Hurtig kopi i Dataflow Gen2
I denne artikel beskrives funktionen til hurtig kopiering i Dataflows Gen2 til Data Factory i Microsoft Fabric. Dataflow hjælper med at indtage og transformere data. Med introduktionen af dataflowskalering med SQL DW-beregning kan du transformere dine data i stor skala. Dine data skal dog først indtages. Med introduktionen af hurtig kopiering kan du indtage terabyte data med den nemme oplevelse af dataflow, men med den skalerbare backend af pipelinen Kopiér aktivitet.
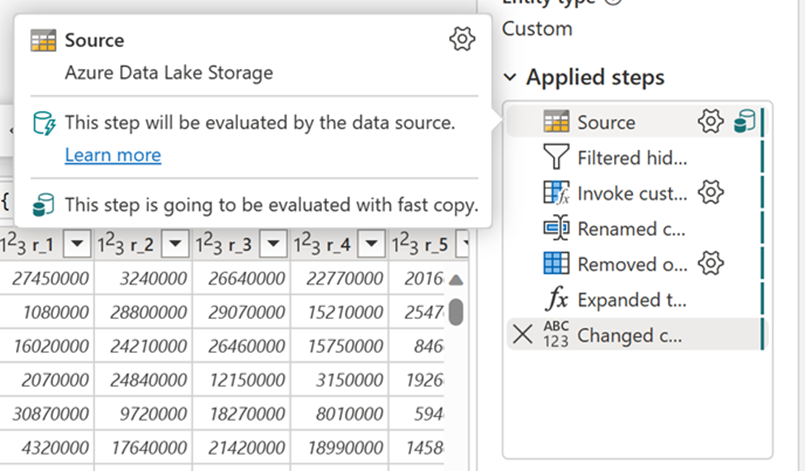
Når du har aktiveret denne funktion, skifter Dataflow automatisk backend, når datastørrelsen overskrider en bestemt grænse, uden at det er nødvendigt at ændre noget under oprettelsen af dataflowet. Efter opdateringen af et dataflow kan du tjekke opdateringshistorikken ind for at se, om der blev brugt hurtig kopi under kørslen, ved at se på den programtype , der vises der.
Når indstillingen Kræv hurtig kopiering er aktiveret, annulleres opdateringen af dataflowet, hvis der ikke bruges hurtig kopi. Dette hjælper dig med at undgå at vente på en timeout for opdatering for at fortsætte. Denne funktionsmåde kan også være nyttig i en fejlfindingssession for at teste dataflowets funktionsmåde med dine data, samtidig med at ventetiden reduceres. Ved hjælp af indikatorerne for hurtig kopiering i ruden med forespørgselstrin kan du nemt kontrollere, om din forespørgsel kan køre med hurtig kopi.
Forudsætninger
- Du skal have en Fabric-kapacitet.
- I forbindelse med fildata er filer i .csv eller parquetformat på mindst 100 MB og gemt i en ADLS Gen2-konto (Azure Data Lake Storage) eller en Blob Storage-konto.
- For database, herunder Azure SQL DB og PostgreSQL, 5 millioner rækker eller flere data i datakilden.
Bemærk
Du kan tilsidesætte tærsklen for at gennemtvinge hurtig kopiering ved at vælge indstillingen "Kræv hurtig kopi".
Understøttelse af connector
Hurtig kopiering understøttes i øjeblikket for følgende Dataflow Gen2-connectors:
- ADLS Gen2
- Blob Storage
- Azure SQL DB
- Lakehouse
- PostgreSQL
- SQL Server i det lokale lokale
- Lagersted
- Oracle
- Snowflake
Kopieringsaktiviteten understøtter kun nogle få transformationer, når der oprettes forbindelse til en filkilde:
- Kombiner filer
- Vælg kolonner
- Skift datatyper
- Omdøb en kolonne
- Fjern en kolonne
Du kan stadig anvende andre transformationer ved at opdele trinnene for indtagelse og transformation i separate forespørgsler. Den første forespørgsel henter faktisk dataene, og den anden forespørgsel refererer til resultaterne, så DW-beregning kan bruges. For SQL-kilder understøttes alle transformationer, der er en del af den oprindelige forespørgsel.
Når du indlæser forespørgslen direkte til en outputdestination, understøttes kun Lakehouse-destinationer i øjeblikket. Hvis du vil bruge en anden outputdestination, kan du faseforespørgslen først og referere til den senere.
Sådan bruger du hurtig kopi
Gå til det relevante Fabric-slutpunkt.
Gå til et Premium-arbejdsområde, og opret et dataflow Gen2.
På fanen Hjem i det nye dataflow skal du vælge Indstillinger:
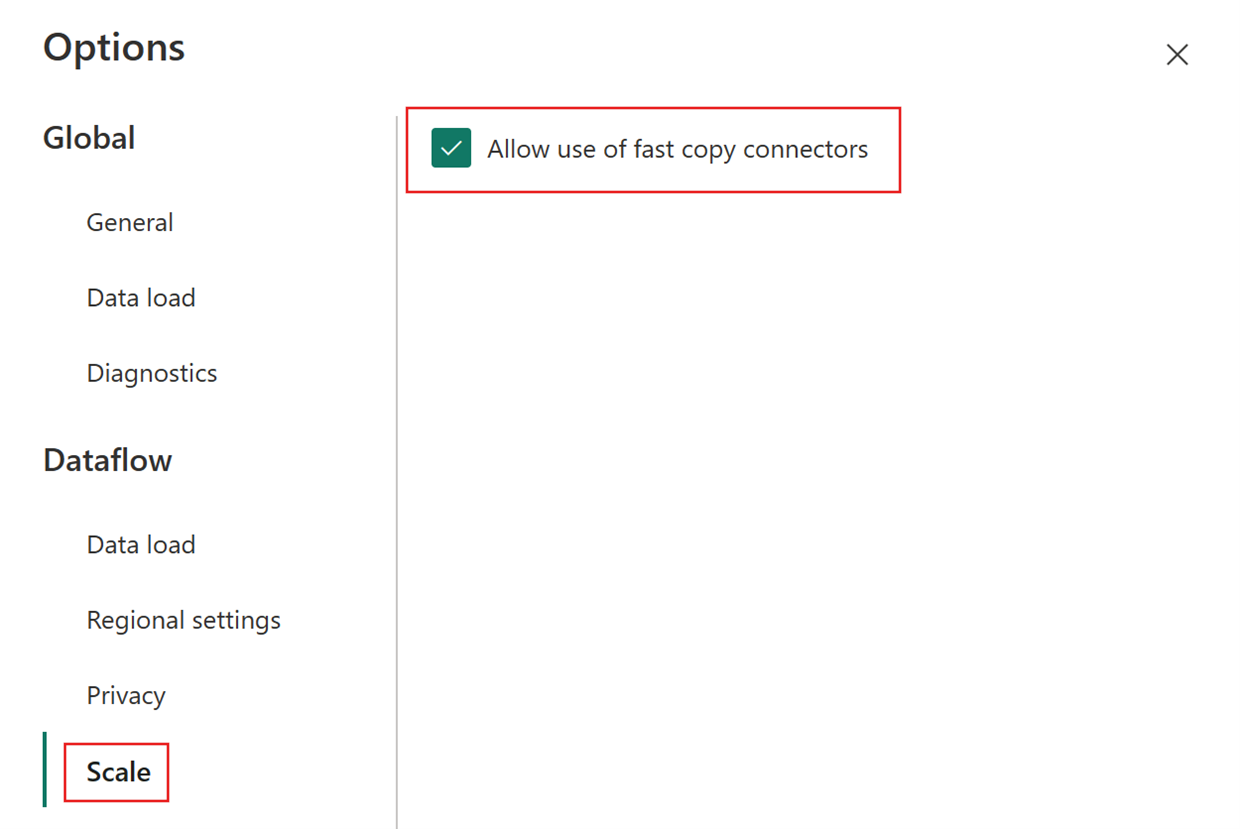
Vælg derefter fanen Skaler i dialogboksen Indstillinger, og markér afkrydsningsfeltet Tillad brug af forbindelser med hurtig kopiering for at aktivere hurtig kopiering. Luk derefter dialogboksen Indstillinger.
Vælg Hent data , og vælg derefter ADLS Gen2-kilden, og udfyld oplysningerne om din objektbeholder.
Brug funktionen Kombiner fil .
Hvis du vil sikre hurtig kopiering, skal du kun anvende transformationer, der er angivet i afsnittet Connector-understøttelse i denne artikel. Hvis du har brug for at anvende flere transformationer, skal du fase dataene først og referere til forespørgslen senere. Foretag andre transformationer i den forespørgsel, der refereres til.
(Valgfrit) Du kan angive indstillingen Kræv hurtig kopiering for forespørgslen ved at højreklikke på den for at vælge og aktivere denne indstilling.
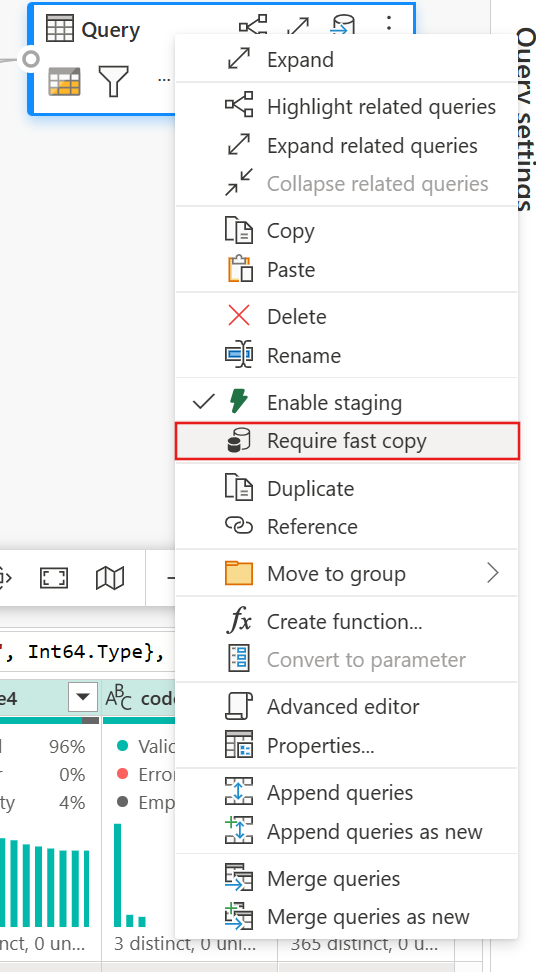
(Valgfrit) I øjeblikket kan du kun konfigurere en Lakehouse som outputdestination. For enhver anden destination skal du fase forespørgslen og referere til den senere i en anden forespørgsel, hvor du kan skrive til en hvilken som helst kilde.
Kontrollér indikatorerne for hurtig kopiering for at se, om din forespørgsel kan køre med hurtig kopi. Hvis det er tilfældet, vises CopyActivity i programtypen.

Publicer dataflowet.
Kontrollér, efter at opdateringen er fuldført, for at bekræfte, at der blev brugt en hurtig kopi.

Sådan opdeler du din forespørgsel for at udnytte hurtig kopiering
Hvis du vil have optimal ydeevne ved behandling af store datamængder med Dataflow Gen2, skal du bruge funktionen Hurtig kopiering til først at indføde data til midlertidig lagring og derefter transformere dem i stor skala med SQL DW-beregning. Denne fremgangsmåde forbedrer ydeevnen fra ende til anden betydeligt.
Hvis du vil implementere dette, kan hurtige kopieringsindikatorer hjælpe dig med at opdele forespørgslen i to dele: dataindtagelse til midlertidig lagring og transformation i stor skala med SQL DW-beregning. Du opfordres til at overføre så meget af evalueringen af en forespørgsel til Hurtig kopi, der kan bruges til at indtage dine data. Når indikatorer for hurtig kopiering fortæller, at resten af trinnene ikke kan udføres af Hurtig kopi, kan du opdele resten af forespørgslen med midlertidig lagring aktiveret.
Indikatorer for trindiagnosticering
| Indikator | Ikon | Beskrivelse |
|---|---|---|
| Dette trin evalueres med hurtig kopiering | 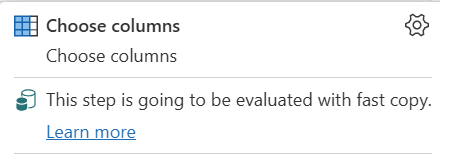
|
Indikatoren Hurtig kopiering fortæller dig, at forespørgslen op til dette trin understøtter hurtig kopiering. |
| Dette trin understøttes ikke af hurtig kopiering | 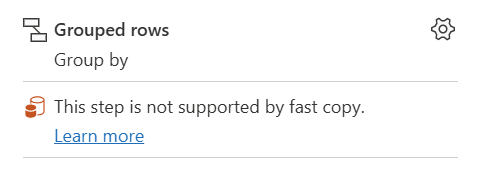
|
Indikatoren Hurtig kopi viser, at dette trin ikke understøtter Hurtig kopi. |
| Et eller flere trin i forespørgslen understøttes ikke af hurtige | 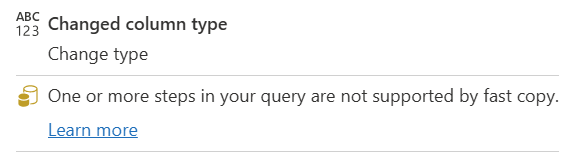
|
Indikatoren Hurtig kopiering viser, at nogle trin i denne forespørgsel understøtter Hurtig kopiering, mens andre ikke gør det. Hvis du vil optimere, skal du opdele forespørgslen: gule trin (understøttes muligvis af Hurtig kopi) og røde trin (understøttes ikke). |
Trinvis vejledning
Når du har fuldført din datatransformationslogik i Dataflow Gen2, evaluerer indikatoren For hurtig kopiering hvert trin for at bestemme, hvor mange trin der kan udnytte Hurtig kopiering for at opnå en bedre ydeevne.
I eksemplet nedenfor vises rødt i det sidste trin, hvilket angiver, at trinnet med Gruppér efter ikke understøttes af Hurtig kopiér. Alle tidligere trin, der viser gul, kan dog muligvis understøttes af Hurtig kopi.
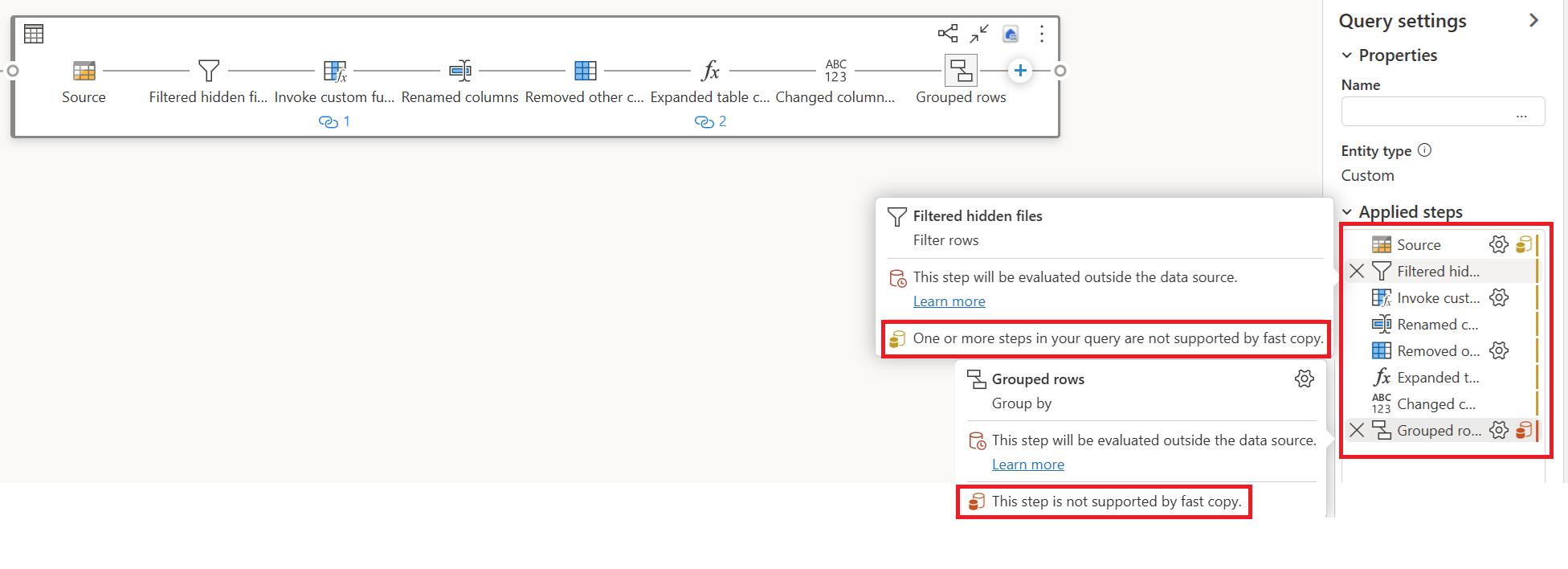
Hvis du i øjeblikket publicerer og kører dit Dataflow Gen2 direkte, bruger det ikke programmet Hurtig kopiering til at indlæse dine data som billedet nedenfor:
Hvis du vil bruge programmet Til hurtig kopiering og forbedre ydeevnen for dit Dataflow Gen2, kan du opdele din forespørgsel i to dele: dataindtagelse til midlertidig og storstilet transformation med SQL DW-beregning som følger:
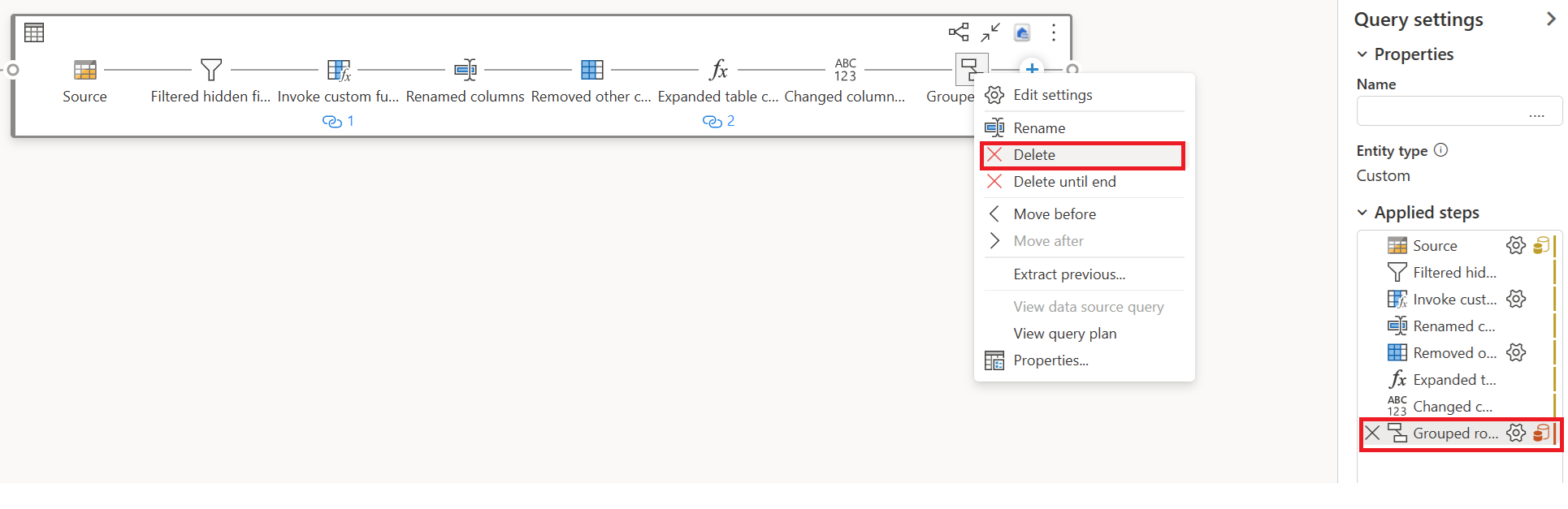
Fjern de transformationer (med rødt), der ikke understøttes af Hurtig kopi, sammen med destinationen (hvis de er defineret).
Indikatoren Hurtig kopiering viser nu grøn for de resterende trin, hvilket betyder, at din første forespørgsel kan udnytte Hurtig kopi for at opnå en bedre ydeevne.
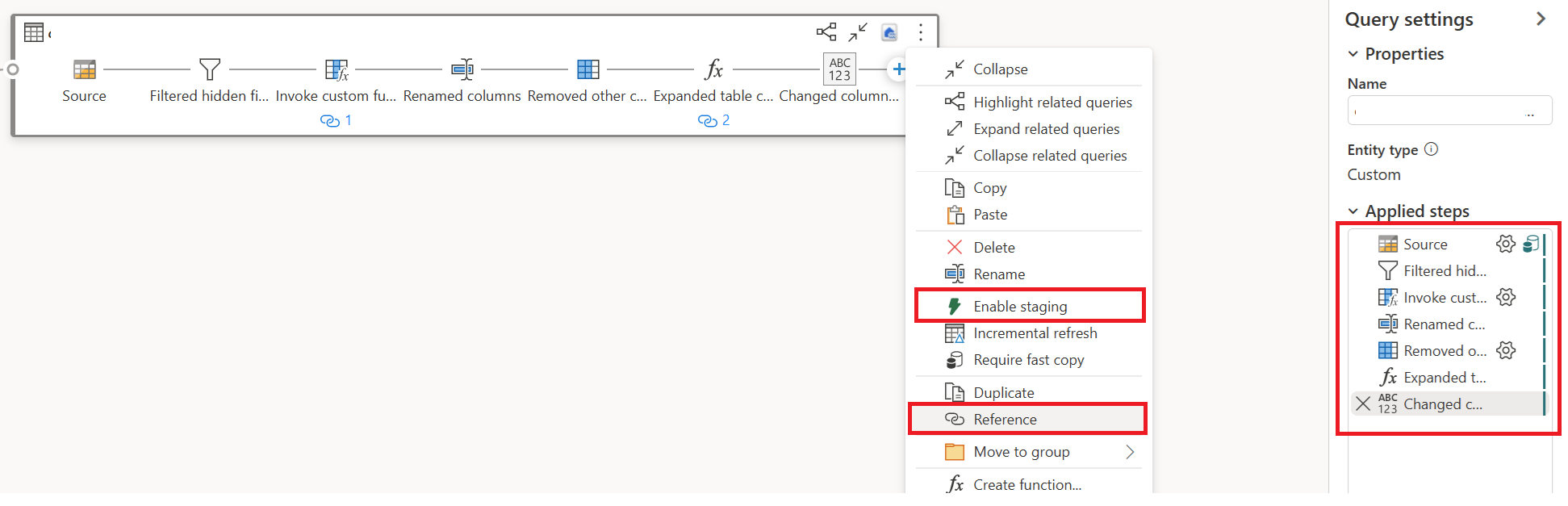
Vælg Handling for din første forespørgsel, og vælg derefter Aktivér midlertidig og reference.
I en ny refereret forespørgsel læste transformationen "Gruppér efter" og destinationen (hvis relevant).
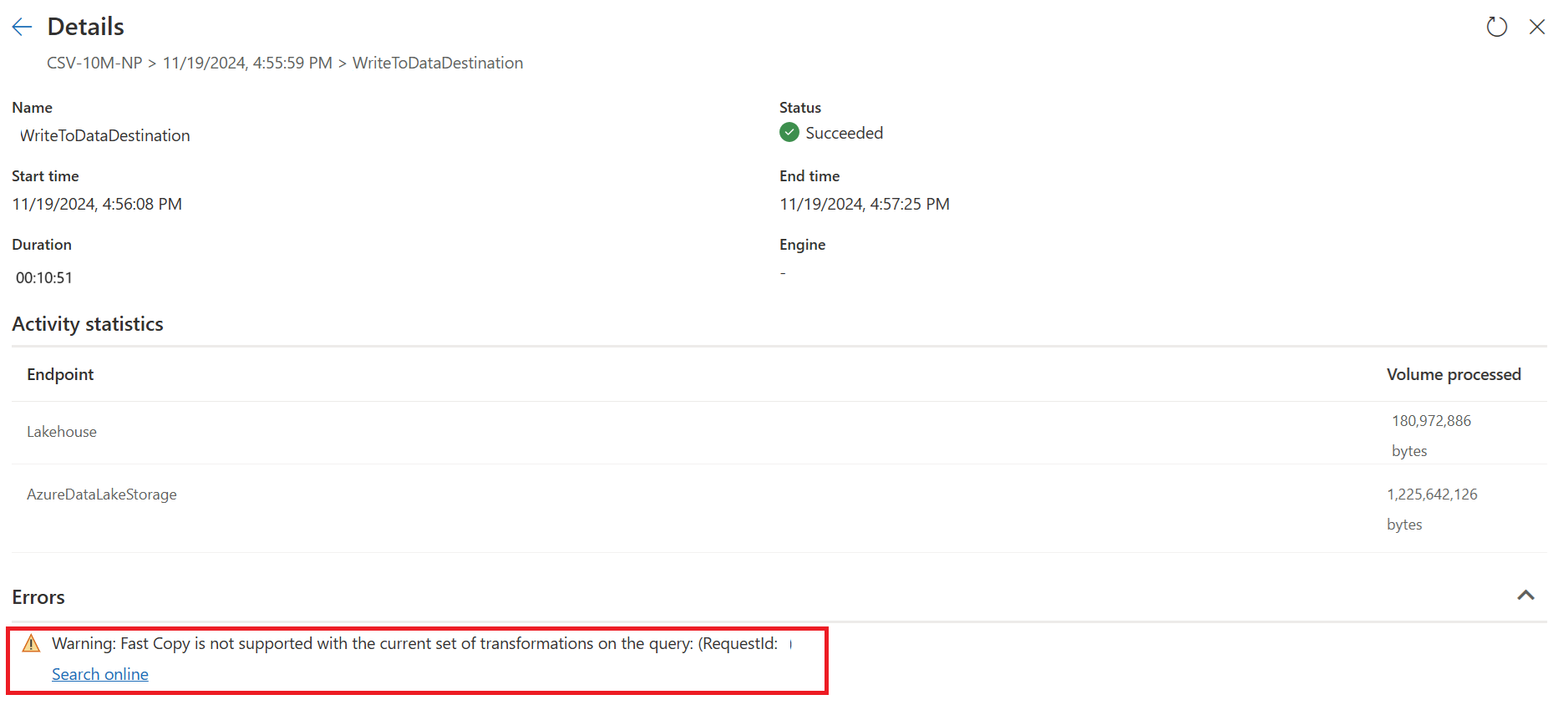
Publicer og opdater dit Dataflow Gen2. Du kan nu se to forespørgsler i dit Dataflow Gen2, og den samlede varighed reduceres stort set.
Den første forespørgsel henter data til midlertidig lagring ved hjælp af Hurtig kopi.
