Selvstudium Del 2: Udforsk og visualiser data ved hjælp af Microsoft Fabric-notesbøger
I dette selvstudium lærer du, hvordan du udfører EDA (Exploratory Data Analysis) for at undersøge og undersøge dataene, samtidig med at du opsummerer de vigtigste egenskaber ved hjælp af teknikker til datavisualisering.
Du skal bruge seaborn, som er et Python-datavisualiseringsbibliotek, der indeholder en grænseflade på højt niveau til oprettelse af visualiseringer på dataframes og matrixer. Du kan få flere oplysninger om seabornunder Seaborn: Statistical Data Visualization.
Du skal også bruge Data Wrangler, et notesbogbaseret værktøj, der giver dig en fordybende oplevelse til at udføre udforskning af dataanalyser og rengøring.
De vigtigste trin i dette selvstudium er:
- Læs de data, der er gemt fra en deltatabel i lakehouse.
- Konvertér en Spark DataFrame til Pandas DataFrame, som python-visualiseringsbiblioteker understøtter.
- Brug Data Wrangler til at udføre indledende datarensning og -transformation.
- Udfør udforskningsdataanalyse ved hjælp af
seaborn.
Forudsætninger
Få et Microsoft Fabric-abonnement. Du kan også tilmelde dig en gratis Microsoft Fabric-prøveversion.
Log på Microsoft Fabric.
Brug oplevelsesskifteren nederst til venstre på startsiden til at skifte til Fabric.

Dette er del 2 af 5 i selvstudieserien. Hvis du vil fuldføre dette selvstudium, skal du først fuldføre:
Følg med i notesbogen
2-explore-cleanse-data.ipynb er den notesbog, der følger med dette selvstudium.
Hvis du vil åbne den medfølgende notesbog til dette selvstudium, skal du følge vejledningen i Forbered dit system til selvstudier om datavidenskab importere notesbogen til dit arbejdsområde.
Hvis du hellere vil kopiere og indsætte koden fra denne side, kan du oprette en ny notesbog.
Sørg for at vedhæfte et lakehouse til notesbogen, før du begynder at køre kode.
Vigtig
Vedhæft det samme lakehouse, du brugte i del 1.
Læs rådata fra lakehouse
Læs rådata fra afsnittet Filer i lakehouse. Du har uploadet disse data i den forrige notesbog. Sørg for, at du har knyttet det samme lakehouse, som du brugte i del 1, til denne notesbog, før du kører denne kode.
df = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv("Files/churn/raw/churn.csv")
.cache()
)
Opret en pandas DataFrame fra datasættet
Konvertér spark DataFrame til pandas DataFrame for at gøre det nemmere at behandle og visualisere.
df = df.toPandas()
Vis rådata
Udforsk rådata med display, gør nogle grundlæggende statistikker, og vis diagramvisninger. Bemærk, at du først skal importere de påkrævede biblioteker, f.eks. Numpy, Pnadas, Seabornog Matplotlib til dataanalyse og visualisering.
import seaborn as sns
sns.set_theme(style="whitegrid", palette="tab10", rc = {'figure.figsize':(9,6)})
import matplotlib.pyplot as plt
import matplotlib.ticker as mticker
from matplotlib import rc, rcParams
import numpy as np
import pandas as pd
import itertools
display(df, summary=True)
Brug Data Wrangler til at udføre indledende datarensning
Hvis du vil udforske og transformere pandas Dataframes i din notesbog, skal du starte Data Wrangler direkte fra notesbogen.
Seddel
Data Wrangler kan ikke åbnes, mens notesbogkernen er optaget. Celleudførelsen skal fuldføres, før Data Wrangler startes.
- Vælg
Launch Data Wrangler under fanen Data påbåndet i notesbogen. Du får vist en liste over aktiverede pandas DataFrames, der kan redigeres. - Vælg den DataFrame, du vil åbne i Data Wrangler. Da denne notesbog kun indeholder én DataFrame,
dfskal du vælgedf.
Data Wrangler starter og genererer en beskrivende oversigt over dine data. Tabellen i midten viser hver datakolonne. Panelet Oversigt ud for tabellen viser oplysninger om DataFrame. Når du vælger en kolonne i tabellen, opdateres oversigten med oplysninger om den valgte kolonne. I nogle tilfælde vil de viste og opsummerede data være en afkortet visning af din DataFrame. Når dette sker, får du vist et advarselsbillede i oversigtsruden. Peg på denne advarsel for at få vist tekst, der forklarer situationen.

Hver handling, du udfører, kan anvendes i et spørgsmål om klik, opdatere datavisningen i realtid og generere kode, som du kan gemme tilbage til din notesbog som en funktion, der kan genbruges.
Resten af dette afsnit fører dig gennem trinnene til at udføre datarensning med Data Wrangler.
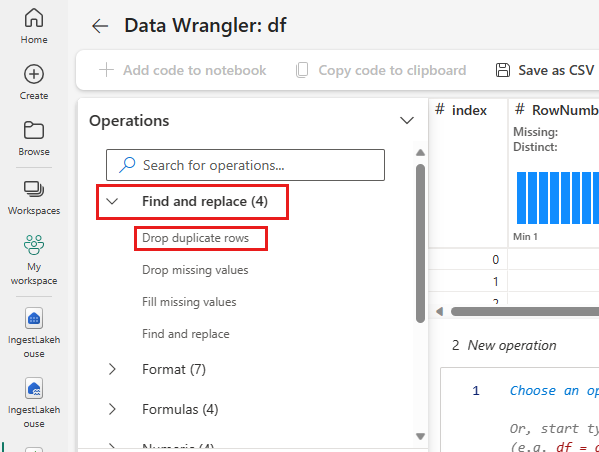
Slip dublerede rækker
I panelet til venstre er der en liste over handlinger (f.eks. Søg og erstat, Formatér, Formler, Numerisk), som du kan udføre på datasættet.
Udvid Søg efter og erstat, og vælg Slip dublerede rækker.
Der vises et panel, hvor du kan vælge den liste over kolonner, du vil sammenligne, for at definere en dubletrække. Vælg Rækkenummer og CustomerId.
I det midterste panel er der et eksempel på resultaterne af denne handling. Under prøveversionen er den kode, der skal bruges til at udføre handlingen. I dette tilfælde ser dataene ud til at være uændrede. Men da du ser på en afkortet visning, er det en god idé stadig at anvende handlingen.
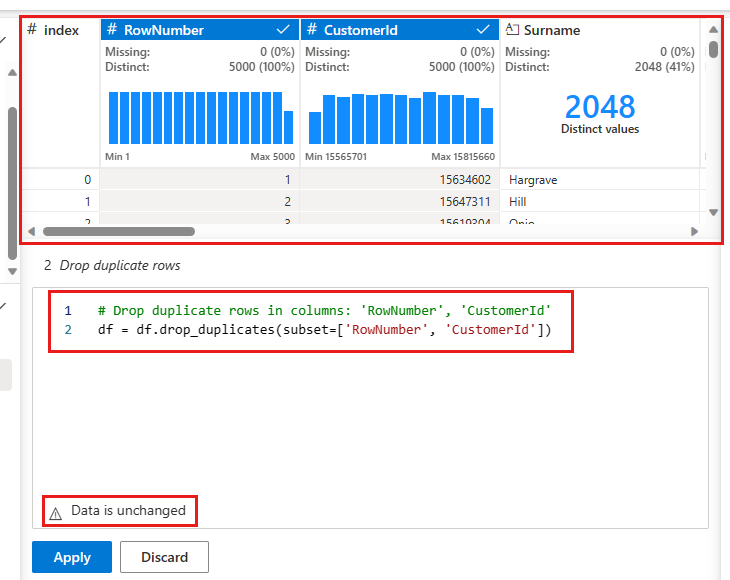
Vælg Anvend (enten i siden eller nederst) for at gå til næste trin.

Slip rækker med manglende data
Brug Data Wrangler til at slippe rækker med manglende data på tværs af alle kolonner.
Vælg Slip manglende værdier fra Søg efter og erstat.
Vælg Vælg alle i kolonnerne Target.
Vælg Anvend for at gå videre til næste trin.

Slip kolonner
Brug Data Wrangler til at slippe kolonner, som du ikke har brug for.
Udvid skema, og vælg Slip kolonner.
Vælg RowNumber, CustomerIdEfternavn. Disse kolonner vises med rødt i eksempelvisningen for at vise, at de er ændret af koden (i dette tilfælde er de udeladt).
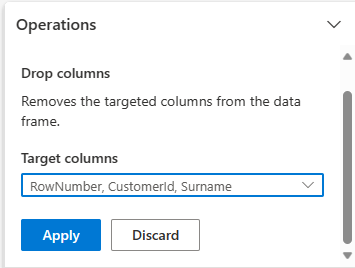
Vælg Anvend for at gå videre til næste trin.

Føj kode til notesbog
Hver gang du vælger Anvend, oprettes der et nyt trin i panelet Rengøringstrin nederst til venstre. Nederst i panelet skal du vælge eksempelkode for alle trin for at få vist en kombination af alle de separate trin.
Vælg Føj kode til notesbogen øverst til venstre for at lukke Data Wrangler og tilføje koden automatisk. Føj kode til notesbog ombryder koden i en funktion og kalder derefter funktionen.
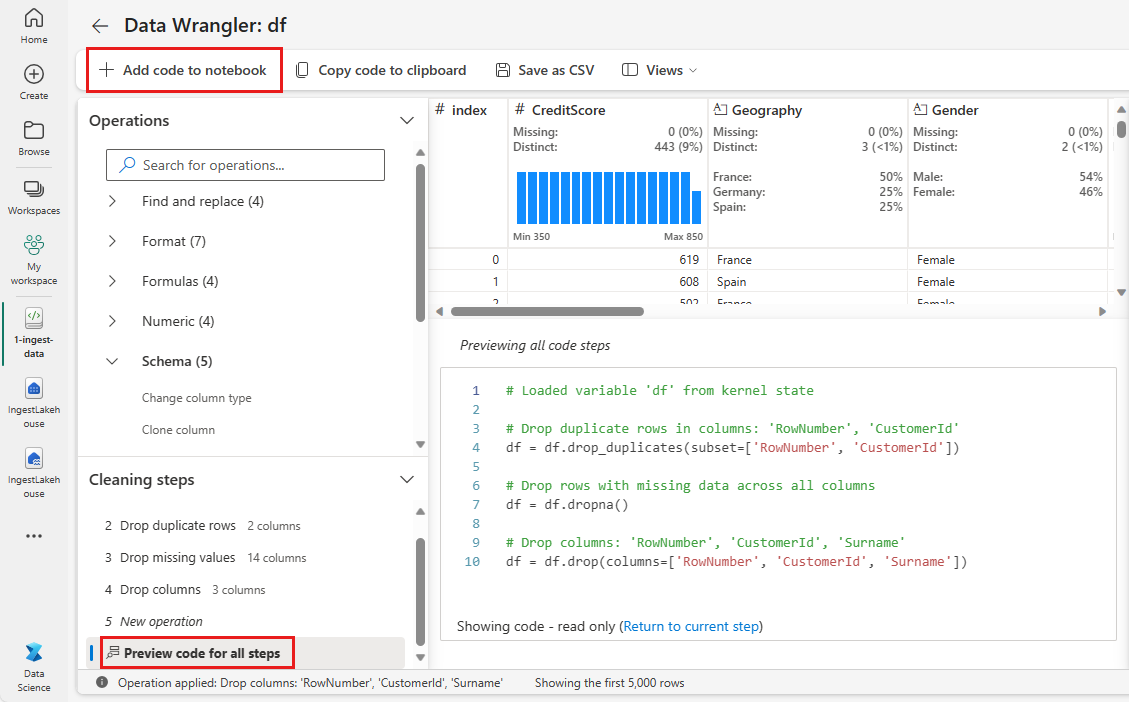
Drikkepenge
Den kode, der genereres af Data Wrangler, anvendes ikke, før du manuelt kører den nye celle.
Hvis du ikke brugte Data Wrangler, kan du i stedet bruge denne næste kodecelle.
Denne kode svarer til den kode, der er produceret af Data Wrangler, men føjer argumentet inplace=True til hvert af de genererede trin. Ved at angive inplace=Trueoverskriver pandas den oprindelige DataFrame i stedet for at producere en ny DataFrame som et output.
# Modified version of code generated by Data Wrangler
# Modification is to add in-place=True to each step
# Define a new function that include all above Data Wrangler operations
def clean_data(df):
# Drop rows with missing data across all columns
df.dropna(inplace=True)
# Drop duplicate rows in columns: 'RowNumber', 'CustomerId'
df.drop_duplicates(subset=['RowNumber', 'CustomerId'], inplace=True)
# Drop columns: 'RowNumber', 'CustomerId', 'Surname'
df.drop(columns=['RowNumber', 'CustomerId', 'Surname'], inplace=True)
return df
df_clean = clean_data(df.copy())
df_clean.head()
Udforsk dataene
Vis nogle opsummeringer og visualiseringer af de rensede data.
Fastlæg kategori-, numeriske og målattributter
Brug denne kode til at bestemme kategoriske, numeriske og målattributter.
# Determine the dependent (target) attribute
dependent_variable_name = "Exited"
print(dependent_variable_name)
# Determine the categorical attributes
categorical_variables = [col for col in df_clean.columns if col in "O"
or df_clean[col].nunique() <=5
and col not in "Exited"]
print(categorical_variables)
# Determine the numerical attributes
numeric_variables = [col for col in df_clean.columns if df_clean[col].dtype != "object"
and df_clean[col].nunique() >5]
print(numeric_variables)
Femtalsoversigten
Vis oversigten med fem tal (minimumresultatet, første kvartil, medianen, tredje kvartil, den maksimale score) for de numeriske attributter ved hjælp af feltafbildninger.
df_num_cols = df_clean[numeric_variables]
sns.set(font_scale = 0.7)
fig, axes = plt.subplots(nrows = 2, ncols = 3, gridspec_kw = dict(hspace=0.3), figsize = (17,8))
fig.tight_layout()
for ax,col in zip(axes.flatten(), df_num_cols.columns):
sns.boxplot(x = df_num_cols[col], color='green', ax = ax)
fig.delaxes(axes[1,2])
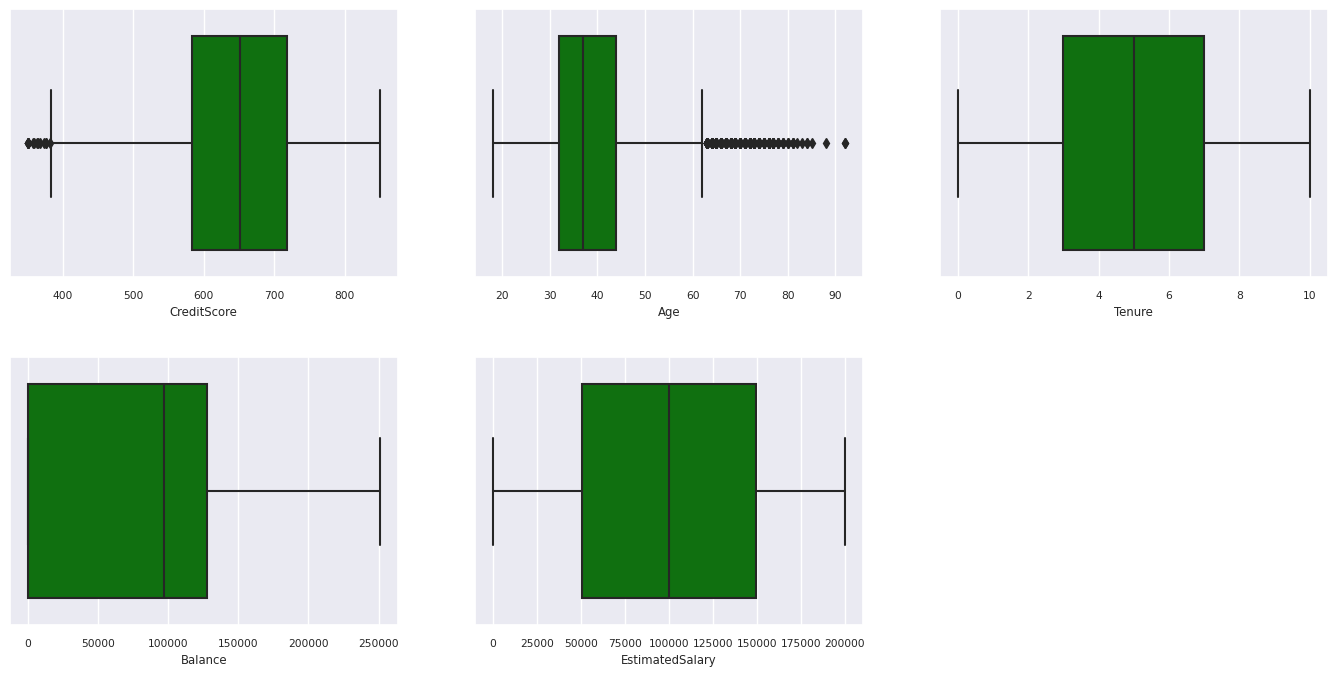
Distribution af afsluttede og ikke-xiterede kunder
Vis fordelingen af afsluttede kunder i forhold til kunder uden tilknytning på tværs af kategoriattributterne.
attr_list = ['Geography', 'Gender', 'HasCrCard', 'IsActiveMember', 'NumOfProducts', 'Tenure']
fig, axarr = plt.subplots(2, 3, figsize=(15, 4))
for ind, item in enumerate (attr_list):
sns.countplot(x = item, hue = 'Exited', data = df_clean, ax = axarr[ind%2][ind//2])
fig.subplots_adjust(hspace=0.7)

Distribution af numeriske attributter
Vis frekvensfordelingen af numeriske attributter ved hjælp af histogramme.
columns = df_num_cols.columns[: len(df_num_cols.columns)]
fig = plt.figure()
fig.set_size_inches(18, 8)
length = len(columns)
for i,j in itertools.zip_longest(columns, range(length)):
plt.subplot((length // 2), 3, j+1)
plt.subplots_adjust(wspace = 0.2, hspace = 0.5)
df_num_cols[i].hist(bins = 20, edgecolor = 'black')
plt.title(i)
plt.show()

Udfør funktionskonstruktion
Udfør funktionskonstruktion for at generere nye attributter baseret på aktuelle attributter:
df_clean["NewTenure"] = df_clean["Tenure"]/df_clean["Age"]
df_clean["NewCreditsScore"] = pd.qcut(df_clean['CreditScore'], 6, labels = [1, 2, 3, 4, 5, 6])
df_clean["NewAgeScore"] = pd.qcut(df_clean['Age'], 8, labels = [1, 2, 3, 4, 5, 6, 7, 8])
df_clean["NewBalanceScore"] = pd.qcut(df_clean['Balance'].rank(method="first"), 5, labels = [1, 2, 3, 4, 5])
df_clean["NewEstSalaryScore"] = pd.qcut(df_clean['EstimatedSalary'], 10, labels = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
Brug Data Wrangler til at udføre en-hot-kodning
Data Wrangler kan også bruges til at udføre en-hot kodning. Det gør du ved at åbne Data Wrangler igen. Denne gang skal du vælge de df_clean data.
- Udvid Formler, og vælg En-hot-kode.
- Der vises et panel, hvor du kan vælge den liste over kolonner, du vil udføre en hot-kodning på. Vælg Geografi og Køn.
Du kan kopiere den genererede kode, lukke Data Wrangler for at vende tilbage til notesbogen og derefter indsætte den i en ny celle. Eller vælg Føj kode til notesbog øverst til venstre for at lukke Data Wrangler og tilføje koden automatisk.
Hvis du ikke brugte Data Wrangler, kan du i stedet bruge denne næste kodecelle:
# This is the same code that Data Wrangler will generate
import pandas as pd
def clean_data(df_clean):
# One-hot encode columns: 'Geography', 'Gender'
df_clean = pd.get_dummies(df_clean, columns=['Geography', 'Gender'])
return df_clean
df_clean_1 = clean_data(df_clean.copy())
df_clean_1.head()
Oversigt over observationer fra den udforskende dataanalyse
- De fleste af kunderne kommer fra Frankrig i sammenligning med Spanien og Tyskland, mens Spanien har den laveste faldrate sammenlignet med Frankrig og Tyskland.
- De fleste af kunderne har kreditkort.
- Der er kunder, hvis alder og kreditscore er henholdsvis over 60 og under 400, men de kan ikke betragtes som udenforliggende værdier.
- Meget få kunder har mere end to af bankens produkter.
- Kunder, der ikke er aktive, har en højere faldrate.
- Køn og ansættelsesår ser ikke ud til at have indflydelse på kundens beslutning om at lukke bankkontoen.
Opret en deltatabel til de rensede data
Du skal bruge disse data i den næste notesbog i denne serie.
table_name = "df_clean"
# Create Spark DataFrame from pandas
sparkDF=spark.createDataFrame(df_clean_1)
sparkDF.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark dataframe saved to delta table: {table_name}")
Næste trin
Oplær og registrer modeller til maskinel indlæring med disse data: