Kurz Lakehouse: Příprava a transformace dat v jezeře
V tomto kurzu použijete poznámkové bloky s modulem runtime Spark k transformaci a přípravě nezpracovaných dat v jezeře.
Požadavky
Pokud nemáte jezerní dům, který obsahuje data, musíte:
Příprava dat
V předchozích krocích kurzu jsme nezpracovaná data přijatá ze zdroje do části Soubory v jezeře. Teď můžete tato data transformovat a připravit je na vytváření tabulek Delta.
Stáhněte si poznámkové bloky ze složky Zdrojový kód kurzu Lakehouse.
V přepínacím panelu v levém dolním rohu obrazovky vyberte Datoví technici ing.

V horní části cílové stránky vyberte Importovat poznámkový blok z oddílu Nový .
V podokně Stavu importu, které se otevře na pravé straně obrazovky, vyberte Nahrát.
Vyberte všechny poznámkové bloky, které jste stáhli v prvním kroku této části.
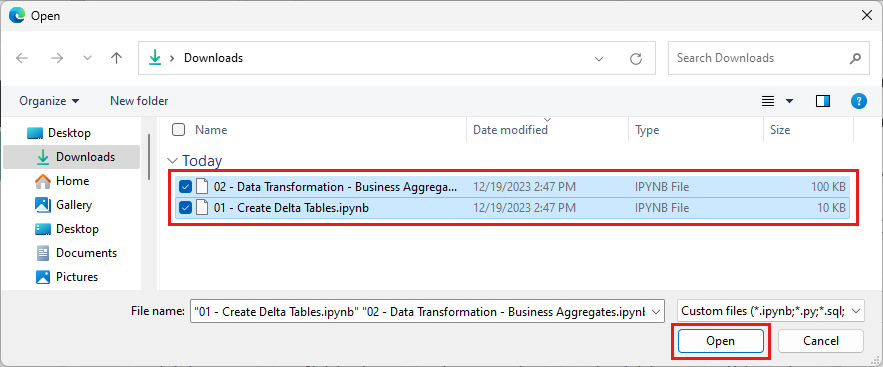
Vyberte Otevřít. V pravém horním rohu okna prohlížeče se zobrazí oznámení o stavu importu.
Po úspěšném importu přejděte do zobrazení položek pracovního prostoru a prohlédněte si nově importované poznámkové bloky. Vyberte wwilakehouse lakehouse a otevřete ho.
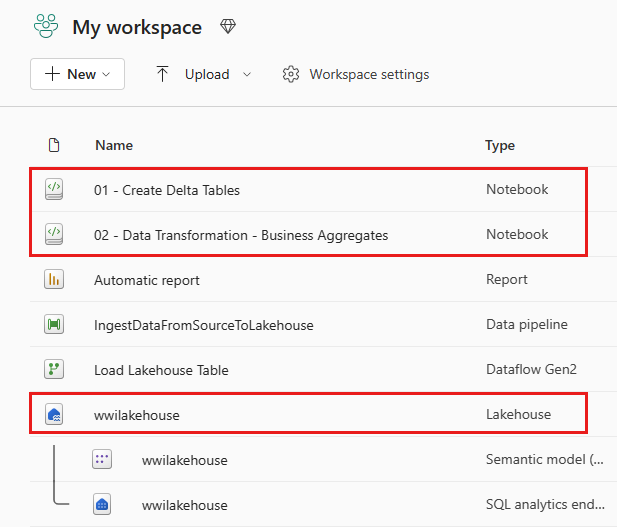
Po otevření jezera wwilakehouse vyberte Otevřít poznámkový blok Existující poznámkový blok> v horní navigační nabídce.
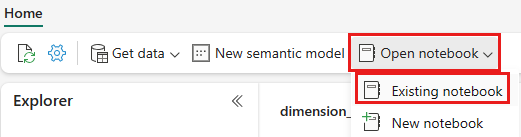
V seznamu existujících poznámkových bloků vyberte poznámkový blok 01 – Vytvořit poznámkový blok Tabulky Delta a vyberte Otevřít.
V otevřeném poznámkovém bloku v Průzkumníku jezera uvidíte, že poznámkový blok je už propojený s otevřeným lakehousem.
Poznámka:
Prostředky infrastruktury poskytují funkci pořadí virtuálních počítačů pro zápis optimalizovaných souborů Delta Lake. Pořadí V často zlepšuje kompresi o tři až čtyřikrát a až 10krát zrychlení výkonu u souborů Delta Lake, které nejsou optimalizované. Spark v Prostředcích infrastruktury dynamicky optimalizuje oddíly při generování souborů s výchozí velikostí 128 MB. Velikost cílového souboru se může změnit podle požadavků na úlohy pomocí konfigurací.
Díky optimalizaci možností zápisu modul Apache Spark snižuje počet zapsaných souborů a má za cíl zvýšit velikost jednotlivých souborů zapsaných dat.
Než začnete zapisovat data jako tabulky Delta Lake v části Tabulky v lakehouse, použijete dvě funkce Infrastruktury (pořadí V a optimalizovat zápis) pro optimalizované zápisy dat a pro lepší výkon čtení. Pokud chcete tyto funkce povolit ve vaší relaci, nastavte tyto konfigurace v první buňce poznámkového bloku.
Pokud chcete spustit poznámkový blok a spustit všechny buňky v posloupnosti, vyberte Spustit vše na horním pásu karet (v části Domů). Pokud chcete kód spustit jenom z určité buňky, vyberte ikonu Spustit , která se zobrazí nalevo od buňky po najetí myší, nebo stiskněte klávesy SHIFT + ENTER na klávesnici, zatímco je ovládací prvek v buňce.
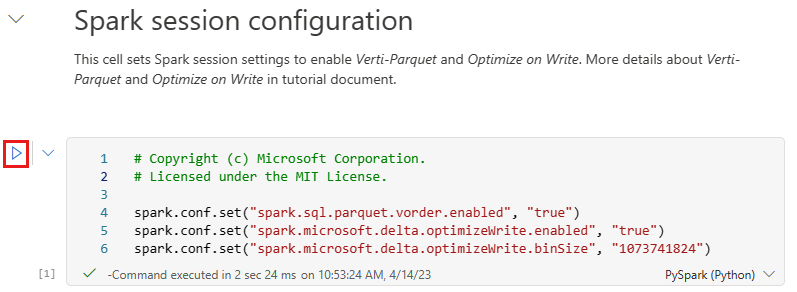
Při spuštění buňky jste nemuseli zadávat základní informace o fondu Sparku nebo clusteru, protože prostředky infrastruktury je poskytují prostřednictvím živého fondu. Každý pracovní prostor prostředků infrastruktury má výchozí fond Sparku s názvem Živý fond. To znamená, že když vytváříte poznámkové bloky, nemusíte se starat o zadání jakýchkoli konfigurací Sparku nebo podrobností o clusteru. Při spuštění prvního příkazu poznámkového bloku je aktivní fond spuštěný během několika sekund. A relace Sparku se vytvoří a spustí kód. Následné spuštění kódu je v tomto poznámkovém bloku téměř okamžité, zatímco relace Sparku je aktivní.
Dále si přečtete nezpracovaná data z oddílu Soubory v jezeře a v rámci transformace přidáte další sloupce pro různé části kalendářních dat. Nakonec pomocí rozhraní Spark API rozdělíte data před jejich zápisem jako formát tabulky Delta na základě nově vytvořených sloupců datových částí (Year a Quarter).
from pyspark.sql.functions import col, year, month, quarter table_name = 'fact_sale' df = spark.read.format("parquet").load('Files/wwi-raw-data/WideWorldImportersDW/parquet/full/fact_sale_1y_full') df = df.withColumn('Year', year(col("InvoiceDateKey"))) df = df.withColumn('Quarter', quarter(col("InvoiceDateKey"))) df = df.withColumn('Month', month(col("InvoiceDateKey"))) df.write.mode("overwrite").format("delta").partitionBy("Year","Quarter").save("Tables/" + table_name)Po načtení tabulek faktů můžete přejít na načítání dat pro zbytek dimenzí. Následující buňka vytvoří funkci pro čtení nezpracovaných dat z oddílu Files (Soubory ) jezerahouse pro každý název tabulky předaný jako parametr. Dále vytvoří seznam tabulek dimenzí. Nakonec projde seznamem tabulek a vytvoří tabulku Delta pro každý název tabulky, který se načte ze vstupního parametru. Všimněte si, že skript zahodí sloupec pojmenovaný
Photov tomto příkladu, protože se sloupec nepoužívá.from pyspark.sql.types import * def loadFullDataFromSource(table_name): df = spark.read.format("parquet").load('Files/wwi-raw-data/WideWorldImportersDW/parquet/full/' + table_name) df = df.drop("Photo") df.write.mode("overwrite").format("delta").save("Tables/" + table_name) full_tables = [ 'dimension_city', 'dimension_customer', 'dimension_date', 'dimension_employee', 'dimension_stock_item' ] for table in full_tables: loadFullDataFromSource(table)Chcete-li ověřit vytvořené tabulky, klikněte pravým tlačítkem myši a vyberte aktualizovat na wwilakehouse lakehouse . Zobrazí se tabulky.
Přejděte znovu do zobrazení položek pracovního prostoru a otevřete ho výběrem jezera wwilakehouse .
Teď otevřete druhý poznámkový blok. V zobrazení lakehouse vyberte Na pásu karet možnost Otevřít poznámkový blok Existující poznámkový>blok.
V seznamu existujících poznámkových bloků vyberte 02 – Transformace dat – Obchodní poznámkový blok a otevřete ho.
V otevřeném poznámkovém bloku v Průzkumníku jezera uvidíte, že poznámkový blok je už propojený s otevřeným lakehousem.
Organizace může mít datové inženýry, kteří pracují s jazykem Scala/Python a dalšími datovými inženýry pracujícími s SQL (Spark SQL nebo T-SQL), a to vše, co pracují na stejné kopii dat. Prostředky infrastruktury umožňují těmto různým skupinám, s různými zkušenostmi a předvolbami, pracovat a spolupracovat. Dva různé přístupy transformují a generují obchodní agregace. Můžete si vybrat ten vhodný pro vás nebo kombinovat a shodovat se s těmito přístupy na základě vašich preferencí bez ohrožení výkonu:
Přístup č. 1 – Použití PySparku ke spojení a agregaci dat pro generování obchodních agregací Tento přístup je vhodnější pro někoho, kdo má pozadí programování (Python nebo PySpark).
Přístup č. 2 – Připojení a agregace dat pro generování obchodních agregací pomocí Spark SQL Tento přístup je vhodnější pro někoho s pozadím SQL a přechodem na Spark.
Přístup č. 1 (sale_by_date_city) – K propojení a agregaci dat pro generování obchodních agregací použijte PySpark. Pomocí následujícího kódu vytvoříte tři různé datové rámce Sparku, z nichž každá odkazuje na existující tabulku Delta. Tyto tabulky pak spojíte pomocí datových rámců, seskupíte je za účelem vygenerování agregace, přejmenujete několik sloupců a nakonec je napíšete jako tabulku Delta v oddílu Tabulky v jezeře, aby se zachovala s daty.
V této buňce vytvoříte tři různé datové rámce Sparku, z nichž každý odkazuje na existující tabulku Delta.
df_fact_sale = spark.read.table("wwilakehouse.fact_sale") df_dimension_date = spark.read.table("wwilakehouse.dimension_date") df_dimension_city = spark.read.table("wwilakehouse.dimension_city")Přidejte následující kód do stejné buňky pro spojení těchto tabulek pomocí datových rámců vytvořených dříve. Seskupte agregaci, přejmenujte několik sloupců a nakonec je napište jako tabulku Delta v části Tabulky u jezera.
sale_by_date_city = df_fact_sale.alias("sale") \ .join(df_dimension_date.alias("date"), df_fact_sale.InvoiceDateKey == df_dimension_date.Date, "inner") \ .join(df_dimension_city.alias("city"), df_fact_sale.CityKey == df_dimension_city.CityKey, "inner") \ .select("date.Date", "date.CalendarMonthLabel", "date.Day", "date.ShortMonth", "date.CalendarYear", "city.City", "city.StateProvince", "city.SalesTerritory", "sale.TotalExcludingTax", "sale.TaxAmount", "sale.TotalIncludingTax", "sale.Profit")\ .groupBy("date.Date", "date.CalendarMonthLabel", "date.Day", "date.ShortMonth", "date.CalendarYear", "city.City", "city.StateProvince", "city.SalesTerritory")\ .sum("sale.TotalExcludingTax", "sale.TaxAmount", "sale.TotalIncludingTax", "sale.Profit")\ .withColumnRenamed("sum(TotalExcludingTax)", "SumOfTotalExcludingTax")\ .withColumnRenamed("sum(TaxAmount)", "SumOfTaxAmount")\ .withColumnRenamed("sum(TotalIncludingTax)", "SumOfTotalIncludingTax")\ .withColumnRenamed("sum(Profit)", "SumOfProfit")\ .orderBy("date.Date", "city.StateProvince", "city.City") sale_by_date_city.write.mode("overwrite").format("delta").option("overwriteSchema", "true").save("Tables/aggregate_sale_by_date_city")Přístup č. 2 (sale_by_date_employee) – Ke spojení a agregaci dat pro generování obchodních agregací použijte Spark SQL. Pomocí následujícího kódu vytvoříte dočasné zobrazení Sparku spojením tří tabulek, seskupením podle vygenerování agregace a přejmenováním několika sloupců. Nakonec načtete z dočasného zobrazení Sparku a nakonec ji zapíšete jako tabulku Delta v části Tabulky v lakehouse, aby se zachovala s daty.
V této buňce vytvoříte dočasné zobrazení Sparku spojením tří tabulek, seskupením podle vygenerování agregace a přejmenováním několika sloupců.
%%sql CREATE OR REPLACE TEMPORARY VIEW sale_by_date_employee AS SELECT DD.Date, DD.CalendarMonthLabel , DD.Day, DD.ShortMonth Month, CalendarYear Year ,DE.PreferredName, DE.Employee ,SUM(FS.TotalExcludingTax) SumOfTotalExcludingTax ,SUM(FS.TaxAmount) SumOfTaxAmount ,SUM(FS.TotalIncludingTax) SumOfTotalIncludingTax ,SUM(Profit) SumOfProfit FROM wwilakehouse.fact_sale FS INNER JOIN wwilakehouse.dimension_date DD ON FS.InvoiceDateKey = DD.Date INNER JOIN wwilakehouse.dimension_Employee DE ON FS.SalespersonKey = DE.EmployeeKey GROUP BY DD.Date, DD.CalendarMonthLabel, DD.Day, DD.ShortMonth, DD.CalendarYear, DE.PreferredName, DE.Employee ORDER BY DD.Date ASC, DE.PreferredName ASC, DE.Employee ASCV této buňce si přečtete z dočasného zobrazení Sparku vytvořeného v předchozí buňce a nakonec ji napíšete jako tabulku Delta v části Tabulky u jezerahouse.
sale_by_date_employee = spark.sql("SELECT * FROM sale_by_date_employee") sale_by_date_employee.write.mode("overwrite").format("delta").option("overwriteSchema", "true").save("Tables/aggregate_sale_by_date_employee")Chcete-li ověřit vytvořené tabulky, klikněte pravým tlačítkem myši a vyberte Aktualizovat na wwilakehouse lakehouse . Zobrazí se agregační tabulky.
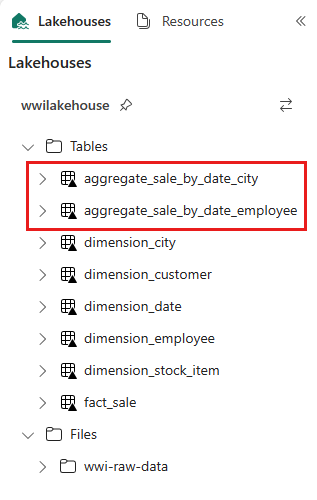
Oba přístupy vytvářejí podobný výsledek. Pokud chcete minimalizovat potřebu naučit se novou technologii nebo ohrozit výkon, zvolte přístup, který nejlépe vyhovuje vašemu pozadí a předvolbám.
Možná si všimnete, že zapisujete data jako soubory Delta Lake. Funkce automatického zjišťování a registrace tabulek v Prostředcích infrastruktury je vybere a zaregistruje v metastoru. K vytváření tabulek pro použití s SQL nemusíte explicitně volat CREATE TABLE příkazy.