Takže se chcete dozvědět o Service Fabric?
Azure Service Fabric je platforma distribuovaných systémů usnadňující balení, nasazování a spravování škálovatelných a spolehlivých mikroslužeb. Service Fabric má ale velkou plochu a je tu hodně, co se naučit. Tento článek obsahuje souhrn Service Fabric a popisuje základní koncepty, programovací modely, životní cyklus aplikací, testování, clustery a monitorování stavu. Přečtěte si přehled a co jsou mikroslužby? Úvod a způsob použití Service Fabric k vytváření mikroslužeb. Tento článek neobsahuje komplexní seznam obsahu, ale odkazuje na přehled a články Začínáme pro každou oblast Service Fabric.
Klíčové koncepty
Terminologie Service Fabric, aplikační model a podporované programovací modely poskytují více konceptů a popisů, ale tady jsou základy.
- Cluster Service Fabric: Na tomto odkazu najdete školicí video, kde najdete úvod do architektury Service Fabric a jejích základních konceptů a prozkoumání mnoha funkcí Service Fabric.
- Koncepty modulu runtime: V tomto odkazu najdete školicí video, kde najdete vysvětlení konceptů modulu runtime a osvědčených postupů Service Fabric.
- Koncepty typu návrhu: Na tomto odkazu najdete školicí video, které vám umožní porozumět aplikacím, balení a nasazení, klíčové terminologii Service Fabric, abstrakce a koncepty.
Čas návrhu: typ služby, balíček služby a manifest, typ aplikace, balíček aplikace a manifest
Typ služby je název/verze přiřazená balíčkům kódu, datovým balíčkům a konfiguračním balíčkům služby. Toto je definováno v souboru ServiceManifest.xml. Typ služby se skládá ze spustitelného kódu a nastavení konfigurace služby, která se načítají za běhu, a statických dat, která služba využívá.
Balíček služby je adresář disku obsahující soubor typu služby ServiceManifest.xml, který odkazuje na kód, statická data a konfigurační balíčky pro typ služby. Například balíček služby může odkazovat na kód, statická data a konfigurační balíčky, které tvoří databázovou službu.
Typ aplikace je název/verze přiřazená kolekci typů služeb. Toto je definováno v souboru ApplicationManifest.xml.
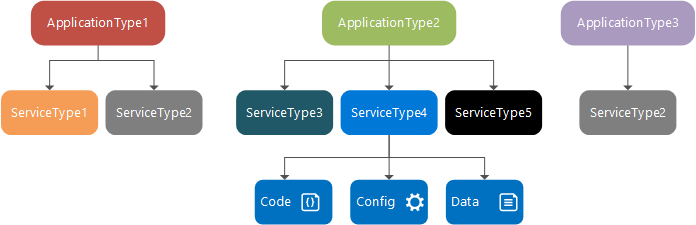
Balíček aplikace je adresář disku, který obsahuje soubor typu aplikace ApplicationManifest.xml, který odkazuje na balíčky služby pro každý typ služby, který tvoří typ aplikace. Například balíček aplikace pro typ e-mailové aplikace může obsahovat odkazy na balíček služby fronty, balíček front-endové služby a balíček databázové služby.
Soubory v adresáři balíčku aplikace se zkopírují do úložiště imagí clusteru Service Fabric. Potom můžete vytvořit pojmenovanou aplikaci z tohoto typu aplikace, která se pak spustí v rámci clusteru. Po vytvoření pojmenované aplikace můžete vytvořit pojmenovanou službu z jednoho z typů služeb typu aplikace.
Doba běhu: clustery a uzly, pojmenované aplikace, pojmenované služby, oddíly a repliky
Cluster Service Fabric je síťově propojená sada virtuálních nebo fyzických počítačů, ve které se nasazují a spravují mikroslužby. Clustery je možné škálovat na tisíce počítačů.
Počítač nebo virtuální počítač, který je součástí clusteru, se nazývá uzel. Každému uzlu je přiřazen název uzlu (řetězec). Uzly mají určité charakteristiky, například vlastnosti umístění. Každý počítač nebo virtuální počítač má službu windows automatického spuštění, FabricHost.exekterá se spustí při spuštění a pak spustí dva spustitelné soubory: Fabric.exe a FabricGateway.exe. Tyto dva spustitelné soubory tvoří uzel. V případě scénářů vývoje nebo testování můžete hostovat více uzlů na jednom počítači nebo virtuálním počítači spuštěním několika instancí Fabric.exe a FabricGateway.exe.
Pojmenovaná aplikace je kolekce pojmenovaných služeb, které provádějí určitou funkci nebo funkce. Služba provádí úplnou a samostatnou funkci (může spustit a spustit nezávisle na jiných službách) a skládá se z kódu, konfigurace a dat. Po zkopírování balíčku aplikace do úložiště imagí vytvoříte instanci aplikace v clusteru zadáním typu aplikace balíčku aplikace (pomocí názvu nebo verze). Každá instance typu aplikace má přiřazený název identifikátoru URI, který vypadá jako fabric:/MyNamedApp. V rámci clusteru můžete vytvořit více pojmenovaných aplikací z jednoho typu aplikace. Pojmenované aplikace můžete vytvářet také z různých typů aplikací. Každá pojmenovaná aplikace se spravuje a spravuje nezávisle na verzích.
Po vytvoření pojmenované aplikace můžete vytvořit instanci jednoho z jeho typů služeb (pojmenované služby) v clusteru zadáním typu služby (pomocí názvu nebo verze). Každá instance typu služby má přiřazený název URI vymezený pod jeho pojmenovaným identifikátorem URI aplikace. Pokud například vytvoříte "MyDatabase" pojmenovanou službu v pojmenované aplikaci MyNamedApp, identifikátor URI vypadá takto: fabric:/MyNamedApp/MyDatabase. V pojmenované aplikaci můžete vytvořit jednu nebo více pojmenovaných služeb. Každá pojmenovaná služba může mít vlastní schéma oddílů a počet instancí nebo replik.
Existují dva typy služeb: bezstavové a stavové. Bezstavové služby neukládají stav v rámci služby. Bezstavové služby nemají trvalé úložiště vůbec nebo uchovávají trvalý stav v externí službě úložiště, jako je Azure Storage, Azure SQL Database nebo Azure Cosmos DB. Stavová služba ukládá stav v rámci služby a ke správě stavu používá programovací modely Reliable Collections nebo Reliable Actors.
Při vytváření pojmenované služby zadáte schéma oddílů. Služby s velkým množstvím stavu rozdělují data mezi oddíly. Každý oddíl zodpovídá za část kompletního stavu služby, která je rozložená mezi uzly clusteru.
Následující diagram znázorňuje vztah mezi aplikacemi a instancemi služeb, oddíly a replikami.
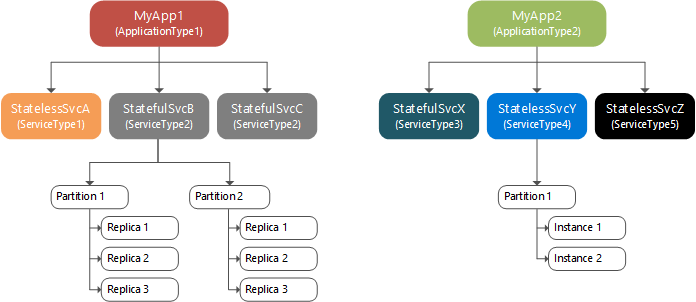
Dělení, škálování a dostupnost
Dělení není pro Service Fabric jedinečné. Známou formou dělení je dělení dat nebo horizontální dělení. Stavové služby s velkým množstvím stavu rozdělují data mezi oddíly. Každý oddíl zodpovídá za část kompletního stavu služby.
Repliky jednotlivých oddílů jsou rozloženy mezi uzly clusteru, což umožňuje škálování stavu pojmenované služby. S rostoucími potřebami dat se oddíly zvětšují a Service Fabric znovu vyrovnává oddíly napříč uzly, aby bylo možné efektivně využívat hardwarové prostředky. Pokud do clusteru přidáte nové uzly, Service Fabric znovu vyrovná repliky oddílů ve větším počtu uzlů. Celkový výkon aplikace zlepšuje a kolize přístupu k paměti se snižuje. Pokud se uzly v clusteru nepoužívají efektivně, můžete snížit počet uzlů v clusteru. Service Fabric znovu vyrovnává repliky oddílů napříč nižším počtem uzlů, aby se lépe používal hardware na každém uzlu.
V rámci oddílu mají bezstavové pojmenované služby instance, zatímco stavové pojmenované služby mají repliky. Bezstavové pojmenované služby mají obvykle jen jeden oddíl, protože nemají žádný interní stav, i když existují výjimky. Instance oddílů poskytují dostupnost. Pokud jedna instance selže, ostatní instance budou dál normálně fungovat a Service Fabric vytvoří novou instanci. Stavové pojmenované služby udržují svůj stav v rámci replik a každý oddíl má svou vlastní sadu replik. Operace čtení a zápisu se provádějí na jedné replice (označované jako primární). Změny stavu z operací zápisu se replikují do několika dalších replik (označovaných jako aktivní sekundy). Pokud replika selže, Service Fabric vytvoří novou repliku z existujících replik.
Bezstavové a stavové mikroslužby pro Service Fabric
Service Fabric umožňuje sestavovat aplikace, které se skládají z mikroslužeb nebo kontejnerů. Bezstavové mikroslužby (například brány protokolů a webové proxy) si mimo požadavek a odpověď ze služby neudržují měnitelný stav. Role pracovních procesů služby Azure Cloud Services jsou příkladem stavové služby. Stavové mikroslužby (například uživatelské účty, databáze, zařízení, nákupní košíky a fronty) si udržují měnitelný a autoritativní stav i mimo požadavek a odpověď. Dnešní aplikace v internetovém měřítku se skládají z kombinace bezstavových a stavových mikroslužeb.
Klíčovou diferenciací service Fabric je silné zaměření na vytváření stavových služeb, a to buď s integrovanými programovacími modely , nebo kontejnerizovanými stavovými službami. Scénáře aplikací popisují scénáře, ve kterých se používají stavové služby.
Proč mají stavové mikroslužby spolu s bezstavovými mikroslužbami? Mezi dva hlavní důvody patří:
- Služby OLTP (High-Throughput, low-latency, failure-tolerant online transaction processing) můžete vytvářet tak, že na stejném počítači zachováte kód a data. Mezi příklady patří interaktivní výkladní skříně, vyhledávání, systémy Internetu věcí (IoT), obchodní systémy, zpracování platebních karet a systémy detekce podvodů a správa osobních záznamů.
- Návrh aplikace můžete zjednodušit. Stavové mikroslužby odstraňují potřebu dalších front a mezipamětí, které se tradičně vyžadují k řešení požadavků na dostupnost a latenci čistě bezstavové aplikace. Stavové služby jsou přirozeně vysoce dostupné a nízké latence, což snižuje počet přesunovaných částí, které se mají spravovat v aplikaci jako celek.
Podporované programovací modely
Service Fabric nabízí několik způsobů, jak psát a spravovat služby. Služby můžou využívat rozhraní API Service Fabric k plnému využití funkcí a aplikačních architektur platformy. Služby můžou být také jakýkoli kompilovaný spustitelný program napsaný v libovolném jazyce a hostovaný v clusteru Service Fabric. Další informace naleznete v tématu Podporované programovací modely.
Kontejnery
Service Fabric ve výchozím nastavení nasazuje a aktivuje služby jako procesy. Service Fabric může také nasazovat služby v kontejnerech. Důležité je, že ve stejné aplikaci můžete kombinovat služby v procesech a službách v kontejnerech. Service Fabric podporuje nasazení kontejnerů Linuxu a kontejnerů Windows ve Windows Serveru 2016. Do kontejnerů můžete nasadit existující aplikace, bezstavové služby nebo stavové služby.
Reliable Services
Reliable Services je zjednodušená architektura pro psaní služeb, které se integrují s platformou Service Fabric a využívají výhod celé sady funkcí platformy. Reliable Services může být bezstavová (podobně jako většina platforem služeb, jako jsou webové servery nebo role pracovních procesů v Cloud Services Azure), kde se stav trvale nachází v externím řešení, jako je Azure DB nebo Azure Table Storage. Reliable Services může být také stavový, kde je stav trvalý přímo v samotné službě pomocí Reliable Collections. Stav je vysoce dostupný prostřednictvím replikace a distribuován prostřednictvím dělení, a to vše automaticky spravované Service Fabric.
Reliable Actors
Architektura Reliable Actor postavená na Reliable Services je aplikační architektura, která implementuje model virtuálního objektu actor na základě vzoru návrhu objektu actor. Architektura Reliable Actor používá nezávislé jednotky výpočetních a stavových jednotek s jednovláknovým spouštěním označovaným jako aktéři. Architektura Reliable Actor poskytuje integrovanou komunikaci pro aktéry a předem nastavené konfigurace trvalosti stavu a škálování na více instancí.
ASP.NET Core
Service Fabric se integruje s ASP.NET Core jako prvotřídní programovací model pro vytváření webových a api aplikací. ASP.NET Core je možné v Service Fabric používat dvěma různými způsoby:
- Hostovaný jako spustitelný soubor hosta. Používá se primárně ke spouštění existujících aplikací ASP.NET Core ve službě Service Fabric beze změn kódu.
- Spusťte službu Reliable Service. To umožňuje lepší integraci s modulem runtime Service Fabric a umožňuje stavové služby ASP.NET Core.
Spustitelné soubory typu Host
Spustitelný soubor hosta je existující libovolný spustitelný soubor (napsaný v libovolném jazyce) hostovaný v clusteru Service Fabric spolu s dalšími službami. Spustitelné soubory hosta se neintegrují přímo s rozhraními API Service Fabric. Stále ale využívají výhod funkcí, které nabízí platforma, jako jsou vlastní sestavy stavu a generování sestav zatížení a zjistitelnost služeb voláním rozhraní REST API. Mají také plnou podporu životního cyklu aplikace.
Životní cyklus aplikace
Stejně jako u jiných platforem aplikace v Service Fabric obvykle prochází následujícími fázemi: návrh, vývoj, testování, nasazení, upgrade, údržba a odebrání. Service Fabric poskytuje prvotřídní podporu pro celý životní cyklus aplikací cloudu, od vývoje po nasazení, každodenní správu a údržbu až po případné vyřazení z provozu. Model služby umožňuje nezávislé účasti několika různých rolí v životním cyklu aplikace. Životní cyklus aplikace Service Fabric poskytuje přehled rozhraní API a jejich používání různými rolemi ve fázích životního cyklu aplikace Service Fabric.
Celý životní cyklus aplikace je možné spravovat pomocí rutin PowerShellu, příkazů rozhraní příkazového řádku, rozhraní API jazyka C#, rozhraní JAVA API a rozhraní REST API. Kanály průběžné integrace nebo průběžného nasazování můžete také nastavit pomocí nástrojů, jako jsou Azure Pipelines nebo Jenkins.
Na tomto odkazu najdete školicí video, které popisuje, jak spravovat životní cyklus vaší aplikace:
Testování aplikací a služeb
Pokud chcete vytvářet skutečně cloudové služby, je důležité ověřit, že vaše aplikace a služby můžou odolat skutečným selháním. Služba Analýza chyb je navržená pro testování služeb, které jsou založené na Service Fabric. Pomocí služby Analýza chyb můžete indukovat smysluplné chyby a spouštět kompletní testovací scénáře pro vaše aplikace. Tyto chyby a scénáře si procvičí a ověří množství stavů a přechodů, které služba bude mít po celou dobu životnosti, a to vše řízeným, bezpečným a konzistentním způsobem.
Akce cílí na službu pro testování pomocí jednotlivých chyb. Vývojář služeb je může použít jako stavební bloky k psaní složitých scénářů. Příklady simulovaných chyb:
- Restartujte uzel a simulujte libovolný počet situací, kdy se počítač nebo virtuální počítač restartuje.
- Přesuňte repliku stavové služby pro simulaci vyrovnávání zatížení, převzetí služeb při selhání nebo upgradu aplikace.
- Vyvolání ztráty kvora ve stavové službě za účelem vytvoření situace, kdy operace zápisu nemohou pokračovat, protože pro přijetí nových dat není dostatek "záloh" nebo "sekundárních" replik.
- Vyvolání ztráty dat ve stavové službě za účelem vytvoření situace, kdy je veškerý stav v paměti zcela vymazán.
Scénáře jsou složité operace složené z jedné nebo více akcí. Služba Analýza chyb poskytuje dva předdefinované kompletní scénáře:
- Scénář chaosu – simuluje souvislé prokládání chyb (elegantní i nevděčné) v průběhu delších časových období.
- Scénář převzetí služeb při selhání – verze scénáře testování chaosu, která cílí na konkrétní oddíl služby, zatímco ostatní služby nebudou ovlivněné.
Clustery
Cluster Service Fabric je síťově propojená sada virtuálních nebo fyzických počítačů, ve které se nasazují a spravují mikroslužby. Clustery je možné škálovat na tisíce počítačů. Počítač nebo virtuální počítač, který je součástí clusteru, se nazývá uzel clusteru. Každému uzlu je přiřazen název uzlu (řetězec). Uzly mají určité charakteristiky, například vlastnosti umístění. Každý počítač nebo virtuální počítač má službu automatického spuštění, FabricHost.exekterá se spustí při spuštění a pak spustí dva spustitelné soubory: Fabric.exe a FabricGateway.exe. Tyto dva spustitelné soubory tvoří uzel. Pro testovací scénáře můžete hostovat více uzlů na jednom počítači nebo virtuálním počítači spuštěním několika instancí Fabric.exe a FabricGateway.exe.
Clustery Service Fabric je možné vytvářet na virtuálních nebo fyzických počítačích s Windows Serverem nebo Linuxem. Můžete nasazovat a spouštět aplikace Service Fabric v libovolném prostředí, ve kterém máte sadu počítačů s Windows Serverem nebo Linuxem, které jsou vzájemně propojené: místně, v Microsoft Azure nebo v libovolném poskytovateli cloudu.
Clustery v Azure
Spouštění clusterů Service Fabric v Azure poskytuje integraci s dalšími funkcemi a službami Azure, díky čemuž je provoz a správa clusteru jednodušší a spolehlivější. Cluster je prostředek Azure Resource Manageru, takže můžete modelovat clustery jako jakékoli jiné prostředky v Azure. Resource Manager také poskytuje snadnou správu všech prostředků používaných clusterem jako jednu jednotku. Clustery v Azure jsou integrované s diagnostikou Azure a protokoly služby Azure Monitor. Typy uzlů clusteru jsou škálovací sady virtuálních počítačů, takže funkce automatického škálování jsou integrované.
Cluster v Azure můžete vytvořit prostřednictvím webu Azure Portal, ze šablony nebo ze sady Visual Studio.
Service Fabric v Linuxu umožňuje vytvářet, nasazovat a spravovat vysoce dostupné a vysoce škálovatelné aplikace v Linuxu stejně jako ve Windows. Rozhraní Service Fabric (Reliable Services a Reliable Actors) jsou k dispozici v Javě v Linuxu kromě C# (.NET Core). Můžete také vytvářet spustitelné služby hosta s libovolným jazykem nebo architekturou. Orchestrace kontejnerů Dockeru je také podporovaná. Kontejnery Dockeru můžou spouštět spustitelné soubory hosta nebo nativní služby Service Fabric, které používají architektury Service Fabric. Další informace najdete v tématu Service Fabric v Linuxu.
Ve Windows jsou podporované některé funkce, ale ne v Linuxu. Další informace najdete v článku Rozdíly mezi Service Fabric v Linuxu a Windows.
Samostatné clustery
Service Fabric poskytuje instalační balíček pro vytvoření samostatných clusterů Service Fabric místně nebo na libovolném poskytovateli cloudu. Samostatné clustery vám umožňují hostovat cluster, ať chcete kdekoli. Pokud jsou vaše data předmětem dodržování předpisů nebo zákonných omezení nebo chcete zachovat svá data v místním prostředí, můžete hostovat vlastní cluster a aplikace. Aplikace Service Fabric se můžou spouštět v několika hostitelských prostředích beze změn, takže vaše znalosti o vytváření aplikací se přenášejí z jednoho hostitelského prostředí do jiného.
Vytvoření prvního samostatného clusteru Service Fabric
Samostatné clustery s Linuxem se zatím nepodporují.
Zabezpečení clusteru
Clustery musí být zabezpečené, aby se zabránilo neoprávněným uživatelům v připojení k vašemu clusteru, a to zejména v případě, že na něm běží produkční úlohy. I když je možné vytvořit nezabezpečený cluster, umožníte tak anonymním uživatelům připojit se k němu, pokud jsou koncové body správy vystavené veřejnému internetu. Později není možné povolit zabezpečení v nezabezpečeném clusteru: Zabezpečení clusteru je povoleno při vytváření clusteru.
Scénáře zabezpečení clusteru:
- Zabezpečení uzlů na uzel
- Zabezpečení mezi klienty a uzly
- Řízení přístupu na základě role Service Fabric
Další informace najdete v tématu Zabezpečení clusteru.
Škálování
Pokud do clusteru přidáte nové uzly, Service Fabric znovu vyrovnává repliky oddílů a instance ve větším počtu uzlů. Celkový výkon aplikace zlepšuje a kolize přístupu k paměti se snižuje. Pokud se uzly v clusteru nepoužívají efektivně, můžete snížit počet uzlů v clusteru. Service Fabric znovu vyrovnává repliky oddílů a instance napříč nižším počtem uzlů, aby se lépe používal hardware na každém uzlu. Clustery můžete škálovat v Azure ručně nebo programově. Samostatné clustery je možné škálovat ručně.
Upgrady clusterů
Pravidelně se vydávají nové verze modulu runtime Service Fabric. Proveďte v clusteru upgrady modulu runtime nebo prostředků infrastruktury, abyste vždy spustili podporovanou verzi. Kromě upgradů prostředků infrastruktury můžete také aktualizovat konfiguraci clusteru, jako jsou certifikáty nebo porty aplikací.
Cluster Service Fabric je prostředek, který vlastníte, ale částečně ho spravuje Microsoft. Microsoft zodpovídá za opravy základního operačního systému a provádění upgradů prostředků infrastruktury ve vašem clusteru. Cluster můžete nastavit tak, aby přijímal automatické upgrady prostředků infrastruktury, když Microsoft vydá novou verzi, nebo vyberte požadovanou podporovanou verzi prostředků infrastruktury. Upgrady prostředků infrastruktury a konfigurace je možné nastavit prostřednictvím webu Azure Portal nebo prostřednictvím Resource Manageru. Další informace najdete v tématu Upgrade clusteru Service Fabric.
Samostatný cluster je prostředek, který vlastníte úplně. Zodpovídáte za opravy základního operačního systému a iniciování upgradů prostředků infrastruktury. Pokud se váš cluster může připojit https://www.microsoft.com/download, můžete cluster nastavit tak, aby se automaticky stáhl a zřídil nový balíček modulu runtime Service Fabric. Pak byste zahájili upgrade. Pokud váš cluster nemá přístup https://www.microsoft.com/download, můžete nový balíček modulu runtime stáhnout ručně z počítače připojeného k internetu a pak zahájit upgrade. Další informace najdete v tématu Upgrade samostatného clusteru Service Fabric.
Monitorování stavu
Service Fabric zavádí model stavu navržený tak, aby označoval podmínky clusteru a aplikací, které nejsou v pořádku, u konkrétních entit (jako jsou uzly clusteru a repliky služeb). Model stavu používá sestavy stavu (systémové komponenty a kukátky). Cílem je snadná a rychlá diagnostika a oprava. Autoři služeb musí předem přemýšlet o stavu a o tom, jak navrhnout vytváření sestav stavu. Všechny podmínky, které můžou mít vliv na stav, by měly být hlášeny, zejména pokud můžou pomoct označit problémy blízko kořenového adresáře. Informace o stavu můžou ušetřit čas a úsilí při ladění a vyšetřování, jakmile je služba ve velkém provozu v produkčním prostředí.
Reportéři Service Fabric monitorují zjištěné podmínky zájmu. Tyto podmínky hlásí na základě místního zobrazení. Úložiště stavu agreguje data o stavu odesílaná všemi reportéry, aby bylo možné určit, jestli jsou entity globálně v pořádku. Model má být bohatý, flexibilní a snadno použitelný. Kvalita sestav o stavu určuje přesnost zobrazení stavu clusteru. Falešně pozitivní výsledky, které nesprávně ukazují problémy, které nejsou v pořádku, můžou negativně ovlivnit upgrady nebo jiné služby, které používají data o stavu. Příkladem takových služeb jsou opravné služby a mechanismy upozorňování. Proto je potřeba si představit, že je potřeba poskytnout sestavy, které zachycují podmínky zájmu nejlepším možným způsobem.
Vytváření sestav lze provést z:
- Monitorovaná replika nebo instance služby Service Fabric.
- Interní watchdogs nasazené jako služba Service Fabric (například bezstavová služba Service Fabric, která monitoruje podmínky a sestavy problémů). Watchdogs je možné nasadit na všechny uzly nebo je lze spřažením s monitorovanou službou.
- Interní watchdogs, které běží na uzlech Service Fabric, ale nejsou implementovány jako služby Service Fabric.
- Externí watchdogs, které testuje prostředek mimo cluster Service Fabric (například monitorovací služba, jako je Gomez).
Komponenty Service Fabric hlásí stav všech entit v clusteru. Sestavy stavu systému poskytují přehled o funkcích clusteru a aplikacích a oznamují problémy prostřednictvím stavu. V případě aplikací a služeb sestavy stavu systému ověřují, že se entity implementují a chovají se správně z pohledu modulu runtime Service Fabric. Sestavy neposkytují žádné monitorování stavu obchodní logiky služby ani detekují procesy, které přestaly reagovat. Pokud chcete přidat informace o stavu specifické pro logiku vaší služby, implementujte ve svých službách vlastní generování sestav stavu .
Service Fabric nabízí několik způsobů zobrazení sestav o stavu agregovaných v úložišti stavu:
- Service Fabric Explorer nebo jiné vizualizační nástroje.
- Dotazy na stav (prostřednictvím PowerShellu, rozhraní příkazového řádku, rozhraní API C# FabricClient a rozhraní API Java FabricClient nebo rozhraní REST API).
- Obecné dotazy, které vracejí seznam entit, které mají stav jako jednu z vlastností (prostřednictvím PowerShellu, rozhraní příkazového řádku, rozhraní API nebo ROZHRANÍ REST).
Monitorování a diagnostika
Monitorování a diagnostika jsou důležité pro vývoj, testování a nasazování aplikací a služeb v jakémkoli prostředí. Řešení Service Fabric fungují nejlépe, když plánujete a implementujete monitorování a diagnostiku, která pomáhají zajistit, aby aplikace a služby fungovaly podle očekávání v místním vývojovém prostředí nebo v produkčním prostředí.
Hlavními cíli monitorování a diagnostiky jsou:
- Detekce a diagnostika problémů s hardwarem a infrastrukturou
- Zjišťování problémů se softwarem a aplikacemi, snížení výpadků služeb
- Vysvětlení spotřeby prostředků a pomoc s rozhodováním o operacích
- Optimalizace výkonu aplikací, služeb a infrastruktury
- Generováníobchodníchch
Celkový pracovní postup monitorování a diagnostiky se skládá ze tří kroků:
- Generování událostí: To zahrnuje události (protokoly, trasování, vlastní události) na úrovni infrastruktury (clusteru), platformy a aplikace / služby.
- Agregace událostí: Vygenerované události je potřeba shromáždit a agregovat před jejich zobrazením.
- Analýza: Události je potřeba vizualizovat a zpřístupnit v určitém formátu, aby bylo možné analyzovat a zobrazovat podle potřeby.
K dispozici je více produktů, které pokrývají tyto tři oblasti a můžete si vybrat různé technologie pro každý z nich. Další informace najdete v tématu Monitorování a diagnostika pro Azure Service Fabric.
Další kroky
- Naučte se vytvořit cluster v Azure nebo samostatný clusteru ve Windows.
- Zkuste si vytvořit službu pomocí programovacího modelu Reliable Services nebo Reliable Actors.
- Zjistěte, jak migrovat z Cloud Services.
- Naučte se monitorovat a diagnostikovat služby.
- Naučte se testovat aplikace a služby.
- Naučte se spravovat a orchestrovat prostředky clusteru.
- Projděte si ukázky Service Fabric.
- Seznamte se s možnostmi podpory Service Fabric.
- Přečtěte si týmový blog o článcích a oznámeních.