Datové typy v Power BI Desktopu
Tento článek popisuje datové typy, které Power BI Desktop a DAX (Data Analysis Expressions) podporují.
Když Power BI načte data, pokusí se převést datové typy zdrojových sloupců na datové typy, které podporují efektivnější úložiště, výpočty a vizualizaci dat. Pokud například sloupec hodnot importovaných z Excelu neobsahuje žádné desetinné hodnoty, Power BI Desktop převede datový sloupec na Celé číslo datový typ, který je vhodnější pro ukládání celých čísel.
Tento koncept je důležitý, protože některé funkce DAX mají speciální požadavky na datový typ. V mnoha případech DAX implicitně převádí datové typy, ale v některých případech tak nečiní. Pokud například funkce DAX vyžaduje datový typ Datum, ale datový typ pro sloupec je Text, funkce DAX nebude fungovat správně. Proto je důležité a užitečné použít pro sloupce správné datové typy.
Určení a určení datového typu sloupce
V Power BI Desktopu můžete určit a zadat datový typ sloupce v Editoru Power Query, v zobrazení tabulky nebo v zobrazení sestavy:
V Editoru Power Query vyberte sloupec, pak na pásu karet ve skupině Transform vyberte typ dat.
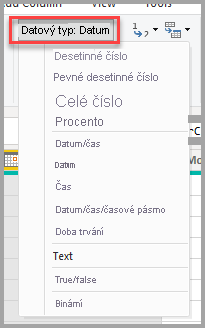
V zobrazení tabulky nebo v zobrazení sestavy vyberte sloupec a pak vyberte šipku rozevíracího seznamu vedle Datový typ na kartě nástrojů Sloupců na pásu karet.
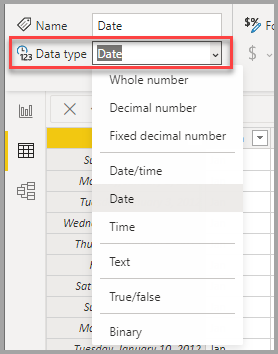
Výběr rozevíracího seznamu Datový typ v Editoru Power Query obsahuje dva datové typy, které nejsou k dispozici v zobrazení tabulky nebo v zobrazení sestavy: datum a čas/ časové pásmo a doba trvání. Když načtete sloupec s těmito datovými typy do modelu Power BI, sloupec Datum/Čas/Časová zóna se převede na datový typ Datum a čas a sloupec Trvání se převede na datový typ Desetinné číslo.
Datový typ Binary není podporovaný mimo Editor Power Query. V Editoru Power Query můžete použít datový typ Binary při načítání binárních souborů, pokud ho před načtením do modelu Power BI převedete na jiné datové typy. Binární výběr existuje v nabídkách zobrazení tabulky a zobrazení sestav ze starších důvodů, ale pokud se pokusíte načíst binární sloupce do modelu Power BI, může docházet k chybám.
Číselné typy
Power BI Desktop podporuje tři typy čísel: desetinné číslo, pevné desetinné čísloa celé číslo.
K určení výčtů DataType pro číselné typy můžete použít vlastnost sloupce v Tabulkovém Objektovém Modelu (TOM) DataType. Další informace o programové úpravě objektů v Power BI najdete v tématu Programování sémantických modelů Power BI pomocí tabulkového objektového modelu.
Desetinné číslo
desetinné číslo je nejběžnější typ čísla a dokáže zpracovat čísla s desetinnými hodnotami a celými čísly. Desetinné číslo typu představuje 64bitová (osmibajtová) čísla s plovoucí desetinnou čárkou se zápornými hodnotami od -1,79E +308 až do -2,23E -308, kladnými hodnotami od 2,23E -308 až do 1,79E +308, a hodnotou 0. Čísla jako 34, 34,01a 34,000367063 jsou platná desetinná čísla.
Nejvyšší přesnost, kterou typ desetinné číslo může představovat, je 15 čísel. Oddělovač desetinných míst může nastat kdekoli v čísle. Tento typ odpovídá tomu, jak Excel ukládá čísla, přičemž TOM specifikuje tento typ jako DataType.Double Enum.
