen und debuggen können. Führen Sie das Debuggen mit der Apache Hadoop YARN-Benutzeroberfläche, der Spark-Benutzeroberfläche und dem Spark-Verlaufsserver durch. Sie starten einen Spark-Auftrag über das im Spark-Cluster verfügbare Notebook Machine Learning: Predictive analysis on food inspection data using MLLib (Maschinelles Lernen: Vorhersageanalyse von Lebensmittelkontrolldaten mithilfe von MLLib). Verfolgen Sie mithilfe der folgenden Schritte eine Anwendung nach, die Sie mit einer anderen Methode wie spark-submit übermittelt haben.
Wenn Sie kein Azure-Abonnement besitzen, können Sie ein kostenloses Konto erstellen, bevor Sie beginnen.
Voraussetzungen
Ein Apache Spark-Cluster unter HDInsight. Eine Anleitung finden Sie unter Erstellen von Apache Spark-Clustern in Azure HDInsight.
Sie sollten mit der Ausführung des Notebooks Machine Learning: Predictive analysis on food inspection data using MLLib (Maschinelles Lernen: Vorhersageanalyse von Lebensmittelkontrolldaten mithilfe von MLLib) begonnen haben. Für eine Anleitung zum Ausführen dieses Notebooks folgen Sie dem Link.
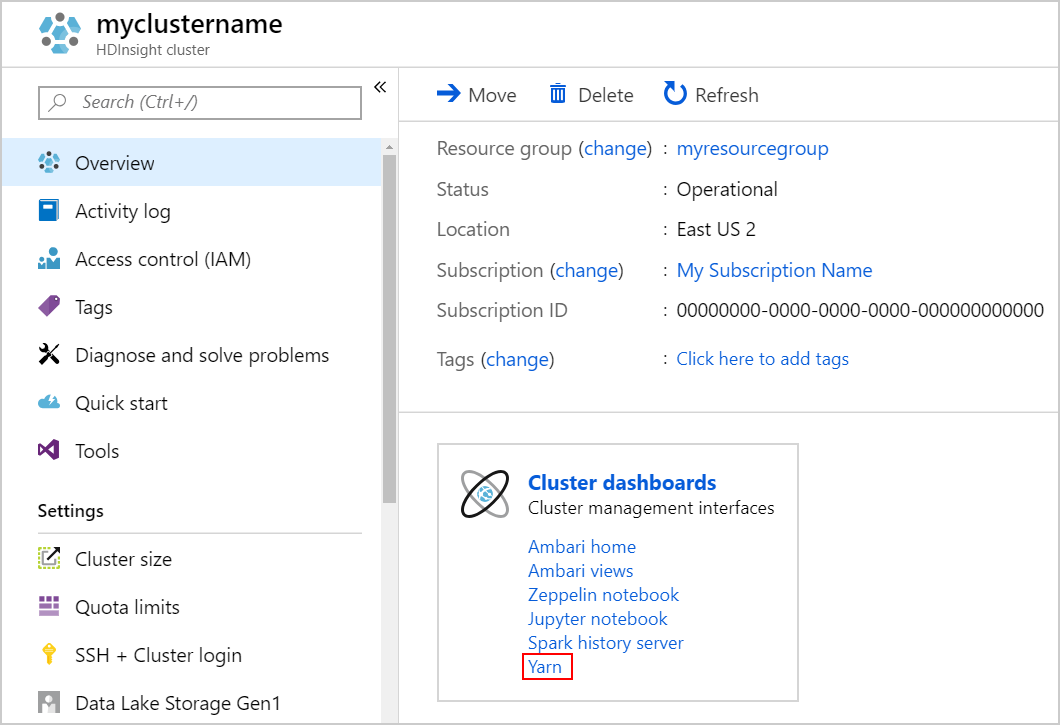
Nachverfolgen einer Anwendung auf der YARN-Benutzeroberfläche
Starten Sie die YARN-Benutzeroberfläche. Klicken Sie unter Clusterdashboards auf Yarn.
