Databáze Access Lake využívající bezserverový fond SQL
Pracovní prostor Azure Synapse Analytics umožňuje vytvořit dva typy databází nad datovým jezerem Spark:
- Databáze Lake, ve kterých můžete definovat tabulky nad daty lake pomocí poznámkových bloků Apache Sparku, databázových šablon nebo Microsoft Dataverse (dříve Common Data Service). Tyto tabulky je možné dotazovat pomocí jazyka T-SQL (Transact-SQL) pomocí bezserverového fondu SQL.
- Databáze SQL, ve kterých můžete definovat vlastní databáze a tabulky přímo pomocí bezserverového fondu SQL. Pomocí funkce T-SQL CREATE DATABASE, CREATE EXTERNAL TABLE můžete definovat objekty a přidat do tabulek další zobrazení, procedury a funkce vložené tabulky.
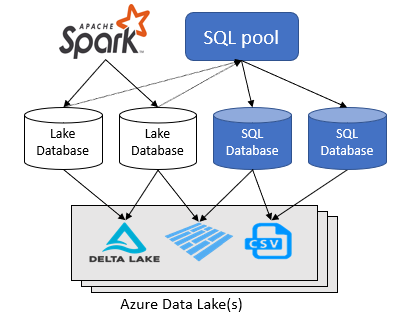
Tento článek se zaměřuje na databáze lake v bezserverovém fondu SQL ve službě Azure Synapse Analytics.
Azure Synapse Analytics umožňuje vytvářet databáze a tabulky lake pomocí Návrháře sparku nebo databáze a pak analyzovat data v databázích lake pomocí bezserverového fondu SQL. Databáze lake a tabulky (parketové nebo sdílené svazky clusteru), které se vytvářejí ve fondech Apache Sparku, šablonách databáze lake nebo Dataverse, jsou automaticky k dispozici pro dotazování pomocí bezserverového modulu fondu SQL. Databáze a tabulky lake, které jsou upraveny, jsou po nějaké době dostupné v bezserverovém fondu SQL. Dochází ke zpoždění, dokud se změny provedené v návrháři sparku nebo databáze nezobrazí v bezserverové verzi.
Správa databáze Lake
Ke správě databází Lake vytvořených Sparkem můžete použít fondy Apache Sparku nebo návrháře databází. Můžete například vytvořit nebo odstranit databázi lake prostřednictvím úlohy fondu Spark. Databázi lake nebo objekty v databázích lake nemůžete vytvořit pomocí bezserverového fondu SQL.
Databáze Spark default je k dispozici v kontextu bezserverového fondu SQL jako databáze lake s názvem default.
Poznámka:
Nemůžete vytvořit jezero a databázi SQL v bezserverovém fondu SQL se stejným názvem.
Tabulky v databázích lake nelze upravovat z bezserverového fondu SQL. K úpravě databáze jezero použijte návrháře databáze nebo fondy Apache Sparku. Bezserverový fond SQL umožňuje provádět v databázi lake následující změny pomocí příkazů T-SQL:
- Přidání, změna a vyřazení zobrazení, procedur, vložených funkcí hodnoty tabulky v databázi lake
- Přidání a odebrání uživatelů Microsoft Entra v oboru databáze
- Přidejte nebo odeberte uživatele databáze Microsoft Entra do role db_datareader . Uživatelé databáze Microsoft Entra v roli db_datareader mají oprávnění ke čtení všech tabulek v databázi lake, ale nemůžou číst data z jiných databází.
Model zabezpečení
Databáze a tabulky lake jsou zabezpečené na dvou úrovních:
- Základní vrstva úložiště tím, že přiřadíte uživatelům Microsoft Entra jednu z následujících možností:
- Řízení přístupu Azure na základě rolí (Azure RBAC)
- Role řízení přístupu na základě atributů Azure (Azure ABAC)
- Oprávnění seznamu řízení přístupu (ACL)
- Vrstva SQL, ve které můžete definovat uživatele Microsoft Entra a udělit oprávnění
SELECTSQL k datům z tabulek odkazujících na data lake.
Model zabezpečení Lake
Přístup k databázovým souborům lake se řídí pomocí oprávnění lake ve vrstvě úložiště. Tabulky v databázích lake můžou používat jenom uživatelé Microsoft Entra a k datům v jezeře mají přístup pomocí vlastních identit.
Přístup k podkladovým datům používaným pro externí tabulky můžete udělit instančnímu objektu zabezpečení, například uživateli, aplikaci Microsoft Entra s přiřazeným instančním objektem nebo skupinou zabezpečení. Pro přístup k datům udělte obě následující oprávnění:
- Udělte
read (R)oprávnění k souborům (například podkladovým datovým souborům tabulky). - Udělte
execute (X)oprávnění ke složce, ve které jsou soubory uložené, a ve všech nadřazených složkách až do kořenové složky. Další informace o těchto oprávněních najdete v seznamech řízení přístupu (ACL).
Například v https://<storage-name>.dfs.core.windows.net/<fs>/synapse/workspaces/<synapse_ws>/warehouse/mytestdb.db/myparquettable/objektech zabezpečení jsou potřeba:
-
execute (X)oprávnění ke všem složkám, které začínají na<fs>kartěmyparquettable. -
read (R)oprávnění kmyparquettablesouborům a souborům v této složce, aby bylo možné číst tabulku v databázi (synchronizované nebo původní).
Pokud objekt zabezpečení vyžaduje schopnost vytvářet objekty nebo odstraňovat objekty v databázi, jsou pro složky a soubory ve složce skladu vyžadována další write (W) oprávnění. Úpravy objektů v databázi není možné z bezserverového fondu SQL, pouze z fondů Sparku nebo návrháře databáze.
Model zabezpečení SQL
Pracovní prostor Azure Synapse poskytuje koncový bod T-SQL, který umožňuje dotazovat databázi lake pomocí bezserverového fondu SQL. Kromě přístupu k datům umožňuje rozhraní SQL řídit, kdo má k tabulkám přístup. Potřebujete uživateli povolit přístup ke sdíleným databázím lake pomocí bezserverového fondu SQL. Existují dva typy uživatelů, kteří mají přístup k databázím lake:
- Správci: Přiřaďte roli pracovního prostoru Správce Synapse SQL nebo roli na úrovni serveru sysadmin v bezserverovém fondu SQL. Tato role má plnou kontrolu nad všemi databázemi. Role Správce Synapse a Synapse SQL mají ve výchozím nastavení všechna oprávnění pro všechny objekty v bezserverovém fondu SQL.
- Čtenáři pracovního prostoru: Udělte oprávnění na úrovni serveru UDĚLIT OPRÁVNĚNÍ PŘIPOJIT LIBOVOLNOU DATABÁZI a UDĚLIT MOŽNOST VYBRAT VŠECHNY UŽIVATELE SECURABLES v bezserverovém fondu SQL pro přihlášení, které umožňuje přihlášení pro přístup k jakékoli databázi a čtení jakékoli databáze. To může být dobrá volba pro přiřazení přístupu čtenáře nebo správce k uživateli.
- Čtenáři databáze: Vytvořte uživatele databáze z Microsoft Entra ID v databázi lake a přidejte je do db_datareader role, která jim umožňuje číst data v databázi lake.
Přečtěte si další informace o nastavení řízení přístupu u sdílených databází.
Vlastní objekty SQL v databázích lake
Databáze Lake umožňují vytvářet vlastní objekty T-SQL, jako jsou schémata, procedury, zobrazení a vložené funkce tabulek (iTVFs). Chcete-li vytvořit vlastní objekty SQL, musíte vytvořit schéma, kam umístíte objekty. Vlastní objekty SQL nelze umístit do dbo schématu, protože jsou vyhrazené pro tabulky lake definované ve Sparku, návrháři databáze nebo Dataverse.
Důležité
Musíte vytvořit vlastní schéma SQL, kam umístíte objekty SQL. Vlastní objekty SQL nelze umístit do schématu dbo . Schéma dbo je vyhrazené pro tabulky lake, které se původně vytvořily v návrháři sparku nebo databáze.
Příklady
Vytvoření čtečky databáze SQL v databázi Lake
V tomto příkladu přidáme uživatele Microsoft Entra do databáze lake, který může číst data prostřednictvím sdílených tabulek. Uživatelé se přidají do databáze lake prostřednictvím bezserverového fondu SQL. Potom uživateli přiřaďte roli db_datareader , aby mohl číst data.
CREATE USER [customuser@contoso.com] FROM EXTERNAL PROVIDER;
GO
ALTER ROLE db_datareader
ADD MEMBER [customuser@contoso.com];
Vytvoření čtečky dat na úrovni pracovního prostoru
Přihlášení s oprávněními GRANT CONNECT ANY DATABASEGRANT SELECT ALL USER SECURABLES umožňuje číst všechny tabulky pomocí bezserverového fondu SQL, ale nemůže vytvářet databáze SQL nebo upravovat objekty v nich.
CREATE LOGIN [wsdatareader@contoso.com] FROM EXTERNAL PROVIDER
GRANT CONNECT ANY DATABASE TO [wsdatareader@contoso.com]
GRANT SELECT ALL USER SECURABLES TO [wsdatareader@contoso.com]
Tento skript umožňuje vytvářet uživatele bez oprávnění správce, kteří mohou číst libovolnou tabulku v databázích Lake.
Vytvoření a připojení k databázi Sparku s bezserverovým fondem SQL
Nejprve vytvořte novou databázi Spark s názvem mytestlakedb pomocí clusteru Spark, který jste už vytvořili ve svém pracovním prostoru. Toho můžete dosáhnout například pomocí poznámkového bloku Spark C# s následujícím příkazem .NET for Spark:
spark.sql("CREATE DATABASE mytestlakedb")
Po krátké prodlevě uvidíte databázi Lake z bezserverového fondu SQL. Spusťte například následující příkaz z bezserverového fondu SQL.
SELECT * FROM sys.databases;
Ověřte, že mytestlakedb je součástí výsledků.
Vytváření vlastních objektů SQL v databázi Lake
Následující příklad ukazuje, jak vytvořit vlastní zobrazení, proceduru a vloženou funkci table-value (iTVF) ve schématu reports :
CREATE SCHEMA reports
GO
CREATE OR ALTER VIEW reports.GreenReport
AS SELECT puYear, puMonth,
fareAmount = SUM(fareAmount),
tipAmount = SUM(tipAmount),
mtaTax = SUM(mtaTax)
FROM dbo.green
GROUP BY puYear, puMonth
GO
CREATE OR ALTER PROCEDURE reports.GreenReportSummary
AS BEGIN
SELECT puYear, puMonth,
fareAmount = SUM(fareAmount),
tipAmount = SUM(tipAmount),
mtaTax = SUM(mtaTax)
FROM dbo.green
GROUP BY puYear, puMonth
END
GO
CREATE OR ALTER FUNCTION reports.GreenDataReportMonthly(@year int)
RETURNS TABLE
RETURN ( SELECT puYear = @year, puMonth,
fareAmount = SUM(fareAmount),
tipAmount = SUM(tipAmount),
mtaTax = SUM(mtaTax)
FROM dbo.green
WHERE puYear = @year
GROUP BY puMonth )
GO
Související obsah
- Sdílená metadata služby Azure Synapse Analytics
- Sdílené tabulky metadat služby Azure Synapse Analytics
- Rychlý start: Vytvoření nové databáze Lake s využitím šablon databází
- Kurz: Použití bezserverového fondu SQL v Power BI Desktopu a vytvoření sestavy
- Synchronizace definic externích tabulek Apache Spark pro Azure Synapse v bezserverovém fondu SQL
- Kurz: Zkoumání a analýza datových jezer pomocí bezserverového fondu SQL