Správa knihoven Apache Sparku v Microsoft Fabric
Knihovna je kolekce předem psaného kódu, kterou můžou vývojáři importovat, aby mohli poskytovat funkce. Pomocí knihoven můžete ušetřit čas a úsilí tím, že nemusíte psát kód od začátku a provádět běžné úlohy. Místo toho importujte knihovnu a použijte její funkce a třídy k dosažení požadované funkce. Microsoft Fabric poskytuje několik mechanismů, které vám pomůžou spravovat a používat knihovny.
- Integrované knihovny: Každý modul runtime Sparku infrastruktury poskytuje bohatou sadu oblíbených předinstalovaných knihoven. Úplný seznam předdefinovaných knihoven najdete v prostředí Fabric Spark Runtime.
- Veřejné knihovny: Veřejné knihovny jsou zdrojové z úložišť, jako jsou PyPI a Conda, které jsou aktuálně podporované.
- Vlastní knihovny: Vlastní knihovny odkazují na kód, který vy nebo vaše organizace sestavíte. Prostředky infrastruktury je podporují ve formátech .whl, .jar a .tar.gz . Prostředky infrastruktury podporují .tar.gz pouze pro jazyk R. Pro vlastní knihovny Pythonu použijte formát .whl .
Shrnutí osvědčených postupů správy knihoven
Následující scénáře popisují osvědčené postupy při používání knihoven v Microsoft Fabric.
Scénář 1: Správce nastaví výchozí knihovny pro pracovní prostor
Pokud chcete nastavit výchozí knihovny, musíte být správcem pracovního prostoru. Jako správce můžete provádět tyto úlohy:
- Vytvoření nového prostředí
- Instalace požadovaných knihoven v prostředí
- Připojit toto prostředí jako výchozí pracovní prostor
Když jsou vaše poznámkové bloky a definice úloh Sparku připojené k nastavení pracovního prostoru, spustí relace s knihovnami nainstalovanými ve výchozím prostředí pracovního prostoru.
Scénář 2: Zachování specifikací knihovny pro jednu nebo více položek kódu
Pokud máte společné knihovny pro různé položky kódu a nevyžadují častou aktualizaci, nainstalujte knihovny v prostředí a připojte je k položkám kódu.
Při publikování bude trvat nějakou dobu, než se knihovny v prostředích stanou efektivními. V závislosti na složitosti knihoven obvykle trvá 5 až 15 minut. Během tohoto procesu pomůže systém vyřešit potenciální konflikty a stáhnout požadované závislosti.
Jednou z výhod tohoto přístupu je, že při spuštění relace Sparku s připojeným prostředím je zaručeno, že úspěšně nainstalované knihovny budou k dispozici. Šetří úsilí při údržbě běžných knihoven pro vaše projekty.
Důrazně se doporučuje pro scénáře kanálů se stabilitou.
Scénář 3: Vložená instalace v interaktivním spuštění
Pokud k interaktivnímu psaní kódu používáte poznámkové bloky, použijte vloženou instalaci k přidání dalších nových knihoven PyPI/conda nebo ověření vlastních knihoven pro jednorázové použití je osvědčeným postupem. Vložené příkazy v prostředcích infrastruktury umožňují mít knihovnu efektivní v aktuální relaci Sparku poznámkového bloku. Umožňuje rychlou instalaci, ale nainstalovaná knihovna se neuchovává v různých relacích.
Vzhledem k tomu, že %pip install generování různých stromů závislostí od času, což může vést ke konfliktům knihoven, jsou vložené příkazy ve výchozím nastavení v kanálech vypnuté a nedoporučuje se používat ve vašich kanálech.
Souhrn podporovaných typů knihoven
| Typ knihovny | Správa knihovny prostředí | Vložená instalace |
|---|---|---|
| Veřejný Python (PyPI a Conda) | Podporováno | Podporováno |
| Vlastní Python (.whl) | Podporováno | Podporováno |
| Veřejné R (CRAN) | Nepodporováno | Podporováno |
| Vlastní R (.tar.gz) | Podporováno jako vlastní knihovna | Podporováno |
| Sklenice | Podporováno jako vlastní knihovna | Podporováno |
Vložená instalace
Vložené příkazy podporují správu knihoven v jednotlivých relacích poznámkových bloků.
Vložená instalace Pythonu
Systém restartuje interpret Pythonu, aby použil změnu knihoven. Všechny proměnné definované před spuštěním buňky příkazu budou ztraceny. Důrazně doporučujeme umístit všechny příkazy pro přidání, odstranění nebo aktualizaci balíčků Pythonu na začátku poznámkového bloku.
Vložené příkazy pro správu knihoven Pythonu jsou ve výchozím nastavení zakázané ve spuštění kanálu poznámkového bloku. Pokud chcete povolit %pip install kanál, přidejte do parametrů aktivity poznámkového bloku hodnotu _inlineInstallationEnabled jako logický parametr true.
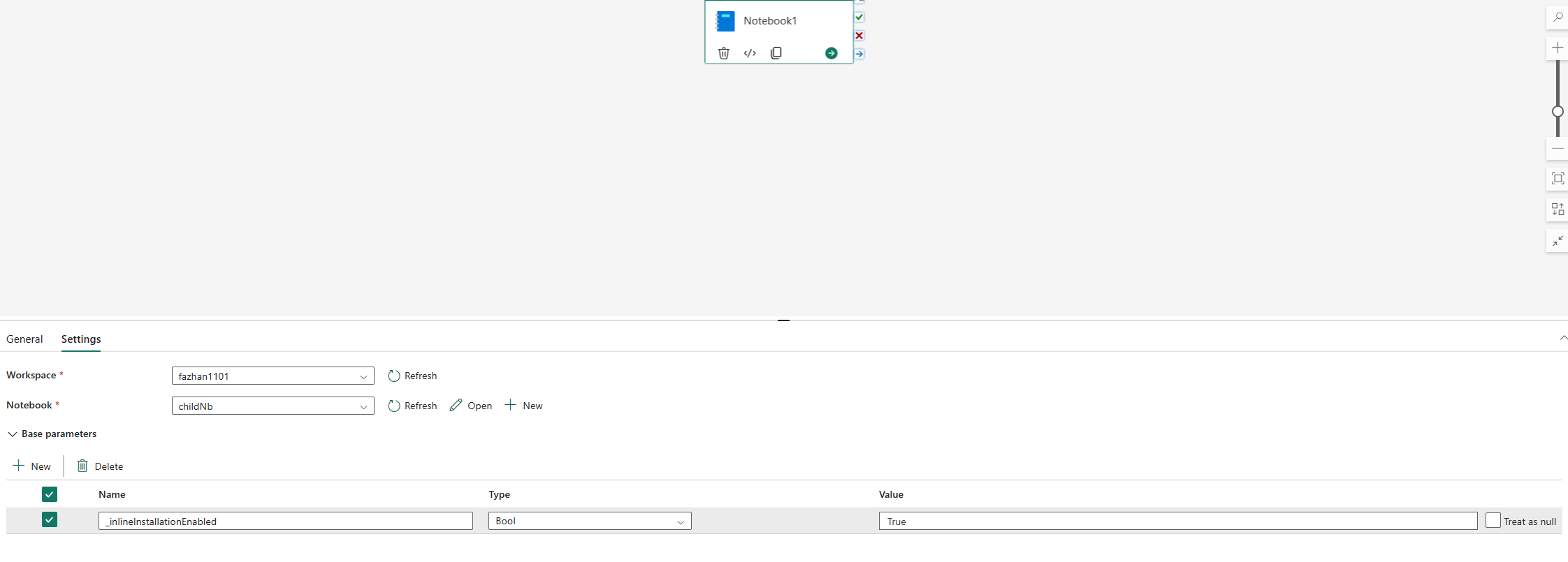
Poznámka:
To %pip install může vést k nekonzistentním výsledkům od času. Doporučuje se nainstalovat knihovnu do prostředí a použít ji v kanálu.
V referenčních informacích k poznámkovému bloku se vložené příkazy pro správu knihoven Pythonu nepodporují. Chcete-li zajistit správnost provádění, doporučujeme odebrat tyto vložené příkazy z odkazovaného poznámkového bloku.
Doporučujeme %pip místo !pip.
!pip je integrovaný příkaz prostředí IPython, který má následující omezení:
-
!pipnainstaluje balíček pouze na uzel ovladače, nikoli na uzly exekutoru. - Balíčky, které se instalují prostřednictvím
!pip, nemají vliv na konflikty s předdefinovanými balíčky nebo na to, jestli se balíčky už importují do poznámkového bloku.
%pip Tyto scénáře ale zpracovává. Knihovny nainstalované prostřednictvím %pip jsou k dispozici na uzlech ovladače i exekutoru a stále platí i pro knihovnu, která je již importována.
Tip
Instalace %conda install nových knihoven Pythonu %pip install obvykle trvá déle než příkaz. Kontroluje úplné závislosti a řeší konflikty.
Možná budete chtít použít %conda install větší spolehlivost a stabilitu. Můžete použít %pip install , pokud jste si jisti, že knihovna, kterou chcete nainstalovat, není v konfliktu s předinstalovanými knihovnami v prostředí runtime.
Všechny dostupné vložené příkazy a vysvětlení Pythonu najdete v tématu %pip a %conda.
Správa veřejných knihoven Pythonu prostřednictvím vložené instalace
V tomto příkladu se dozvíte, jak používat vložené příkazy ke správě knihoven. Předpokládejme, že chcete k jednorázovému zkoumání dat použít altair, výkonnou knihovnu vizualizací pro Python. Předpokládejme, že knihovna není ve vašem pracovním prostoru nainstalovaná. Následující příklad používá příkazy Conda k ilustraci kroků.
Vložené příkazy můžete použít k povolení altair v relaci poznámkového bloku, aniž by to ovlivnilo jiné relace poznámkového bloku nebo jiných položek.
V buňce kódu poznámkového bloku spusťte následující příkazy. První příkaz nainstaluje knihovnu altair . Nainstalujte také vega_datasets, který obsahuje sémantický model, který můžete použít k vizualizaci.
%conda install altair # install latest version through conda command %conda install vega_datasets # install latest version through conda commandVýstup buňky označuje výsledek instalace.
Importujte balíček a sémantický model spuštěním následujícího kódu v jiné buňce poznámkového bloku.
import altair as alt from vega_datasets import dataTeď si můžete pohrát s knihovnou altair s vymezeným oborem relace.
# load a simple dataset as a pandas DataFrame cars = data.cars() alt.Chart(cars).mark_point().encode( x='Horsepower', y='Miles_per_Gallon', color='Origin', ).interactive()
Správa vlastních knihoven Pythonu prostřednictvím vložené instalace
Vlastní knihovny Pythonu můžete nahrát do složky prostředků poznámkového bloku nebo připojeného prostředí. Složky prostředků jsou integrovaný systém souborů poskytovaný jednotlivými poznámkovými bloky a prostředími. Další podrobnosti najdete v materiálech poznámkového bloku. Po nahrání můžete vlastní knihovnu přetáhnout do buňky kódu. Vložený příkaz pro instalaci knihovny se automaticky vygeneruje. Nebo můžete k instalaci použít následující příkaz.
# install the .whl through pip command from the notebook built-in folder
%pip install "builtin/wheel_file_name.whl"
Vložená instalace jazyka R
Ke správě knihoven jazyka R podporuje Prostředky infrastruktury a install.packages()remove.packages()devtools:: příkazy . Všechny dostupné vložené příkazy jazyka R a vysvětlení najdete v příkazu install.packages a příkazu remove.package.
Správa veřejných knihoven R prostřednictvím vložené instalace
Postupujte podle tohoto příkladu a projděte si postup instalace veřejné knihovny jazyka R.
Instalace knihovny informačních kanálů R:
Na pásu karet poznámkového bloku přepněte pracovní jazyk na SparkR (R ).
Nainstalujte knihovnu caesar spuštěním následujícího příkazu v buňce poznámkového bloku.
install.packages("caesar")Teď si můžete pohrát s knihovnou caesar s vymezenou relací pomocí úlohy Sparku.
library(SparkR) sparkR.session() hello <- function(x) { library(caesar) caesar(x) } spark.lapply(c("hello world", "good morning", "good evening"), hello)
Správa knihoven Jar prostřednictvím vložené instalace
Soubory .jar podporují relace poznámkového bloku pomocí následujícího příkazu.
%%configure -f
{
"conf": {
"spark.jars": "abfss://<<Lakehouse prefix>>.dfs.fabric.microsoft.com/<<path to JAR file>>/<<JAR file name>>.jar",
}
}
Buňka kódu jako příklad používá úložiště Lakehouse. V Průzkumníku poznámkových bloků můžete zkopírovat úplnou cestu k souboru ABFS a nahradit v kódu.
