Odstraňování problémů s řešením pro zdravotní data v Microsoft Fabric
Tento článek obsahuje informace o některých problémech nebo chybách, se kterými se můžete setkat při používání datových řešení pro zdravotnictví v Microsoft Fabric a jak je vyřešit. Tento článek obsahuje také některé pokyny k monitorování aplikací.
Pokud váš problém přetrvává i po provedení pokynů v tomto článku, vytvořte lístek incidentu pro tým podpory.
Řešení problémů s nasazením
Někdy se můžete setkat s občasnými problémy při nasazování řešení pro zdravotní data do pracovního prostoru prostředků infrastruktury. Zde jsou některé běžně pozorované problémy a alternativní řešení k jejich odstranění:
Vytvoření řešení se nezdaří nebo trvá příliš dlouho.
Chyba: Vytváření řešení zdravotní péče probíhá déle než 5 minut a/nebo se nezdaří.
Příčina: K této chybě dochází, pokud existuje jiné řešení zdravotní péče, které má stejný název nebo bylo nedávno odstraněno.
Řešení: Pokud jste nedávno odstranili řešení, počkejte 30 až 60 minut, než se pokusíte o další nasazení.
Nasazení schopnosti selhává.
Chyba: Funkce v rámci Řešení pro zdravotní data se nedaří nasadit.
Řešení: Ověřte, jestli je funkce uvedená v části Správa nasazených schopností.
- Pokud tato funkce není uvedená v tabulce, zkuste ji nasadit znovu. Vyberte dlaždici schopností a potom vyberte tlačítko Nasadit do pracovního prostoru.
- Pokud je funkce uvedená v tabulce s hodnotou stavu Nasazení se nezdařilo, nasaďte ji znovu. Případně můžete vytvořit nové prostředí datových řešení pro zdravotnictví a znovu tam tuto funkci nasadit.
Řešení potíží s neidentifikovanými tabulkami
Při prvním vytvoření rozdílových tabulek v lakehouse se můžou v zobrazení Průzkumníka transakčního jezera dočasně zobrazit jako "neidentifikované" nebo prázdné. Po několika minutách by se však měly správně zobrazit ve složce tables.

Opětovné spuštění kanálu dat
Pokud chcete znovu spustit komplexní ukázková data, postupujte takto:
Spuštěním příkazu Spark SQL z poznámkového bloku odstraňte všechny tabulky z transakčního jezera. Tady je příklad:
lakehouse_name = "<lakehouse_name>" tables = spark.sql(f"SHOW TABLES IN {lakehouse_name}") for row in tables.collect(): spark.sql(f"DROP TABLE {lakehouse_name}.{row[1]}")Pomocí Průzkumníka souborů OneLake se připojte k OneLake v Průzkumníku souborů Windows.
Přejděte do složky pracovního prostoru v Průzkumníku souborů Windows. V části
<solution_name>.HealthDataManager\DMHCheckpointodstraňte všechny odpovídající složky v<lakehouse_id>/<table_name>. Alternativně můžete k odstranění složky použít také Microsoft Spark Utilities (MSSparkUtils) for Fabric.Znovu spusťte datové kanály, počínaje příjmem klinických dat v bronzovém transakčním jezeře.
Monitorování protokolů aplikace Apache Spark pomocí Azure Log Analytics
Protokoly aplikace Apache Spark se odesílají do instance pracovního prostoru Azure služby Log Analytics, na kterou se můžete dotazovat. Pomocí tohoto ukázkového dotazu Kusto můžete filtrovat protokoly specifické pro Řešení pro zdravotní data:
AppTraces
| where Properties['LoggerName'] contains "Healthcaredatasolutions"
or Properties['LoggerName'] contains "DMF"
or Properties['LoggerName'] contains "RMT"
| limit 1000
Protokoly konzoly poznámkového bloku také protokolují RunId pro každé spuštění. Tuto hodnotu můžete použít k načtení protokolů pro konkrétní spuštění, jak je znázorněno v následujícím ukázkovém dotazu:
AppTraces
| where Properties['RunId'] == "<RunId>"
Obecné informace o monitorování najdete v tématu Použití centra monitorování prostředků infrastruktury.
Použití Průzkumníka souborů OneLake
Aplikace Průzkumník souborů OneLake bezproblémově integruje OneLake s Průzkumníkem souborů Windows. Pomocí Průzkumníka souborů OneLake můžete zobrazit libovolnou složku nebo soubor nasazený v pracovním prostoru prostředků infrastruktury. Můžete také zobrazit ukázková data, soubory a složky OneLake a soubory kontrolních bodů.
Použití nástroje Azure Storage Explorer
Můžete také použít Průzkumníka služby Azure Storage k následujícímu:
- Přístup k souborům OneLake v transakčních jezerech prostředků infrastruktury
- Připojení k cestě k souboru adresy URL OneLake
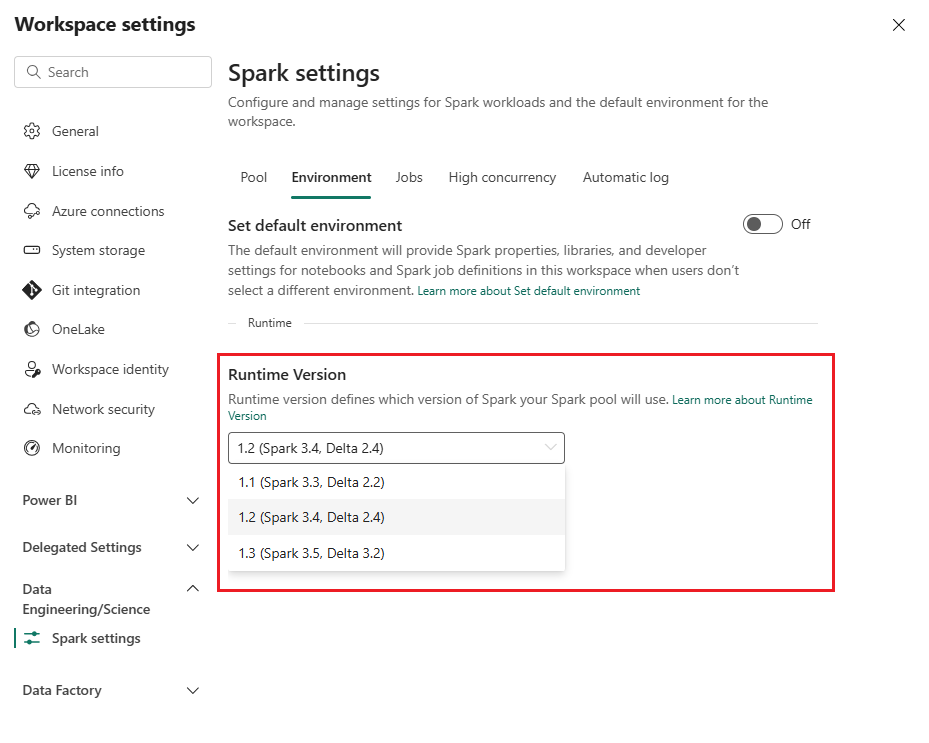
Resetování verze modulu runtime Sparku v pracovním prostoru prostředků infrastruktury
Ve výchozím nastavení používají všechny nové pracovní prostory prostředků infrastruktury nejnovější verzi modulu runtime prostředků infrastruktury, což je aktuálně modul runtime 1.3. Řešení pro zdravotní data však podporují pouze modul runtime 1.2.
Po nasazení Řešení pro zdravotní data do pracovního prostoru se proto ujistěte, že je výchozí verze modulu runtime prostředků infrastruktury nastavená na Runtime 1.2 (Apache Spark 3.4 a Delta Lake 2.4). Pokud ne, spuštění datového kanálu a poznámkového bloku může selhat. Další informace najdete v tématu Podpora více modulů runtime v prostředcích infrastruktury.
Pokud chcete zkontrolovat nebo aktualizovat verzi modulu runtime v prostředcích infrastruktury, postupujte takto:
Přejděte do zobrazení pracovního prostoru řešení pro data ve zdravotnictví a vyberte Nastavení pracovního prostoru.
Na stránce nastavení pracovního prostoru rozbalte rozevírací seznam Datové Inženýrství/věda a vyberte Nastavení Spark.
Na kartě Prostředí aktualizujte hodnotu Verze modulu runtime na 1.2 (Spark 3.4, Delta 2.4) a uložte změny.

Aktualizace uživatelského rozhraní prostředků infrastruktury a Průzkumníka souborů OneLake
V některých případech si můžete všimnout, že uživatelské rozhraní prostředků infrastruktury nebo Průzkumník souborů OneLake ne vždy aktualizuje obsah po každém spuštění poznámkového bloku. Pokud po spuštění jakéhokoli kroku spuštění (například vytvoření nové složky nebo transakční jezero nebo přijetí nových dat do tabulky) v uživatelském rozhraní nevidíte očekávaný výsledek, zkuste artefakt (tabulku, transakční jezero, složku) aktualizovat. Tato aktualizace může často vyřešit nesrovnalosti, než prozkoumáte jiné možnosti nebo prozkoumáte dále.