Eksportér Dataverse-data i Delta Lake-format
Brug Azure Synapse Link til Dataverse til at eksportere dine Microsoft Dataverse data til Azure Synapse Analytics i Delta Lake-format. Undersøg derefter dine data, og få hurtigere tid til indsigt. Denne artikel indeholder følgende oplysninger og viser, hvordan du udfører følgende opgaver:
- Artiklen forklarer Delta Lake og Parquet, og hvorfor du skal eksportere data i dette format.
- Eksportér dine Dataverse data til dit Azure Synapse Analytics arbejdsområde i Delta Lake-format med linket Azure Synapse.
- Overvåg dit Azure Synapse link- og din datakonvertering.
- Få vist dine data fra Azure Data Lake Storage Gen2.
- Få vist dine data fra Synapse Workspace.
Vigtige oplysninger
- Hvis du opgraderer fra CSV til Delta Lake med eksisterende brugerdefinerede visninger, anbefaler vi, at du opdaterer scriptet, så det erstatter alle partitioned tabeller til non_partitioned. Det kan du gøre ved at søge efter forekomster af
_partitionedog erstatte dem med en tom streng. - For Dataverse-konfigurationen aktiveres Tilføj kun som standard for at eksportere CSV-data i
appendonly-tilstand. Men Delta Lake-tabellen vil have en opdateringsstruktur på plads, da Delta Lake-konverteringen ledsages af en periodisk fletningsproces. - Der påløber ingen omkostninger i forbindelse med oprettelse af Spark-grupper. Der påløber kun gebyrer, når et Spark-job udføres på Spark-målgruppen, og Spark-forekomsten iværksættes efter behov. Disse omkostninger er relateret til brugen af Azure Synapse workspace Spark, og de faktureres månedligt. Omkostningerne ved at bruge Spark-beregning afhænger primært af tidsintervallet for trinvis opdatering og datamængderne. Du finder flere oplysninger under: Azure Synapse Analytics-prisfastsættelse
- Det er vigtigt at tage højde for disse ekstra omkostninger, når du beslutter dig for at bruge denne funktion, da de ikke er valgfrie og skal betales for at fortsætte med at bruge funktionen.
- Levetidens slutning annonceret (EOLA) for Azure Synapse Runtime for Apache Spark 3.3 er blevet annonceret den 12. juli 2024. I overensstemmelse med Synapse-runtime for Apache Spark-livscykluspolitikken vil Azure Synapse-runtime for Apache Spark 3.3 blive udfaset og deaktiveret pr. 31. marts 2025. Efter EOL-datoen er de tilbagetrukne kørselstider ikke tilgængelige for nye Spark-puljer, og eksisterende arbejdsgange kan ikke udføres. Metadata forbliver midlertidigt i Synapse-arbejdsområdet. Du kan finde flere oplysninger i: Azure Synapse Runtime for Apache Spark 3.3 (EOSA). For at have dit Synapse Link til Dataverse med eksport til Delta Lake-formatopgradering til Spark 3.4, lav en opgradering på stedet for dine eksisterende profiler. Flere oplysninger: In-place opgradering til Apache Spark 3.4 med Delta Lake 2.4
- Fra og med den 25. december 2024 understøttes kun Spark-gruppe version 3.4, første gang sammenkædningen oprettes.
Bemærk
Linkstatus Azure Synapse i Power Apps (make.powerapps.com) afspejler Delta Lake-konverteringstilstanden:
-
Countviser antallet af poster i tabellen Delta Lake. - Dato og klokkeslæt for
Last synchronized onrepræsenterer tidsstemplet for den sidste vellykkede konvertering. -
Sync statusvises som aktiv, når datasynkroniseringen og Delta Lake-konverteringen er fuldført, hvilket angiver, at dataene er klar til forbrug.
Hvad er Delta Lake?
Delta Lake er et projekt med åben kildekode, som giver mulighed for at bygge en lakehouse-arkitektur oven på datasøer. Delta Lake leverer ACID (atomicity, consistency, isolation, durability)-transaktioner samt skalerbar metadatahåndtering og forener streaming og batchdatabehandling oven på eksisterende datasøer. Azure Synapse Analytics er kompatibel med Linux Foundation Delta Lake. Den aktuelle version af Delta Lake, der følger med Azure Synapse, har sprogsupport af Scala, PySpark og .NET. Flere oplysninger: Hvad er Delta Lake?. Du kan også få mere at vide i videoen Introduktion til Delta-tabeller.
Apache Parquet er det grundlæggende format for Delta Lake, som giver dig mulighed for at udnytte de effektive komprimerings- og kodningsskemaer, der er indbygget i formatet. Parquet-filformatet anvender komprimering pr. kolonne. Det er effektivt og sparer lagerplads. Forespørgsler, der henter bestemte kolonneværdier, behøver ikke at læse alle rækkedata, hvilket forbedrer ydeevnen. Serveruafhængige SQL-grupper behøver derfor mindre tid og færre forespørgsler om lagerplads for at læse dataene.
Hvorfor bruge Delta Lake?
- Skalerbarhed: Delta Lake er bygget på en Apache-licens med åben kildekode, som er udviklet til at imødekomme branchestandarder for håndtering af store arbejdsbelastninger i forbindelse med databehandling.
- Pålidelighed: Delta Lake leverer ACID-transaktioner, der sikrer, at dataene er ensartede og pålidelige, også i tilfælde af fejl eller samtidig adgang.
- Ydeevne: Delta Lake anvender kolonnelagerformatet for Parquet, hvilket giver bedre komprimerings- og kodningsteknikker, hvilket kan give forbedret forespørgselsydeevne i forhold til CSV-forespørgselsfiler.
- Omkostningseffektivt: Delta Lake-filformatet er en yderst komprimeret datalagringsteknologi, der giver store potentielle lagerbesparende muligheder for virksomheder. Dette format er designet specifikt til at optimere databehandlingen og potentielt reducere den samlede mængde behandlede data eller kørselstid, som kræves til databehandling efter behov.
- Overholdelse af databeskyttelse: Delta Lake med Azure Synapse Link indeholder værktøjer og funktioner, herunder blød sletning og hård sletning for at overholde forskellige databeskyttelsesregler, herunder generel forordning om databeskyttelse (GDPR).
Sådan fungerer Delta Lake sammen med Azure Synapse Link til Dataverse?
Når du konfigurerer et Azure Synapse Link til Dataverse, kan du aktivere funktionen til eksport til Delta Lake og oprette forbindelse til et Synapse-arbejdsområde og en Spark-pulje. Azure Synapse Link eksporterer de valgte Dataverse-tabeller i CSV-format med bestemte tidsintervaller og behandler dem via et Delta Lake-konverterings Spark-job. Når denne konverteringsproces er fuldført, renses CSV-data til lagring. Derudover planlægges en række vedligeholdelsesjob til at køre på daglig basis, hvor der automatisk udføres komprimerings- og rydningsprocesser for at flette og rydde op i datafiler for yderligere at optimere lagerpladsen og forbedre forespørgselsydeevnen.
Forudsætninger
- Dataverse: Sørg for, at du har sikkerhedsrollen Dataverse-systemadministrator. Derudover skal de tabeller, du vil eksportere via Azure Synapse Link, have egenskaben Registrer ændringer aktiveret. Flere oplysninger: Avanceret opslag
- Azure Data Lake Storage Gen2: Du skal have adgang til en Azure Data Lake Storage Gen2-konto og Ejer og Bidragyder til lagring af Blob Data-rolleadgang. Lagerkontoen skal aktivere hierarkisk navneområde og offentlig netværksadgang for både den første konfiguration og deltasynkronisering. Tillad adgang til lagerkontonøgle kræves kun i forbindelse med den første konfiguration.
- Synapse-arbejdsområde: Du skal have et Synapse-arbejdsområde og rollen Ejer i Access Control (IAM) og rolleadgangen Synapse-administrator i Synapse Studio. Arbejdsområdet Synapse skal være i det samme område som din Azure Data Lake Storage Gen2-konto. Lagerkontoen skal tilføjes som en tilknyttet tjeneste i Synapse Studio. Hvis du vil oprette et Synapsearbejdsområde, skal du gå til Oprettelse af et Synapsearbejdsområde.
- En Apache Spark-gruppe i det tilsluttede Azure Synapse workspace med Apache Spark version 3.4, der bruger denne anbefalede konfiguration af Spark-gruppe. Du kan finde oplysninger om, hvordan du opretter en Spark-gruppe i Opret ny Apache Spark-gruppe.
- Minimumskravet til Microsoft Dynamics 365-version for at bruge denne funktion er 9.2.22082. Flere oplysninger: Tilmelde dig opdateringer med tidlig adgang
Anbefalet konfiguration af Spark-gruppe
Denne konfiguration kan opfattes som et bootstrap-trin i almindelige use cases.
- Nodestørrelse: lille (4 vCores / 32 GB)
- Autoskalering: Aktiveret
- Antal noder: 5 til 10
- Automatisk pause: Aktiveret
- Antal minutter inaktiv: 5
- Apache Spark: 3.4
- Dynamisk allokere eksekutorer: Aktiveret
- Standardantal eksekutorer: 1 til 9
Vigtige oplysninger
Brug Spark-gruppen udelukkende til Delta Lake-konverteringsoperation med Synapse-link til Dataverse. Du kan opnå optimal pålidelighed og ydeevne ved at undgå at køre andre Spark-job ved hjælp af den samme Spark-pulje.
Tilslut Dataverse til Synapse-arbejdsområde, og eksportér data i Delta Lake-format
Log på Power Apps, og vælg det ønskede miljø.
I venstre navigationsrude skal du vælge Azure Synapse Link. Hvis elementet ikke findes i sidepanelruden, skal du vælge ...Flere og derefter vælge det ønskede element.
Vælg + Nyt link på kommandolinjen
Vælg Opret forbindelse til dit Azure Synapse Analytics-arbejdsområde, og vælg derefter Abonnement, Ressourcegruppe og Arbejdsområdenavn.
Vælg Brug af Spark-pulje til behandling, og vælg derefter den foruddefinerede Spark-pulje og Lagerkonto.
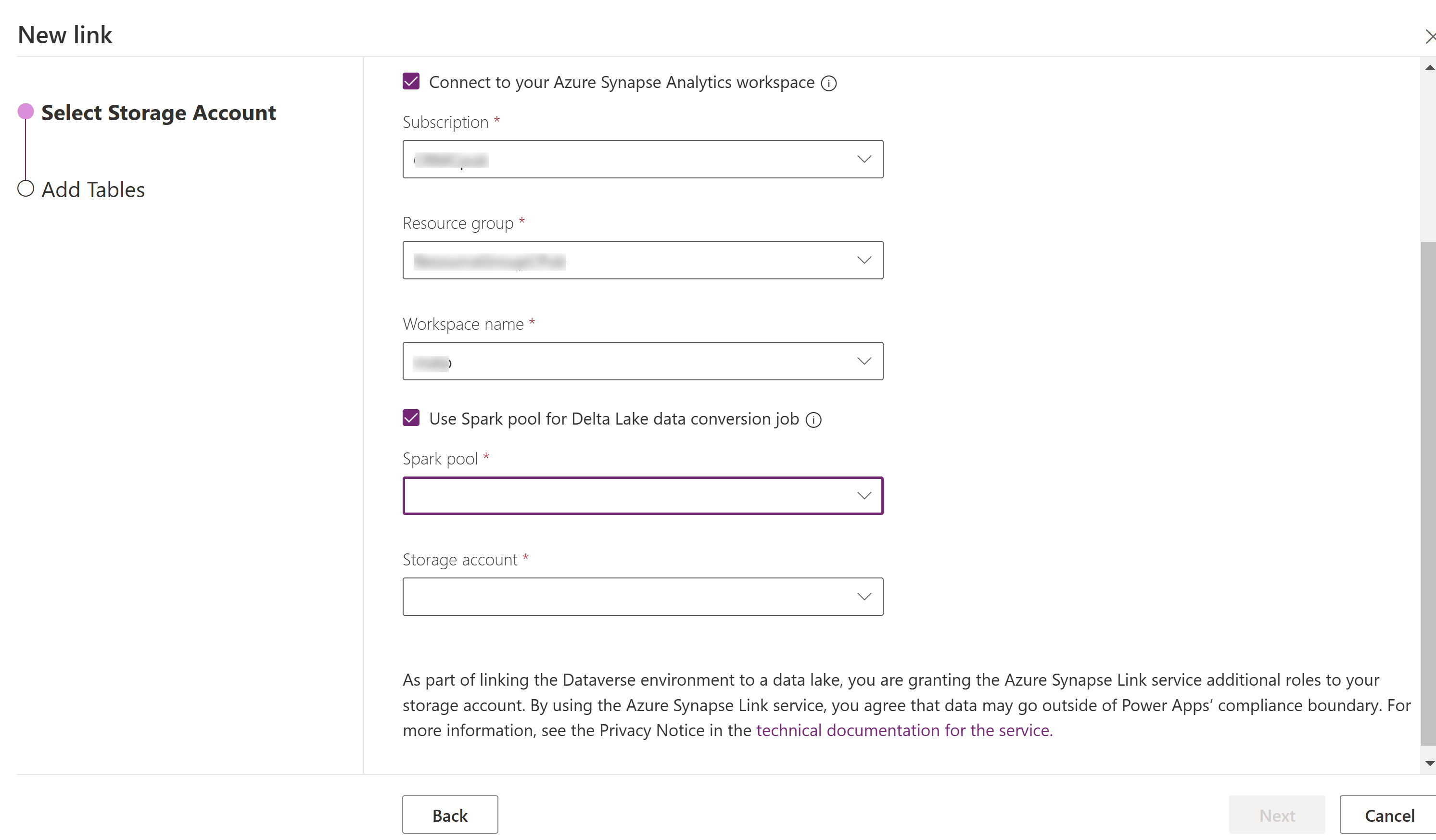
Vælg Næste.
