Dělení spolehlivých služeb Service Fabric
Tento článek obsahuje úvod do základních konceptů dělení spolehlivých služeb Azure Service Fabric. Dělení umožňuje ukládání dat na místních počítačích, aby bylo možné data a výpočetní prostředky škálovat společně.
Tip
Kompletní ukázka kódu v tomto článku je k dispozici na GitHubu.
dělení na části
Dělení není pro Service Fabric jedinečné. Ve skutečnosti se jedná o základní vzor vytváření škálovatelných služeb. V širším smyslu můžeme uvažovat o dělení jako o konceptu rozdělení stavu (dat) a výpočetních prostředků na menší dostupné jednotky, abychom zlepšili škálovatelnost a výkon. Dobře známá forma dělení je dělení dat, označovaná také jako horizontální dělení.
Dělení bezstavových služeb Service Fabric
U bezstavových služeb si můžete představit, že oddíl je logická jednotka, která obsahuje jednu nebo více instancí služby. Obrázek 1 ukazuje bezstavovou službu s pěti instancemi distribuovanými v clusteru pomocí jednoho oddílu.
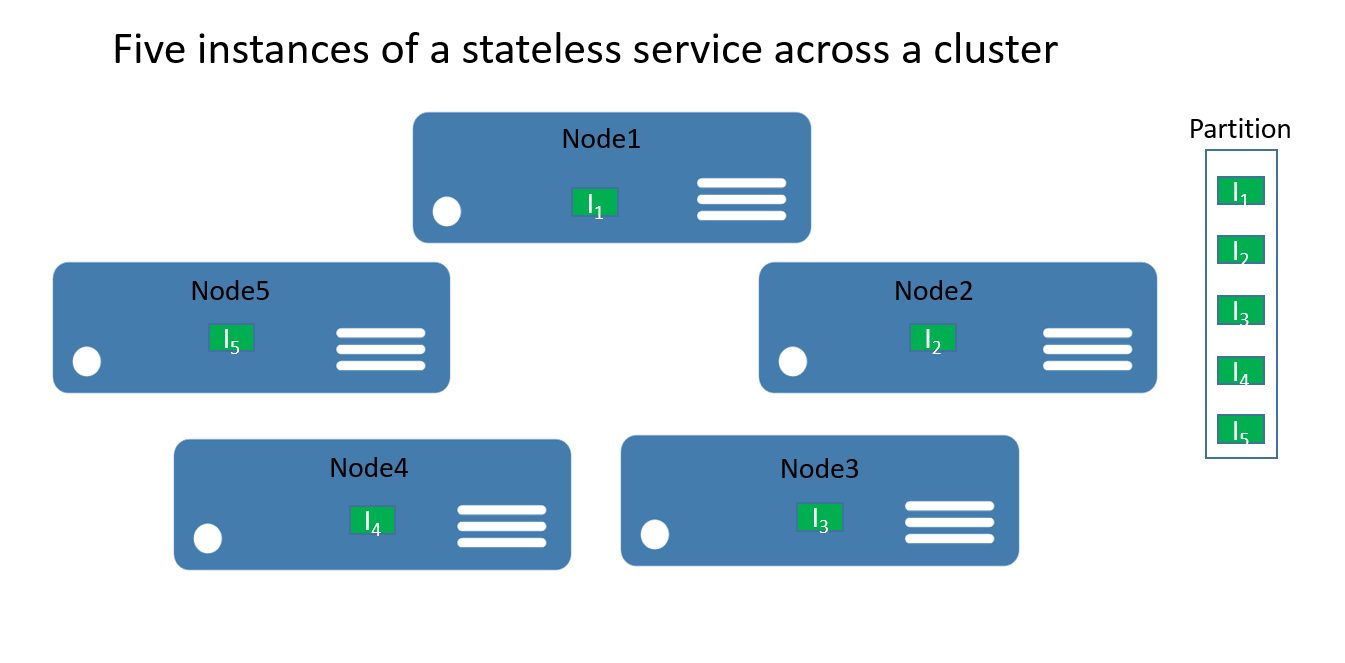
Existují opravdu dva typy bezstavových řešení služeb. První je služba, která uchovává svůj stav externě, například v databázi v Azure SQL Database (například na webu, který ukládá informace a data relace). Druhým je výpočetní služba (například kalkulačka nebo miniatura obrázků), které nespravují žádný trvalý stav.
V obou případech je dělení bezstavové služby velmi vzácné – škálovatelnost a dostupnost se obvykle dosahuje přidáním dalších instancí. Jediný čas, kdy chcete zvážit více oddílů pro instance bezstavové služby, je, když potřebujete splnit zvláštní požadavky směrování.
Představte si například případ, kdy by uživatelé s ID v určitém rozsahu měli obsluhovat pouze konkrétní instanci služby. Dalším příkladem toho, kdy byste mohli rozdělit bezstavovou službu, je, když máte skutečně dělený back-end (např. horizontálně dělenou databázi ve službě SQL Database) a chcete řídit, která instance služby by se měla zapisovat do horizontálního oddílu databáze, nebo provádět jinou přípravu v rámci bezstavové služby, která vyžaduje stejné informace o dělení, jaké se používají v back-endu. Tyto typy scénářů je také možné vyřešit různými způsoby a nemusí nutně vyžadovat dělení služby.
Zbývající část tohoto názorného postupu se zaměřuje na stavové služby.
Dělení stavových služeb Service Fabric
Service Fabric usnadňuje vývoj škálovatelných stavových služeb tím, že nabízí prvotřídní způsob rozdělení stavu (data). Koncepčně si můžete představit oddíl stavové služby jako jednotku škálování, která je vysoce spolehlivá prostřednictvím replik distribuovaných a vyvážených mezi uzly v clusteru.
Dělení v kontextu stavových služeb Service Fabric odkazuje na proces určení, že konkrétní oddíl služby odpovídá za část kompletního stavu služby. (Jak už bylo zmíněno dříve, oddíl je sada replik). Skvělou věcí o Service Fabric je, že umístí oddíly na různé uzly. To jim umožní zvětšit limit prostředků uzlu. S růstem potřeb dat se oddíly zvětšují a Service Fabric znovu vyrovnává oddíly napříč uzly. Tím se zajistí trvalé efektivní využívání hardwarových prostředků.
Řekněme, že začnete s clusterem s 5 uzly a službou, která je nakonfigurovaná tak, aby měla 10 oddílů a cíl tří replik. V tomto případě by Service Fabric vyvažovaly a distribuovaly repliky napříč clusterem– a nakonec byste měli dvě primární repliky na uzel. Pokud teď potřebujete škálovat cluster na 10 uzlů, Service Fabric znovu vyrovnává primární repliky napříč všemi 10 uzly. Podobně pokud jste škálovali zpět na 5 uzlů, Service Fabric by znovu vyrovnala všechny repliky napříč 5 uzly.
Obrázek 2 znázorňuje distribuci 10 oddílů před a po škálování clusteru.
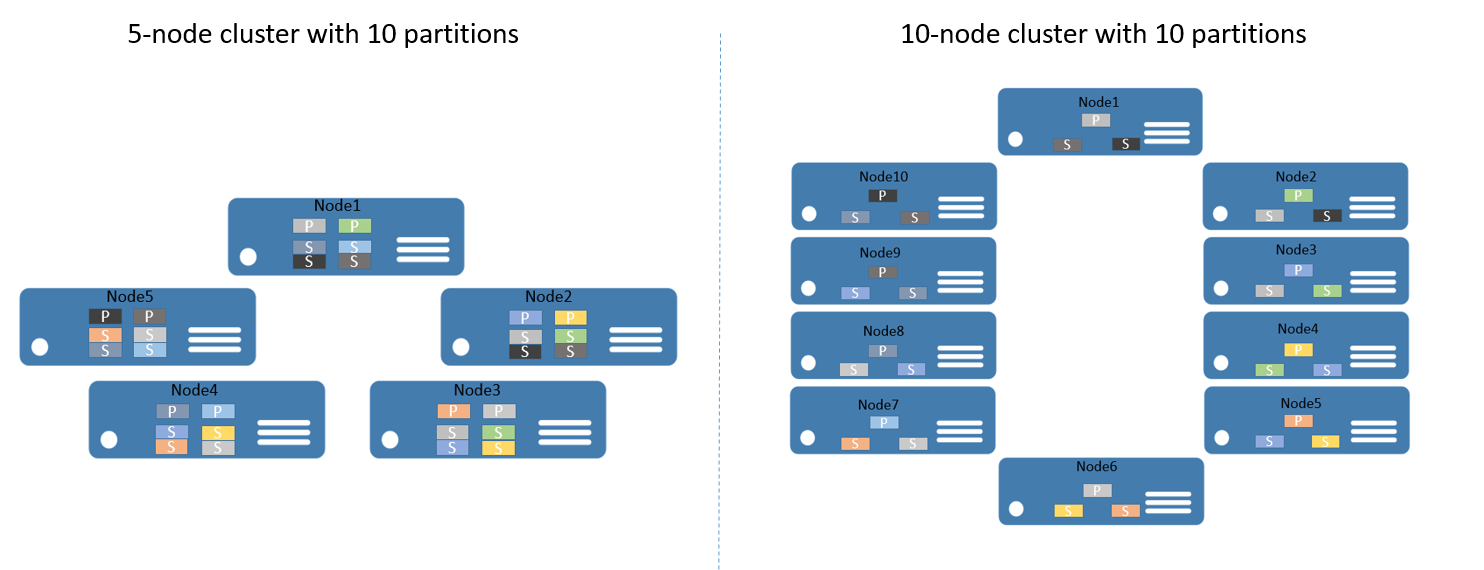
V důsledku toho se škálování na více instancí dosahuje, protože požadavky klientů se distribuují mezi počítače, zlepší se celkový výkon aplikace a sníží se kolize přístupu k blokům dat.
Plánování dělení
Před implementací služby byste měli vždy zvážit strategii dělení, která se vyžaduje pro horizontální navýšení kapacity. Existují různé způsoby, ale všechny se zaměřují na to, co aplikace potřebuje k dosažení. Pro kontext tohoto článku se podíváme na některé z důležitějších aspektů.
Dobrým přístupem je zamyslet se nad strukturou stavu, který je potřeba rozdělit, jako první krok.
Podívejme se na jednoduchý příklad. Pokud byste chtěli vytvořit službu pro hlasování v celé okrese, mohli byste vytvořit oddíl pro každé město v okresu. Pak můžete uložit hlasy pro každou osobu ve městě v oddílu, který odpovídá danému městu. Obrázek 3 znázorňuje sadu lidí a města, ve kterých se nacházejí.