Tipp
Alternativ können Sie die YARN-Benutzeroberfläche auch über die Ambari-Benutzeroberfläche starten. Klicken Sie zum Starten der Ambari-Benutzeroberfläche unter Clusterdashboards auf Ambari home (Ambari-Homepage). Navigieren Sie von der Ambari-Benutzeroberfläche zu Yarn>Quicklinks>, wählen Sie den aktiven Ressourcen-Manager aus, und klicken Sie auf >Resource Manager UI (Benutzeroberfläche des Ressourcen-Managers).
Da Sie den Spark-Auftrag mit Jupyter Notebook-Instanzen gestartet haben, hat die Anwendung den Namen remotesparkmagics (dies ist der Name für alle Anwendungen, die über die Notebook-Instanzen gestartet werden). Klicken Sie auf die Anwendungs-ID für den Anwendungsnamen, um weitere Informationen zum Auftrag abzurufen. Diese Aktion öffnet die Anwendungsansicht.
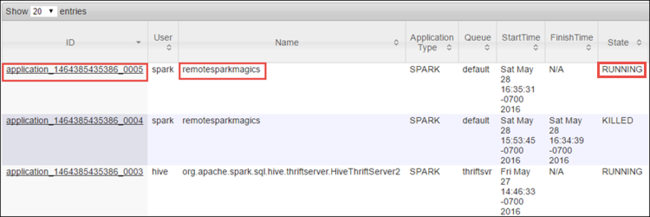
Für Anwendungen, die über die Jupyter Notebook-Instanzen gestartet werden, ist der Status immer WIRD AUSGEFÜHRT, bis Sie die Notebook-Instanz beenden.
In der Anwendungsansicht können Sie weitere Details anzeigen, um die der Anwendung zugeordneten Container und die Protokolle (stdout/stderr) zu finden. Sie können die Spark-Benutzeroberfläche auch starten, indem Sie auf die Verknüpfung für die Nachverfolgungs-URLklicken, wie unten dargestellt.
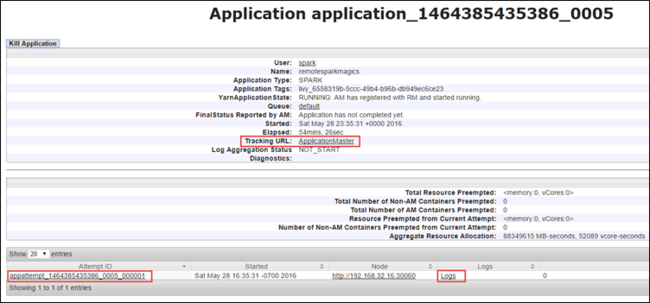
Nachverfolgen einer Anwendung auf der Spark-Benutzeroberfläche
Auf der Spark-Benutzeroberfläche können Sie Details der Spark-Aufträge anzeigen, die von der Anwendung erzeugt werden, die Sie zuvor gestartet haben.
Klicken Sie wie auf dem Screenshot oben dargestellt in der Anwendungsansicht auf den Link für die Nachverfolgungs-URL, um die Spark-Benutzeroberfläche zu starten Es werden alle Spark-Aufträge angezeigt, die von der Anwendung, die in der Jupyter Notebook-Instanz ausgeführt wird, gestartet werden.
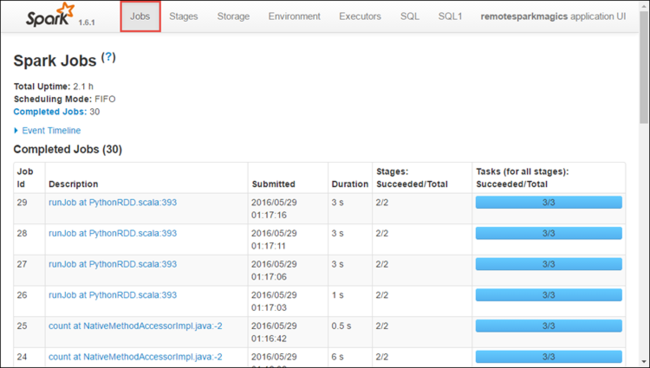
Klicken Sie auf die Registerkarte Executors (Executor), um Informationen zur Verarbeitung und Speicherung für jeden Executor anzuzeigen. Sie können auch die Aufrufliste abrufen, indem Sie auf den Link Thread Dump (Sicherungskopie des Threads) klicken.
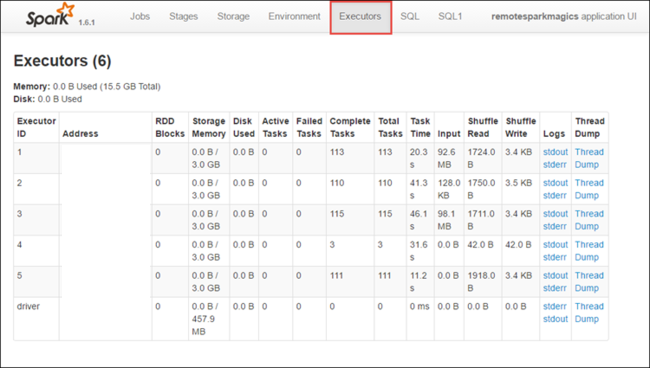
Klicken Sie auf die Registerkarte Stages (Phasen), um die der Anwendung zugeordneten Phasen anzuzeigen.
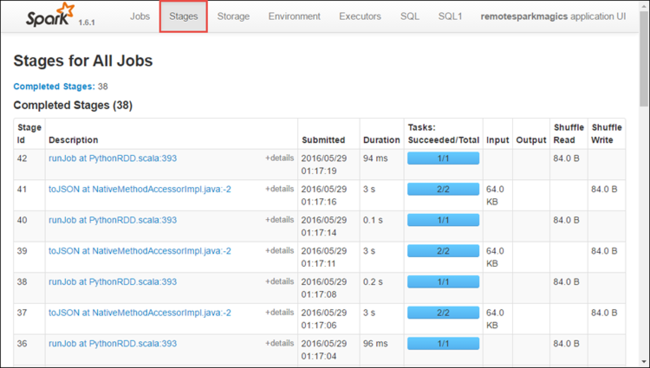
Jede Phase kann mehrere Aufgaben aufweisen, für die Sie Ausführungsstatistiken anzeigen können, wie unten dargestellt.
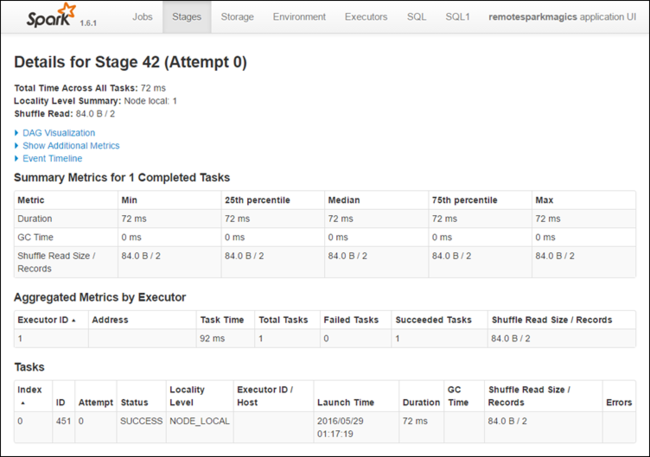
Auf der Seiten mit Phasendetails können Sie die DAG-Visualisierung starten. Erweitern Sie den Link DAG Visualization oben auf der Seite, wie unten dargestellt.
