Výchozí sémantické modely Power BI v Microsoft Fabric
Platí pro:✅SQL Analytics endpoint, Warehouse a Mirrored Database in Microsoft Fabric
V Microsoft Fabric jsou sémantické modely Power BI logickým popisem analytické domény s metrikami, obchodní terminologií a reprezentací, které umožňují hlubší analýzu. Tento sémantický model je obvykle hvězdicové schéma s fakty, které představují doménu, a dimenze, které umožňují analyzovat, nebo rozdělit a rozdělit doménu k podrobnostem, filtrování a výpočtu různých analýz. V sémantickém modelu se automaticky vytvoří sémantický model a zvolíte, které tabulky, relace a míry se mají přidat, a výše uvedená obchodní logika se zdědí z nadřazeného jezera nebo skladu v uvedeném pořadí, rychle zahájí podřízené analytické prostředí pro business intelligence a analýzu s položkou v Microsoft Fabric, která je spravovaná, optimalizované a synchronizované bez zásahu uživatele.
Vizualizace a analýzy v sestavách Power BI se teď dají sestavit na webu – nebo v několika krocích v Power BI Desktopu – což uživatelům šetří čas, prostředky a ve výchozím nastavení poskytuje uživatelům bezproblémové prostředí pro spotřebu. Výchozí sémantický model Power BI se řídí konvencí pojmenování lakehouse.
Sémantické modely Power BI představují zdroj dat připravených pro vytváření sestav, vizualizaci, zjišťování a spotřebu. Sémantické modely Power BI poskytují:
- Schopnost rozšířit konstrukce skladových prostorů tak, aby zahrnovala hierarchie, popisy a relace. To umožňuje hlubší sémantické porozumění doméně.
- Možnost katalogovat, vyhledávat a vyhledávat informace o sémantickém modelu Power BI v katalogu OneLake.
- Možnost nastavit oprávnění pro izolaci a zabezpečení úloh.
- Schopnost vytvářet míry, standardizované metriky pro opakovatelnou analýzu.
- Možnost vytvářet sestavy Power BI pro vizuální analýzu
- Schopnost zjišťovat a využívat data v Excelu.
- Možnost připojení a analýzy dat pro nástroje třetích stran, jako je Tableau
Další informace o Power BI najdete v doprovodných materiálech k Power BI.
Poznámka:
Microsoft přejmenoval typ obsahu datové sady Power BI na sémantický model. To platí i pro Microsoft Fabric. Další informace najdete v tématu Nový název datových sad Power BI.
Režim Direct Lake
Režim Direct Lake je základní funkcí nového modulu pro analýzu velmi velkých datových sad v Power BI. Tato technologie je založená na myšlence využívání souborů formátovaných parquet přímo z datového jezera, aniž byste museli dotazovat koncový bod služby Warehouse nebo SQL Analytics a nemuseli importovat nebo duplikovat data do sémantického modelu Power BI. Tato nativní integrace přináší jedinečný režim přístupu k datům z koncového bodu služby Warehouse nebo SQL Analytics s názvem Direct Lake. Přehled Direct Lake obsahuje další informace o tomto režimu úložiště pro sémantické modely Power BI.
Direct Lake poskytuje nejvýkonnější prostředí pro dotazy a vytváření sestav. Direct Lake je rychlá cesta k využívání dat z datového jezera přímo do modulu Power BI připraveného k analýze.
V tradičním režimu DirectQuery modul Power BI přímo dotazuje data ze zdroje pro každé spuštění dotazu a výkon dotazu závisí na rychlosti načítání dat. DirectQuery eliminuje potřebu kopírování dat a zajišťuje, aby se všechny změny ve zdroji okamžitě projevily ve výsledcích dotazu.
V režimu importu je výkon lepší, protože data jsou snadno dostupná v paměti, aniž byste museli dotazovat data ze zdroje pro každé spuštění dotazu. Modul Power BI ale musí data nejprve zkopírovat do paměti v době aktualizace dat. Všechny změny souvisejícího zdroje dat se vyberou během příští aktualizace dat.
Režim Direct Lake eliminuje požadavek na import kopírování dat tím, že využívá datové soubory přímo do paměti. Vzhledem k tomu, že neexistuje žádný explicitní proces importu, je možné vyzvednout všechny změny ve zdroji, jak k nim dojde. Direct Lake kombinuje výhody režimu DirectQuery a importu a současně se jim vyhnout jejich nevýhodám. Režim Direct Lake je ideální volbou pro analýzu velmi velkých datových sad a datových sad s častými aktualizacemi ve zdroji. Direct Lake se automaticky přesměruje na DirectQuery pomocí koncového bodu analýzy SQL služby Warehouse nebo koncového bodu analýzy SQL, když Direct Lake překročí limity pro skladovou položku, nebo používá funkce, které nejsou podporované, což uživatelům sestav umožní pokračovat bez přerušení.
Režim Direct Lake je režim úložiště pro výchozí sémantické modely Power BI a nové sémantické modely Power BI vytvořené v koncovém bodu analýzy SQL nebo Warehouse. Pomocí Power BI Desktopu můžete také vytvářet sémantické modely Power BI pomocí koncového bodu analýzy SQL Warehouse nebo koncového bodu analýzy SQL jako zdroje dat pro sémantické modely v režimu importu nebo úložiště DirectQuery.
Vysvětlení toho, co je ve výchozím sémantickém modelu Power BI
Při vytváření koncového bodu služby Warehouse nebo SQL Analytics se vytvoří výchozí sémantický model Power BI. Výchozí sémantický model je reprezentován (výchozí) příponou. K výběru tabulek, které chcete přidat, můžete použít spravovat výchozí sémantický model .
Synchronizace výchozího sémantického modelu Power BI
Dříve jsme do výchozího sémantického modelu Power BI automaticky přidali všechny tabulky a zobrazení ve skladu. Na základě zpětné vazby jsme výchozí chování upravili tak, aby do výchozího sémantického modelu Power BI automaticky nepřidávejte tabulky a zobrazení. Tato změna zajistí, že se synchronizace na pozadí neaktivuje. Tím se také zakáže některé akce, jako je "Nová míra", "Vytvořit sestavu", "Analyzovat v aplikaci Excel".
Pokud chcete toto výchozí chování změnit, můžete:
Ručně povolte synchronizaci výchozího nastavení sémantického modelu Power BI pro každý koncový bod služby Warehouse nebo SQL Analytics v pracovním prostoru. Tím se restartuje synchronizace na pozadí, která způsobí určité náklady na spotřebu.
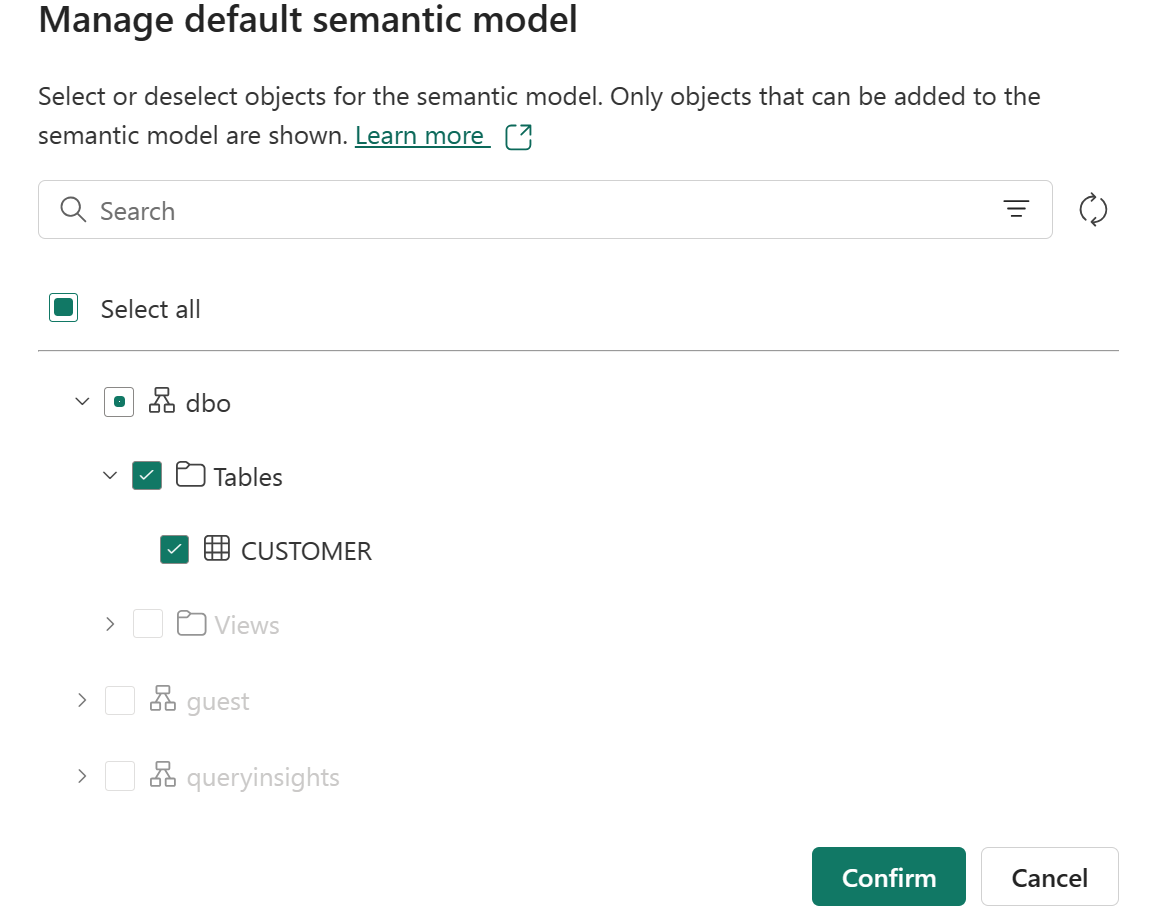
Ruční výběr tabulek a zobrazení pro přidání do sémantického modelu prostřednictvím sémantického modelu Správy výchozího sémantického modelu Power BI na pásu karet nebo na informačním panelu


Poznámka:
Pokud nepoužíváte výchozí sémantický model Power BI pro účely vytváření sestav, ručně zakažte nastavení sémantického modelu Power BI, abyste se vyhnuli automatickému přidávání objektů. Aktualizace nastavení zajistí, že se synchronizace na pozadí neaktivuje a ušetří náklady na spotřebu Onelake.
Ruční aktualizace výchozího sémantického modelu Power BI
Jakmile ve výchozím sémantickém modelu Power BI existují objekty, můžete tabulky ověřit nebo vizuálně zkontrolovat dvěma způsoby:
Na pásu karet vyberte tlačítko Ručně aktualizovat sémantický model.
Zkontrolujte výchozí rozložení pro výchozí sémantické objekty modelu.
Výchozí rozložení tabulek s podporou BI se zachová v uživatelské relaci a vygeneruje se vždy, když uživatel přejde do zobrazení modelu. Vyhledejte kartu Výchozí sémantické objekty modelu.
Přístup k výchozímu sémantickému modelu Power BI
Pokud chcete získat přístup k výchozím sémantickým modelům Power BI, přejděte do pracovního prostoru a vyhledejte sémantický model, který odpovídá názvu požadovaného lakehouse. Výchozí sémantický model Power BI se řídí konvencí pojmenování lakehouse.

Pokud chcete načíst sémantický model, vyberte název sémantického modelu.
Monitorování výchozího sémantického modelu Power BI
Aktivitu v sémantickém modelu můžete monitorovat a analyzovat pomocí SQL Server Profileru připojením ke koncovému bodu XMLA.
SQL Server Profiler se instaluje pomocí aplikace SQL Server Management Studio (SSMS) a umožňuje trasování a ladění sémantických událostí modelu. I když je pro SQL Server oficiálně zastaralý, Profiler je stále součástí SSMS a zůstává podporovaný pro Analysis Services a Power BI. Použití s výchozím sémantickým modelem Power BI pro Prostředky infrastruktury vyžaduje SQL Server Profiler verze 18.9 nebo vyšší. Uživatelé musí při připojování pomocí koncového bodu XMLA určit sémantický model jako počáteční katalog . Další informace najdete v tématu SQL Server Profiler pro Analysis Services.
Skriptování výchozího sémantického modelu Power BI
Pomocí aplikace SQL Server Management Studio (SSMS) můžete skriptovat výchozí sémantický model Power BI z koncového bodu XMLA.
Zobrazte schéma jazyka TMSL (Tabular Model Scripting Language) sémantického modelu tím, že ho skriptujete prostřednictvím Průzkumník objektů v SSMS. Chcete-li se připojit, použijte sémantický model připojovací řetězec, který vypadá jako powerbi://api.powerbi.com/v1.0/myorg/username. Připojovací řetězec pro sémantický model najdete v části Nastavení v části Nastavení. Odtud můžete vygenerovat skript XMLA sémantického modelu prostřednictvím akce místní nabídky skriptu SSMS. Další informace najdete v tématu Připojení datové sady ke koncovému bodu XMLA.