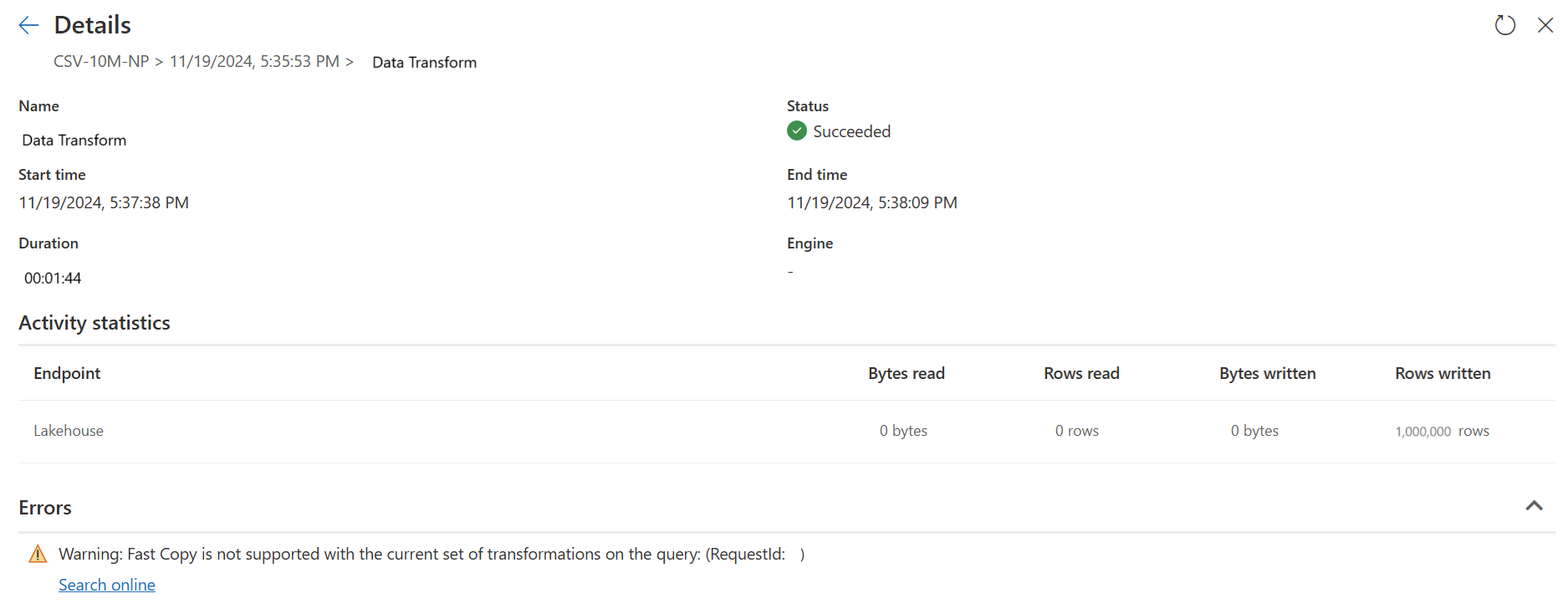
Den anden forespørgsel udfører transformationer i stor skala ved hjælp af SQL DW-beregning.
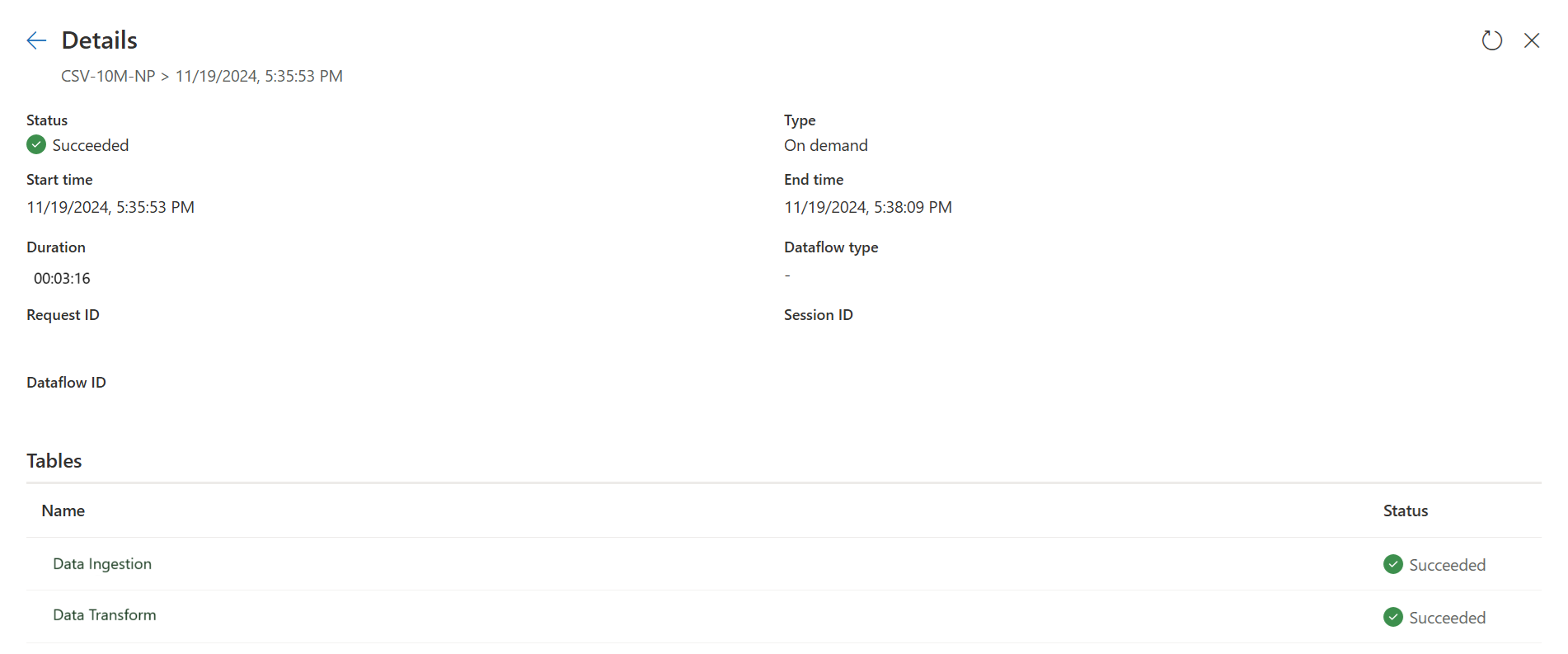
Den første forespørgsel:
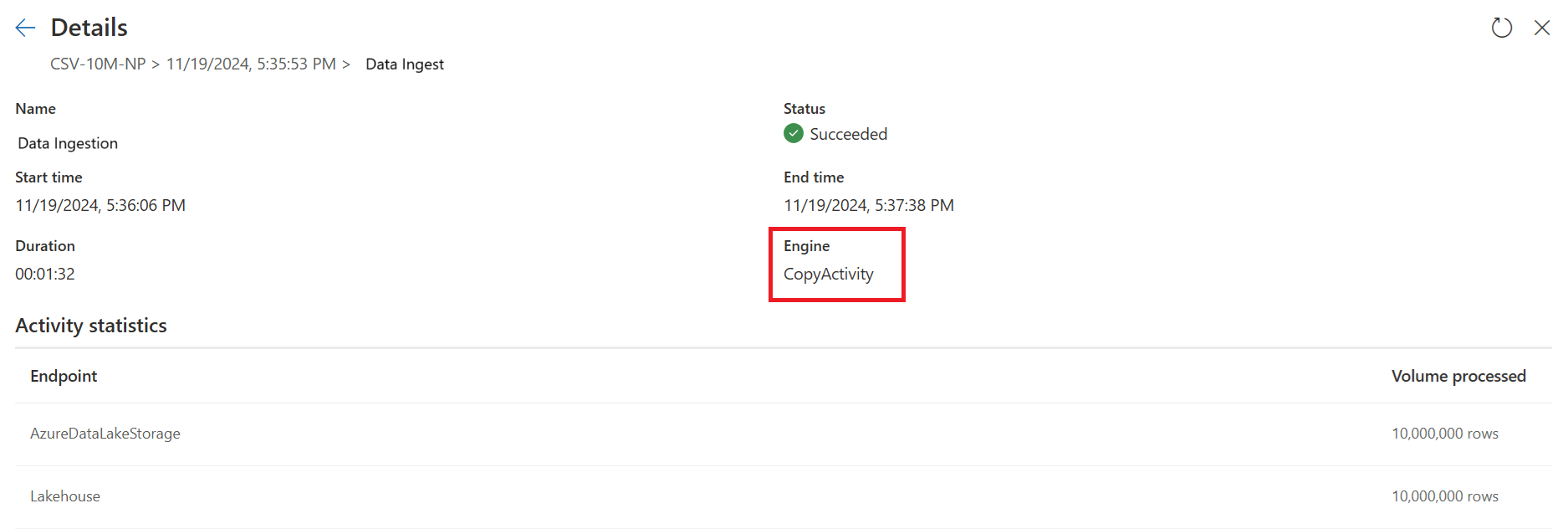
Den anden forespørgsel:
Kendte begrænsninger
- Der kræves en datagateway i det lokale miljø version 3000.214.2 eller nyere for at understøtte Hurtig kopi.
- VNet-gatewayen understøttes ikke.
- Skrivning af data til en eksisterende tabel i Lakehouse understøttes ikke.
- Fast skema understøttes ikke.