Trinvis opdatering i Dataflow Gen2 (prøveversion)
I denne artikel introducerer vi trinvis opdatering af data i Dataflow Gen2 til Microsoft Fabric's Data Factory. Når du bruger dataflow til dataindtagelse og -transformation, er der scenarier, hvor du specifikt kun skal opdatere nye eller opdaterede data – især i takt med at dine data fortsætter med at vokse. Funktionen til trinvis opdatering løser dette behov ved at give dig mulighed for at reducere opdateringstider, forbedre pålideligheden ved at undgå langvarige handlinger og minimere ressourceforbruget.
Forudsætninger
Hvis du vil bruge trinvis opdatering i Dataflow Gen2, skal du opfylde følgende forudsætninger:
- Du skal have en Fabric-kapacitet.
- Din datakilde understøtter foldning (anbefales) og skal indeholde en Date/DateTime-kolonne, der kan bruges til at filtrere dataene.
- Du skal have en datadestination, der understøtter trinvis opdatering. Du kan få flere oplysninger ved at gå til Destinationssupport.
- Før du går i gang, skal du sikre dig, at du har gennemgået begrænsningerne ved trinvis opdatering. Du kan få flere oplysninger ved at gå til Begrænsninger.
Destinationssupport
Følgende datadestinationer understøttes til trinvis opdatering:
- Fabric Warehouse
- Azure SQL Database
- Azure Synapse Analytics
Andre destinationer som Lakehouse kan bruges sammen med trinvis opdatering ved hjælp af en anden forespørgsel, der refererer til de trinvise data for at opdatere datadestinationen. På denne måde kan du stadig bruge trinvis opdatering til at reducere mængden af data, der skal behandles og hentes fra kildesystemet. Men du skal foretage en fuld opdatering fra de fasede data til datadestinationen.
Sådan bruger du trinvis opdatering
Opret et nyt Dataflow Gen2, eller åbn et eksisterende Dataflow Gen2.
I datafloweditoren skal du oprette en ny forespørgsel, der henter de data, du vil opdatere trinvist.
Kontrollér dataeksemplet for at sikre, at forespørgslen returnerer data, der indeholder kolonnen DateTime, Date eller DateTimeZone, som du kan bruge til at filtrere dataene.
Sørg for, at forespørgslen foldes helt, hvilket betyder, at forespørgslen skubbes helt ned til kildesystemet. Hvis forespørgslen ikke foldes helt, skal du ændre forespørgslen, så den foldes helt ud. Du kan sikre, at forespørgslen foldes fuldt ud ved at kontrollere forespørgselstrinnene i forespørgselseditoren.
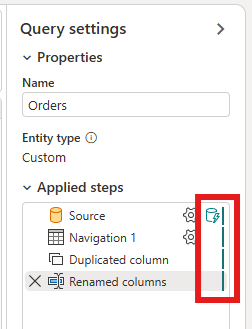
Højreklik på forespørgslen, og vælg Trinvis opdatering.
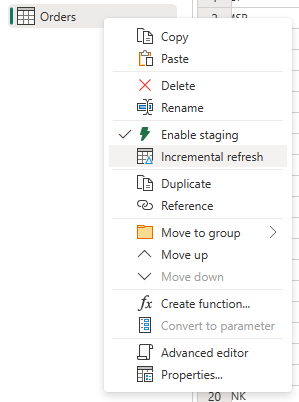
Angiv de nødvendige indstillinger for trinvis opdatering.
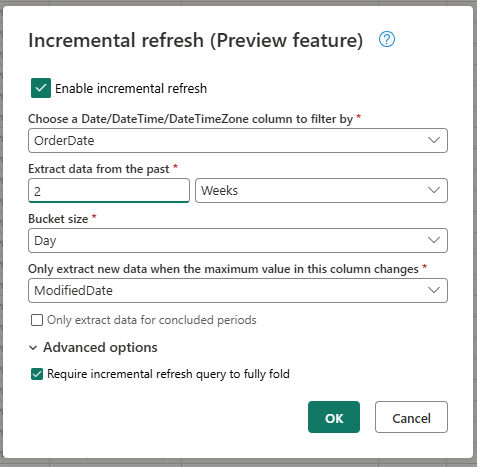
- Vælg en DateTime-kolonne, der skal filtreres efter.
