Generování sestav fakturace a využití pro Apache Spark v Microsoft Fabric
Platí pro:✅ Datoví technici ing a Datová Věda v Microsoft Fabric
Tento článek vysvětluje využití výpočetních prostředků a vytváření sestav pro ApacheSpark, které pohání úlohy Fabric Datoví technici a vědy v Microsoft Fabric. Využití výpočetních prostředků zahrnuje operace lakehouse, jako je table Preview, načtení do rozdílu, spuštění poznámkového bloku z rozhraní, naplánovaná spuštění, spuštění aktivovaná kroky poznámkového bloku v kanálech a spuštění definice úlohy Apache Spark.
Stejně jako u jiných prostředí v Microsoft Fabric používá Datoví technici ke spuštění této úlohy také kapacitu přidruženou k pracovnímu prostoru a celkové poplatky za kapacitu se zobrazí na webu Azure Portal v rámci vašeho předplatného Microsoft Cost Management. Další informace o fakturaci prostředků infrastruktury najdete v tématu Vysvětlení informací na faktuře za Azure v kapacitě Fabric.
Kapacita prostředků infrastruktury
Jako uživatel můžete zakoupit kapacitu Prostředků infrastruktury z Azure zadáním předplatného Azure. Velikost kapacity určuje množství výpočetního výkonu, který je k dispozici. Pro Apache Spark for Fabric se každá zakoupená CU přeloží na 2 virtuální jádra Apache Sparku. Pokud například zakoupíte kapacitu Infrastruktury F128, převede se to na 256 SparkVCores. Kapacita prostředků infrastruktury se sdílí napříč všemi přidanými pracovními prostory a v nichž se celkový povolený výpočetní výkon Apache Sparku sdílí mezi všemi úlohami odeslaným ze všech pracovních prostorů přidružených ke kapacitě. Vysvětlení různých skladových položek, přidělení jader a omezování ve Sparku najdete v tématu Omezení souběžnosti a zařazování do fronty v Apache Sparku pro Microsoft Fabric.
Konfigurace výpočetních prostředků Sparku a zakoupená kapacita
Výpočetní prostředí Apache Spark pro Prostředky infrastruktury nabízí dvě možnosti, pokud jde o konfiguraci výpočetních prostředků.
Úvodní fondy: Tyto výchozí fondy jsou rychlé a snadné použití Sparku na platformě Microsoft Fabric během několika sekund. Relace Sparku můžete hned používat, a nemusíte čekat, až Spark nastaví uzly za vás, což vám pomůže s daty dělat víc a rychleji získat přehledy. Pokud jde o fakturaci a spotřebu kapacity, účtují se vám poplatky, když začnete spouštět poznámkový blok nebo definici úlohy Sparku nebo operaci lakehouse. Za dobu nečinnosti clusterů ve fondu se vám neúčtují poplatky.
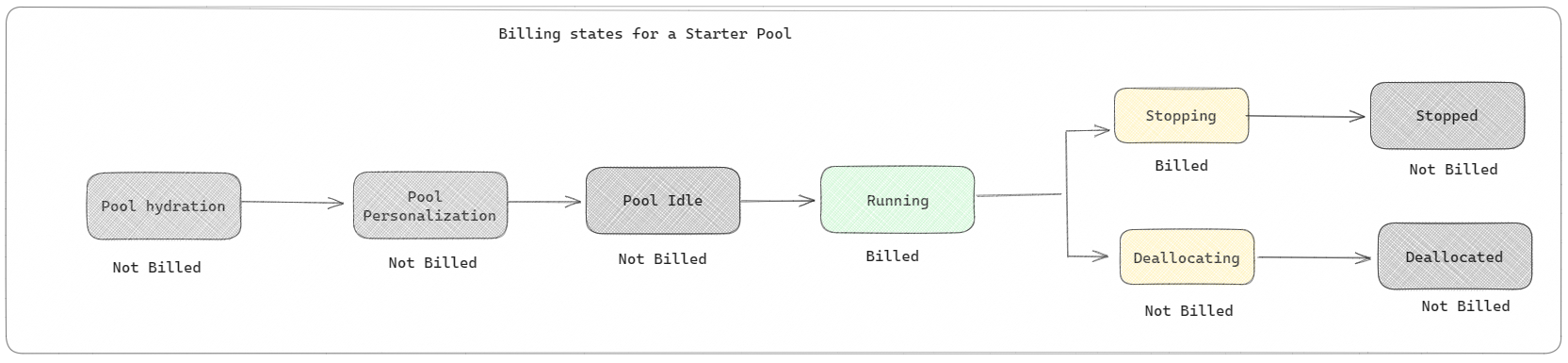
Pokud například odešlete úlohu poznámkového bloku do počátečního fondu, účtuje se vám jenom časové období, ve kterém je relace poznámkového bloku aktivní. Fakturovaný čas nezahrnuje dobu nečinnosti ani čas potřebný k přizpůsobení relace s kontextem Sparku. Další informace o konfiguraci počátečních fondů na základě zakoupené skladové položky kapacity infrastruktury najdete v tématu Konfigurace počátečních fondů založených na kapacitě prostředků infrastruktury.
Fondy Sparku: Jedná se o vlastní fondy, kde si můžete přizpůsobit velikost prostředků, které potřebujete pro úlohy analýzy dat. Fond Sparku můžete pojmenovat a zvolit, kolik a kolik uzlů (počítačů, které dělají práci) jsou. Sparku také můžete říct, jak upravit počet uzlů v závislosti na tom, kolik práce máte. Vytvoření fondu Sparku je zdarma; platíte jenom v případě, že ve fondu spustíte úlohu Sparku a pak Spark nastaví uzly za vás.
- Velikost a počet uzlů, které můžete mít ve vlastním fondu Sparku, závisí na vaší kapacitě Microsoft Fabric. Pomocí těchto virtuálních jader Sparku můžete vytvořit uzly různých velikostí pro vlastní fond Sparku, pokud celkový počet virtuálních jader Sparku nepřekračuje 128.
- Fondy Sparku se účtují jako počáteční fondy; Za vlastní fondy Sparku, které jste vytvořili, neplatíte, pokud nemáte vytvořenou aktivní relaci Sparku pro spuštění poznámkového bloku nebo definice úlohy Sparku. Účtuje se vám jenom doba trvání spuštění úlohy. Po dokončení úlohy se vám neúčtují fáze, jako je vytvoření clusteru a uvolnění.
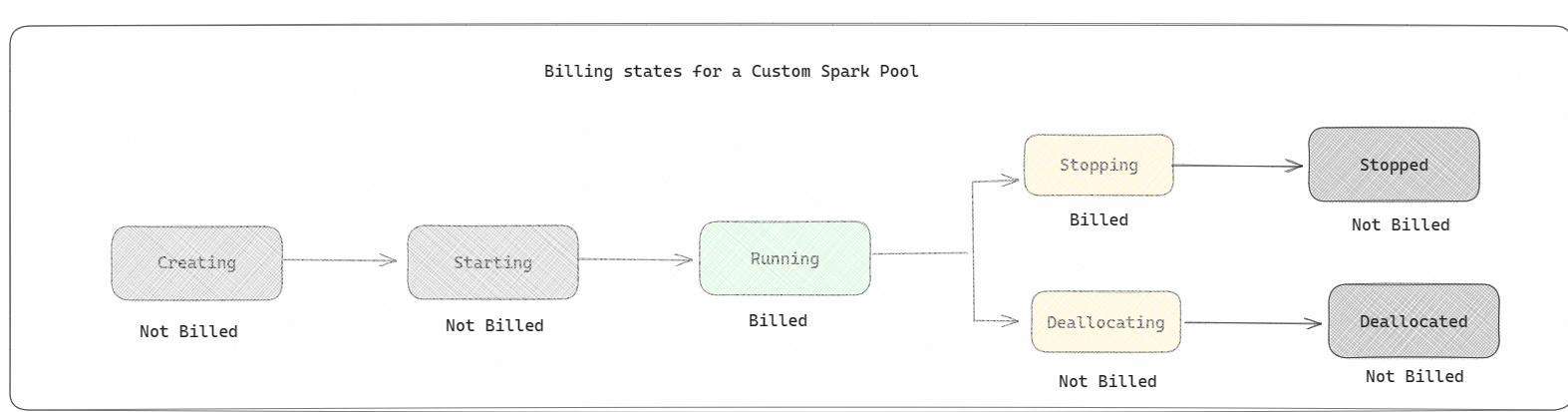
Pokud například odešlete úlohu poznámkového bloku do vlastního fondu Sparku, bude se vám účtovat jenom časové období, kdy je relace aktivní. Fakturace pro danou relaci poznámkového bloku se zastaví, jakmile se relace Sparku zastaví nebo vyprší jeho platnost. Za dobu potřebnou k získání instancí clusteru z cloudu ani za dobu potřebnou k inicializaci kontextu Sparku se vám neúčtují poplatky. Další informace o konfiguraci fondů Sparku na základě zakoupené skladové položky kapacity prostředků infrastruktury najdete v tématu Konfigurace fondů na základě kapacity prostředků infrastruktury.


Poznámka:
Výchozí časové období vypršení platnosti relace pro počáteční fondy a fondy Sparku, které vytvoříte, je nastavené na 20 minut. Pokud fond Sparku nepoužíváte 2 minuty po vypršení platnosti relace, váš fond Sparku se uvolní. Pokud chcete ukončit relaci a fakturaci po dokončení provádění poznámkového bloku před vypršením časového období relace, můžete buď kliknout na tlačítko zastavit relaci z domovské nabídky poznámkových bloků, nebo přejít na stránku centra monitorování a zastavit relaci tam.
Generování sestav využití výpočetních prostředků Sparku
Aplikace Microsoft Fabric Capacity Metrics poskytuje přehled o využití kapacity pro všechny úlohy Infrastruktury na jednom místě. Správci kapacity ji používají ke sledování výkonu úloh a jejich využití v porovnání s zakoupenou kapacitou.
Po instalaci aplikace vyberte typ položky Notebook, Lakehouse, Definice úlohy Spark z rozevíracího seznamu Vybrat typ položky: Graf pásového grafu s více metrikou je teď možné upravit na požadovaný časový rámec, abyste porozuměli využití všech těchto vybraných položek.
Všechny operace související se Sparkem jsou klasifikovány jako operace na pozadí. Spotřeba kapacity ze Sparku se zobrazuje v poznámkovém bloku, v definici úlohy Sparku nebo v jezeře a agreguje se podle názvu operace a položky. Například: Pokud spustíte úlohu poznámkového bloku, zobrazí se spuštění poznámkového bloku, jednotky CU používané poznámkovým blokem (celkový počet virtuálních jader Sparku/2 jako 1 CU poskytuje 2 virtuální jádra Sparku), doba trvání, kterou úloha přijala v sestavě.
 Další informace o generování sestav využití kapacity Sparku najdete v tématu Monitorování spotřeby kapacity Apache Sparku.
Další informace o generování sestav využití kapacity Sparku najdete v tématu Monitorování spotřeby kapacity Apache Sparku.
Příklad fakturace
Zvažte následující scénář:
Existuje kapacita C1, která hostuje pracovní prostor infrastruktury W1 a tento pracovní prostor obsahuje Lakehouse LH1 a Notebook NB1.
- Jakákoli operace Sparku, kterou poznámkový blok (NB1) nebo lakehouse (LH1) provádí, se hlásí vůči kapacitě C1.
Rozšíření tohoto příkladu na scénář, kdy existuje další kapacita C2, která hostuje pracovní prostor prostředků infrastruktury W2, a řekněme, že tento pracovní prostor obsahuje definici úlohy Sparku (SJD1) a Lakehouse (LH2).
- Pokud definice úlohy Sparku (SDJ2) z pracovního prostoru (W2) čte data z lakehouse (LH1), ohlašuje se využití s kapacitou C2, která je přidružená k pracovnímu prostoru (W2), který danou položku hostuje.
- Pokud poznámkový blok (NB1) provádí operaci čtení z Lakehouse(LH2), je spotřeba kapacity hlášena vůči kapacitě C1, která spouští pracovní prostor W1, který je hostitelem položky poznámkového bloku.