Tilføj de tabeller, du vil eksportere, og vælg derefter Avanceret.
Du kan også vælge Vis avancerede konfigurationsindstillinger og angive tidsintervallet i minutter, for hvor ofte de trinvise opdateringer skal registreres.
Vælg Gem.
Overvåg dit Azure Synapse Link- og din datakonvertering
- Vælg det ønskede Azure Synapse Link, og vælg derefter Gå til Azure Synapse Analytics-arbejdsområdet på kommandolinjen.
- Vælg Overvåg>Apache Spark-applikationer. Flere oplysninger: Brug Synapse Studio til at overvåge dine Apache Spark-applikationer
Få vist dine data fra Synapse-arbejdsområdet
- Vælg det ønskede Azure Synapse Link, og vælg derefter Gå til Azure Synapse Analytics-arbejdsområdet på kommandolinjen.
- Udvid Lake-databaser i venstre rude, vælg dataverse-environmentNameorganizationUniqueName, og udvid derefter Tabeller. Alle Parquet-tabeller er angivet og tilgængelige til analyse med navngivningskonventionen DataverseTableName.(Non_partitioned tabel).
Bemærk
Brug ikke tabeller med navngivningskonventionen _partitioneret. Når du vælger Delta parquet som format, bruges tabeller med navnekonventionen _partition som midlertidige tabeller og fjernes, når de er brugt af systemet.
Få vist dine data fra Azure Data Lake Storage Gen2
- Vælg det ønskede Azure Synapse Link, og vælg derefter Gå til Azure data lake på kommandolinjen.
- Vælg beholderne under Datalager.
- Vælg *dataverse- *environmentName-organizationUniqueName. Alle parquet-filer gemmes i deltalake-mappen.
In-place-opgradering til Apache Spark 3.4 med Delta Lake 2.4
Forudsætninger
- Du skal have en eksisterende Azure Synapse Link til Dataverse Delta Lake-profil, der kører med en Synapse Spark-version 3.3.
- Du skal oprette en ny Synapse Spark-pulje med Spark version 3.4 ved at bruge den samme eller højere nodes hardwarekonfiguration inden for det samme Synapse-arbejdsområde. Du kan finde oplysninger om, hvordan du opretter en Spark-gruppe i Opret ny Apache Spark-gruppe. Denne Spark pool bør oprettes uafhængigt af den nuværende 3.3 pool.
In-place opgradering til Spark 3.4:
- Log på Power Apps, og vælg det foretrukne miljø.
- I venstre navigationsrude skal du vælge Azure Synapse Link. Hvis elementet ikke findes i venstre navigationsrude, skal du vælge ...Flere og derefter vælge det ønskede element.
- Åbn Azure Synapse Link-profilen, og vælg derefter Opgrader til Apache Spark 3.4 med Delta Lake 2.4.
- Vælg Den tilgængelige Spark-gruppe på listen, og vælg Opdater
Bemærk
Spark-gruppeopgraderingen sker kun, når et nyt Delta Lake-konverterings-Spark-job udløses. Sørg for, at du har mindst én dataændring efter at have valgt Opdatering.