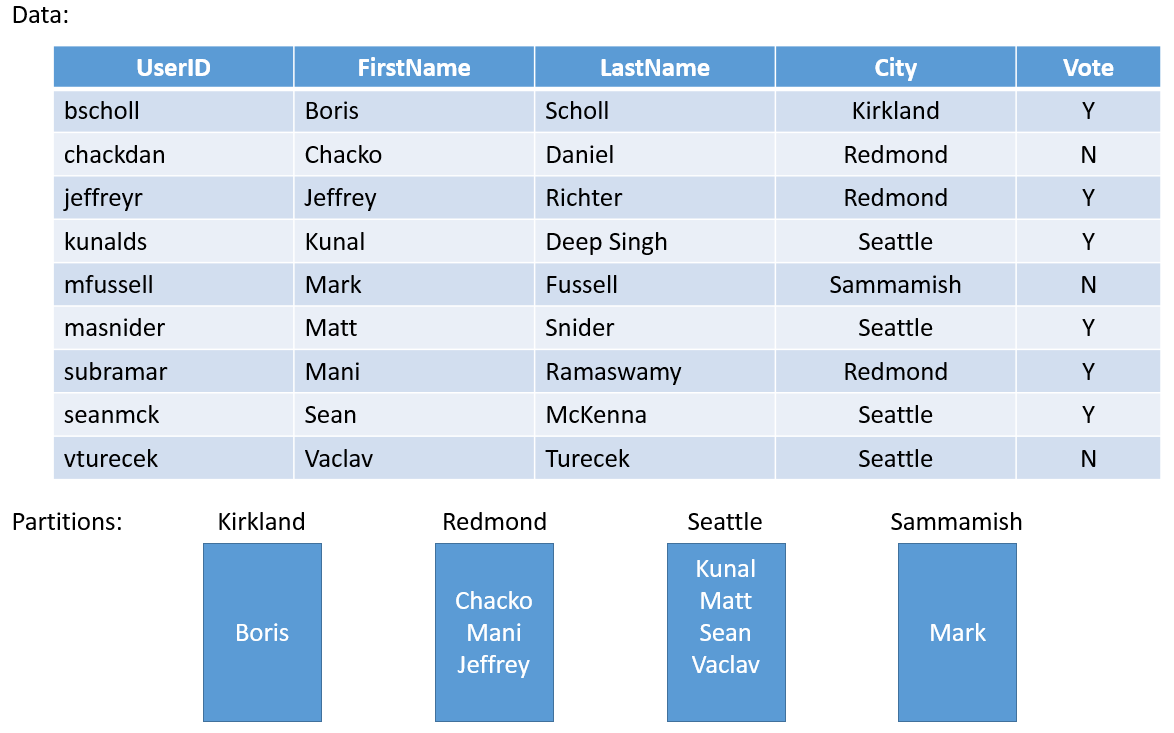
Vzhledem k tomu, že se počet obyvatel měst značně liší, můžete skončit s některými oddíly, které obsahují velké množství dat (např. Seattle) a další oddíly s velmi malým stavem (např. Kirkland). Jaký je tedy dopad rozdělení s nerovnoměrnými objemy stavu?
Pokud si o příkladu znovu myslíte, můžete snadno vidět, že oddíl, který obsahuje hlasy pro Seattle, dostane více provozu než Kirkland. Service Fabric ve výchozím nastavení zajišťuje, že na každém uzlu existuje přibližně stejný počet primárních a sekundárních replik. Takže můžete skončit s uzly, které obsahují repliky, které obsluhují více provozu a další, které obsluhují méně provozu. V clusteru byste se raději vyhnuli horkým a studeným místům.
Abyste se tomu vyhnuli, měli byste z hlediska dělení udělat dvě věci:
- Pokuste se rozdělit stav tak, aby se rovnoměrně distribuoval napříč všemi oddíly.
- Načítá se sestava z každé repliky služby. (Informace o postupu najdete v tomto článku Metriky a zatížení) Service Fabric poskytuje možnost hlásit zatížení spotřebované službami, jako je množství paměti nebo počet záznamů. Na základě hlášených metrik Service Fabric zjistí, že některé oddíly obsluhují vyšší zatížení než jiné, a znovu vyrovnává cluster přesunutím replik do vhodnějších uzlů, aby se celkový počet uzlů nepřetěžoval.
Někdy nemůžete zjistit, kolik dat bude v daném oddílu. Obecně se proto doporučuje nejprve provést strategii dělení, která rovnoměrně rozloží data mezi oddíly a druhou, a to generováním sestav. První metoda zabraňuje situacím popsaným v příkladu hlasování, zatímco druhá pomáhá vyhladit dočasné rozdíly v přístupu nebo zatížení v průběhu času.
Dalším aspektem plánování oddílů je zvolit správný počet oddílů, se kterými začnete. Z pohledu Service Fabric není nic, co by vám bránilo v tom, abyste začali s větším počtem oddílů, než se očekávalo pro váš scénář. Za předpokladu, že maximální počet oddílů je ve skutečnosti platným přístupem.
Ve výjimečných případech možná budete potřebovat více oddílů, než jste původně zvolili. Vzhledem k tomu, že po faktu nemůžete změnit počet oddílů, budete muset použít některé pokročilé přístupy k oddílům, jako je například vytvoření nové instance služby stejného typu služby. Také byste museli implementovat nějakou logiku na straně klienta, která směruje požadavky na správnou instanci služby na základě znalostí na straně klienta, které musí váš klientský kód udržovat.
Dalším aspektem plánování dělení je dostupné prostředky počítače. Vzhledem k tomu, že ke stavu je potřeba přistupovat a ukládat, musíte postupovat následovně:
- Omezení šířky pásma sítě
- Omezení systémové paměti
- Omezení diskových úložišť
Co se stane, když v běžícím clusteru narazíte na omezení prostředků? Odpovědí je, že cluster můžete jednoduše škálovat tak, aby vyhovoval novým požadavkům.
Průvodce plánováním kapacity nabízí pokyny, jak určit, kolik uzlů cluster potřebuje.
Začínáme s dělením
Tato část popisuje, jak začít s dělením služby.
Service Fabric nabízí výběr ze tří schémat oddílů:
- Dělení s rozsahem (jinak označované jako UniformInt64Partition).
- Pojmenované dělení Aplikace používající tento model obvykle obsahují data, která je možné v rámci omezené sady vytvořit do kontejneru. Mezi běžné příklady datových polí používaných jako pojmenované klíče oddílů patří oblasti, PSČ, skupiny zákazníků nebo jiné obchodní hranice.
- Dělení na jednoúčelové oddíly Jednoúčelové oddíly se obvykle používají, když služba nevyžaduje žádné další směrování. Například bezstavové služby ve výchozím nastavení používají toto schéma dělení.
Pojmenovaná a jednoúčelová schémata dělení jsou speciální formy rozsahových oddílů. Šablony sady Visual Studio pro Service Fabric ve výchozím nastavení používají dělené oddíly, protože se jedná o nejběžnější a nejužitečnější. Zbývající část tohoto článku se zaměřuje na schéma dělení v rozsahu.
Schéma dělení s rozsahem
Slouží k určení celočíselného rozsahu (identifikovaného malým klíčem a vysokým klíčem) a počtu oddílů (n). Vytvoří n oddílů, z nichž každý zodpovídá za nepřekrývající se poduskupování celkového rozsahu klíčů oddílu. Například schéma dělení s rozsahem s nízkým klíčem 0, vysokým klíčem 99 a počtem 4 by vytvořilo čtyři oddíly, jak je znázorněno níže.
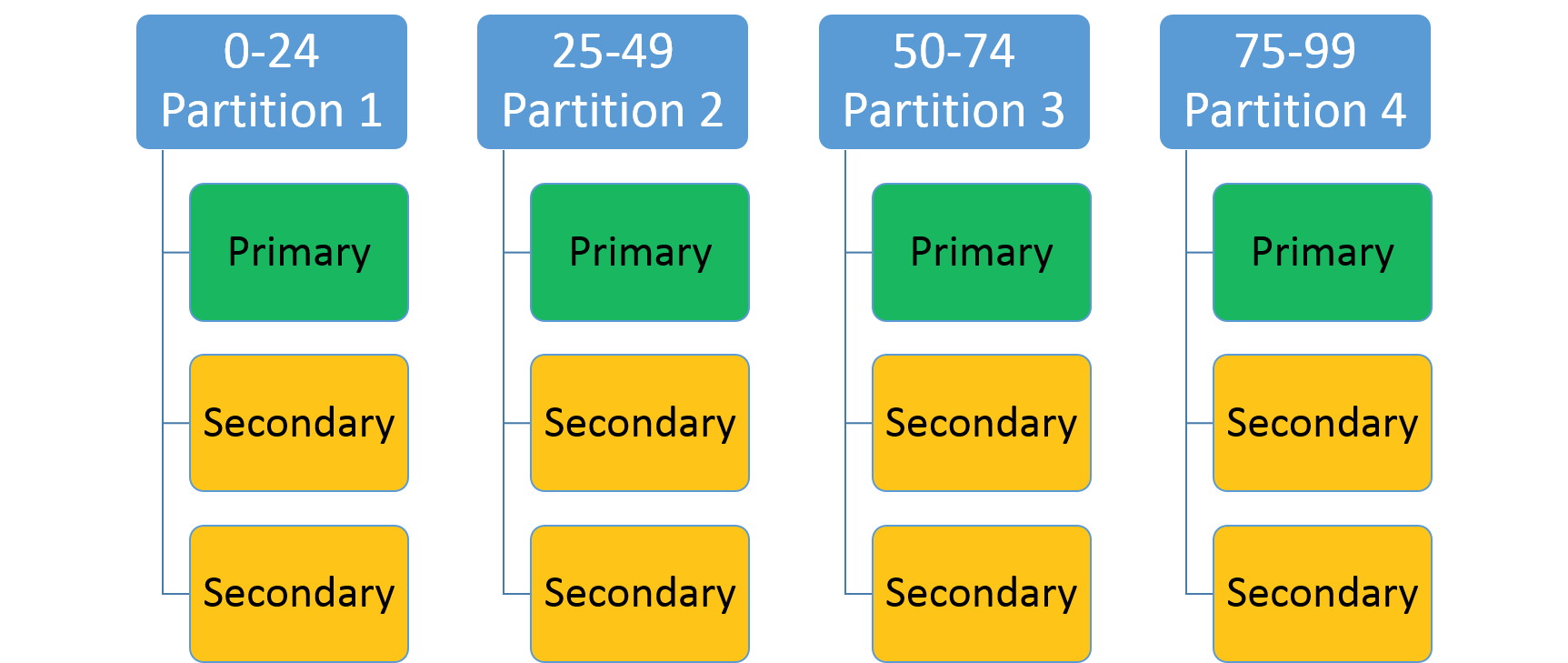
Běžným přístupem je vytvoření hodnoty hash na základě jedinečného klíče v rámci datové sady. Mezi běžné příklady klíčů patří identifikační číslo vozidla (VIN), ID zaměstnance nebo jedinečný řetězec. Když použijete tento jedinečný klíč, vygenerujete kód hash, moduls rozsah klíčů, který se použije jako váš klíč. Můžete zadat horní a dolní mez povoleného rozsahu klíčů.
Výběr hashového algoritmu
Důležitou součástí hashování je výběr algoritmu hash. Je třeba zvážit, jestli je cílem seskupit podobné klíče blízko sebe (zjišťování hodnot hash citlivé na lokalitu) nebo jestli by se aktivita měla distribuovat široce napříč všemi oddíly (rozdělení hash), což je častější.
Charakteristiky vhodného algoritmu hash distribuce jsou, že je snadné vypočítat, má několik kolizí a distribuuje klíče rovnoměrně. Dobrým příkladem efektivního hashovacího algoritmu je hashovací algoritmus FNV-1 .
Vhodným prostředkem pro obecné volby algoritmů hash je stránka Wikipedie o funkcích hash.
Vytvoření stavové služby s více oddíly
Pojďme vytvořit první spolehlivou stavovou službu s více oddíly. V tomto příkladu vytvoříte velmi jednoduchou aplikaci, do které chcete uložit všechna příjmení, která začínají stejným písmenem ve stejném oddílu.
Než začnete psát jakýkoli kód, musíte se zamyslet nad oddíly a klíči oddílů. Potřebujete 26 oddílů (jeden pro každé písmeno v abecedě), ale co nízké a vysoké klíče? Jak doslova chceme mít jeden oddíl na písmeno, můžeme použít 0 jako malý klíč a 25 jako vysoký klíč, protože každé písmeno je jeho vlastní klíč.
Poznámka:
Jedná se o zjednodušený scénář, protože ve skutečnosti by rozdělení bylo nerovnoměrné. Příjmení začínající písmeny "S" nebo "M" jsou častější než příjmení začínající písmeny "X" nebo "Y".
Otevřete nový>projekt v sadě Visual Studio>>File.
V dialogovém okně Nový projekt zvolte aplikaci Service Fabric.
Zavolejte projekt "AlphabetPartitions".
V dialogovém okně Vytvořit službu zvolte Stavová služba a zavolejte ji "Alphabet.Processing".
Nastavte počet oddílů. Otevřete soubor ApplicationManifest.xml umístěný ve složce ApplicationPackageRoot projektu AlphabetPartitions a aktualizujte parametr Processing_PartitionCount na 26, jak je znázorněno níže.
<Parameter Name="Processing_PartitionCount" DefaultValue="26" />Je také nutné aktualizovat LowKey a HighKey vlastnosti StatefulService elementu v ApplicationManifest.xml, jak je znázorněno níže.
<Service Name="Alphabet.Processing"> <StatefulService ServiceTypeName="Alphabet.ProcessingType" TargetReplicaSetSize="[Processing_TargetReplicaSetSize]" MinReplicaSetSize="[Processing_MinReplicaSetSize]"> <UniformInt64Partition PartitionCount="[Processing_PartitionCount]" LowKey="0" HighKey="25" /> </StatefulService> </Service>Aby byla služba přístupná, otevřete koncový bod na portu přidáním prvku koncového bodu ServiceManifest.xml (umístěného ve složce PackageRoot) pro službu Alphabet.Processing, jak je znázorněno níže:
<Endpoint Name="ProcessingServiceEndpoint" Port="8089" Protocol="http" Type="Internal" />Teď je služba nakonfigurovaná tak, aby naslouchala internímu koncovému bodu s 26 oddíly.
Dále je potřeba přepsat
CreateServiceReplicaListeners()metodu třídy Processing.Poznámka:
Pro tuto ukázku předpokládáme, že používáte jednoduchý HttpCommunicationListener. Další informace o spolehlivé komunikaci služby naleznete v tématu Model komunikace Reliable Service.
Doporučený vzor adresy URL, na které replika naslouchá, je následující formát:
{scheme}://{nodeIp}:{port}/{partitionid}/{replicaid}/{guid}. Proto chcete nakonfigurovat naslouchací proces komunikace tak, aby naslouchal správným koncovým bodům a s tímto vzorem.Na stejném počítači může být hostováno více replik této služby, takže tato adresa musí být pro repliku jedinečná. Proto se ID oddílu + ID repliky nachází v adrese URL. HttpListener může naslouchat více adres na stejném portu, pokud je předpona adresy URL jedinečná.
Další identifikátor GUID je k dispozici pro pokročilý případ, kdy sekundární repliky také naslouchají požadavkům jen pro čtení. V takovém případě chcete zajistit, aby se při přechodu z primární na sekundární použila nová jedinečná adresa, aby klienti mohli adresu přeložit znovu. "+" se používá jako adresa, aby replika naslouchala na všech dostupných hostitelích (IP adresa, plně kvalifikovaný název domény, localhost atd.). Následující kód ukazuje příklad.
protected override IEnumerable<ServiceReplicaListener> CreateServiceReplicaListeners() { return new[] { new ServiceReplicaListener(context => this.CreateInternalListener(context))}; } private ICommunicationListener CreateInternalListener(ServiceContext context) { EndpointResourceDescription internalEndpoint = context.CodePackageActivationContext.GetEndpoint("ProcessingServiceEndpoint"); string uriPrefix = String.Format( "{0}://+:{1}/{2}/{3}-{4}/", internalEndpoint.Protocol, internalEndpoint.Port, context.PartitionId, context.ReplicaOrInstanceId, Guid.NewGuid()); string nodeIP = FabricRuntime.GetNodeContext().IPAddressOrFQDN; string uriPublished = uriPrefix.Replace("+", nodeIP); return new HttpCommunicationListener(uriPrefix, uriPublished, this.ProcessInternalRequest); }Stojí také za zmínku, že publikovaná adresa URL se mírně liší od předpony adresy URL naslouchání. Naslouchající adresa URL se předá httpListeneru. Publikovaná adresa URL je adresa URL publikovaná ve službě pojmenování Service Fabric, která se používá ke zjišťování služeb. Klienti budou tuto adresu žádat prostřednictvím této služby zjišťování. Adresa, kterou klienti získají, musí mít k připojení skutečnou IP adresu nebo plně kvalifikovaný název domény uzlu. Proto je potřeba nahradit "+" IP adresou uzlu nebo plně kvalifikovaným názvem domény, jak je znázorněno výše.
Posledním krokem je přidání logiky zpracování do služby, jak je znázorněno níže.
private async Task ProcessInternalRequest(HttpListenerContext context, CancellationToken cancelRequest) { string output = null; string user = context.Request.QueryString["lastname"].ToString(); try { output = await this.AddUserAsync(user); } catch (Exception ex) { output = ex.Message; } using (HttpListenerResponse response = context.Response) { if (output != null) { byte[] outBytes = Encoding.UTF8.GetBytes(output); response.OutputStream.Write(outBytes, 0, outBytes.Length); } } } private async Task<string> AddUserAsync(string user) { IReliableDictionary<String, String> dictionary = await this.StateManager.GetOrAddAsync<IReliableDictionary<String, String>>("dictionary"); using (ITransaction tx = this.StateManager.CreateTransaction()) { bool addResult = await dictionary.TryAddAsync(tx, user.ToUpperInvariant(), user); await tx.CommitAsync(); return String.Format( "User {0} {1}", user, addResult ? "successfully added" : "already exists"); } }ProcessInternalRequestpřečte hodnoty parametru řetězce dotazu použitého k volání oddílu a voláníAddUserAsyncpro přidání příjmení do spolehlivého slovníkudictionary.Pojďme do projektu přidat bezstavovou službu, abychom viděli, jak můžete volat konkrétní oddíl.
Tato služba slouží jako jednoduché webové rozhraní, které přijímá příjmení jako parametr řetězce dotazu, určuje klíč oddílu a odesílá ho do služby Alphabet.Processing ke zpracování.
V dialogovém okně Vytvořit službu zvolte Bezstavová služba a zavolejte ji "Alphabet.Web", jak je znázorněno níže.
 .
.Aktualizujte informace o koncovém bodu v ServiceManifest.xml služby Alphabet.WebApi a otevřete port, jak je znázorněno níže.
<Endpoint Name="WebApiServiceEndpoint" Protocol="http" Port="8081"/>Potřebujete vrátit kolekci ServiceInstanceListeners ve třídě Web. Znovu můžete implementovat jednoduchý HttpCommunicationListener.
protected override IEnumerable<ServiceInstanceListener> CreateServiceInstanceListeners() { return new[] {new ServiceInstanceListener(context => this.CreateInputListener(context))}; } private ICommunicationListener CreateInputListener(ServiceContext context) { // Service instance's URL is the node's IP & desired port EndpointResourceDescription inputEndpoint = context.CodePackageActivationContext.GetEndpoint("WebApiServiceEndpoint") string uriPrefix = String.Format("{0}://+:{1}/alphabetpartitions/", inputEndpoint.Protocol, inputEndpoint.Port); var uriPublished = uriPrefix.Replace("+", FabricRuntime.GetNodeContext().IPAddressOrFQDN); return new HttpCommunicationListener(uriPrefix, uriPublished, this.ProcessInputRequest); }Teď potřebujete implementovat logiku zpracování. HttpCommunicationListener volá
ProcessInputRequest, když přijde požadavek. Pojďme tedy pokračovat a přidat níže uvedený kód.private async Task ProcessInputRequest(HttpListenerContext context, CancellationToken cancelRequest) { String output = null; try { string lastname = context.Request.QueryString["lastname"]; char firstLetterOfLastName = lastname.First(); ServicePartitionKey partitionKey = new ServicePartitionKey(Char.ToUpper(firstLetterOfLastName) - 'A'); ResolvedServicePartition partition = await this.servicePartitionResolver.ResolveAsync(alphabetServiceUri, partitionKey, cancelRequest); ResolvedServiceEndpoint ep = partition.GetEndpoint(); JObject addresses = JObject.Parse(ep.Address); string primaryReplicaAddress = (string)addresses["Endpoints"].First(); UriBuilder primaryReplicaUriBuilder = new UriBuilder(primaryReplicaAddress); primaryReplicaUriBuilder.Query = "lastname=" + lastname; string result = await this.httpClient.GetStringAsync(primaryReplicaUriBuilder.Uri); output = String.Format( "Result: {0}. <p>Partition key: '{1}' generated from the first letter '{2}' of input value '{3}'. <br>Processing service partition ID: {4}. <br>Processing service replica address: {5}", result, partitionKey, firstLetterOfLastName, lastname, partition.Info.Id, primaryReplicaAddress); } catch (Exception ex) { output = ex.Message; } using (var response = context.Response) { if (output != null) { output = output + "added to Partition: " + primaryReplicaAddress; byte[] outBytes = Encoding.UTF8.GetBytes(output); response.OutputStream.Write(outBytes, 0, outBytes.Length); } } }Pojďme si to projít krok za krokem. Kód přečte první písmeno parametru
lastnameřetězce dotazu do znaku. Potom určí klíč oddílu pro toto písmeno odečtením šestnáctkové hodnotyAod šestnáctkové hodnoty od šestnáctkové hodnoty prvního písmena příjmení.string lastname = context.Request.QueryString["lastname"]; char firstLetterOfLastName = lastname.First(); ServicePartitionKey partitionKey = new ServicePartitionKey(Char.ToUpper(firstLetterOfLastName) - 'A');Nezapomeňte, že v tomto příkladu používáme 26 oddílů s jedním klíčem oddílu na oddíl. Dále získáme oddíl
partitionslužby pro tento klíč pomocíResolveAsyncmetody objektuservicePartitionResolver.servicePartitionResolverje definován jakoprivate readonly ServicePartitionResolver servicePartitionResolver = ServicePartitionResolver.GetDefault();Metoda
ResolveAsyncpřebírá identifikátor URI služby, klíč oddílu a token zrušení jako parametry. Identifikátor URI služby pro zpracování jefabric:/AlphabetPartitions/Processing. Dále získáme koncový bod oddílu.ResolvedServiceEndpoint ep = partition.GetEndpoint()Nakonec vytvoříme adresu URL koncového bodu a řetězec dotazu a zavoláme službu zpracování.
JObject addresses = JObject.Parse(ep.Address); string primaryReplicaAddress = (string)addresses["Endpoints"].First(); UriBuilder primaryReplicaUriBuilder = new UriBuilder(primaryReplicaAddress); primaryReplicaUriBuilder.Query = "lastname=" + lastname; string result = await this.httpClient.GetStringAsync(primaryReplicaUriBuilder.Uri);Po dokončení zpracování zapíšeme výstup zpět.
Posledním krokem je otestování služby. Visual Studio používá parametry aplikace pro místní a cloudové nasazení. Pokud chcete službu otestovat s 26 oddíly místně, musíte soubor aktualizovat
Local.xmlve složce ApplicationParameters projektu AlphabetPartitions, jak je znázorněno níže:<Parameters> <Parameter Name="Processing_PartitionCount" Value="26" /> <Parameter Name="WebApi_InstanceCount" Value="1" /> </Parameters>Po dokončení nasazení můžete v Service Fabric Exploreru zkontrolovat službu a všechny její oddíly.
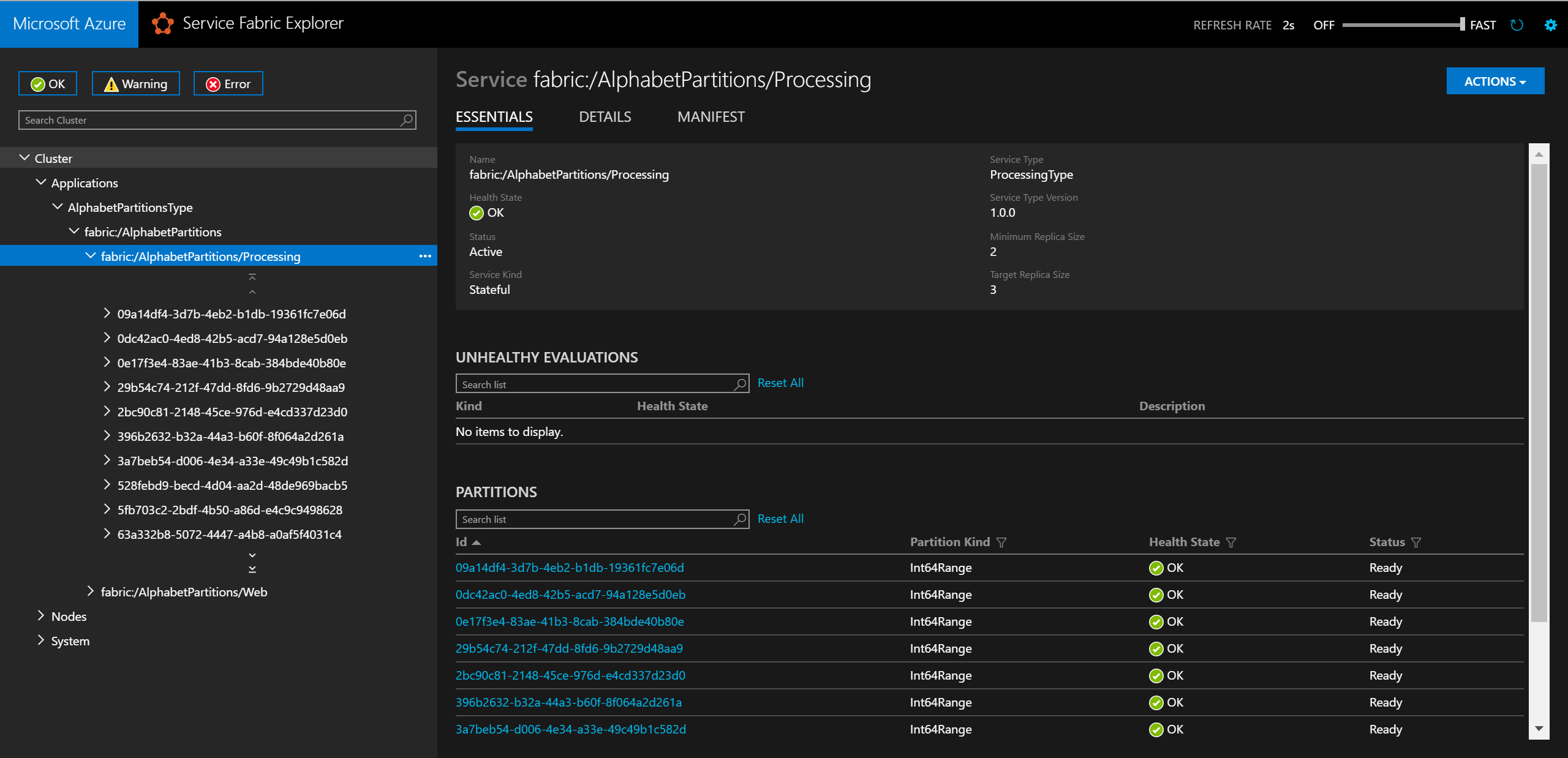
V prohlížeči můžete logiku dělení otestovat zadáním
http://localhost:8081/?lastname=somename. Uvidíte, že každé příjmení začínající stejným písmenem se ukládá do stejného oddílu.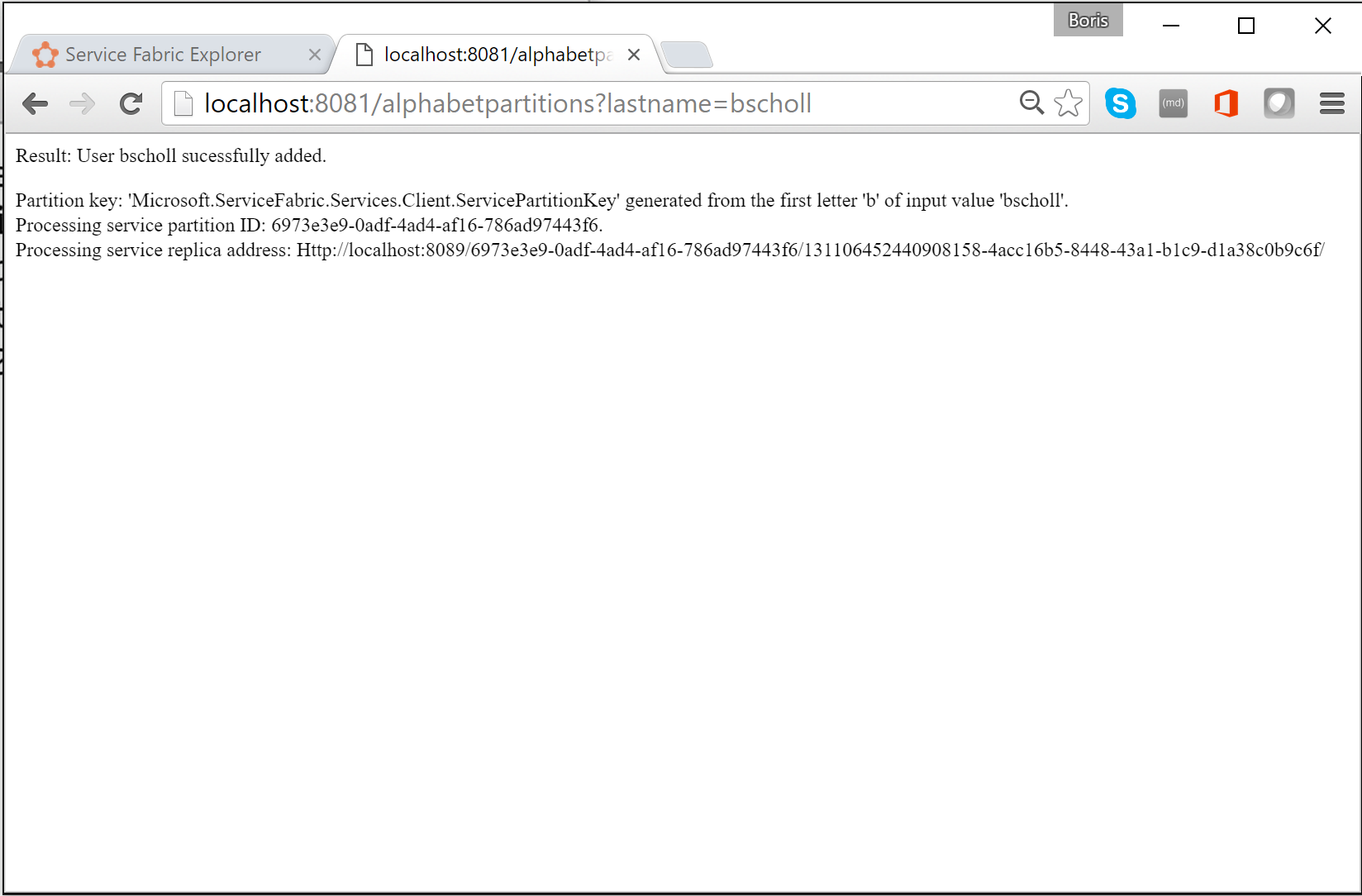
Kompletní řešení kódu použitého v tomto článku je k dispozici zde: https://github.com/Azure-Samples/service-fabric-dotnet-getting-started/tree/classic/Services/AlphabetPartitions.
Další kroky
Další informace o službách Service Fabric: