Dataudvikler indstillinger for administration af arbejdsområder i Microsoft Fabric
Gælder for:✅ Dataudvikler ing og datavidenskab i Microsoft Fabric
Når du opretter et arbejdsområde i Microsoft Fabric, oprettes der automatisk en startpulje , der er knyttet til det pågældende arbejdsområde. Med den forenklede konfiguration i Microsoft Fabric er der ingen grund til at vælge node- eller maskinstørrelser, da disse indstillinger håndteres for dig i baggrunden. Denne konfiguration giver brugerne en hurtigere (5-10 sekunder) startoplevelse af Apache Spark-sessionen, så de kan komme i gang og køre dine Apache Spark-job i mange almindelige scenarier uden at skulle bekymre sig om at konfigurere beregningen. I forbindelse med avancerede scenarier med specifikke beregningskrav kan brugerne oprette en brugerdefineret Apache Spark-pulje og tilpasse nodernes størrelse på baggrund af deres ydeevnebehov.
Hvis du vil foretage ændringer af Apache Spark-indstillingerne i et arbejdsområde, skal du have administratorrollen for det pågældende arbejdsområde. Du kan få mere at vide under Roller i arbejdsområder.
Sådan administrerer du Spark-indstillingerne for den gruppe, der er knyttet til dit arbejdsområde:
Gå til indstillingerne for arbejdsområdet i arbejdsområdet, og vælg indstillingen Dataudvikler/Videnskab for at udvide menuen:
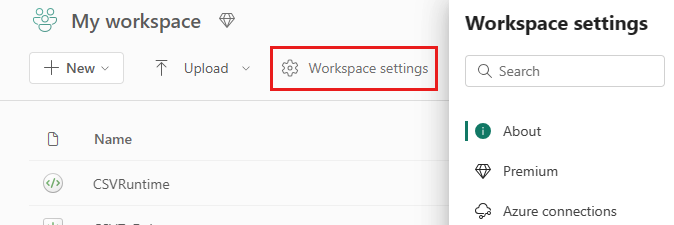
Du kan se indstillingen Spark Compute i menuen til venstre:
Bemærk
Hvis du ændrer standardpuljen fra Startpulje til en brugerdefineret Spark-gruppe, kan du se længere sessionstart (~3 minutter).

Pulje
Standardgruppe for arbejdsområdet
Du kan bruge den automatisk oprettede startpulje eller oprette brugerdefinerede puljer for arbejdsområdet.
Starter Pool: Prehydrerede live-puljer automatisk oprettet til din hurtigere oplevelse. Disse klynger er mellemstore. Startpuljen er indstillet til en standardkonfiguration baseret på den varenummer for Fabric-kapacitet, der er købt. Administratorer kan tilpasse de maksimale noder og eksekveringsprogrammer baseret på deres Krav til Spark-arbejdsbelastningsskala. Du kan få mere at vide under Konfigurer startpuljer
Brugerdefineret Spark-pulje: Du kan tilpasse størrelsen på noderne, autoskalere og tildele eksekveringsfiler dynamisk baseret på dine krav til Spark-job. Hvis du vil oprette en brugerdefineret Spark-gruppe, skal kapacitetsadministratoren aktivere indstillingen Brugerdefinerede arbejdsområdepuljer i afsnittet Spark Compute under Indstillinger for kapacitetsadministrator .
Bemærk
Kontrolelementet på kapacitetsniveau for brugerdefinerede arbejdsområdegrupper er aktiveret som standard. Du kan få mere at vide under Konfigurer og administrer indstillinger for datakonstruktion og datavidenskab for Fabric-kapaciteter.
Administratorer kan oprette brugerdefinerede Spark-puljer baseret på deres beregningskrav ved at vælge indstillingen Ny pulje .

Apache Spark til Microsoft Fabric understøtter enkeltnodeklynger, hvilket giver brugerne mulighed for at vælge en minimumnodekonfiguration på 1, i hvilket tilfælde driveren og eksekveren kører i en enkelt node. Disse klynger med en enkelt node tilbyder reaktiverbar høj tilgængelighed under nodefejl og bedre jobpålidelighed for arbejdsbelastninger med mindre beregningskrav. Du kan også aktivere eller deaktivere indstillingen automatisk skalering for dine brugerdefinerede Spark-puljer. Når indstillingen er aktiveret med automatisk skalering, henter gruppen nye noder inden for den maksimale nodegrænse, der er angivet af brugeren, og trækker dem tilbage efter udførelsen af jobbet for at opnå bedre ydeevne.
Du kan også vælge muligheden for dynamisk at tildele eksekveringsfiler til automatisk at gruppere det optimale antal eksekveringsfiler inden for den maksimale grænse, der er angivet, baseret på datamængden for at opnå en bedre ydeevne.

