Datoví technici nastavení správy pracovního prostoru v Microsoft Fabric
Platí pro:✅ Datoví technici ing a Datová Věda v Microsoft Fabric
Při vytváření pracovního prostoru v Microsoft Fabric se automaticky vytvoří počáteční fond přidružený k housku. Díky zjednodušenému nastavení v Microsoft Fabric nemusíte vybírat uzly nebo velikosti počítačů, protože tyto možnosti se zpracovávají na pozadí. Tato konfigurace poskytuje rychlejší (5 až 10sekundové) prostředí spuštění relace Apache Sparku pro uživatele, aby mohli začít a spouštět úlohy Apache Sparku v mnoha běžných scénářích, aniž byste se museli starat o nastavení výpočetních prostředků. V případě pokročilých scénářů s konkrétními požadavky na výpočetní prostředky můžou uživatelé vytvořit vlastní fond Apache Sparku a nastavit velikost uzlů na základě jejich požadavků na výkon.
Pokud chcete provést změny nastavení Apache Sparku v pracovním prostoru, měli byste mít pro tento pracovní prostor roli správce. Další informace najdete v tématu Role v pracovních prostorech.
Správa nastavení Sparku pro fond přidružený k vašemu pracovnímu prostoru:
Přejděte do nastavení pracovního prostoru v pracovním prostoru a výběrem možnosti Datoví technici/Věda rozbalte nabídku:
V nabídce vlevo se zobrazí možnost Spark Compute :
Poznámka:
Pokud změníte výchozí fond z počátečního fondu na vlastní fond Sparku, může se zobrazit delší spuštění relace (přibližně 3 minuty).

Fond
Výchozí fond pro pracovní prostor
Můžete použít automaticky vytvořený počáteční fond nebo vytvořit vlastní fondy pro pracovní prostor.
Počáteční fond: Předem dosazené živé fondy se automaticky vytvořily pro vaše rychlejší prostředí. Tyto clustery mají střední velikost. Počáteční fond je nastavený na výchozí konfiguraci na základě zakoupené skladové položky kapacity Fabric. Správci můžou přizpůsobit maximální počet uzlů a exekutorů na základě požadavků na škálování úloh Sparku. Další informace najdete v tématu Konfigurace úvodních fondů.
Vlastní fond Sparku: Uzly, automatické škálování a dynamicky přidělovat exekutory na základě vašich požadavků na úlohu Sparku můžete nastavit velikost. Pokud chcete vytvořit vlastní fond Sparku, správce kapacity by měl povolit možnost Přizpůsobené fondy pracovních prostorů v části Výpočty Sparku v nastavení správce kapacity.
Poznámka:
Řízení na úrovni kapacity pro vlastní fondy pracovních prostorů je ve výchozím nastavení povolené. Další informace najdete v tématu Konfigurace a správa nastavení přípravy dat a datových věd pro kapacity Fabric.
Správci můžou vytvářet vlastní fondy Sparku na základě svých požadavků na výpočetní prostředky výběrem možnosti Nový fond .

Apache Spark pro Microsoft Fabric podporuje clustery s jedním uzlem, což uživatelům umožňuje vybrat minimální konfiguraci uzlu 1 v takovém případě, že ovladač a exekutor běží v jednom uzlu. Tyto clustery s jedním uzlem nabízejí obnovitelnou vysokou dostupnost během selhání uzlů a lepší spolehlivost úloh pro úlohy s menšími požadavky na výpočetní prostředky. Můžete také povolit nebo zakázat možnost automatického škálování pro vlastní fondy Sparku. Pokud je povoleno automatické škálování, fond získá nové uzly v rámci maximálního limitu uzlu určeného uživatelem a vyřadí je po spuštění úlohy, aby byl výkon lepší.
Můžete také vybrat možnost dynamicky přidělovat exekutory do fondu automaticky optimální počet exekutorů v maximální mezí zadané závislosti na datovém svazku pro lepší výkon.

Přečtěte si další informace o výpočetních prostředcích Apache Sparku pro Prostředky infrastruktury.
- Přizpůsobení konfigurace výpočetních prostředků pro položky: Jako správce pracovního prostoru můžete uživatelům povolit úpravu výpočetních konfigurací (vlastnosti na úrovni relace, které zahrnují Driver/Executor Core, Driver/Executor Memory) pro jednotlivé položky, jako jsou poznámkové bloky, definice úloh Sparku pomocí prostředí.
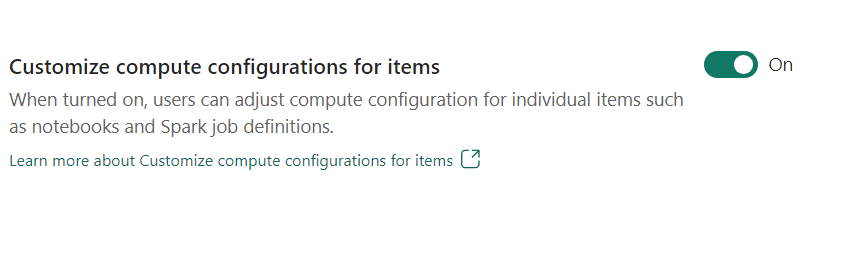
Pokud správce pracovního prostoru toto nastavení vypne, použije se výchozí fond a jeho konfigurace výpočetních prostředků pro všechna prostředí v pracovním prostoru.
Prostředí
Prostředí poskytuje flexibilní konfigurace pro spouštění úloh Sparku (poznámkové bloky, definice úloh Sparku). V prostředí můžete nakonfigurovat vlastnosti výpočetních prostředků, vybrat jiný modul runtime, nastavit závislosti balíčků knihoven na základě vašich požadavků na úlohy.
Na kartě prostředí máte možnost nastavit výchozí prostředí. Můžete zvolit, jakou verzi Sparku chcete pro pracovní prostor použít.
Jako správce pracovního prostoru Fabric můžete jako výchozí prostředí pracovního prostoru vybrat prostředí.
Nový můžete vytvořit také v rozevíracím seznamu Prostředí .

Pokud možnost zakázat výchozí prostředí, máte možnost vybrat verzi modulu runtime Fabric z dostupných verzí modulu runtime uvedených v rozevíracím seznamu.

Přečtěte si další informace o modulech runtime Apache Sparku.
Úlohy
Nastavení úloh umožňuje správcům řídit logiku přístupu úlohy pro všechny úlohy Sparku v pracovním prostoru.

Ve výchozím nastavení jsou u všech pracovních prostorů povolená optimistická přístupová úloha. Přečtěte si další informace o přijetí úloh pro Spark v Microsoft Fabric.
Pro aktivní úlohy Sparku můžete povolit maximální počet jader pro aktivní úlohy Sparku, abyste se mohli obrátit na přístup založený na optimistické úloze a vyhraďte si maximální počet jader pro úlohy Sparku.
Můžete také nastavit časový limit relace Sparku, abyste přizpůsobili vypršení platnosti relace pro všechny interaktivní relace poznámkového bloku.
Poznámka:
Výchozí vypršení platnosti relace je pro interaktivní relace Sparku nastavené na 20 minut.
Vysoká souběžnost
Režim vysoké souběžnosti umožňuje uživatelům sdílet stejné relace Sparku v Apache Sparku pro úlohy přípravy dat a datových věd. Položka, jako je poznámkový blok, používá ke spuštění relaci Sparku a když je tato možnost povolená, umožňuje uživatelům sdílet jednu relaci Sparku napříč několika poznámkovými bloky.

Přečtěte si další informace o vysoké souběžnosti v Apache Sparku for Fabric.
Automatické protokolování pro modely a experimenty služby Machine Learning
Správci teď můžou povolit automatické protokolování pro své modely a experimenty strojového učení. Tato možnost automaticky zaznamenává hodnoty vstupních parametrů, výstupních metrik a výstupních položek modelu strojového učení při trénování. Přečtěte si další informace o automatickémlogování.

Související obsah
- Přečtěte si o modulech Runtime Apache Spark v prostředcích infrastruktury – přehled, správa verzí, podpora více modulů runtime a upgrade protokolu Delta Lake.
- Další informace najdete ve veřejné dokumentaci k Apache Sparku.
- Najděte odpovědi na nejčastější dotazy: Nejčastější dotazy k nastavení správy pracovních prostorů Apache Sparku.