Použití nasazení a konfigurace schopnosti obohacení nestrukturovaných klinických poznámek (preview) v řešeních pro zdravotní data
[Tento článek představuje předběžnou dokumentaci a může se změnit.]
Poznámka:
Tento obsah je v současné době aktualizován.
Rozšiřování nestrukturovaných klinických poznámek (Preview) používá službu Text Analytics for health řešení Azure AI Jazyk k extrahování entit Fast Healthcare Interoperability Resources (FHIR) z nestrukturovaných klinických poznámek. Z těchto klinických poznámek vytváří strukturovaná data. Strukturovaná data pak můžete analyzovat, abyste odvodili přehledy, předpovědi a měřítka kvality zaměřená na zlepšení zdravotních výsledků pacientů.
Další informace o této funkci a pochopení toho, jak ji nasadit a nakonfigurovat, najdete tady:
- Přehled nasazení obohacení nestrukturovaných klinických poznámek (preview)
- Nasazení a konfigurace schopnosti obohacení nestrukturovaných klinických poznámek (preview)
Rozšiřování nestrukturovaných klinických poznámek (Preview) má přímou závislost na schopnosti základů dat zdravotní péče. Nejprve se ujistěte, že jste úspěšně nastavili a spustili kanály Základů zdravotních dat.
Předpoklady
- Nasazení datových řešení Healthcare ve službě Microsoft Fabric
- Nainstalujte základní poznámkové bloky a kanály v Nasazení zdravotnických datových základů.
- Nastavte službu jazyka Azure, jak je vysvětleno v tématu Nastavení služby jazyka Azure.
- Nasazení a konfigurace schopnosti obohacení nestrukturovaných klinických poznámek (preview)
- Nasazení a konfigurace transformací OMOP. Tento krok je nepovinný.
Služba příjmu dat NLP
Poznámkový blok healthcare#_msft_ta4h_silver_ingestion spouští modul NLPIngestionService v knihovně Řešení pro zdravotní data a používá službu Text Analytics for health. Tato služba extrahuje nestrukturované klinické poznámky z prostředku FHIR DocumentReference.Content a vytvoří zploštělý výstup. Další informace najdete v tématu Kontrola konfigurace poznámkového bloku.
Úložiště dat ve stříbrné vrstvě
Po analýze rozhraní API zpracování přirozeného jazyka (NLP) se strukturovaný a zploštělý výstup uloží do následujících nativních tabulek v transakčním jezeře healthcare#_msft_silver:
- nlpentity: Obsahuje zploštělé entity extrahované z nestrukturovaných klinických poznámek. Každý řádek je jeden výraz extrahovaný z nestrukturovaného textu po provedení analýzy textu.
- nlprelationship: Poskytuje vztah mezi extrahovanými entitami.
- nlpfhir: Obsahuje výstupní sadu FHIR jako řetězec JSON.
Ke sledování posledního aktualizovaného časového razítka NLPIngestionService používá pole parent_meta_lastUpdated ve všech třech tabulkách stříbrného transakčního jezera. Toto sledování zajišťuje, že zdrojový dokument DocumentReference, což je nadřazený prostředek, je nejprve uložen, aby se zachovala referenční integrita. Tento proces pomáhá zabránit nekonzistenci v datech a osamocených prostředcích.
Důležité
Text Analytics for Health v současné době vrací slovníky uvedené v dokumentaci ke slovníku UMLS Metathesaurus. Pokyny k těmto slovníkům najdete v tématu Import dat z UMLS.
Pro verzi Preview používáme terminologii SNOMED-CT (Systematizovaná nomenklatura medicíny – klinické termíny), LOINC (logické identifikátory pozorování, názvy a kódy) a RxNorm, které jsou součástí ukázkové datové sady OMOP na základě pokynů z Observational Health Data Sciences and Informatics (OHDSI).
Transformace OMOP
Řešení zdravotnických dat v Microsoft Fabric také poskytují další schopnost pro transformaci Observational Medical Outcomes Partnership (OMOP). Když tuto funkci spustíte, podkladová transformace ze stříbrného transakčního jezera na zlaté jezero OMOP také transformuje strukturovaný a zploštělý výstup analýzy nestrukturovaných klinických poznámek. Transformace čte z tabulky nlpentity ve stříbrném transakčním jezeře a mapuje výstup na tabulku NOTE_NLP ve zlatém transakčním jezeře OMOP.
Další informace najdete v článku Přehled transformací OMOP.
Tady je schéma pro strukturované výstupy NLP s odpovídajícím mapováním sloupce NOTE_NLP na Common Data Model OMOP:
| Odkaz na zploštělý dokument | Popis | Mapování Note_NLP | Vzorkování dat |
|---|---|---|---|
| id | Jedinečný identifikátor entity. Složený klíč parent_id, offset a length. |
note_nlp_id |
1380 |
| parent_id | Cizí klíč ke zploštělému textu documentreferencecontent, ze kterého byl termín extrahován. | note_id |
625 |
| text | Text entity, jak je uveden v dokumentu. | lexical_variant |
Nejsou známy žádné alergie |
| Odsazení | Posun znaků extrahovaného výrazu ve vstupním textu documentreferencecontent. | offset |
294 |
| data_source_entity_id | ID entity v daném zdrojovém katalogu. | note_nlp_concept_id a note_nlp_source_concept_id |
37396387 |
| nlp_last_executed | Datum zpracování analýzy textu documentreferencecontent. | nlp_date_time a nlp_date |
2023-05-17T00:00:00.0000000 |
| model | Název a verze systému NLP (název systému NLP Text Analytics for Health a verze). | nlp_system |
MSFT TA4H |

Omezení služby pro Text Analytics for Health
- Maximální počet znaků v dokumentu je omezen na 125 000.
- Maximální velikost dokumentů obsažených v celém požadavku je omezena na 1 MB.
- Maximální počet dokumentu na požadavek je omezen na:
- 25 pro webové rozhraní API.
- 1000 pro kontejner.
Povolit protokoly
Pokud chcete povolit protokolování požadavků a odpovědí pro rozhraní API Text Analytics for Health, postupujte takto:
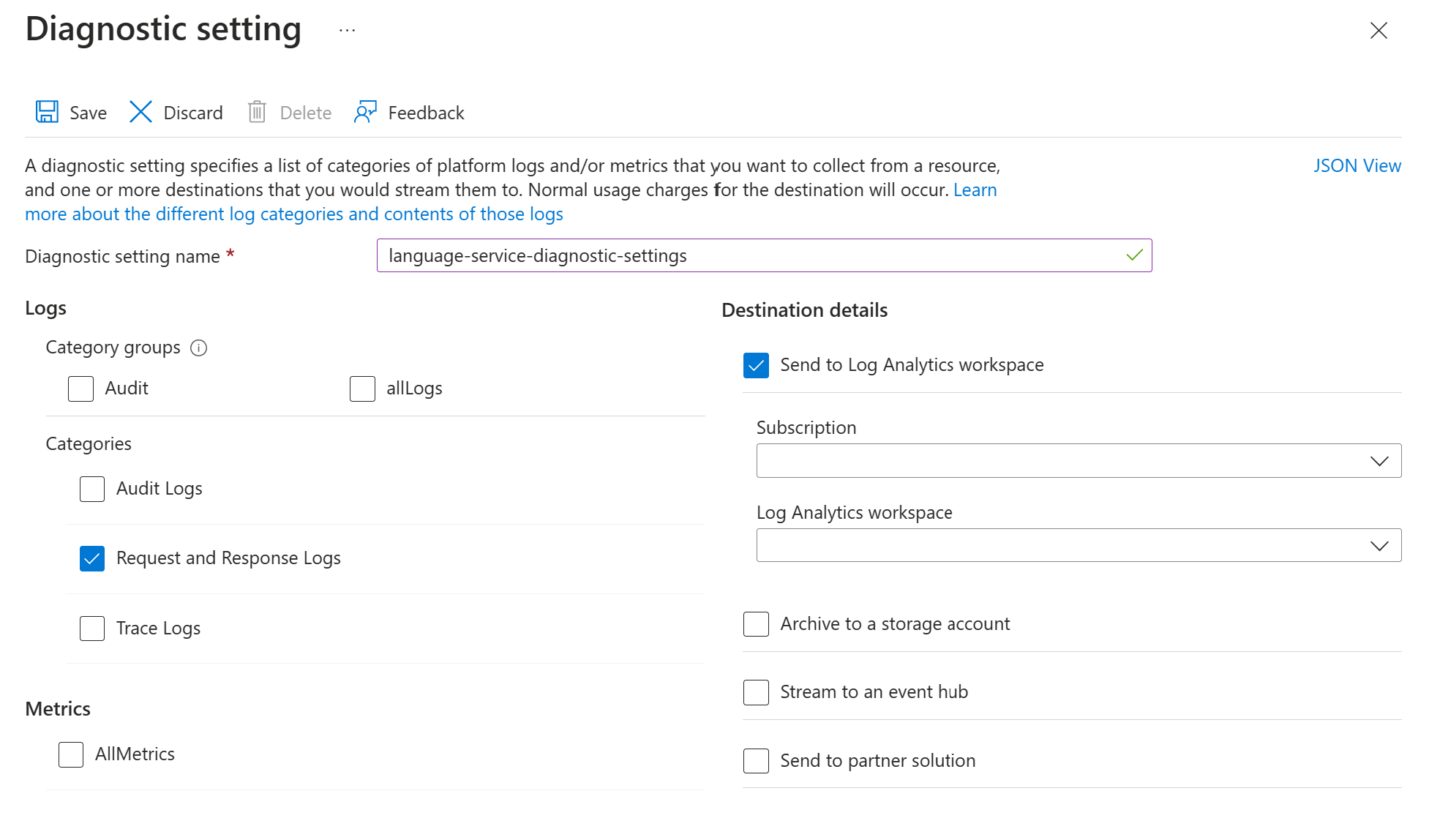
Povolte nastavení diagnostiky pro prostředek služby jazyka Azure podle pokynů v tématu Povolení protokolování diagnostiky pro služby Azure AI. Tento prostředek je stejná jazyková služba, kterou jste vytvořili během kroku nasazení Nastavit službu Azure Jazyk.
- Zadejte název nastavení diagnostiky.
- Nastavte kategorii na Protokoly požadavků a odpovědí.
- Pokud chcete zobrazit podrobnosti o cíli, vyberte Odeslat do pracovního prostoru Log Analytics a vyberte požadovaný pracovní prostor služby Log Analytics. Pokud pracovní prostor nemáte, vytvořte ho podle pokynů.
- Uložte nastavení.
V poznámkovém bloku služby pro příjem dat NLP přejděte do části Konfigurace NLP. Aktualizujte hodnotu parametru konfigurace
enable_text_analytics_logsnaTrue. Další informace o tomto poznámkovém bloku uvádí článek Kontrola konfigurace poznámkového bloku.

Zobrazení protokolů v Azure Log Analytics
Prozkoumání dat analytiky protokolů:
- Přejděte do pracovního prostoru Log Analytics.
- Vyhledejte a vyberte Protokoly. Na této stránce můžete spouštět dotazy na protokoly.
Ukázkový dotaz
Následuje základní dotaz Kusto, který můžete použít k prozkoumání dat protokolu. Tento ukázkový dotaz načte všechny neúspěšné požadavky od Azure poskytovatele prostředků Azure Cognitive Services za poslední den, seskupené podle typu chyby:
AzureDiagnostics
| where TimeGenerated > ago(1d)
| where Category == "RequestResponse"
| where ResourceProvider == "MICROSOFT.COGNITIVESERVICES"
| where tostring(ResultSignature) startswith "4" or tostring(ResultSignature) startswith "5"
| summarize NumberOfFailedRequests = count() by ResultSignature