Kurz: Použití poznámkového bloku s Apache Sparkem k dotazování databáze KQL
Poznámkové bloky jsou čitelné dokumenty obsahující popisy analýzy dat a výsledky a spustitelné dokumenty, které je možné spustit za účelem analýzy dat. V tomto článku se dozvíte, jak pomocí poznámkového bloku Microsoft Fabric číst a zapisovat data do databáze KQL pomocí Apache Sparku. Tento kurz používá předem vytvořenou datovou sadu a poznámkové bloky v reálném čase i v prostředích Datoví technici v Microsoft Fabric. Další informace o poznámkových blocích najdete v tématu Použití poznámkových bloků Microsoft Fabric.
Konkrétně se naučíte:
- Vytvoření databáze KQL
- Import poznámkového bloku
- Zápis dat do databáze KQL pomocí Apache Sparku
- Dotazování dat z databáze KQL
Požadavky
- Pracovní prostor s kapacitou s podporou Microsoft Fabric
1. Vytvoření databáze KQL
V levém navigačním panelu vyberte pracovní prostor.
Pokud chcete začít vytvářet eventstream, postupujte podle jednoho z těchto kroků:
- Vyberte Nová položka a pak Eventhouse. Do pole Název centra událostí zadejte nycGreenTaxi a pak vyberte Vytvořit. Vytvoří se databáze KQL se stejným názvem.
- V existujícím objektu událostí vyberte databáze. V části databáze KQL vyberte +, v poli Název databáze KQL zadejte nycGreenTaxia pak vyberte Vytvořit.
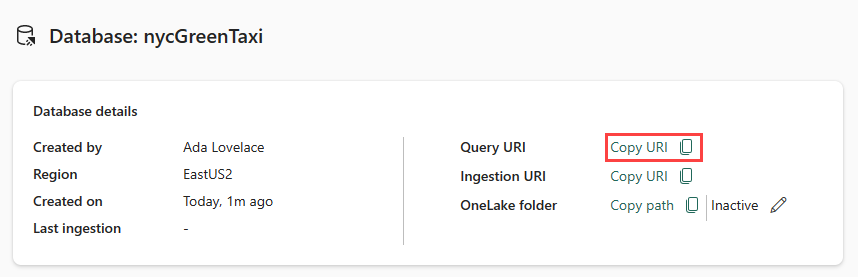
Zkopírujte identifikátor URI dotazu z karty podrobností databáze na řídicím panelu databáze a vložte ho někam, jako je poznámkový blok, abyste ho mohli použít v pozdějším kroku.
2. Stáhněte si poznámkový blok NYC GreenTaxi
Vytvořili jsme ukázkový poznámkový blok, který vás provede všemi potřebnými kroky pro načtení dat do databáze pomocí konektoru Spark.
Otevřete úložiště ukázek Prostředků infrastruktury na GitHubu a stáhněte si poznámkový blok NYC GreenTaxi KQL.
Uložte poznámkový blok místně do zařízení.
Poznámka:
Poznámkový blok musí být uložen ve
.ipynbformátu souboru.

3. Import poznámkového bloku
Zbytek tohoto pracovního postupu se vyskytuje v části Datoví technici produktu a používá poznámkový blok Spark k načtení a dotazování dat v databázi KQL.
V pracovním prostoru vyberte Import>Sešit>Z tohoto počítače>Nahrát, poté vyberte sešit NYC GreenTaxi, který jste si stáhli v předchozím kroku.
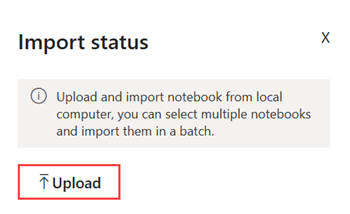
Po dokončení importu otevřete poznámkový blok z pracovního prostoru.
4. Získání dat
Pokud chcete dotazovat databázi pomocí konektoru Spark, musíte udělit přístup pro čtení a zápis ke kontejneru objektů blob NYC GreenTaxi.
Vyberte tlačítko přehrát, aby se spustily následující buňky, nebo vyberte buňku a stiskněte Shift+Enter. Tento krok opakujte pro každou buňku kódu.
Poznámka:
Před spuštěním další buňky počkejte, než se zobrazí značka zaškrtnutí dokončení.
Spuštěním následující buňky povolte přístup ke kontejneru objektů blob NYC GreenTaxi.
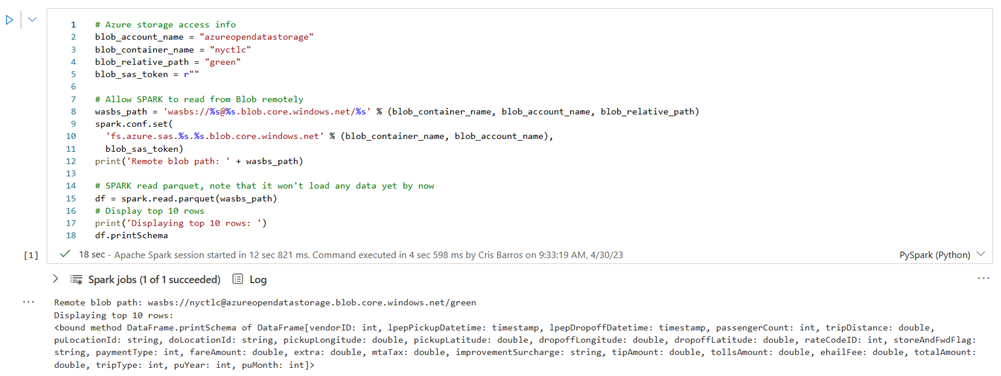
Do kustoURI vložte identifikátor URI dotazu, který jste zkopírovali dříve , místo zástupného textu.
Změňte název zástupné databáze na nycGreenTaxi.
Změňte název zástupné tabulky na GreenTaxiData.

Spusťte buňku.
Spuštěním další buňky zapište data do databáze. Dokončení tohoto kroku může trvat několik minut.




Databáze teď obsahuje data načtená do tabulky s názvem GreenTaxiData.
5. Spuštění poznámkového bloku
Spusťte zbývající dvě buňky postupně a dotazujte se na data z tabulky. Výsledky ukazují prvních 20 nejvyšších a nejnižších jízdných taxíků a vzdáleností zaznamenaných podle roku.

6. Vyčištění prostředků
Vyčistěte položky vytvořené tak, že přejdete do pracovního prostoru, ve kterém byly vytvořeny.
V pracovním prostoru najeďte myší na poznámkový blok, který chcete odstranit, vyberte nabídku Další [...] >Odstranit.
Vyberte Odstranit. Jakmile poznámkový blok odstraníte, nemůžete ho obnovit.