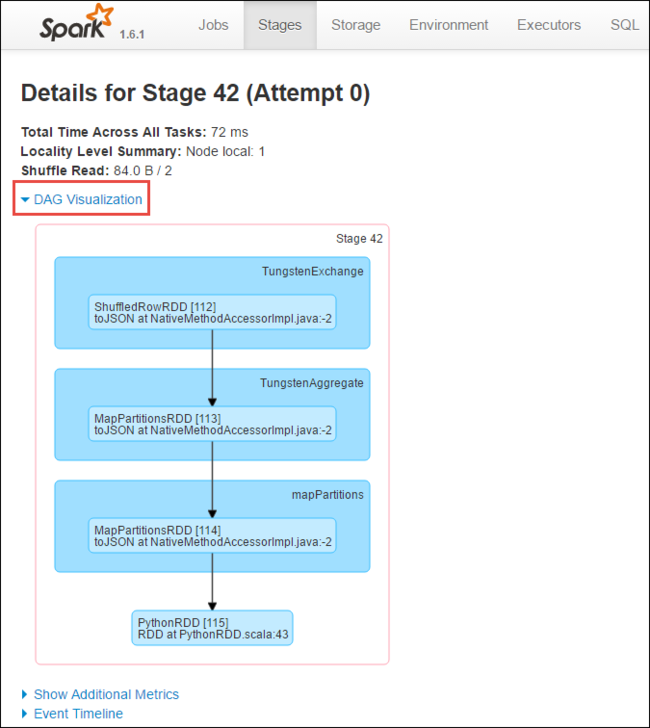
Mit DAG (Direct Aclyic Graph, gerichteter azyklischer Graph) werden die verschiedenen Phasen in der Anwendung dargestellt. Jedes blaue Feld im Diagramm stellt einen Spark-Vorgang dar, der von der Anwendung aufgerufen wurde.
Auf der Seite mit den Phasendetails können Sie auch die Zeitachsenansicht für die Anwendung starten. Erweitern Sie den Link Event Timeline oben auf der Seite, wie unten dargestellt.
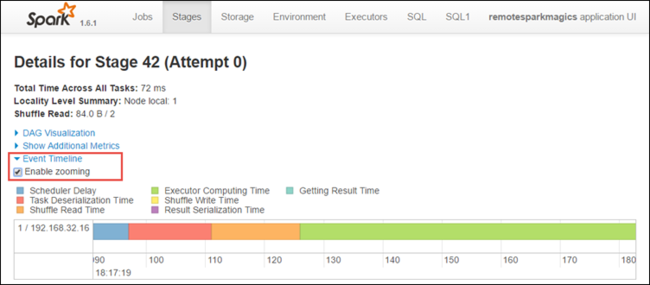
Diese Abbildung zeigt die Spark-Ereignisse in Form einer Zeitachse an. Die Zeitachsenansicht ist auf drei Ebenen verfügbar: für Aufträge, innerhalb eines Auftrags und innerhalb einer Phase. In der Abbildung oben ist die Zeitachsenansicht für eine bestimmte Phase dargestellt.
Tipp
Wenn Sie das Kontrollkästchen Enable zooming aktivieren, können Sie in der Zeitachsenansicht einen Bildlauf nach links und rechts ausführen.
Andere Registerkarten der Spark-Benutzeroberfläche enthalten ebenfalls nützliche Informationen über die Spark-Instanz.
- Registerkarte „Storage“ (Speicher): Wenn Ihre Anwendung ein RDD-Objekt erstellt, finden Sie hierzu Informationen auf der Registerkarte „Storage“ (Speicher).
- Registerkarte „Umgebung“: Diese Registerkarte enthält viele nützliche Informationen zu Ihrer Spark-Instanz einschließlich der Folgenden:
- Scala-Version
- Ereignisprotokollverzeichnis, das dem Cluster zugeordnet ist
- Anzahl der Executorkerne für die Anwendung
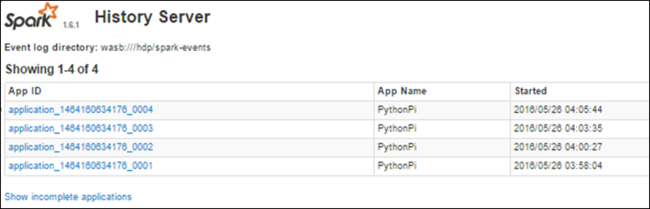
Anzeigen von Informationen zu abgeschlossenen Aufträgen mithilfe des Spark-Verlaufsservers
Wenn ein Auftrag abgeschlossen ist, werden die Informationen zum Auftrag auf dem Spark-Verlaufsserver beibehalten.
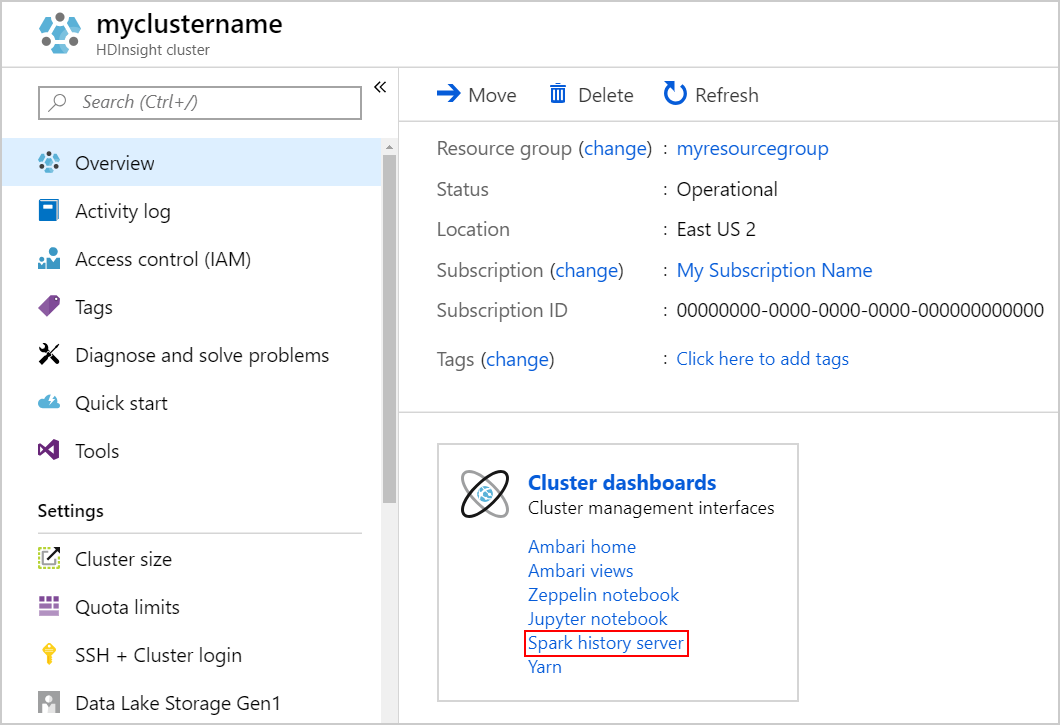
Klicken Sie zum Starten des Spark-Verlaufsservers auf der Seite Übersicht unter Clusterdashboard auf Spark-Verlaufsserver.
Tipp
Alternativ können Sie die Benutzeroberfläche des Spark-Verlaufsservers auch über die Ambari-Benutzeroberfläche starten. Klicken Sie zum Starten der Ambari-Benutzeroberfläche auf dem Blatt „Übersicht“ unter Clusterdashboards auf Ambari home (Ambari-Homepage). Navigieren Sie auf der Ambari-Benutzeroberfläche zu Spark2>Quicklinks>Spark2 History Server UI (Benutzeroberfläche des Spark2-Verlaufsservers).
Eine Liste der abgeschlossenen Anwendungen wird angezeigt. Klicken Sie auf eine Anwendungs-ID, um weitere Informationen zur Anwendung anzuzeigen.