Skriptování vyžaduje oprávnění k zápisu Power BI do sémantického modelu Power BI. S oprávněními ke čtení můžete zobrazit data, ale ne schéma sémantického modelu Power BI.
Vytvoření nového sémantického modelu Power BI v režimu úložiště Direct Lake
Můžete také vytvořit další sémantické modely Power BI v režimu Direct Lake pomocí koncového bodu analýzy SQL nebo dat ve skladu. Tyto nové sémantické modely Power BI je možné upravovat v pracovním prostoru pomocí datového modelu Open a lze je používat s dalšími funkcemi, jako je psaní dotazů DAX a zabezpečení na úrovni řádků sémantického modelu.
Tlačítko Nový sémantický model Power BI vytvoří nový prázdný sémantický model oddělený od výchozího sémantického modelu.
Pokud chcete vytvořit sémantický model Power BI v režimu Direct Lake, postupujte takto:
Otevřete lakehouse a na pásu karet vyberte Nový sémantický model Power BI.
Alternativně otevřete koncový bod analýzy SQL služby Warehouse nebo Lakehouse, nejprve vyberte pás karet Vytváření sestav a pak vyberte Nový sémantický model Power BI.
Zadejte název nového sémantického modelu, vyberte pracovní prostor, do něhož ho chcete uložit, a vyberte tabulky, které chcete zahrnout. Pak vyberte Potvrdit.
Nový sémantický model Power BI je možné upravovat v pracovním prostoru, kde můžete přidávat relace, míry, přejmenovat tabulky a sloupce, zvolit, jak se hodnoty zobrazují ve vizuálech sestavy, a mnoho dalšího. Pokud se zobrazení modelu po vytvoření nezobrazí, zkontrolujte blokování automaticky otevíraných oken v prohlížeči.
Pokud chcete později sémantický model Power BI upravit, vyberte možnost Otevřít datový model z místní nabídky sémantického modelu nebo na stránce podrobností položky, abyste mohli sémantický model dále upravit.
Sestavy Power BI je možné vytvořit v pracovním prostoru výběrem nové sestavy z webového modelování nebo v Power BI Desktopu živým připojením k tomuto novému sémantickému modelu.
Další informace o připojení k sémantickým modelům v služba Power BI z Power BI Desktopu
Vytvoření nového sémantického modelu Power BI v režimu importu nebo úložiště DirectQuery
Když máte data v Microsoft Fabric, znamená to, že můžete vytvářet sémantické modely Power BI v jakémkoli režimu úložiště – Direct Lake, import nebo DirectQuery. Další sémantické modely Power BI můžete vytvořit v režimu importu nebo DirectQuery pomocí koncového bodu analýzy SQL nebo datového skladu.
Pokud chcete vytvořit sémantický model Power BI v režimu importu nebo DirectQuery, postupujte takto:
Otevřete Power BI Desktop, přihlaste se a vyberte OneLake.
Zvolte koncový bod analýzy SQL lakehouse nebo skladu.
Vyberte rozevírací seznam Připojit a zvolte Připojit ke koncovému bodu SQL.
Vyberte režim úložiště Import nebo DirectQuery a tabulky, které chcete přidat do sémantického modelu.
Odtud můžete vytvořit sémantický model a sestavu Power BI, které se publikují do pracovního prostoru, až budou připravené.
Další informace o Power BI najdete v Power BI.
Omezení
Výchozí sémantické modely Power BI se řídí aktuálními omezeními sémantických modelů v Power BI. Další informace:
- Limity prostředků a objektů služby Azure Analysis Services
- Datové typy v Power BI Desktopu – Power BI
Pokud se datové typy Parquet, Apache Spark nebo SQL nedají mapovat na jeden z datových typů Power BI Desktopu, v rámci procesu synchronizace se zahodí. To je v souladu s aktuálním chováním Power BI. Pro tyto sloupce doporučujeme přidat explicitní převody typů v jejich procesech ETL, abyste je převedli na podporovaný typ. Pokud existují datové typy, které jsou potřeba upstreamové, mohou uživatelé volitelně zadat zobrazení v SQL s požadovaným explicitním převodem typu. Synchronizace ji vyzvedne nebo ji můžete přidat ručně, jak je uvedeno dříve.
- Výchozí sémantické modely Power BI je možné upravovat jenom v koncovém bodu analýzy SQL nebo skladu.