- Udtræk data fra fortiden.
- Bucketstørrelse.
- Udtræk kun nye data, når den maksimale værdi i denne kolonne ændres.
Konfigurer de avancerede indstillinger, hvis det er nødvendigt.
- Kræv, at forespørgslen om trinvis opdatering foldes helt.
Vælg OK for at gemme indstillingerne.
Hvis du vil, kan du nu konfigurere en datadestination for forespørgslen. Sørg for, at du udfører denne konfiguration før den første trinvise opdatering, da datadestinationen ellers kun indeholder de trinvist ændrede data siden den seneste opdatering.
Publicer Dataflow Gen2.
Når du har konfigureret trinvis opdatering, opdaterer dataflowet automatisk dataene trinvist baseret på de indstillinger, du har angivet. Dataflowet henter kun de data, der er ændret siden den seneste opdatering. Dataflowet kører derfor hurtigere og bruger færre ressourcer.
Sådan fungerer trinvis opdatering i baggrunden
Trinvis opdatering fungerer ved at opdele dataene i buckets baseret på kolonnen DateTime. Hver bucket indeholder de data, der er ændret siden den seneste opdatering. Dataflowet ved, hvad der er ændret, ved at kontrollere maksimumværdien i den kolonne, du har angivet. Hvis den maksimale værdi ændres for den pågældende bucket, henter dataflowet hele bucket'en og erstatter dataene i destinationen. Hvis maksimumværdien ikke blev ændret, henter dataflowet ikke nogen data. Følgende afsnit indeholder en overordnet oversigt over, hvordan trinvis opdatering fungerer trinvist.
Første trin: Evaluer ændringerne
Når dataflowet kører, evalueres ændringerne i datakilden først. Den udfører denne evaluering ved at sammenligne den maksimale værdi i kolonnen DateTime med den maksimale værdi i den forrige opdatering. Hvis den maksimale værdi ændres, eller hvis det er den første opdatering, markerer dataflowet bucket'en som ændret og viser den til behandling. Hvis den maksimale værdi ikke blev ændret, springer dataflowet bucket'en over og behandler den ikke.
Andet trin: Hent dataene
Nu er dataflowet klar til at hente dataene. Den henter dataene for hver bucket, der er ændret. Dataflowet udfører denne hentning parallelt for at forbedre ydeevnen. Dataflowet henter dataene fra kildesystemet og indlæser dem i det midlertidige område. Dataflowet henter kun de data, der er inden for bucketområdet. Med andre ord henter dataflowet kun de data, der er ændret siden den seneste opdatering.
Sidste trin: Erstat dataene i datadestinationen
Dataflowet erstatter dataene i destinationen med de nye data. Dataflowet replace bruger metoden til at erstatte dataene i destinationen. Dataflowet sletter først dataene i destinationen for den pågældende bucket og indsætter derefter de nye data. Dataflowet påvirker ikke de data, der er uden for bucketområdet. Hvis du har data i destinationen, der er ældre end den første bucket, påvirker den trinvise opdatering derfor ikke disse data på nogen måde.
Forklaret indstillinger for trinvis opdatering
Hvis du vil konfigurere trinvis opdatering, skal du angive følgende indstillinger.
Generelle indstillinger
De generelle indstillinger er påkrævet, og angiv den grundlæggende konfiguration for trinvis opdatering.
Vælg en DateTime-kolonne, der skal filtreres efter
Denne indstilling er påkrævet og angiver den kolonne, som dataflow bruger til at filtrere dataene. Denne kolonne skal enten være en DateTime-, Date- eller DateTimeZone-kolonne. Dataflowet bruger denne kolonne til at filtrere dataene og henter kun de data, der er ændret siden den seneste opdatering.
Udtræk data fra fortiden
Denne indstilling er påkrævet og angiver, hvor langt tilbage i tiden dataflowet skal udtrække data. Denne indstilling bruges til at hente den indledende dataindlæsning. Dataflowet henter alle data fra kildesystemet, der er inden for det angivne tidsinterval. Mulige værdier er:
- x dage
- x uger
- x måneder
- x kvartaler
- x år
Hvis du f.eks. angiver 1 måned, henter dataflowet alle de nye data fra kildesystemet, der ligger inden for den sidste måned.
Bucketstørrelse
Denne indstilling er påkrævet og angiver størrelsen på de buckets, som dataflowet bruger til at filtrere dataene. Dataflowet opdeler dataene i buckets baseret på kolonnen DateTime. Hver bucket indeholder de data, der er ændret siden den seneste opdatering. Bucketstørrelsen bestemmer, hvor mange data der behandles i hver gentagelse. En mindre bucketstørrelse betyder, at dataflowet behandler færre data i hver gentagelse, men det betyder også, at der kræves flere gentagelser for at behandle alle dataene. En større bucketstørrelse betyder, at dataflowet behandler flere data i hver gentagelse, men det betyder også, at der kræves færre gentagelser for at behandle alle dataene.
Udtræk kun nye data, når den maksimale værdi i denne kolonne ændres
Denne indstilling er påkrævet og angiver den kolonne, som dataflowet bruger til at bestemme, om dataene er ændret. Dataflowet sammenligner den maksimale værdi i denne kolonne med den maksimale værdi i den forrige opdatering. Hvis den maksimale værdi ændres, henter dataflowet de data, der er ændret siden den seneste opdatering. Hvis maksimumværdien ikke ændres, henter dataflowet ingen data.
Udtræk kun data for afsluttede perioder
Denne indstilling er valgfri og angiver, om dataflowet kun skal udtrække data for afsluttede perioder. Hvis denne indstilling er aktiveret, udtrækker dataflowet kun data for perioder, der er afsluttet. Så dataflowet udtrækker kun data for perioder, der er fuldførte og ikke indeholder nogen fremtidige data. Hvis denne indstilling er deaktiveret, udtrækker data for alle perioder, herunder perioder, der ikke er fuldført og indeholder fremtidige data.
Hvis du f.eks. har en DateTime-kolonne, der indeholder datoen for transaktionen, og du kun vil opdatere hele måneder, kan du aktivere denne indstilling i kombinationer med bucketstørrelsen på month. Derfor udtrækker dataflowet kun data for hele måneder og udtrækker ikke data for ufuldstændige måneder.
Avancerede indstillinger
Nogle indstillinger anses for at være avancerede og er ikke påkrævet i de fleste scenarier.
Kræv trinvis opdateringsforespørgsel for at kunne foldes helt
Denne indstilling er valgfri og angiver, om den forespørgsel, der bruges til trinvis opdatering, skal foldes helt. Hvis denne indstilling er aktiveret, skal den forespørgsel, der bruges til trinvis opdatering, foldes helt. Med andre ord skal forespørgslen skubbes helt ned til kildesystemet. Hvis denne indstilling er deaktiveret, behøver den forespørgsel, der bruges til trinvis opdatering, ikke at folde helt. I dette tilfælde kan forespørgslen skubbes delvist ned til kildesystemet. Vi anbefaler på det kraftigste , at du aktiverer denne indstilling for at forbedre ydeevnen for at undgå at hente unødvendige og ufiltrerede data.
Begrænsninger
Kun SQL-baserede datadestinationer understøttes
I øjeblikket er det kun SQL-baserede datadestinationer, der understøttes til trinvis opdatering. Så du kan kun bruge Fabric Warehouse, Azure SQL Database eller Azure Synapse Analytics som en datadestination til trinvis opdatering. Årsagen til denne begrænsning er, at disse datadestinationer understøtter de SQL-baserede handlinger, der kræves til trinvis opdatering. Vi bruger handlingerne Delete og Insert til at erstatte dataene i datadestinationen, som ikke kan udføres parallelt på andre datadestinationer.
Datadestinationen skal angives til et fast skema
Datadestinationen skal angives til et fast skema, hvilket betyder, at skemaet for tabellen i datadestinationen skal være fast og ikke kan ændres. Hvis skemaet for tabellen i datadestinationen er angivet til dynamisk skema, skal du ændre det til et fast skema, før du konfigurerer trinvis opdatering.
Den eneste understøttede opdateringsmetode i datadestinationen er replace
Den eneste understøttede opdateringsmetode i datadestinationen er replace, hvilket betyder, at dataflowet erstatter dataene for hver bucket i datadestinationen med de nye data. Data, der ligger uden for bucketområdet, påvirkes dog ikke. Så hvis du har data i datadestinationen, der er ældre end den første bucket, påvirker den trinvise opdatering ikke disse data på nogen måde.
Det maksimale antal buckets er 50 for en enkelt forespørgsel og 150 for hele dataflowet
Det maksimale antal buckets pr. forespørgsel, som dataflowet understøtter, er 50. Hvis du har mere end 50 buckets, skal du øge bucketstørrelsen eller reducere bucketområdet for at reducere antallet af buckets. For hele dataflowet er det maksimale antal buckets 150. Hvis du har mere end 150 buckets i dataflowet, skal du reducere antallet af trinvise opdateringsforespørgsler eller øge bucketstørrelsen for at reducere antallet af buckets.
Forskelle mellem trinvis opdatering i Dataflow Gen1 og Dataflow Gen2
Mellem Dataflow Gen1 og Dataflow Gen2 er der nogle forskelle i, hvordan trinvis opdatering fungerer. På følgende liste forklares de primære forskelle mellem trinvis opdatering i Dataflow Gen1 og Dataflow Gen2.
- Trinvis opdatering er nu en førsteklasses funktion i Dataflow Gen2. I Dataflow Gen1 var du nødt til at konfigurere trinvis opdatering, efter du publicerede dataflowet. I Dataflow Gen2 er trinvis opdatering nu en førsteklasses funktion, som du kan konfigurere direkte i datafloweditoren. Denne funktion gør det nemmere at konfigurere trinvis opdatering og reducerer risikoen for fejl.
- I Dataflow Gen1 skulle du angive det historiske dataområde, da du konfigurerede trinvis opdatering. I Dataflow Gen2 behøver du ikke at angive det historiske dataområde. Dataflowet fjerner ikke nogen data fra destinationen, der er uden for bucketområdet. Hvis du har data i destinationen, der er ældre end den første bucket, påvirker den trinvise opdatering derfor ikke disse data på nogen måde.
- I Dataflow Gen1 skulle du angive parametrene for den trinvise opdatering, da du konfigurerede trinvis opdatering. I Dataflow Gen2 behøver du ikke at angive parametrene for den trinvise opdatering. Dataflowet tilføjer automatisk filtrene og parametrene som det sidste trin i forespørgslen. Så du behøver ikke at angive parametrene for den trinvise opdatering manuelt.
OFTE STILLEDE SPØRGSMÅL
Jeg modtog en advarsel om, at jeg brugte den samme kolonne til at registrere ændringer og filtrering. Hvad betyder dette?
Hvis du får vist en advarsel om, at du har brugt den samme kolonne til at registrere ændringer og filtrering, betyder det, at den kolonne, du har angivet til registrering af ændringer, også bruges til at filtrere dataene. Vi anbefaler ikke dette forbrug, da det kan føre til uventede resultater. Vi anbefaler i stedet, at du bruger en anden kolonne til at registrere ændringer og filtrere dataene. Hvis dataene skifter mellem buckets, kan dataflowet muligvis ikke registrere ændringerne korrekt og kan oprette duplikerede data i destinationen. Du kan løse denne advarsel ved at bruge en anden kolonne til at registrere ændringer og filtrere dataene. Eller du kan ignorere advarslen, hvis du er sikker på, at dataene ikke ændres mellem opdateringer for den kolonne, du har angivet.
Jeg vil bruge trinvis opdatering sammen med en datadestination, der ikke understøttes. Hvad kan jeg gøre?
Hvis du vil bruge trinvis opdatering sammen med en datadestination, der ikke understøttes, kan du aktivere trinvis opdatering af forespørgslen og bruge en anden forespørgsel, der refererer til de fasede data, til at opdatere datadestinationen. På denne måde kan du stadig bruge trinvis opdatering til at reducere mængden af data, der skal behandles og hentes fra kildesystemet, men du skal foretage en fuld opdatering fra de fasede data til datadestinationen. Sørg for, at du konfigurerer vinduets og bucketstørrelsen korrekt, da vi ikke garanterer, at dataene i den midlertidige placering bevares uden for bucketområdet.
Hvordan gør jeg vide, om trinvis opdatering er aktiveret i min forespørgsel?
Du kan se, om trinvis opdatering er aktiveret for din forespørgsel, ved at kontrollere ikonet ud for forespørgslen i datafloweditoren. Hvis ikonet indeholder en blå trekant, aktiveres trinvis opdatering. Hvis ikonet ikke indeholder en blå trekant, aktiveres trinvis opdatering ikke.
Min kilde får for mange anmodninger, når jeg bruger trinvis opdatering. Hvad kan jeg gøre?
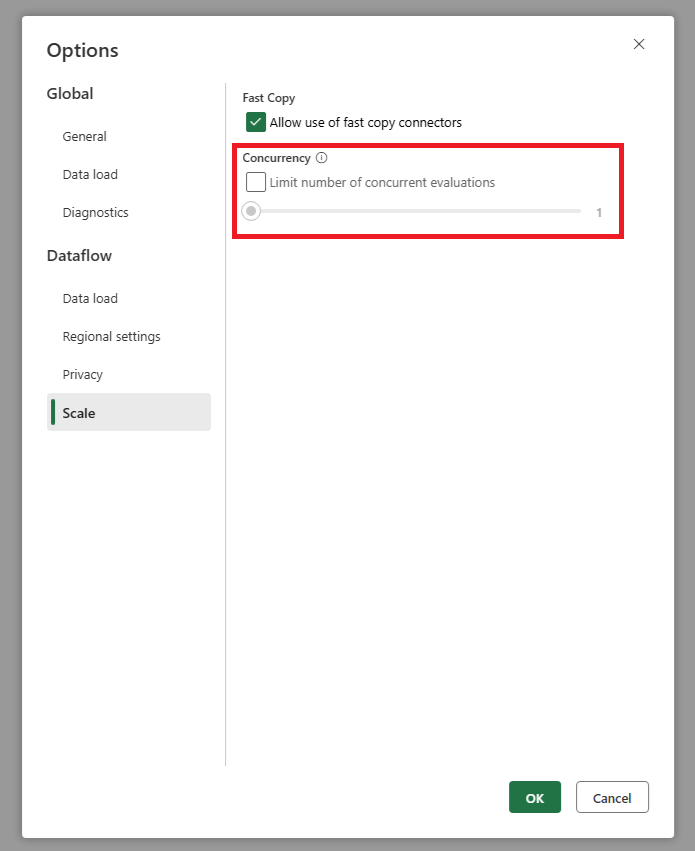
Vi har tilføjet en indstilling, der giver dig mulighed for at angive det maksimale antal parallelle forespørgselsevalueringer. Denne indstilling findes i de globale indstillinger for dataflowet. Hvis du angiver denne værdi til et lavere tal, kan du reducere antallet af anmodninger, der sendes til kildesystemet. Denne indstilling kan hjælpe med at reducere antallet af samtidige anmodninger og forbedre kildesystemets ydeevne. Hvis du vil angive det maksimale antal parallelle udførelser af forespørgsler, skal du gå til de globale indstillinger for dataflowet, navigere til fanen Skaler og angive det maksimale antal parallelle forespørgselsevalueringer. Vi anbefaler, at du ikke aktiverer denne grænse, medmindre du oplever problemer med kildesystemet.
Jeg vil bruge trinvis opdatering, men jeg kan se, at det tager længere tid at opdatere dataflowet efter aktiveringen. Hvad kan jeg gøre?
Trinvis opdatering, som beskrevet i denne artikel, er designet til at reducere mængden af data, der skal behandles og hentes fra kildesystemet. Men hvis det tager længere tid at opdatere dataflowet, når du har aktiveret trinvis opdatering, kan det skyldes, at den ekstra belastning ved at kontrollere, om data er ændret og behandlet i buckets, er højere end den tid, der er gemt ved at behandle færre data. I dette tilfælde anbefaler vi, at du gennemser indstillingerne for trinvis opdatering og justerer dem, så de passer bedre til dit scenarie. Du kan f.eks. øge bucketstørrelsen for at reducere antallet af buckets og omkostningerne ved at behandle dem. Du kan også reducere antallet af buckets ved at øge bucketstørrelsen. Hvis du stadig oplever lav ydeevne, når du har justeret indstillingerne, kan du deaktivere trinvis opdatering og bruge en fuld opdatering i stedet, da det kan være mere effektivt i dit scenarie.