Bedste praksis for samling af data
Når du konfigurerer regler for at samle dine data i en kundeprofil, skal du overveje disse bedste fremgangsmåder:
Balancere tid til samlet vs. komplet matching. Forsøg på at registrere alle mulige matchkundeemner for mange regler og samling tager lang tid.
Tilføj regler gradvist, og spor resultaterne. Fjern regler, der ikke forbedrer matchresultatet.
Dedupliker de enkelte tabeller, så alle kunder er repræsenteret i en enkelt række.
Brug normalisering til at standardisere variationer for, hvordan data blev indtastet, f.eks. Gade vs. Gd vs. Gd. vs. gd.
Brug fuzzymatchning strategisk til at rette stavefejl og andre fejl, f.eks. bob@contoso.com og bob@contoso.cm. Det tager længere tid at køre fuzzymatchning end nøjagtig matchning. Test altid for at se, om den ekstra tid, der bruges på fuzzymatchning, er den ekstra matchrate værd.
Begræns omfanget af matches med nøjagtigt match. Sørg for, at alle regler med uklare betingelser har mindst én nøjagtig matchbetingelse.
Match ikke kolonner, der indeholder meget gentagne data. Kontrollér, at kolonner, der er fuzzymatchet, ikke har værdier, der gentages ofte, f.eks. standardværdien "Firstname" i en formular.
Samlingsydeevne
Det tager tid at køre hver regel. Mønstre, f.eks. sammenligning af alle tabeller med alle andre tabeller eller forsøg på at registrere alle mulige postmatches, kan føre til lange behandlingstider for samling. Det returnerer også nogle få, hvis der er flere matches med en plan, der sammenligner de enkelte tabeller med en basistabel.
Den bedste fremgangsmåde er at starte med et grundlæggende sæt regler, som du ved er nødvendige, f.eks. sammenligning af hver tabel med din primære tabel. Din primære tabel skal være den tabel, der har de mest komplette og nøjagtige data. Denne tabel skal arrangeres øverst i samlingstrinnet for matchingregler.
Tilføj gradvist flere regler, og se, hvor lang tid det tager at køre ændringerne, og om dine resultater forbedres. Gå til Indstillinger>System>Status, og vælg Match for at se, hvor lang tid deduplikering og matchning tog for hver samlingskørsel.
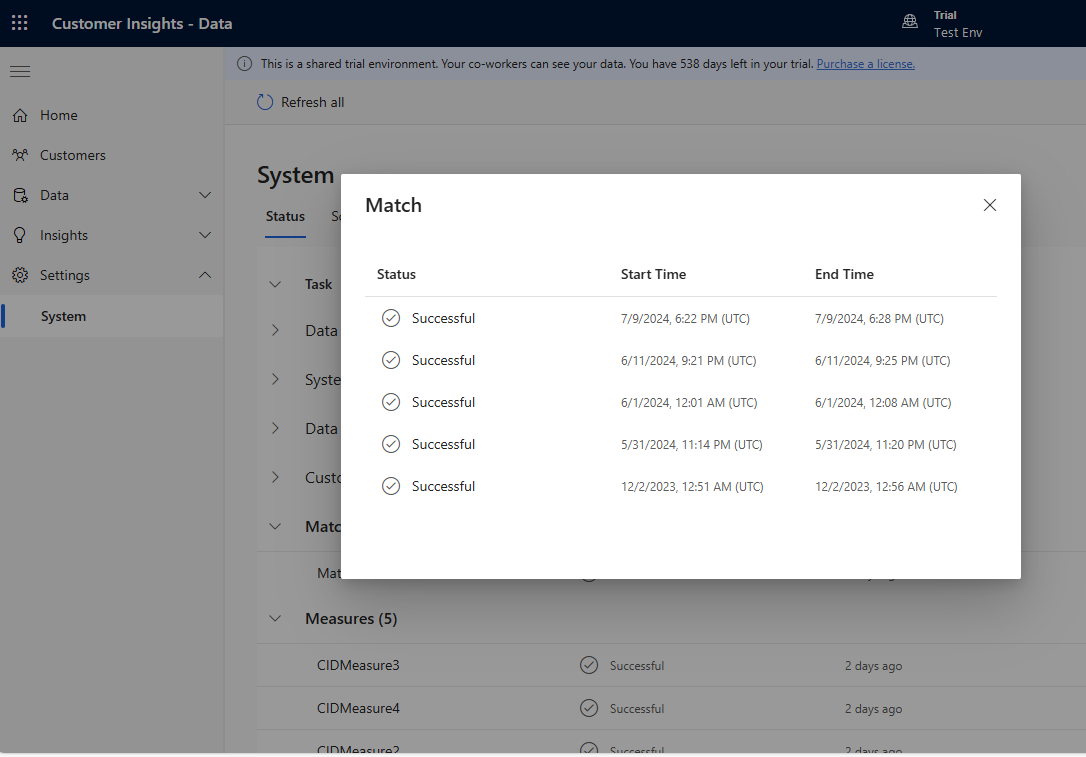
Få vist regelstatistikken på siderne Deduplikeringsregler og Matchningsregler for at se, om antallet af entydige poster ændres. Hvis en ny regel matcher nogle poster, og det entydige postantal ikke ændres, identificerer en tidligere regel disse matches.
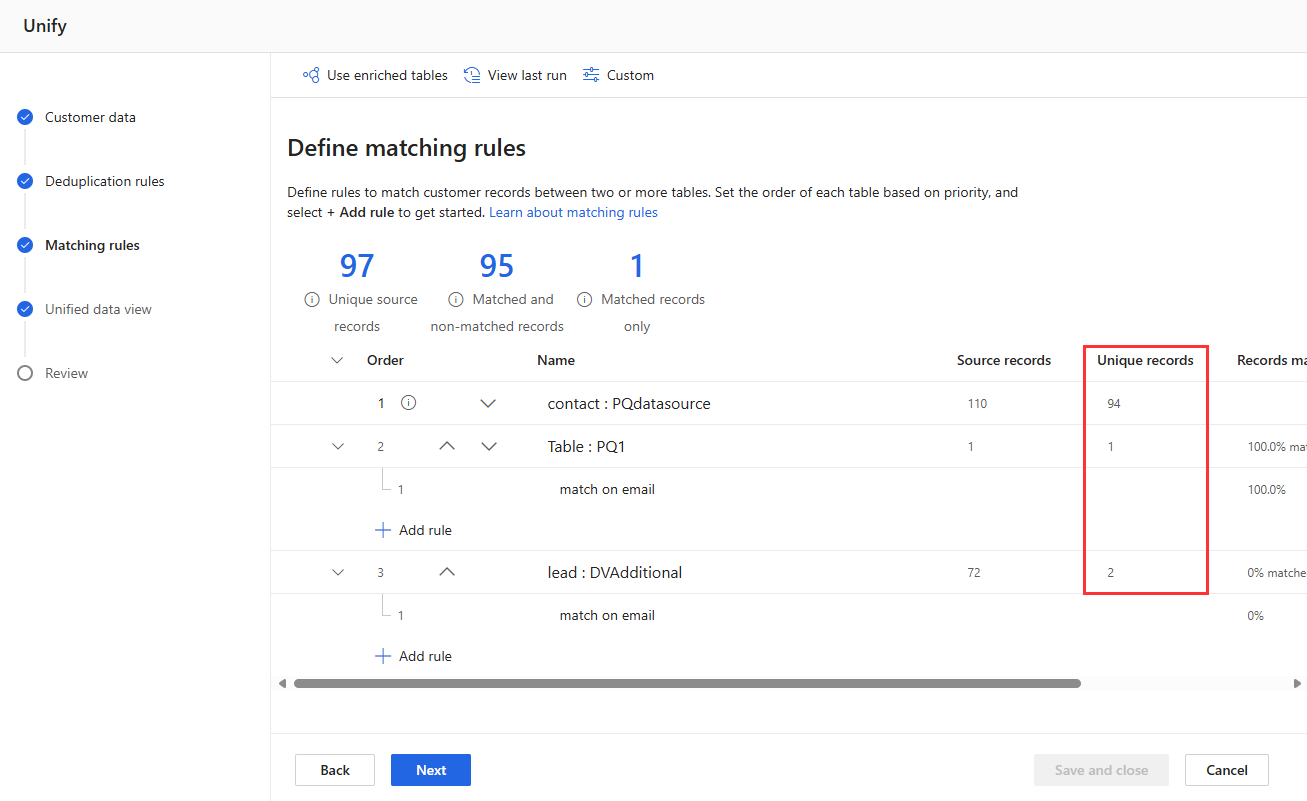
Kundedata
I trinnet Kundedata:
Udelad kolonner, der ikke skal bruges til matchning af regler, eller som du ikke vil have inkluderet i den endelige kundeprofil.
Gennemse kolonnebeskrivelser, der er valgt af intelligent tilknytning.
Det er ikke alle kolonner, der skal tilknyttes. Ved at tilknytte almindelige kolonner, f.eks. mail- og adressefelter, kan Customer Insights gøre downstreamprocesser nemmere, men kolonner med et entydigt id eller formål for din virksomhed kan forblive uden tilknytning.
Deduplikering
Brug deduplikeringsregler til at fjerne dublerede kundeposter i en tabel, så en enkelt række i hver tabel repræsenterer hver kunde. En god regel identificerer en entydig kunde.
I dette simple eksempel deler post 1, 2 og 3 enten en mail eller et telefonnummer og repræsenterer den samme person.
| Id | Navn | Telefonnummer | |
|---|---|---|---|
| 1 | Person 1 | (425) 555-1111 | AAA@A.com |
| 2 | Person 1 | (425) 555-1111 | BBB@B.com |
| 3 | Person 1 | (425) 555-2222 | BBB@B.com |
| 4 | Person 2 | (206) 555-9999 | Person2@contoso.com |
Vi ønsker ikke kun at matche navnet, da det stemmer overens med forskellige personer med det samme navn.
Opret regel 1 ved hjælp af Navn og Telefon, der matcher posterne 1 og 2.
Opret regel 2 ved hjælp af Navn og Mail, der matcher posterne 2 og 3.
Ved kombination af regel 1 og regel 2 oprettes der en enkelt matchgruppe, fordi de deler post 2.
Du bestemmer antallet af regler og betingelser, der entydigt identificerer dine kunder. De nøjagtige regler afhænger af de data, du har til rådighed, kvaliteten af dine data, og hvor udtømmende du ønsker, at deduplikeringsprocessen skal være.
Normalisering
Brug normalisering til at standardisere data for bedre matchning. Normalisering fungerer godt på store datasæt.
De normaliserede data bruges kun til sammenligningsformål for at matche kundeposter mere effektivt. Dataene ændres ikke i det endelige output af en samlet kundeprofil.
Nøjagtigt match
Brug præcision til at bestemme, hvor tæt to strenge skal være for at blive betragtet som et match. Standardpræcisionsindstillingen kræver et nøjagtigt match. Alle andre værdier aktiverer fuzzymatchning for den pågældende betingelse.
Præcision kan indstilles til lav (30 % match), medlem (60 % match) og høj (80 % match). Eller du kan tilpasse og indstille præcisionen i trin på 1 %.
Nøjagtige matchbetingelser
De nøjagtige matchbetingelser køres først for at få et mindre sæt værdier for fuzzymatches. For at være effektive bør de nøjagtige matchningsbetingelser have en rimelig grad af entydighed. Hvis alle dine kunder f.eks. bor i samme land/område, vil et nøjagtigt match for landet/området ikke hjælpe med at indsnævre omfanget.
Kolonner som fulde navn, mail, telefon eller adressefelter har god entydighed og er egnet til at bruge som et nøjagtigt match.
Kontrollér, at den kolonne, du bruger til en betingelse med nøjagtigt match, ikke indeholder værdier, der gentages ofte, f.eks. standardværdien "Fornavn", der registreres af en formular. Customer Insights kan profilere datakolonner for at give indsigt i de mest gentagne værdier. Du kan aktivere dataprofilering på Azure Data Lake-forbindelser (ved hjælp af Common Data Model eller Delta-format) og Synapse. Dataprofilen køres, næste gang datakilden opdateres. Du kan finde flere oplysninger under Dataprofilering.
Fuzzymatchning
Brug fuzzymatchning til at matche strenge, der er tætte, men ikke er nøjagtige på grund af slåfejl eller andre små variationer. Brug fuzzymatchning strategisk, da det er langsommere end nøjagtige matches. Kontrollér, at der er mindst én betingelse for nøjagtigt matchning i alle regler, der har betingelser for fuzzymatchning.
Fuzzymatchning er ikke beregnet til at fange navnevariationer som Suzzie og Suzanne. Disse variationer registreres bedre med normaliseringsmønsteret Type: Navn eller den brugerdefinerede aliasmatchning, hvor kunderne kan angive deres liste over de navnevariationer, de vil betragte som matches.
Du kan føje betingelser til en regel, f.eks. matchende fornavn og telefon. Betingelser inden for en given regel er "OG"-betingelser. Alle betingelser skal stemme overens, for at rækkerne stemmer overens. Separate regler er "ELLER"-betingelser. Hvis regel 1 ikke stemmer overens med rækkerne, sammenlignes rækkerne med regel 2.
Bemærk
Kun strengdatatypekolonner kan bruge fuzzymatchning. For kolonner med andre datatyper, f.eks. heltal, dobbelt eller datetime, er præcisionsfeltet skrivebeskyttet og angivet til det nøjagtige match.
Beregninger af fuzzymatchning
Fuzzymatches bestemmes ved at beregne redigeringsafstandsscoren mellem to strenge. Hvis scoren når eller overstiger præcisionstærsklen, betragtes strengene som et match.
Redigeringsafstanden er det antal redigeringer, der kræves for at omdanne en streng til en anden ved at tilføje, slette eller ændre et tegn.
For eksempel har strengene "robert2020@hotmail.com" og "robrt2020@hotmail.cm" en redigeringsafstand på to, når vi fjerner e- og o-tegnene. Hvis du vil beregne redigeringsafstandsscore, skal du bruge denne formel: (Grundlæggende strenglængde - Redigeringsafstand)/Grundlæggende strenglængde.
| Basisstreng | Sammenligningsstreng | Score |
|---|---|---|
| robert2020@hotmail.com | robrt2020@hotmail.cm | (20 - 2)/20 = 0,9 |