Pevné desetinné číslo
Datový typ Pevné desetinné číslo má pevné umístění desetinné čárky. Oddělovač desetinných míst má vždy čtyři číslice vpravo a umožňuje až 19 významných číslic. Největší hodnota, kterou pevné desetinné číslo může představovat, je kladná nebo záporná 922 337 203 685 477,5807.
Typ Pevné desetinné číslo je užitečný v případech, kdy může zaokrouhlování zavádět chyby. Čísla s malými zlomkovými částmi se mohou někdy nahromadit a způsobit, že číslo je lehce nepřesné. Typ Pevné desetinné číslo vám pomůže vyhnout se těmto druhům chyb zkrácením hodnot za čtyři číslice napravo od oddělovače desetinných míst.
Tento datový typ odpovídá datovému typu desetinné (19,4)v SQL Serveru nebo datovému typu Měna v Analysis Services a Power Pivotu v Excelu. TOM specifikuje tento typ jako výčet DataType.Decimal.
Celé číslo
celá celočíselná hodnota představuje 64bitovou (osmibajtovou) celočíselnou hodnotu. Protože se jedná o celé číslo, Celé číslo nemá číslice napravo od desetinné čárky. Tento typ umožňuje 19 číslic kladných nebo záporných celých čísel mezi -9 223 372 036 854 775 807 (-2^63+1) a 9 223 372 036 854 775 806 (2^63-2), takže může představovat největší možný počet číselných datových typů.
Stejně jako u typu Pevný desetinný může být typ Celé číslo užitečný, když potřebujete ovládat zaokrouhlování. TOM představuje datový typ Celé číslo jako DataType.Int64 Enum.
Poznámka
Datový model Power BI Desktopu podporuje 64bitové celočíselné hodnoty, ale vzhledem k omezením JavaScriptu je největší číslo, které mohou vizuály Power BI bezpečně zobrazit, 9 007 199 254 740 991 (2^53-1). Pokud datový model obsahuje větší čísla, můžete jejich velikost před přidáním do vizuálů zmenšit pomocí výpočtů.
Přesnost výpočtů typu čísel
Hodnoty sloupců datového typu Desetinné číslo se ukládají jako přibližné datové typy podle standardu IEEE 754 pro čísla s pohyblivou řádovou čárkou. Přibližné datové typy mají vlastní omezení přesnosti, protože místo ukládání přesných číselných hodnot mohou ukládat extrémně blízko nebo zaokrouhlené aproximace.
Pokud hodnota s plovoucí desetinnou čárkou nedokáže spolehlivě kvantifikovat počet číslic s plovoucí desetinnou čárkou, může dojít ke ztrátě přesnosti nebo nepřesné. Nepřesnost se může projevit jako neočekávané nebo nepřesné výsledky výpočtů v některých reportovacích scénářích.
Výpočty porovnání, které se týkají rovnosti mezi hodnotami typu datového Desetinné číslo, mohou potenciálně vrátit neočekávané výsledky. Porovnání rovnosti zahrnuje rovná se =, větší než >, menší než <, větší než nebo rovno >=a menší než nebo rovno <=.
Tento problém je nejvýraznější, když použijete funkci RANKX ve výrazu DAX, který vypočítá výsledek dvakrát, což vede k mírně odlišným číslům. Uživatelé sestavy si nemusí všimnout rozdílu mezi dvěma čísly, ale výsledek pořadí může být výrazně nepřesný. Chcete-li zabránit neočekávaným výsledkům, můžete změnit datový typ sloupce z Desetinné číslo na Pevné desetinné číslo nebo Celé číslonebo provést vynucené zaokrouhlení pomocí ROUND. Datový typ pevného desetinného čísla má větší přesnost, protože desetinný separátor má vždy čtyři číslice napravo od něj.
Vzácně mohou výpočty, které sčítají hodnoty sloupce datového typu Desetinné číslo, vrátit neočekávané výsledky. Tento výsledek je s největší pravděpodobností u sloupců, které mají velké objemy kladných i záporných čísel. Výsledek součtu je ovlivněn rozdělením hodnot mezi řádky ve sloupci.
Pokud požadovaný výpočet sčítá většinu kladných čísel před součtem většiny záporných čísel, může velký kladný částečný součet na začátku potenciálně zkosit výsledky. Pokud se při výpočtu přidají vyvážená kladná a záporná čísla, dotaz zachová větší přesnost, a proto vrátí přesnější výsledky. Chcete-li zabránit neočekávaným výsledkům, můžete změnit datový typ sloupce z desetinné číslo na pevné desetinné číslo nebo celé číslo.
Typy data a času
Power BI Desktop podporuje pět datových typů datum a čas v Editoru Power Query.
Datum/Čas/Časové pásmo a Délka trvání se během načítání převádějí do datového modelu Power BI Desktopu. Model podporuje
Datum a čas představuje zároveň hodnotu data a času. Podkladová hodnota data a času je uložena jako desetinné číslo typu, takže můžete převést mezi těmito dvěma typy. Časová část se ukládá jako zlomek na celé násobky 1/300 sekund (3,33 ms). Datový typ podporuje data mezi roky 1900 a 9999.
date představuje pouze datum bez časového úseku. Datum se v modelu převede jako hodnota Datum/Čas s nulou pro desetinnou hodnotu.
Čas představuje pouze časovou hodnotu bez datové části. Čas se převede do modelu jako hodnota Datum/Čas s nulovými číslicemi nalevo od desetinné čárky.
Datum/Čas/Časové pásmo představuje datum a čas v UTC s časovým posunem pásma a při načtení do modelu se převede na Datum/Čas. Model Power BI neupravuje časové pásmo na základě umístění nebo národního prostředí uživatele. Hodnota 09:00 načtená do modelu v USA se zobrazí jako 09:00 všude, kde je sestava otevřena nebo zobrazena.
Doba trvání představuje dobu trvání a při načtení do modelu se převede na Desetinné číslo typu. Jako desetinné číslo typ můžete sčítat nebo odečítat hodnoty z hodnoty datum a čas se správnými výsledky a snadno použít hodnoty ve vizualizacích, které ukazují velikost.
Typ textu
Datový typ Text je datový řetězec znaku Unicode, který může být písmena, číslice nebo kalendářní data reprezentovaná v textovém formátu. Praktický maximální limit délky řetězce je přibližně 32 000 znaků Unicode na základě podkladového modulu Power Query v Power BI a jeho omezení pro text délkách datového typu. Datové typy textu nad rámec praktického maximálního limitu pravděpodobně způsobí chyby.
Způsob, jakým Power BI ukládá textová data, může způsobit, že se data v určitých situacích budou zobrazovat odlišně. Další části popisují běžné situace, které můžou způsobit, že textová data změní vzhled mírně mezi dotazováním dat v Editoru Power Query a jejich načtením do Power BI.
Citlivost malých a velkých písmen
Modul, který ukládá a dotazuje data v Power BI, je případově necitlivýa zachází s různými variantami velkých písmen jako se stejnou hodnotou. "A" se rovná "a". Power Query se ale rozlišují malá a velká písmena, kde "A" není totéž jako "a". Rozdíl v rozlišování velkých a malých písmen může vést k situacím, kdy se textová data po načtení do Power BI zdánlivě nevysvětlitelně změní ve velká písmena.
Následující příklad ukazuje data objednávky: sloupec OrderNo, který je jedinečný pro každou objednávku, a sloupec Adresát, který zobrazuje jméno adresáta zadané ručně v době objednávky. V Editoru Power Query se zobrazuje několik objednávek se stejnými jmény adresátů zadanými do systému s různým použitím velkých písmen.
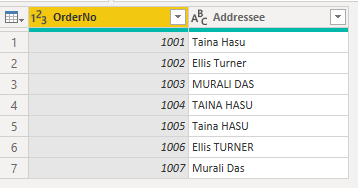
Po načtení dat v Power BI se kapitalizace duplicitních názvů na kartě Data změní z původního zápisu na jednu z možností kapitalizace.
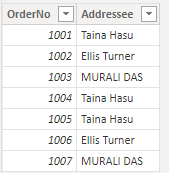
K této změně dochází, protože Editor Power Query rozlišují malá a velká písmena, takže zobrazuje data přesně tak, jak jsou uložená ve zdrojovém systému. Modul, který ukládá data v Power BI, nerozlišuje malá a velká písmena, takže zachází s malými a velkými písmeny znaku jako shodné. Data Power Query načtená do modulu Power BI se můžou odpovídajícím způsobem měnit.
Modul Power BI vyhodnocuje každý řádek jednotlivě při načítání dat počínaje shora. Pro každý textový sloupec, jako je například Adresát, systém ukládá slovník jedinečných hodnot, aby prostřednictvím komprese dat zlepšil výkon. Modul uvidí první tři hodnoty ve sloupci Adresát jako jedinečné a uloží je do slovníku. Proto, že modul nerozlišuje velká a malá písmena, vyhodnotí názvy jako identické.
Stroj vidí název "Taina Hasu" jako totožný s "TAINA HASU" a "Taina HASU", takže tyto varianty neukládá, ale odkazuje na první uloženou variantu. Název "MURALI DAS" se zobrazí velkými písmeny, protože se název zobrazil při prvním vyhodnocení modulu při načítání dat shora dolů.
Tento obrázek znázorňuje proces vyhodnocení:

V předchozím příkladu modul Power BI načte první řádek dat, vytvoří adresáta slovník a přidá do něj Taina Has u. Modul také přidá odkaz na danou hodnotu ve sloupci Adresát v tabulce, kterou načte. Modul dělá totéž pro druhý a třetí řádek, protože tyto názvy nejsou ekvivalentní ostatním, když ignorujete malá a velká písmena.
Pro čtvrtý řádek modul porovná hodnotu s názvy ve slovníku a najde název. Vzhledem k tomu, že motor nerozlišuje malá a velká písmena, "TAINA HASU" a "Taina Hasu" jsou stejné. Modul nepřidá do slovníku nový název, ale odkazuje na existující název. Stejný proces probíhá u zbývajících řádků.
Poznámka
Vzhledem k tomu, že modul, který ukládá a dotazuje data v Power BI, nerozlišuje velká a malá písmena, je třeba při práci v režimu DirectQuery se zdrojem, který rozlišuje velikost písmen, věnovat zvláštní pozornost. Power BI předpokládá, že zdroj odstranil duplicitní řádky. Vzhledem k tomu, že Power BI nerozlišuje malá a velká písmena, považuje dvě hodnoty, které se liší pouze velikostí písmen, za duplicitní, zatímco zdroj je nemusí považovat za takové. V takových případech není konečný výsledek definován.
Chcete-li se této situaci vyhnout, pokud používáte režim DirectQuery se zdrojem dat citlivým na malá a velká písmena, normalizujte velikost písmen ve zdrojovém dotazu nebo v Editoru Power Query.
Úvodní a koncové mezery
Power BI automaticky ořízne všechny koncové mezery, které následují textová data, ale neodstraní počáteční mezery před daty. Abyste se vyhnuli nejasnostem, měli byste při práci s daty, která obsahují úvodní nebo koncové mezery, použít funkci Text.Trim k odebrání mezer na začátku nebo konci textu. Pokud úvodní mezery neodeberete, relace se nemusí podařit vytvořit kvůli duplicitním hodnotám nebo vizuály můžou vrátit neočekávané výsledky.
Následující příklad ukazuje data o zákaznících: sloupec Název, který obsahuje jméno zákazníka a sloupec Index, který je pro každou položku jedinečný. Názvy se zobrazí v uvozovkách, aby bylo jasné. Jméno zákazníka se opakuje čtyřikrát, ale pokaždé s různými kombinacemi úvodních a koncových mezer. K těmto variantám může dojít při ručním zadávání dat v průběhu času.
| Řada | Úvodní mezera | Koncové mezery | Jméno | Index | Délka textu |
|---|---|---|---|---|---|
| 1 | Ne | Ne | "Dylan Williams" | 1 | 14 |
| 2 | Ne | Ano | "Dylan Williams " | 10 | 15 |
| 3 | Ano | Ne | "Dylan Williams" | 20 | 15 |
| 4 | Ano | Ano | " Dylan Williams " | 40 | 16 |
V Editoru Power Query se výsledná data zobrazí následujícím způsobem.
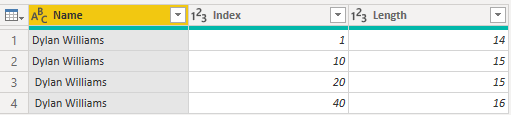
Když po načtení dat přejdete na kartu Tabulka v Power BI, bude stejná tabulka vypadat jako na následujícím obrázku se stejným počtem řádků jako předtím.
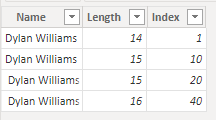
Vizuál založený na těchto datech ale vrátí jenom dva řádky.

Na předchozím obrázku má první řádek celkovou hodnotu 60 pro pole Index, takže první řádek ve vizuálu představuje poslední dva řádky načtených dat. Druhý řádek s celkovou hodnotou indexu 11 představuje první dva řádky. Rozdíl v počtu řádků mezi vizualizací a datovou tabulkou je způsoben tím, že stroj automaticky odstraňuje nebo ořezává koncové mezery, ale nikoli počáteční mezery. Modul proto vyhodnotí první a druhý řádek a třetí a čtvrtý řádek jako stejný a vizuál vrátí tyto výsledky.
Toto chování může také způsobit chybové zprávy související s relacemi, protože jsou zjištěny duplicitní hodnoty. Například v závislosti na konfiguraci relací se může zobrazit chyba podobná následujícímu obrázku:

V jiných situacích nemusíte být schopni vytvořit relaci mnoho ku jedné nebo jedna ku jedné, protože byly zjištěny duplicitní hodnoty.
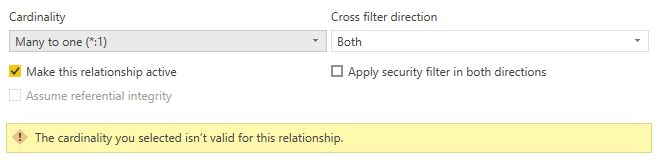
Tyto chyby můžete sledovat zpět na úvodní nebo koncové mezery a vyřešit je pomocí Text.Trimnebo Format>Trim v části Transform, abyste odstranili mezery v Editoru Power Query.
Pravda/nepravda typ
Datový typ True/false je logická hodnota true nebo false. Pro dosažení nejlepších a nejkonzistentnějších výsledků při načítání sloupce s informacemi o logické hodnotě true/false do Power BI nastavte typ sloupce na True/False.
Power BI v určitých situacích převádí a zobrazuje data odlišně. Tato část popisuje běžné případy převodu logických hodnot a způsob, jak řešit převody, které v Power BI vytvářejí neočekávané výsledky.
V tomto příkladu načtete data o tom, jestli se vaši zákazníci zaregistrovali k vašemu bulletinu. Hodnota TRUE označuje, že se zákazník zaregistroval k bulletinu, a hodnota FALSE znamená, že se zákazník nezaregistroval.
Při publikování sestavy do služby Power BI se ve sloupci stavu registrace zpravodaje zobrazí 0 a -1 místo očekávaných hodnot TRUE nebo FALSE. Následující kroky popisují, jak k tomuto převodu dochází a jak tomu zabránit.
Zjednodušený dotaz pro tuto tabulku se zobrazí na následujícím obrázku:
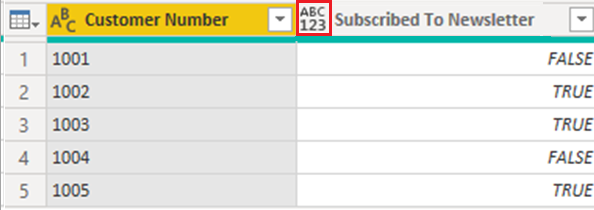
Datový typ sloupce Přihlášení k odběru bulletinu je nastaven na Libovolnýa v důsledku toho Power BI načte data do modelu jako Text.
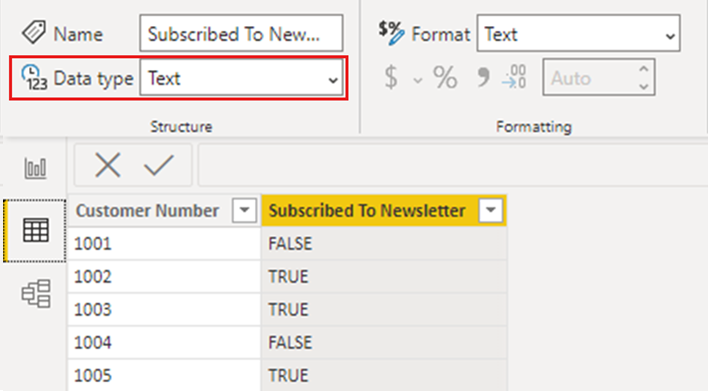
Když přidáte jednoduchou vizualizaci, která zobrazuje podrobné informace pro jednotlivé zákazníky, zobrazí se data ve vizuálu podle očekávání, a to jak v Power BI Desktopu, tak při publikování do služby Power BI.
