Kurz – část 3: Trénování a registrace modelu strojového učení
V tomto kurzu se naučíte vytrénovat více modelů strojového učení, abyste vybrali ten nejlepší, abyste mohli předpovědět, kteří zákazníci z banky pravděpodobně odejdou.
V tomto kurzu:
- Trénování modelů Random Forest a LightGBM
- Pomocí nativní integrace Microsoft Fabric s architekturou MLflow můžete protokolovat natrénované modely strojového učení, použité hyperaparametry a metriky vyhodnocení.
- Zaregistrujte natrénovaný model strojového učení.
- Vyhodnoťte výkony natrénovaných modelů strojového učení v ověřovací datové sadě.
MLflow je opensourcová platforma pro správu životního cyklu strojového učení pomocí funkcí, jako je sledování, modely a registr modelů. MLflow je nativně integrovaný s prostředím fabric Datová Věda.
Požadavky
Získejte předplatné Microsoft Fabric. Nebo si zaregistrujte bezplatnou zkušební verzi Microsoft Fabricu.
Přihlaste se k Microsoft Fabric.
Použijte přepínač v levém dolním rohu vaší domovské stránky a přepněte na Fabric.

Toto je část 3 z 5 v sérii kurzů. K dokončení tohoto kurzu nejprve dokončete:
- Část 1: Ingestování dat do Microsoft Fabric Lakehouse pomocí Apache Sparku
- Část 2: Prozkoumání a vizualizace dat pomocí poznámkových bloků Microsoft Fabric, kde najdete další informace o těchto datech .
Sledování v poznámkovém bloku
3-train-evaluate.ipynb je poznámkový blok, který doprovází tento kurz.
Pokud chcete otevřít poznámkový blok pro tento výukový kurz, řiďte se pokyny uvedenými v Příprava systému pro kurzy datových věd, abyste importovali poznámkový blok do svého pracovního prostoru.
Pokud byste raději zkopírovali a vložili kód z této stránky, můžete vytvořit nový poznámkový blok.
Než začnete spouštět kód, nezapomeňte k poznámkovému bloku připojit lakehouse.
Důležité
Připojte stejný jezerní dům, který jste použili v části 1 a 2.
Instalace vlastních knihoven
Pro tento poznámkový blok nainstalujete nevyvážené učení (importované jako imblearn) pomocí %pip install. Nevyrovnaný učení je knihovna pro syntetickou menšinovou převzorkovací techniku (SMOTE), která se používá při práci s nevyváženými datovými sadami. Po restartování se jádro PySpark restartuje %pip install, takže před spuštěním dalších buněk budete muset knihovnu nainstalovat.
K SMOTE se dostanete pomocí imblearn knihovny. Nainstalujte ho teď pomocí in-line instalačních funkcí (např %pip. , %conda).
# Install imblearn for SMOTE using pip
%pip install imblearn
Důležité
Spusťte tuto instalaci pokaždé, když poznámkový blok restartujete.
Když do poznámkového bloku nainstalujete knihovnu, bude dostupná jenom po dobu trvání relace poznámkového bloku, a ne v pracovním prostoru. Pokud poznámkový blok restartujete, budete muset knihovnu nainstalovat znovu.
Pokud máte knihovnu, kterou často používáte a chcete ji zpřístupnit všem poznámkovým blokům v pracovním prostoru, můžete pro tento účel použít prostředí Fabric. Můžete vytvořit prostředí, nainstalovat do ní knihovnu a pak správce pracovního prostoru může prostředí připojit k pracovnímu prostoru jako jeho výchozí prostředí. Další informace o nastavení prostředí jako výchozího pracovního prostoru najdete v tématu Nastavení výchozích knihoven pro pracovní prostor správcem.
Informace o migraci existujících knihoven pracovních prostorů a vlastností Sparku do prostředí najdete v tématu Migrace knihoven pracovních prostorů a vlastností Sparku do výchozího prostředí.
Načtení dat
Před trénováním jakéhokoli modelu strojového učení je potřeba načíst tabulku Delta z jezera, abyste mohli číst vyčištěná data, která jste vytvořili v předchozím poznámkovém bloku.
import pandas as pd
SEED = 12345
df_clean = spark.read.format("delta").load("Tables/df_clean").toPandas()
Generování experimentu pro sledování a protokolování modelu pomocí MLflow
Tato část ukazuje, jak vygenerovat experiment, určit model strojového učení a parametry trénování a také metriky vyhodnocování, trénovat modely strojového učení, protokolovat je a ukládat natrénované modely pro pozdější použití.
import mlflow
# Setup experiment name
EXPERIMENT_NAME = "bank-churn-experiment" # MLflow experiment name
Rozšíření funkcí automatickéhologování toku MLflow funguje tak, že automaticky zachytává hodnoty vstupních parametrů a výstupních metrik modelu strojového učení při trénování. Tyto informace se pak zaprotokolují do vašeho pracovního prostoru, kde k němu můžete přistupovat a vizualizovat pomocí rozhraní API MLflow nebo odpovídajícího experimentu ve vašem pracovním prostoru.
Všechny experimenty s příslušnými názvy se zaprotokolují a budete moct sledovat jejich parametry a metriky výkonu. Další informace o automatickém přihlašování najdete v tématu Automatickélogování v Microsoft Fabric.
Nastavení specifikací experimentu a automatickéhologování
mlflow.set_experiment(EXPERIMENT_NAME)
mlflow.autolog(exclusive=False)
Import scikit-learn a LightGBM
S daty teď můžete definovat modely strojového učení. V tomto poznámkovém bloku použijete náhodné modely doménové struktury a LightGBM. Použijte scikit-learn a lightgbm implementujte modely v několika řádcích kódu.
# Import the required libraries for model training
from sklearn.model_selection import train_test_split
from lightgbm import LGBMClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, f1_score, precision_score, confusion_matrix, recall_score, roc_auc_score, classification_report
Příprava trénovacích, ověřovacích a testovacích datových sad
train_test_split Pomocí funkce z scikit-learn rozdělte data do trénovacích, ověřovacích a testovacích sad.
y = df_clean["Exited"]
X = df_clean.drop("Exited",axis=1)
# Split the dataset to 60%, 20%, 20% for training, validation, and test datasets
# Train-Test Separation
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=SEED)
# Train-Validation Separation
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.25, random_state=SEED)
Uložení testovacích dat do tabulky Delta
Uložte testovací data do tabulky Delta pro použití v dalším poznámkovém bloku.
table_name = "df_test"
# Create PySpark DataFrame from Pandas
df_test=spark.createDataFrame(X_test)
df_test.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark test DataFrame saved to delta table: {table_name}")
Použití SMOTE na trénovací data pro syntetizaci nových vzorků pro menšinovou třídu
Průzkum dat v části 2 ukázal, že z 10 000 datových bodů, které odpovídají 10 000 zákazníkům, opustilo banku pouze 2 037 zákazníků (přibližně 20 %). To znamená, že datová sada je vysoce nevyvážená. Problém s nevyváženou klasifikací spočívá v tom, že existuje příliš málo příkladů menšinové třídy, aby se model efektivně naučil rozhodovací hranici. SMOTE je nejčastěji používaný přístup k syntetizaci nových vzorků pro menšinovou třídu. Další informace o SMOTE najdete tady a tady.
Tip
Mějte na paměti, že SMOTE by se měla použít pouze pro trénovací datovou sadu. Testovací datovou sadu musíte nechat v původní nevyvážené distribuci, abyste získali platnou aproximaci toho, jak bude model strojového učení fungovat s původními daty, což představuje situaci v produkčním prostředí.
from collections import Counter
from imblearn.over_sampling import SMOTE
sm = SMOTE(random_state=SEED)
X_res, y_res = sm.fit_resample(X_train, y_train)
new_train = pd.concat([X_res, y_res], axis=1)
Tip
Zprávu upozornění MLflow, která se zobrazí při spuštění této buňky, můžete bezpečně ignorovat.
Pokud se zobrazí zpráva ModuleNotFoundError , zmeškali jste spuštění první buňky v tomto poznámkovém bloku, která knihovnu imblearn nainstaluje. Tuto knihovnu musíte nainstalovat pokaždé, když poznámkový blok restartujete. Vraťte se a znovu spusťte všechny buňky začínající první buňkou v tomto poznámkovém bloku.
Trénování modelu
- Trénování modelu pomocí náhodné doménové struktury s maximální hloubkou 4 a 4 funkcí
mlflow.sklearn.autolog(registered_model_name='rfc1_sm') # Register the trained model with autologging
rfc1_sm = RandomForestClassifier(max_depth=4, max_features=4, min_samples_split=3, random_state=1) # Pass hyperparameters
with mlflow.start_run(run_name="rfc1_sm") as run:
rfc1_sm_run_id = run.info.run_id # Capture run_id for model prediction later
print("run_id: {}; status: {}".format(rfc1_sm_run_id, run.info.status))
# rfc1.fit(X_train,y_train) # Imbalanaced training data
rfc1_sm.fit(X_res, y_res.ravel()) # Balanced training data
rfc1_sm.score(X_val, y_val)
y_pred = rfc1_sm.predict(X_val)
cr_rfc1_sm = classification_report(y_val, y_pred)
cm_rfc1_sm = confusion_matrix(y_val, y_pred)
roc_auc_rfc1_sm = roc_auc_score(y_res, rfc1_sm.predict_proba(X_res)[:, 1])
- Trénování modelu pomocí náhodné doménové struktury s maximální hloubkou 8 a 6 funkcí
mlflow.sklearn.autolog(registered_model_name='rfc2_sm') # Register the trained model with autologging
rfc2_sm = RandomForestClassifier(max_depth=8, max_features=6, min_samples_split=3, random_state=1) # Pass hyperparameters
with mlflow.start_run(run_name="rfc2_sm") as run:
rfc2_sm_run_id = run.info.run_id # Capture run_id for model prediction later
print("run_id: {}; status: {}".format(rfc2_sm_run_id, run.info.status))
# rfc2.fit(X_train,y_train) # Imbalanced training data
rfc2_sm.fit(X_res, y_res.ravel()) # Balanced training data
rfc2_sm.score(X_val, y_val)
y_pred = rfc2_sm.predict(X_val)
cr_rfc2_sm = classification_report(y_val, y_pred)
cm_rfc2_sm = confusion_matrix(y_val, y_pred)
roc_auc_rfc2_sm = roc_auc_score(y_res, rfc2_sm.predict_proba(X_res)[:, 1])
- Trénování modelu pomocí LightGBM
# lgbm_model
mlflow.lightgbm.autolog(registered_model_name='lgbm_sm') # Register the trained model with autologging
lgbm_sm_model = LGBMClassifier(learning_rate = 0.07,
max_delta_step = 2,
n_estimators = 100,
max_depth = 10,
eval_metric = "logloss",
objective='binary',
random_state=42)
with mlflow.start_run(run_name="lgbm_sm") as run:
lgbm1_sm_run_id = run.info.run_id # Capture run_id for model prediction later
# lgbm_sm_model.fit(X_train,y_train) # Imbalanced training data
lgbm_sm_model.fit(X_res, y_res.ravel()) # Balanced training data
y_pred = lgbm_sm_model.predict(X_val)
accuracy = accuracy_score(y_val, y_pred)
cr_lgbm_sm = classification_report(y_val, y_pred)
cm_lgbm_sm = confusion_matrix(y_val, y_pred)
roc_auc_lgbm_sm = roc_auc_score(y_res, lgbm_sm_model.predict_proba(X_res)[:, 1])
Artefakt experimentů pro sledování výkonu modelu
Spuštění experimentu se automaticky uloží do artefaktu experimentu, který najdete v pracovním prostoru. Pojmenují se na základě názvu použitého k nastavení experimentu. Protokolují se všechny natrénované modely strojového učení, jejich běhy, metriky výkonu a parametry modelu.
Zobrazení experimentů:
Na levém panelu vyberte pracovní prostor.
V pravém horním rohu vyfiltrujte, abyste zobrazili jenom experimenty, abyste mohli snadněji najít hledaný experiment.
Vyhledejte a vyberte název experimentu, v tomto případě bank-churn-experiment. Pokud experiment v pracovním prostoru nevidíte, aktualizujte prohlížeč.


Posouzení výkonu natrénovaných modelů v ověřovací datové sadě
Po dokončení trénování modelů strojového učení můžete vyhodnotit výkon natrénovaných modelů dvěma způsoby.
Otevřete uložený experiment z pracovního prostoru, načtěte modely strojového učení a pak vyhodnoťte výkon načtených modelů v ověřovací datové sadě.
# Define run_uri to fetch the model # mlflow client: mlflow.model.url, list model load_model_rfc1_sm = mlflow.sklearn.load_model(f"runs:/{rfc1_sm_run_id}/model") load_model_rfc2_sm = mlflow.sklearn.load_model(f"runs:/{rfc2_sm_run_id}/model") load_model_lgbm1_sm = mlflow.lightgbm.load_model(f"runs:/{lgbm1_sm_run_id}/model") # Assess the performance of the loaded model on validation dataset ypred_rfc1_sm_v1 = load_model_rfc1_sm.predict(X_val) # Random Forest with max depth of 4 and 4 features ypred_rfc2_sm_v1 = load_model_rfc2_sm.predict(X_val) # Random Forest with max depth of 8 and 6 features ypred_lgbm1_sm_v1 = load_model_lgbm1_sm.predict(X_val) # LightGBMPřímo vyhodnoťte výkon natrénovaných modelů strojového učení v ověřovací datové sadě.
ypred_rfc1_sm_v2 = rfc1_sm.predict(X_val) # Random Forest with max depth of 4 and 4 features ypred_rfc2_sm_v2 = rfc2_sm.predict(X_val) # Random Forest with max depth of 8 and 6 features ypred_lgbm1_sm_v2 = lgbm_sm_model.predict(X_val) # LightGBM
V závislosti na vašich preferencích je některý z přístupů v pořádku a měl by nabízet identické výkony. V tomto poznámkovém bloku zvolíte první přístup, abyste lépe ukázali možnosti automatickéhologování MLflow v Microsoft Fabric.
Zobrazení pravdivých/falešně pozitivních/negativních výsledků pomocí konfuzní matice
Dále vytvoříte skript, který vykreslí konfuzní matici, aby se vyhodnotila přesnost klasifikace pomocí ověřovací datové sady. Konfuzní matici je možné vykreslit pomocí nástrojů SynapseML, což je vidět v ukázce detekce podvodů, která je zde k dispozici.
import seaborn as sns
sns.set_theme(style="whitegrid", palette="tab10", rc = {'figure.figsize':(9,6)})
import matplotlib.pyplot as plt
import matplotlib.ticker as mticker
from matplotlib import rc, rcParams
import numpy as np
import itertools
def plot_confusion_matrix(cm, classes,
normalize=False,
title='Confusion matrix',
cmap=plt.cm.Blues):
print(cm)
plt.figure(figsize=(4,4))
plt.rcParams.update({'font.size': 10})
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45, color="blue")
plt.yticks(tick_marks, classes, color="blue")
fmt = '.2f' if normalize else 'd'
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, format(cm[i, j], fmt),
horizontalalignment="center",
color="red" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
- Konfuzní matice pro klasifikátor náhodných doménových struktur s maximální hloubkou 4 a 4 funkcí
cfm = confusion_matrix(y_val, y_pred=ypred_rfc1_sm_v1)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='Random Forest with max depth of 4')
tn, fp, fn, tp = cfm.ravel()
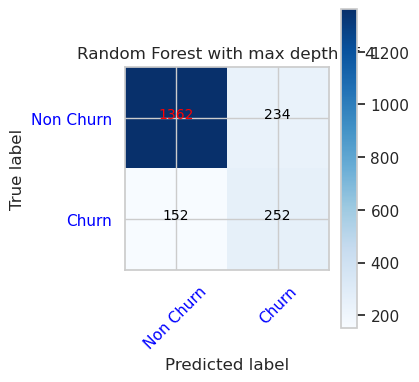
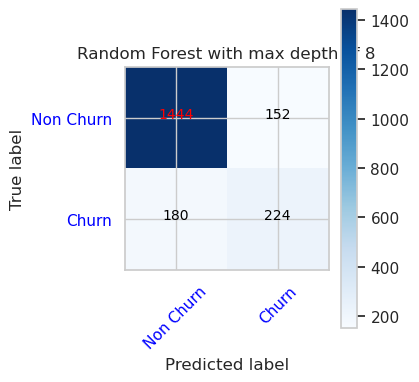
- Konfuzní matice pro klasifikátor náhodných doménových struktur s maximální hloubkou 8 a 6 funkcí
cfm = confusion_matrix(y_val, y_pred=ypred_rfc2_sm_v1)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='Random Forest with max depth of 8')
tn, fp, fn, tp = cfm.ravel()
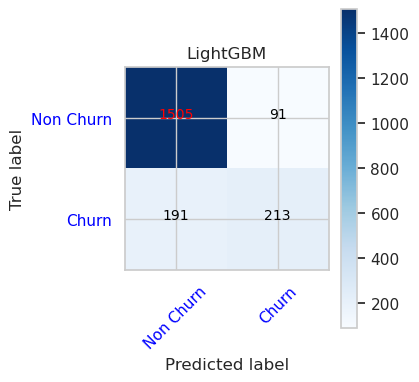
- Matoucí matice pro LightGBM
cfm = confusion_matrix(y_val, y_pred=ypred_lgbm1_sm_v1)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='LightGBM')
tn, fp, fn, tp = cfm.ravel()