Få mere at vide om Apache Spark-beregning for Fabric.
- Tilpas beregningskonfigurationen for elementer: Som administrator af arbejdsområdet kan du give brugerne mulighed for at justere beregningskonfigurationer (egenskaber på sessionsniveau, som omfatter Driver/Executor Core, Driver/Executor Memory) for individuelle elementer, f.eks. notesbøger, Spark-jobdefinitioner ved hjælp af miljø.
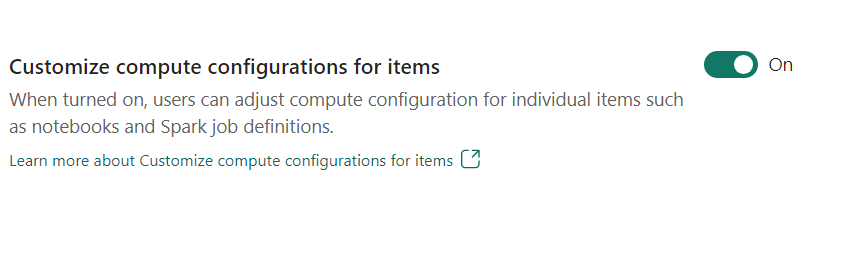
Hvis indstillingen er slået fra af arbejdsområdeadministratoren, bruges standardpuljen og dens beregningskonfigurationer for alle miljøer i arbejdsområdet.
Miljø
Miljø indeholder fleksible konfigurationer til kørsel af dine Spark-job (notesbøger, Spark-jobdefinitioner). I et miljø kan du konfigurere beregningsegenskaber ved at vælge forskellige afhængigheder af kørsel og konfiguration af bibliotekspakker baseret på dine krav til arbejdsbelastninger.
Under fanen Miljø har du mulighed for at angive standardmiljøet. Du kan vælge, hvilken version af Spark du vil bruge til arbejdsområdet.
Som administrator af Fabric-arbejdsområdet kan du vælge et miljø som standardmiljø for arbejdsområdet.
Du kan også oprette en ny via rullelisten Miljø .

Hvis du deaktiverer indstillingen for at have et standardmiljø, kan du vælge Fabric-kørselsversionen fra de tilgængelige kørselsversioner, der er angivet på rullelisten.

Få mere at vide om Apache Spark-kørsel.
Job
Jobindstillinger gør det muligt for administratorer at styre jobadgangslogikken for alle Spark-job i arbejdsområdet.

Alle arbejdsområder er som standard aktiveret med optimistisk jobindtagelse. Få mere at vide om jobindlæggelse for Spark i Microsoft Fabric.
Du kan aktivere reservens maksimale kerner for aktive Spark-job for at vende den optimistiske tilgang til jobindtagelse og reservere maks. kerner til deres Spark-job.
Du kan også angive timeout for Spark-sessionen for at tilpasse sessionens udløb for alle interaktive sessioner i notesbogen.
Bemærk
Standardsessionens udløb er angivet til 20 minutter for de interaktive Spark-sessioner.
Høj samtidighed
Tilstanden Med høj samtidighed giver brugerne mulighed for at dele de samme Spark-sessioner i Apache Spark til Fabric-datakonstruktion og datavidenskabsarbejdsbelastninger. Et element som en notesbog bruger en Spark-session til udførelse, og når det er aktiveret, kan brugerne dele en enkelt Spark-session på tværs af flere notesbøger.

Få mere at vide om Høj samtidighed i Apache Spark til Fabric.
Automatisk logføring af Modeller til maskinel indlæring og eksperimenter
Administratorer kan nu aktivere automatisklogging af deres modeller og eksperimenter til maskinel indlæring. Denne indstilling registrerer automatisk værdierne for inputparametre, outputmetrik og outputelementer for en model til maskinel indlæring, efterhånden som den oplæres. Få mere at vide om automatisk logning.

Relateret indhold
- Læs om Apache Spark Runtimes i Fabric – Oversigt, Versionering, Understøttelse af flere runtimes og opgradering af Delta Lake-protokollen.
- Få mere at vide i den offentlige dokumentation til Apache Spark.
- Få svar på ofte stillede spørgsmål: Ofte stillede spørgsmål om administrationsindstillinger for Apache Spark-arbejdsområder.