Fjerne dubletter i hver tabel i forbindelse med datasamling
Deduplikering finder og fjerner dublerede poster for en kunde fra en kildetabel, så hver kunde repræsenteres af en enkelt række i hver tabel. Hver tabel dubleres separat ved hjælp af regler til identifikation af posterne for en bestemt kunde.
Hver deduplikeringsregel køres mod hver række. Hvis din første regel matcher række 1 og 2, og regel 2 matcher række 2 og 3, matches række 1, 2 og 3. Når der findes matchede rækker, vælges en vinderrække, der repræsenterer den pågældende kunde baseret på Indstillinger for fletning (Mest udfyldte, Seneste eller Mindst seneste). Brug indstillingen Avanceret til at oprette en vinderrække ved at vælge felter fra de forskellige matchede rækker, såsom den seneste mail, men den mest udfyldte adresse.
Customer Insights - Data udfører automatisk følgende handlinger:
- Dedublerer poster med den samme primære nøgleværdi og vælger den første række i datasættet som vinder.
- Dedublerer poster ved hjælp af de matchningsregler, der er defineret for tabellen, når rækker mellem tabeller matches.
Definere deduplikeringsregler
En god regel identificerer en entydig kunde. Overvej dine data. Det kan være nok at identificere kunder baseret på et felt, f.eks. mail. Hvis du imidlertid vil skelne mellem kunder, der deler en mail, kan du vælge at have en regel med to betingelser, der matcher Email + FirstName. Du kan finde flere oplysninger i Bedste praksis for deduplikering.
Vælg en tabel på siden Regler for deduplikerede, og vælg Tilføj regel for at definere reglerne for deduplikering.
Tip
Hvis du har forbedret tabeller på datakildeniveau for at forbedre resultaterne af din samling, skal du vælge Brug forbedrede tabeller øverst på siden. Du kan finde flere oplysninger i Forbedring til datakilder.
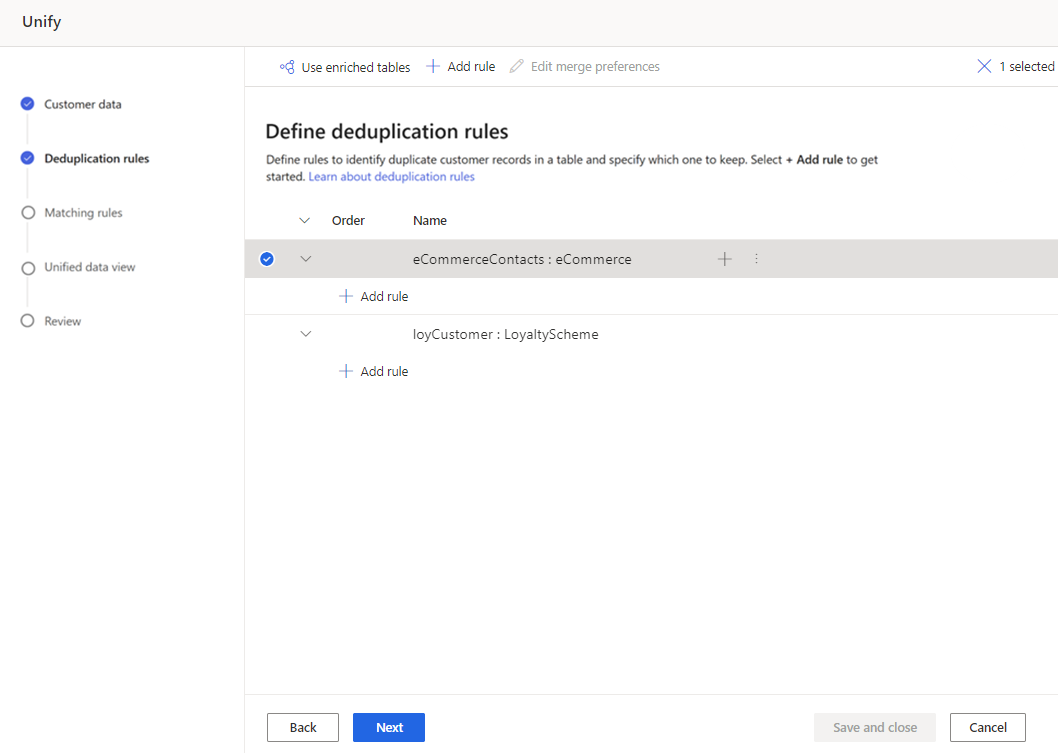
Angiv følgende oplysninger i ruden Tilføj regel:
Vælg felt: Vælg på listen over tilgængelige felter fra den tabel, du vil søge efter dubletter for. Vælg felter, der sandsynligvis er entydige for hver enkelt kunde. Det kan f.eks. være en mailadresse eller en kombination af navn, by og telefonnummer.
Normaliser: Vælg normaliseringsindstillinger for kolonnen. Normalisering påvirker kun det matchende trin og ændrer ikke dataene.
Normalisering Eksempler Tal Konverterer mange Unicode-symboler, der repræsenterer tal, til simple tal.
Eksempler: ❽ og Ⅷ er begge normaliseret til tallet 8.
Bemærk: Symbolerne skal være kodet i Unicode Point Format.Symboler Fjerner symboler og specialtegn.
Eksempler: !?"#$%&'( )+,.-/:;<=>@^~{}`[ ]Tekst til små bogstaver Konverterer tegn fra store til små bogstaver.
Eksempel: "DETTE Er eT EKSemPEL" konverteres til "dette er et eksempel"Type – Telefon Konverterer telefoner i forskellige formater til cifre og tager højde for variationer i, hvordan landekoder og lokalnumre præsenteres. Symboler og mellemrum ignoreres. Foranstillede 0-cifre i landekoder ignoreres, hvilket stemmer overens med +1 og +01. Udvidelser, der betegnes med et bogstavpræfiks, ignoreres (X 123). Den normaliserede landekode er vigtig, så en telefon med en landekode matcher ikke en telefon uden en landekode.
Eksempel: +01 425.555.1212 matcher 1 (425) 555-1212
+01 425.555.1212 matcher ikke (425) 555-1212Type - Navn Konverterer over 500 almindelige navnevariationer og titler.
Eksempler: "debby" -> "deborah" "prof" og "professor" -> "Prof."Type - Adresse Konverterer almindelige dele af adresser
Eksempler: "street" -> "st" og "northwest" -> "nw"Type - Organisation Fjerner omkring 50 firmanavnes "støjord" såsom "co", "corp", "corporation" og "ltd." Unicode til ASCII Konverterer Unicode-tegn til deres tilsvarende ASCII-tegn
Eksempel: Tegnene 'à,' 'á,' 'â,' 'À,' 'Á,' 'Â,' 'Ã,' 'Ä,' 'Ⓐ,' og 'A' konverteres alle til 'a.'Blanktegn Fjerner alle blanktegn Aliastilknytning Giver dig mulighed for at uploade en brugerdefineret liste over strengpar, som derefter kan bruges til at angive strenge, der altid bør betragtes som et nøjagtigt match.
Brug aliastilknytning, når du har specifikke dataeksempler, som du mener burde matche, og som ikke matches ved hjælp af et af de andre normaliseringsmønstre.
Eksempel: Scott og Scooter eller MSFT og Microsoft.Brugerdefineret tilsidesætter Giver dig mulighed for at uploade en brugerdefineret liste over strenge, som derefter kan bruges til at angive strenge, der aldrig bør matches.
Brugerdefineret tilsidesættelse er nyttig, når du har data med fælles værdier, der skal ignoreres, f.eks. et dummy-telefonnummer eller en dummy-mail.
Eksempel: Match aldrig telefonen 555-1212 eller test@contoso.com
Præcision: Angiv præcisionsniveauet. Præcision bruges til nøjagtig match og fuzzy matching og bestemmer, hvor tæt to strenge skal være for at blive betragtet som et match.
- Grundlæggende: Vælg mellem Lav (30 %), Mellem (60 %), Høj (80 %) og Nøjagtig (100 %). Vælg Nøjagtig, hvis du kun vil matche poster, der svarer til 100 procent.
- Brugerdefineret : Angiv en procentdel, som posterne skal matche. Systemet vil kun matche poster, der opfylder denne grænse.
Navn: Navn på reglen.
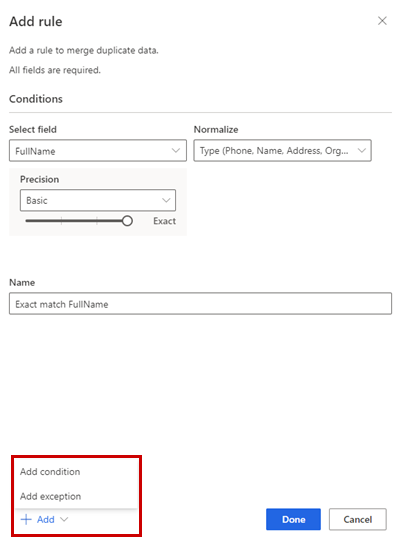
Du kan også vælge Tilføj>Tilføj betingelse for at føje flere betingelser til reglen. Betingelser er knyttet til en logisk AND-operator og køres derfor kun, hvis alle betingelser er opfyldt.
Det er også muligt at Tilføj>Tilføj undtagelse for at føje undtagelser til reglen. Undtagelser bruges til at adressere sjældne tilfælde af falsk positive og false negativer.
Vælg Udført for at oprette reglen.
Du kan også tilføje flere regler.

Vælg flettepræferencer
Når der køres regler, og der identificeres dublerede poster for en kunde, vælges en "vinderrække" baseret på fletningspolitikken. Vinderrækken repræsenterer kunden i det næste samlingstrin, der matcher poster mellem tabeller. Data i de ("alternative") rækker, der ikke vinder, bruges i samlingstrinnet Matchningsregler til at matche poster fra andre tabeller med vinderrækken. Denne fremgangsmåde forbedrer matchningsresultaterne ved at tillade, at oplysninger som tidligere telefonnumre kan hjælpe med at identificere matchende poster. Vinderrækken kan konfigureres til at være den mest udfyldte, seneste eller mindst seneste af de fundne dubletposter.
Vælg en tabel, og derefter Rediger indstillingerne for fletning. Ruden Flet præferencer vises.
Vælg en af tre indstillinger for at bestemme, hvilken post der skal bevares, hvis der findes en dublet:
- Flest udfyldte: Identificerer posten med de fleste udfyldte kolonner som vinderposten. Dette er standardfletteindstillingen.
- Nyeste: Identificerer vinderposten baseret på de nyeste. Kræver en dato eller et numerisk felt for at definere nyeste.
- Mindst nyeste: Identificerer vinderposten baseret på de mindst nyeste. Kræver en dato eller et numerisk felt for at definere nyeste.
Hvis det er umuligt, er vinderposten den post, der har værdien MAX(PK) eller den største primære nøgleværdi.
Du kan også definere indstillinger for fletning for individuelle kolonner for en tabel ved at vælge Avanceret nederst i ruden. Du kan f.eks. vælge at bevare den nyeste e-mail og den mest fuldstændige adresse fra forskellige poster. Udvid tabellen for at få vist alle dens kolonner, og definer, hvilken indstilling der skal bruges til de enkelte kolonner. Hvis du vælger en rekursbaseret indstilling, skal du også angive et dato/klokkeslætsfelt, der definerer rekursen.
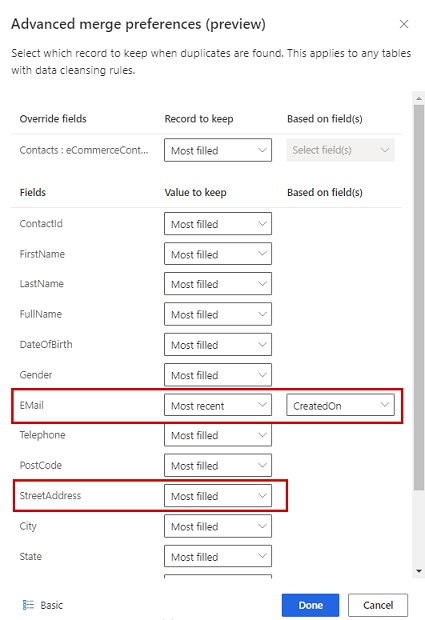
Vælg Fuldført for at anvende flettepræferencer.
Når du har defineret reglerne for duplikering og flettet indstillingerne, skal du vælge Næste.