Databáze Lake
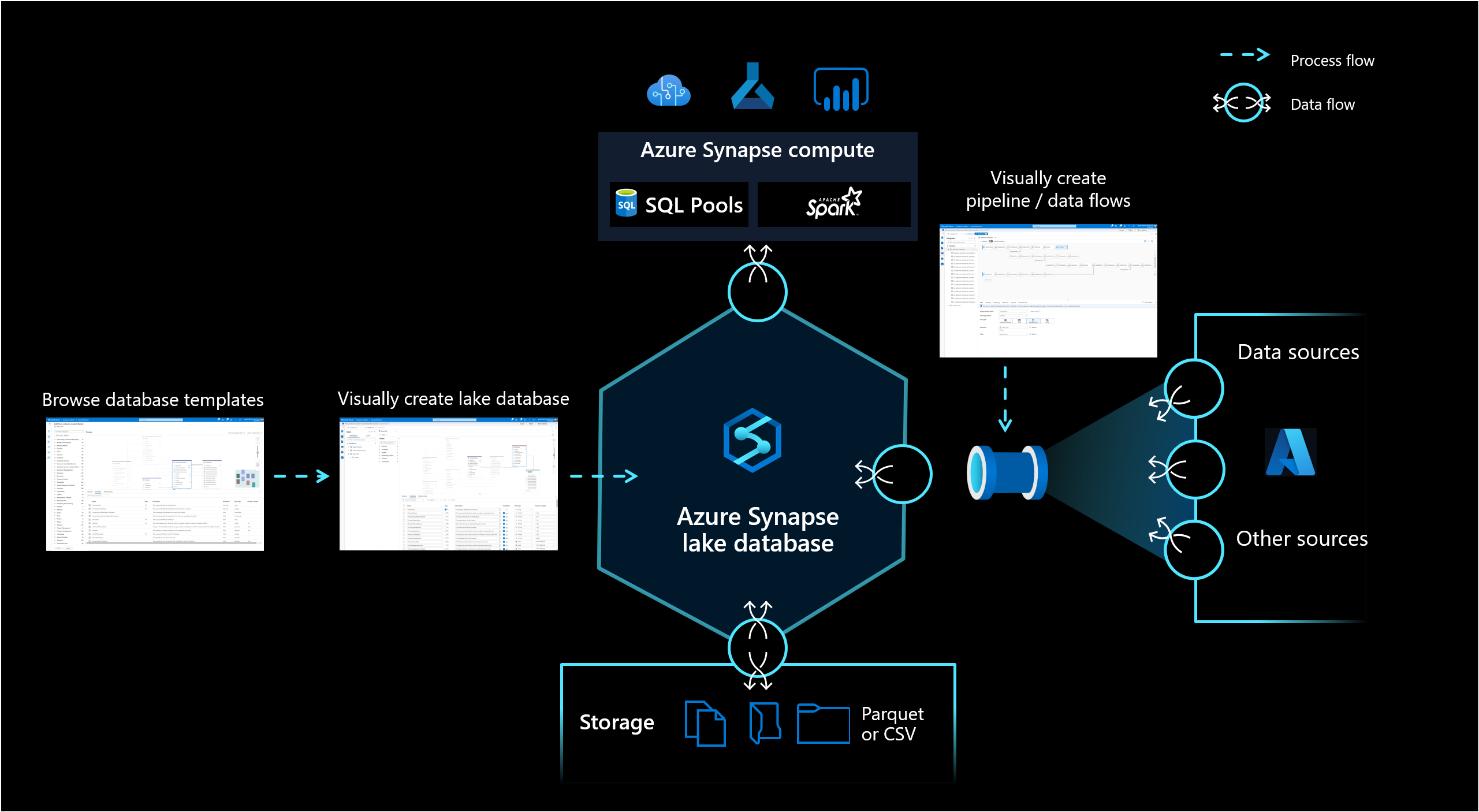
Databáze Lake ve službě Azure Synapse Analytics umožňuje zákazníkům spojit návrh databáze, meta informace o uložených datech a možnost popsat, jak a kde se mají data ukládat. Databáze Lake řeší výzvu dnešních datových jezer, kde je obtížné pochopit, jak jsou data strukturovaná.
Návrhář databáze
Nový návrhář databáze v nástroji Synapse Studio umožňuje vytvořit datový model pro databázi lake a přidat do ní další informace. Každou entitu a atribut lze popsat tak, aby poskytovaly další informace o modelu, které nejen obsahují entity, ale také relace. Konkrétně je nemožnost modelovat relace výzvou pro interakci s datovým jezerem. Tento problém je nyní řešen integrovaným návrhářem, který poskytuje možnosti dostupné v databázích, ale ne v jezeře. Možnost přidat do modelu také popisy a možné ukázkové hodnoty umožňuje uživatelům, kteří s ním v budoucnu pracují, získat informace, kde je potřebují, aby lépe porozuměli datům.
Poznámka:
Maximální velikost metadat v databázi lake je 10 GB. Pokus o publikování nebo aktualizaci modelu, který překračuje velikost 10 GB, selže. Pokud chcete tento problém vyřešit, snižte velikost modelu odebráním tabulek a sloupců. Zvažte rozdělení velkých modelů do několika databází lake, abyste se tomuto limitu vyhnuli.
Úložiště dat
Databáze Lake používají datové jezero v účtu Azure Storage k ukládání dat databáze. Data je možné uložit ve formátu Parquet, Delta nebo CSV a k optimalizaci úložiště je možné použít různá nastavení. Každá databáze lake používá propojenou službu k definování umístění kořenové složky dat. Pro každou entitu se ve výchozím nastavení vytvoří samostatné složky v této složce databáze v datovém jezeře. Ve výchozím nastavení všechny tabulky v databázi lake používají stejný formát, ale v případě požadavku na entitu je možné změnit formáty a umístění dat.
Poznámka:
Publikování databáze lake nevytvoří žádnou z podkladových struktur ani schémat potřebných k dotazování dat ve Sparku nebo SQL. Po publikování načtěte data do databáze lake pomocí kanálů a začněte je dotazovat.
Podpora formátu Delta pro databáze lake se v současné době nepodporuje ve službě Synapse Studio.
Synchronizace databázových objektů lake mezi úložištěm a Synapse je jednosměrná. Ujistěte se, že v nástroji Synapse Studio provedete jakékoli změny vytváření nebo schématu databázových objektů lake pomocí návrháře databáze. Pokud místo toho provedete takové změny ze Sparku nebo přímo v úložišti, definice databází lake se přestanou synchronizovat. Pokud k tomu dojde, může se v návrháři databáze zobrazit stará definice databáze Lake. Aby se databáze lake synchronizovaly, budete muset tyto změny replikovat a publikovat v návrháři databáze.
Výpočetní prostředky databáze
Databáze Lake je vystavená v bezserverovém fondu SQL Synapse SQL a Apache Sparku, který uživatelům poskytuje možnost oddělit úložiště od výpočetních prostředků. Metadata přidružená k databázi lake usnadňují různým výpočetním modulům nejen integrované prostředí, ale také použití dalších informací (například relací), které nebyly původně podporovány v datovém jezeře.
Související obsah
Pokračujte v prozkoumání možností návrháře databáze pomocí následujících odkazů.