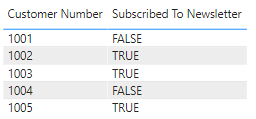
Když ale aktualizujete sémantický model ve službě Power BI, sloupec Přihlášení k odběru bulletinu ve vizuálech zobrazí hodnoty jako -1 a 0, místo aby je zobrazoval jako TRUE nebo FALSE:

Pokud sestavu znovu publikujete z Power BI Desktopu, znovu se ve sloupci Přihlásit k odběru bulletinu zobrazí TRUE nebo FALSE podle očekávání, ale po aktualizaci ve službě Power BI se hodnoty znovu změní tak, aby zobrazovaly -1 a 0.
Řešením této situace je nastavit libovolné Boolean sloupce na typ True/False v Power BI Desktop a znovu publikovat sestavu.
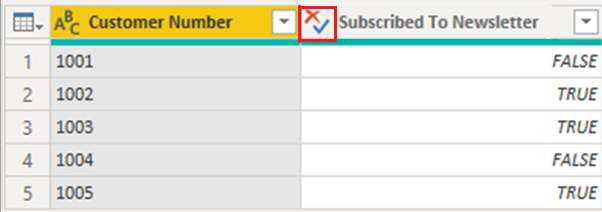
Když provedete změnu, vizualizace zobrazí hodnoty ve sloupci Přihlášení k odběru bulletinu trochu jinak. Namísto toho, aby byl text, jak bylo zadáno v tabulce, celý psaný velkými písmeny, je pouze první písmeno velké. Tato změna je jedním z výsledků změny datového typu sloupce.
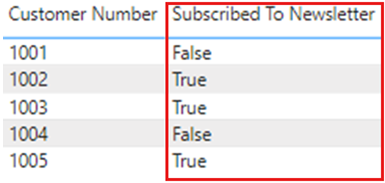
Jakmile změníte datový typ, opakovaně publikujte do služby Power BI a poté dojde k aktualizaci, sestava zobrazí hodnoty jako True nebo False, podle očekávání.

Pokud chcete shrnout, při práci s logickými daty v Power BI se ujistěte, že jsou sloupce nastavené na datový typ True/False v Power BI Desktopu.
Prázdný typ
Prázdný je datový typ DAX, který představuje a nahrazuje hodnoty null SQL. Prázdnou hodnotu můžete vytvořit pomocí funkce BLANK a otestovat prázdné hodnoty pomocí logické funkce ISBLANK.
Binární typ
Datový typ Binary můžete použít k reprezentaci dat s binárním formátem. V Editoru Power Query můžete tento datový typ použít při načítání binárních souborů, pokud ho před načtením do modelu Power BI převedete na jiné datové typy.
Binární sloupce nejsou v datovém modelu Power BI podporované. Binární výběr existuje v nabídkách zobrazení tabulky a zobrazení sestav z historických důvodů, ale pokud se pokusíte načíst binární sloupce do modelu Power BI, můžete narazit na chyby.
Poznámka
Pokud je binární sloupec ve výstupu kroků dotazu, může pokus o aktualizaci dat prostřednictvím brány způsobit chyby. Jako poslední krok v dotazech doporučujeme explicitně odebrat všechny binární sloupce.
Typ tabulky
Jazyk DAX používá datový typ tabulka v mnoha funkcích, jako jsou agregace a výpočty časové inteligence. Některé funkce vyžadují odkaz na tabulku. Jiné funkce vrátí tabulku, kterou pak můžete použít jako vstup do jiných funkcí.
V některých funkcích, které jako vstup vyžadují tabulku, můžete zadat výraz, který se vyhodnotí jako tabulka. Některé funkce vyžadují odkaz na základní tabulku. Informace o požadavcích konkrétních funkcí najdete v referenční příručce funkcí DAX .
Implicitní a explicitní převod datového typu
Každá funkce DAX má specifické požadavky na typy dat, které se mají použít jako vstupy a výstupy. Některé funkce například vyžadují celá čísla pro některé argumenty a kalendářní data pro jiné. Jiné funkce vyžadují text nebo tabulky.
Pokud jsou data ve sloupci, který zadáte jako argument, nekompatibilní s datovým typem, který funkce vyžaduje, může jazyk DAX vrátit chybu. Kdykoli je to ale možné, daX se pokusí implicitně převést data na požadovaný datový typ.
Například:
- Pokud zadáte datum jako řetězec, jazyk DAX řetězec analyzuje a pokusí se ho přetypovat jako jeden z formátů data a času systému Windows.
- Můžete přidat TRUE + 1 a získat výsledek 2, protože DAX implicitně převede PRAVDA na číslo 1a provede operaci 1+1.
- Pokud přidáte hodnoty do dvou sloupců s jednou hodnotou reprezentovanou jako text ("12") a druhou jako číslo (12), jazyk DAX implicitně převede řetězec na číslo a pak provede sčítání číselného výsledku. Výraz = "22" + 22 vrátí 44.
- Pokud se pokusíte zřetězit dvě čísla, DAX je nejprve převede na řetězce a poté je zřetězí. Výraz = 12 & 34 vrátí "1234".
Tabulky implicitních převodů dat
Operace určuje typ konverze, kterou DAX provádí, převedením požadovaných hodnot před provedením dané operace. Následující tabulky uvádějí operátory a konverzi, kterou DAX provádí na každý datový typ při jeho párování s datovým typem v průsečíku buněk.
Poznámka
Tyto tabulky neobsahují datový typ Text. Pokud je číslo reprezentováno v textovém formátu, v některých případech se Power BI pokusí určit typ čísla a představuje data jako číslo.
Sčítání (+)
| CELÉ ČÍSLO | MĚNA | SKUTEČNÝ | Datum a čas | |
|---|---|---|---|---|
| CELÉ ČÍSLO | CELÉ ČÍSLO | MĚNA | REÁLNÝ | Datum a čas |
| MĚNA | MĚNA | MĚNA | SKUTEČNÝ | Datum a čas |
| REAL | SKUTEČNÝ | SKUTEČNÝ | SKUTEČNÝ | Datum a čas |
| Datum/čas | Datum a čas | Datum a čas | Datum a čas | Datum a čas |
Pokud například operace sčítání používá reálné číslo v kombinaci s daty měny, DAX převede obě hodnoty na „REAL“ a vrátí výsledek jako „REAL“.
Odčítání (-)
V následující tabulce je minuend (levá strana) záhlavím řádku a subtrahend (pravá strana) záhlavím sloupce.
| CELÉ ČÍSLO | MĚNA | REÁLNÝ | Datum a čas | |
|---|---|---|---|---|
| CELOČÍSELNÉ | CELÉ ČÍSLO | MĚNA | REÁLNÝ | SKUTEČNÝ |
| MĚNA | MĚNA | MĚNA | SKUTEČNÝ | REÁLNÝ |
| REAL | SKUTEČNÝ | SKUTEČNÝ | SKUTEČNÝ | REÁLNÝ |
| Datum/čas | Datum a čas | Datum a čas | Datum a čas | Datum a čas |
Pokud například operace odčítání používá datum s jakýmkoli jiným datovým typem, jazyk DAX převede obě hodnoty na data, a vrácená hodnota je také datum.
Poznámka
Datové modely podporují unární operátor – (záporné), ale tento operátor nemění datový typ operandu.
Násobení (*)
| CELÉ ČÍSLO | MĚNA | REÁLNÝ | Datum a čas | |
|---|---|---|---|---|
| CELOČÍSELNÉ | CELÉ ČÍSLO | MĚNA | SKUTEČNÝ | CELÉ ČÍSLO |
| MĚNA | MĚNA | SKUTEČNÝ | MĚNA | MĚNA |
| REAL | SKUTEČNÝ | MĚNA | SKUTEČNÝ | REÁLNÝ |
Pokud například operace násobení kombinuje celé číslo se skutečným číslem, jazyk DAX převede obě čísla na reálná čísla a vrácená hodnota je také REAL.
Dělení (/)
V následující tabulce je záhlaví řádku čitatelem a záhlaví sloupce je jmenovatelem.
| CELÉ ČÍSLO | MĚNA | SKUTEČNÝ | Datum a čas | |
|---|---|---|---|---|
| CELOČÍSELNÉ | SKUTEČNÝ | MĚNA | SKUTEČNÝ | SKUTEČNÝ |
| MĚNA | MĚNA | SKUTEČNÝ | MĚNA | REÁLNÝ |
| REAL | SKUTEČNÝ | REÁLNÝ | REÁLNÝ | REÁLNÝ |
| Datum/čas | REÁLNÝ | SKUTEČNÝ | SKUTEČNÝ | SKUTEČNÝ |
Pokud například operace dělení kombinuje celé číslo s hodnotou měny, jazyk DAX převede obě hodnoty na reálná čísla a výsledek je také reálné číslo.
Porovnávací operátory
Ve srovnávacích výrazech DAX považuje logické hodnoty za větší než hodnoty řetězcové, a řetězcové hodnoty za větší než hodnoty číselné nebo datumové/časové. Čísla a hodnoty data a času mají stejné pořadí.
DAX neprovádí žádné implicitní převody booleovských nebo řetězcových hodnot. HODNOTA BLANK nebo prázdná hodnota se převede na 0, ""nebo Falsev závislosti na datovém typu druhé porovnávané hodnoty.
Toto chování ilustrují následující výrazy jazyka DAX:
=IF(FALSE()>"true","Expression is true", "Expression is false")vrátí "Výraz je pravdivý".=IF("12">12,"Expression is true", "Expression is false")vrátí "Výraz je pravdivý".=IF("12"=12,"Expression is true", "Expression is false")vrátí výraz "Výraz je nepravdivý".
DAX provádí implicitní převody číselných nebo typů datum/čas, jak je uvedeno v následující tabulce.
| Porovnání Operátor |
CELÉ ČÍSLO | MĚNA | SKUTEČNÝ | Datum a čas |
|---|---|---|---|---|
| CELÉ ČÍSLO | CELÉ ČÍSLO | MĚNA | SKUTEČNÝ | SKUTEČNÝ |
| MĚNA | MĚNA | MĚNA | REÁLNÝ | SKUTEČNÝ |
| SKUTEČNÝ | SKUTEČNÝ | REÁLNÝ | SKUTEČNÝ | SKUTEČNÝ |
| Datum/čas | REÁLNÝ | REÁLNÝ | SKUTEČNÝ | Datum a čas |
Prázdné hodnoty, prázdné řetězce a nulové hodnoty
DAX představuje hodnotu null, prázdnou hodnotu, prázdnou buňku nebo chybějící hodnotu pomocí nového typu hodnoty nazývaného BLANK. Prázdné hodnoty můžete také vygenerovat pomocí funkce BLANK nebo otestovat prázdné hodnoty pomocí funkce ISBLANK.
Způsob, jakým operace, jako je sčítání nebo zřetězení, pracují s prázdnými hodnotami, závisí na jednotlivých funkcích. Následující tabulka shrnuje rozdíly mezi tím, jak vzorce DAX a Microsoft Excel zpracovávají prázdné hodnoty.
| Výraz | DAX | Excel |
|---|---|---|
| BLANK + BLANK | BIANKO | 0 (nula) |
| BLANK +5 | 5 | 5 |
| BLANK * 5 | BIANKO | 0 (nula) |
| 5/BLANK | Nekonečno | Chyba |
| 0/BLANK | NaN | Chyba |
| BLANK/BLANK | BIANKO | Chyba |
| NEPRAVDA NEBO PRÁZDNÉ | NEPRAVDA | NEPRAVDA |
| NEPRAVDIVÉ A PRÁZDNÉ | NEPRAVDA | FALEŠNÝ |
| PRAVDA NEBO PRÁZDNO | PRAVDIVÝ | PRAVDIVÝ |
| PRAVDA A PRÁZDNÉ | NEPRAVDA | PRAVDIVÝ |
| PRÁZDNÉ NEBO NĚCO JINÉHO | BIANKO | Chyba |
| PRÁZDNÉ A PRÁZDNÉ | BIANKO | Chyba |
Související obsah
S Power BI Desktopem a daty můžete dělat nejrůznější věci. Další informace o možnostech Power BI najdete v následujících zdrojích informací: