Teorie Groverova vyhledávacího algoritmu
V tomto článku najdete podrobné teoretické vysvětlení matematických principů, díky kterým Groverův algoritmus funguje.
Praktickou implementaci Groverova algoritmu k řešení matematických problémů najdete v tématu Implementace Groverova vyhledávacího algoritmu.
Prohlášení o problému
Groverův algoritmus zrychluje řešení na nestrukturované vyhledávání dat (nebo problém hledání), které spouští hledání v menším počtu kroků, než by mohl jakýkoli klasický algoritmus. Libovolný vyhledávací úkol lze vyjádřit pomocí abstraktní funkce $f(x),$ která přijímá položky hledání $x$. Pokud je položka $x$ řešením pro úlohu hledání, pak $f(x)=1$. Pokud položka $x$ není řešením, pak $f(x)=0$. Problém hledání se skládá z vyhledání libovolné položky $x_0$ tak, aby $f(x_0)=1$.
Jakýkoliv problém, který vám umožní zkontrolovat, jestli je daná hodnota $x$ platným řešením (" Ano nebo žádný problém") lze formulovat z hlediska problému hledání. Tady je několik příkladů:
- Problém splnitelnosti výrokové logiky: Je dána množina booleovských hodnot, splňuje tato množina danou booleovskou formuli?
- Problém cestovního prodejce: Jaká je nejkratší možná smyčka, která spojuje všechna města?
- Problém s vyhledáváním databáze: Obsahuje tabulka databáze záznam $x$?
- Problém celočíselné faktorizace: Je číslo $N$ dělitelné číslem $x$?
Úloha, kterou Groverův algoritmus má vyřešit, se dá vyjádřit takto: při zadání klasické funkce $f(x):\{0,1\}^n \rightarrow\{0,1\}$, kde $n$ je bitová velikost vyhledávacího prostoru, najděte vstupní $x_0$ , pro který $f(x_0)=1$. Složitost algoritmu se měří počtem použití funkce $f(x).$ V nejhorším scénáři $musí být f(x)$ vyhodnoceno celkem N-1$$krát, kde $N=2^n$ zkouší všechny možnosti. Za $N-1$ prvky musí být posledním prvkem. Groverův kvantový algoritmus dokáže tento problém vyřešit mnohem rychleji a poskytuje kvadratické zrychlení. Kvadratický zde znamená, že ve srovnání s N by se vyžadovalo pouze hodnocení $\sqrt{N}$$.$
Náčrt algoritmu
Předpokládejme, že pro úlohu vyhledávání existuje $počet opravňujících položek N=2^n$ a indexují se tak, že každé položce přiřadíte celé číslo od $0$ do $N-1$. Dále předpokládejme, že existují $různé platné vstupy M$ , což znamená, že existují $vstupy M$ , pro které $f(x)=1$. Kroky algoritmu jsou pak následující:
- Začněte registrem $n$ qubitů inicializovaných ve stavu $\ket{0}$.
- Připravte registr do jednotné superpozice použitím $H$ na každý qubit registru: $$|\text{zaregistrujte}\rangle=\frac{1}{\sqrt{N}}\sum_{x=0}^{N-1}|x.\rangle$$
- Pro registr použijte následující operace $N_{\text{optimální}}$ kolikrát:
- Orákulum $fáze O_f$ , který pro položky řešení použije podmíněný posun $fáze -1$ .
- Použijte $H$ pro každý qubit v registru.
- Podmíněný posun $fáze -1$ do každého výpočetního základního stavu s výjimkou $\ket{0}$. To může reprezentovat jednotková operace $-O_0$, protože $O_0$ představuje podmíněný posun fáze pouze na $\ket{0}$ .
- Použijte $H$ pro každý qubit v registru.
- Změřte registr, abyste získali index položky, která je řešením s velmi vysokou pravděpodobností.
- Zkontrolujte, jestli se jedná o platné řešení. Pokud ne, začněte znovu.
$N_{\text{optimální}}=\left\lfloor \frac{\pi}{{4}\sqrt{\frac{N}{M}}-\frac{{1}{{2}\right\r\lfloor$ je optimální počet iterací, který maximalizuje pravděpodobnost získání správné položky měřením registru.
Poznámka:
Společné uplatňování kroků 3.b, 3.c a 3.d se obvykle označuje jako Groverův operátor difuzní.
Celková jednotková operace použitá na registr je:
$$(-H^{\otimes n}O_0H^{\otimes n}O_f)^{N_{\text{optimální}}}H^{\otimes n}$$
Krok za krokem podle stavu registru
Pro ilustraci tohoto procesu se podíváme na matematické transformace stavu registru pro jednoduchý případ, ve kterém jsou pouze dva qubity a platným prvkem je $\ket{01}.$
Registrace začíná ve stavu:
$$\ket{\text{zaregistrovat}}=\ket{{00}$$
Po aplikaci $H$ na každý qubit se stav registru transformuje na:
$$\ket{\text{registr}}=\frac{{1}{\sqrt{4}}\sum_{i \in \lbrace 0,1 \rzávorka}^2\ket{i}=\frac12(\ket{00}+\ket{01}+\ket{{10}+\ket{11})$$
Pak se použije fázové orákulum k dosažení:
$$\ket{\text{zaregistrovat}}=\frac12(\ket{{00}-\ket{{01}+\ket{{10}+\ket{{11})$$
Pak $H$ znovu působí na každý qubit, aby:
$$\ket{\text{ }} = \frac12(\ket{{00}+\ket{{01}-\ket{{10}+\ket{{11})$$
Nyní je podmíněný posun fáze aplikován na každý stav s výjimkou $\ket{00}$:
$$\ket{\text{ }} = \frac12(\ket{{00}-\ket{{01}+\ket{{10}-\ket{{11})$$
Nakonec první iterace Grover končí, když znovu použijeme $H$ k získání:
$$\ket{\text{zaregistrovat}}=\ket{{01}$$
Podle výše uvedených kroků se platná položka nachází v jedné iteraci. Jak uvidíte později, je to proto, že pro N=4 a jednu platnou položku je optimální počet opakování $N_{\text{optimální}}=1$.
Geometrické vysvětlení
Abychom zjistili, proč Groverův algoritmus funguje, podívejme se na algoritmus z geometrické perspektivy. Předpokládá se, že existují $M$ platná řešení, superpozice všech kvantových stavů, které nejsou řešení problému hledání:
$$\ket{\text{bad}}=\frac{{1}{\sqrt{N-M}}\sum_{x:f(x)=0}\ket{x}$$
Superpozice všech stavů, které jsou řešení problému hledání:
$$\ket{\text{good}}=\frac{{1}{\sqrt{M}}\sum_{x:f(x)=1}\ket{x}$$
Protože dobré a špatné jsou vzájemně se vylučující množiny, protože položka nemůže být zároveň platná a neplatná, jsou stavy nezávislé. Oba stavy tvoří orthogonální základ roviny ve vektorovém prostoru. Tuto rovinu můžete použít k vizualizaci algoritmu.
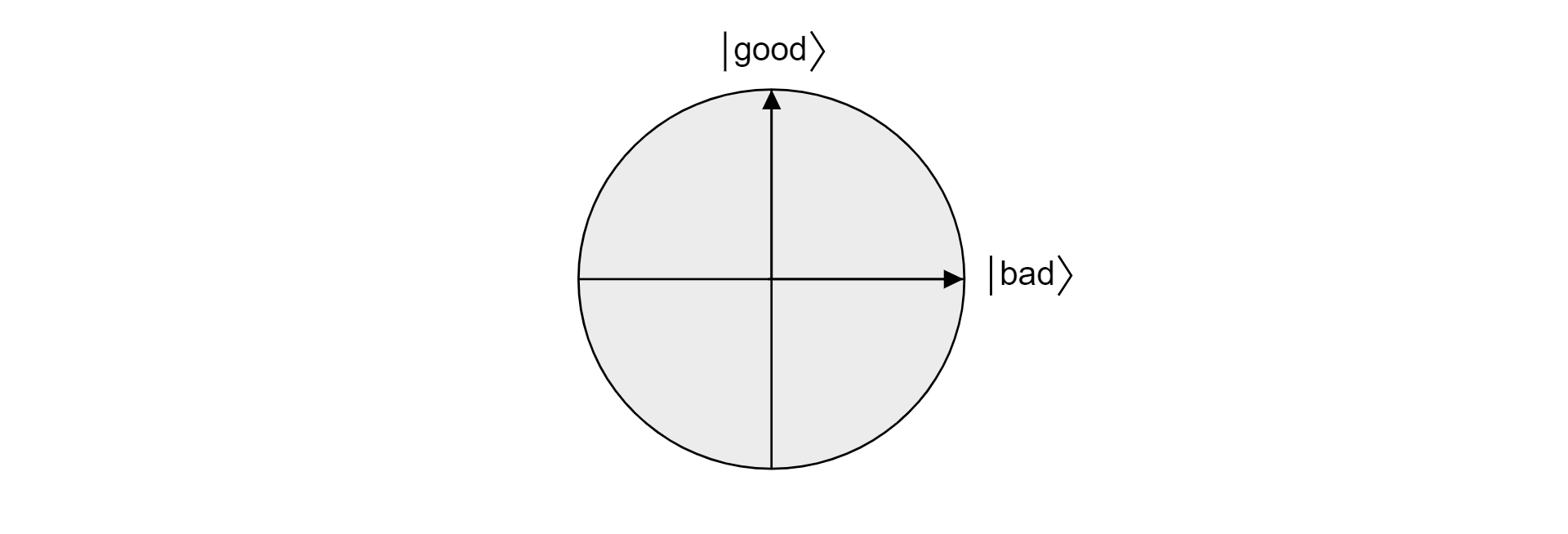
Předpokládejme, že $\ket{\psi}$ je libovolný stav, který žije v letadle rozložený $\ket{\text{podle dobrého}}$ a $\ket{\text{špatného}}$. Jakýkoli stav žijící v této rovině lze vyjádřit takto:
$$\ket{\psi} = \alpha \ket{\text{dobrý}} + \beta\ket{\text{špatný}}$$
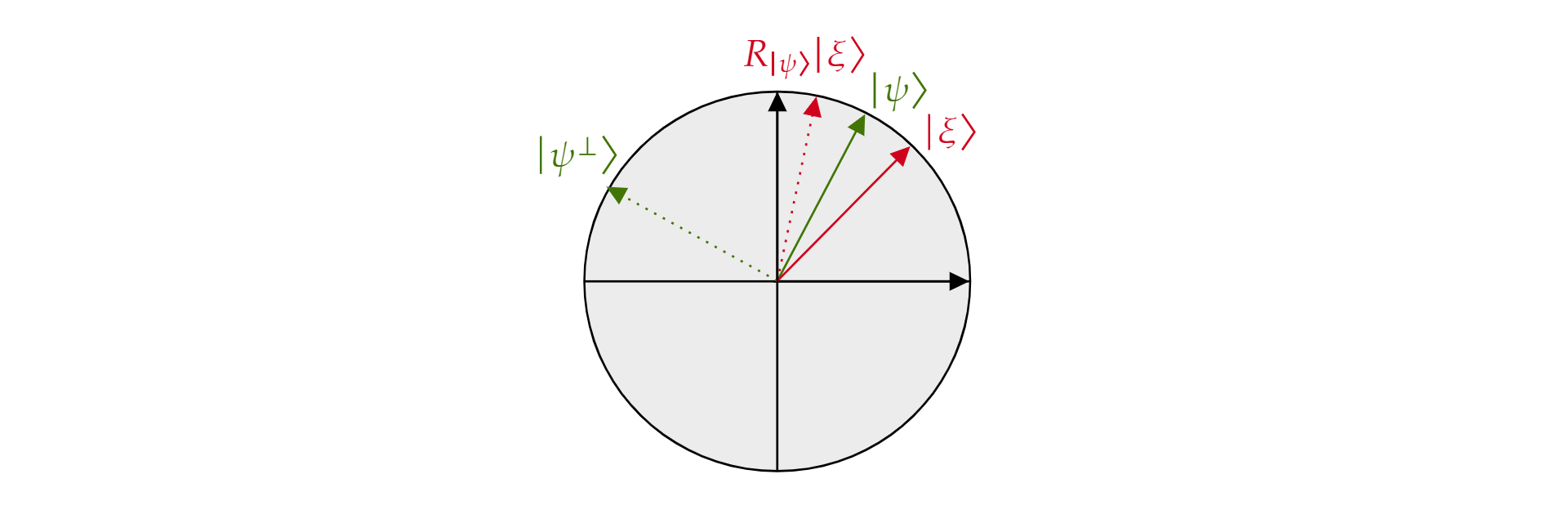
kde $\alpha$ a $\beta$ jsou reálná čísla. Teď si představíme operátor $reflexe R_{\ket{\psi}}$, kde $\ket{\psi}$ se nachází jakýkoli stav qubitu žijícího v rovině. Operátor je definován takto:
$$ {\ket{\psi}}=R_2\ket{\psi}\bra{\psi}-\mathcal{I}$$
Označuje se jako operátor reflexe, $\ket{\psi}$ protože jej lze geometricky interpretovat jako odraz o směru $\ket{\psi}$. Chcete-li to vidět, vezměte orthogonální základ roviny vytvořené $\ket{\psi}$ a jeho orthogonální doplněk $\ket{\psi^{\perp}}$. Jakýkoliv stav $\ket{\xi}$ roviny lze na takové bázi rozložit:
$$\ket{\xi}=\mu \ket{\psi} + \nu {\ket{\psi^{\perp}}}$$
Pokud jeden použije operátor $R_{\ket{\psi}}$ na $\ket{\xi}$:
$$ {\ket{\psi}}\ket{R_\xi}=\mu \ket{\psi} - \nu {\ket{\psi^{\perp}}}$$
Operátor $R_{\ket{\psi}}$ invertuje komponentu orthogonal na $\ket{\psi}$ komponentu $\ket{\psi}$ , ale ponechá ji beze změny. $Proto R_{\ket{\psi}}$ je odrazem o $\ket{\psi}$.
Groverův algoritmus po prvním použití $H$ na každý qubit začíná jednotným superpozicí všech stavů. Může to být napsané takto:
$$\ket{\text{všechny}}=\sqrt{\frac{M}{N}}\ket{\text{dobré}} + \sqrt{\frac{N-M}{N špatné}}\ket{\text{}}$$
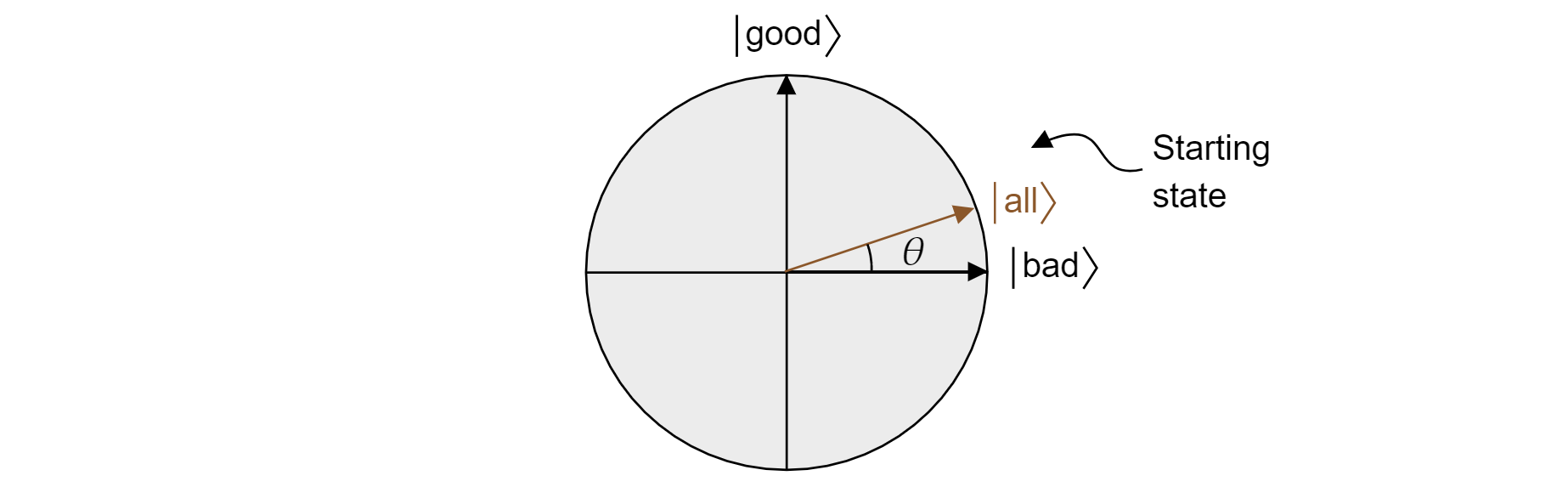
A tak stát žije v letadle. Všimněte si, že pravděpodobnost získání správného výsledku při měření ze stejné superpozice je pouze $|\bra{\text{dobrá}}\ket{\text{^}}|2=M/N$, což je to, co byste očekávali od náhodného odhadu.
Orákulum $O_f$ přidá zápornou fázi k jakémukoli řešení problému hledání. Proto může být napsán jako odraz o $\ket{\text{špatné}}$ ose:
$$O_f = R_{\ket{\text{špatné}}}= 2\ket{\text{špatné}}\bra{\text{špatné}}\mathbb{}$$
Podobně, podmíněný posun $fáze O_0$ je jen invertovaný odraz o stavu $\ket{0}$:
$$O_{0}= R_{\ket{0}}= -2\ket{{0}\bra{{0} + \mathbb{}$$
Když znáte tuto skutečnost, je snadné zkontrolovat, že operace Groverova difuzního procesu $-H^{\otimes n} O_{0} H^{\otimes n}$ je také odrazem o stavu $\ket{všeho}$. Stačí:
$$-H^{\otimes n} O_{{0} H^{\otimes n}=2H^{\otimes n}\ket{0}\bra{{0}H^{\otimes n} -H^{\otimes n}\mathbb{I}H^{\otimes n}= 2\ket{\text{všechny}}\bra{\text{všechny}} - \mathbb{I}= R_{\ket{\text{}}}$$
Ukázalo se, že každá iterace Groverova algoritmu představuje složení dvou odrazů $R_{\ket{\text{bad}}}$ a $R_{\ket{\text{all}}}$.
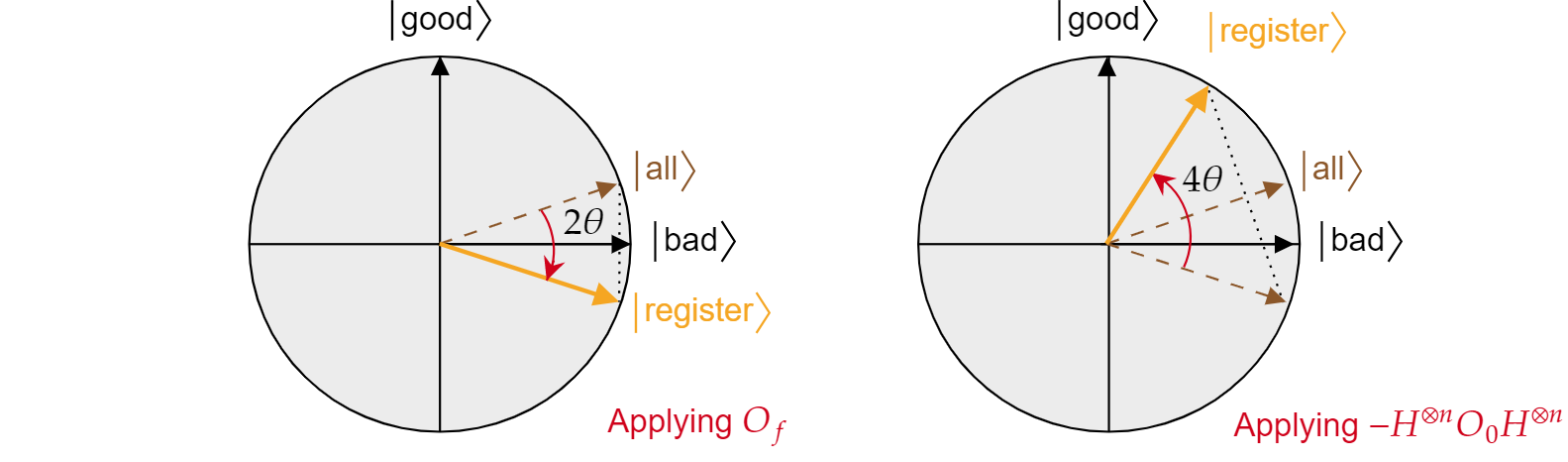
Kombinovaný efekt každé iterace Groveru je otočení proti směru hodinových ručiček úhlu $2\teta$. Naštěstí je úhel $\theta$ snadno najít. Vzhledem k tomu $, že \theta$ je jen úhel mezi $\ket{\text{všemi}}$ a $\ket{\text{špatnými}}$, můžete k nalezení úhlu použít skalární součin. Je známo, že $\cos{\theta}=\braket{\text{všechny}|\text{špatné}}$, takže jeden musí vypočítat $\braket{\text{všechny}|\text{špatné}}$. Z rozkladu $\ket{\text{všech}}$ z hlediska špatného$\ket{\text{ a }}$dobrého $\ket{\text{}}$se to týká:
$$\theta = \arccos{\left(\braket{\text{vše}|\text{špatné}}\right)}= \arccos{\left(\sqrt{\frac{N-M}{N}}\right)}$$
Úhel mezi stavem registru a $\ket{\text{dobrým}}$ stavem se snižuje s každou iterací, což vede k vyšší pravděpodobnosti měření platného výsledku. K výpočtu této pravděpodobnosti stačí vypočítat $|\braket{\text{dobrý}|\text{registr}}|^2$. Úhel mezi $\ket{\text{dobrý}}$ a $\ket{\text{registr}}$ je označen jako $\gamma (k)$, kde $k$ je počet iterací:
$$\gamma = \frac{\pi}{2}-\theta -2k \theta =\frac{\pi}{{2} -(2k + 1) \theta $$
Pravděpodobnost úspěchu je proto:
$$P(\text{success}) = \cos^2((\gammak)) = \sin^2\left[(2k +1)\arccos \left( \sqrt{\frac{N-M}{N}}\right)\right]$$
Optimální počet iterací
Protože pravděpodobnost úspěchu může být napsána jako funkce počtu iterací, optimální počet iterací $N_{\text{optimalitu}}$ lze najít pomocí výpočtu nejmenšího kladného celého čísla, které (přibližně) maximalizuje funkci pravděpodobnosti úspěchu.
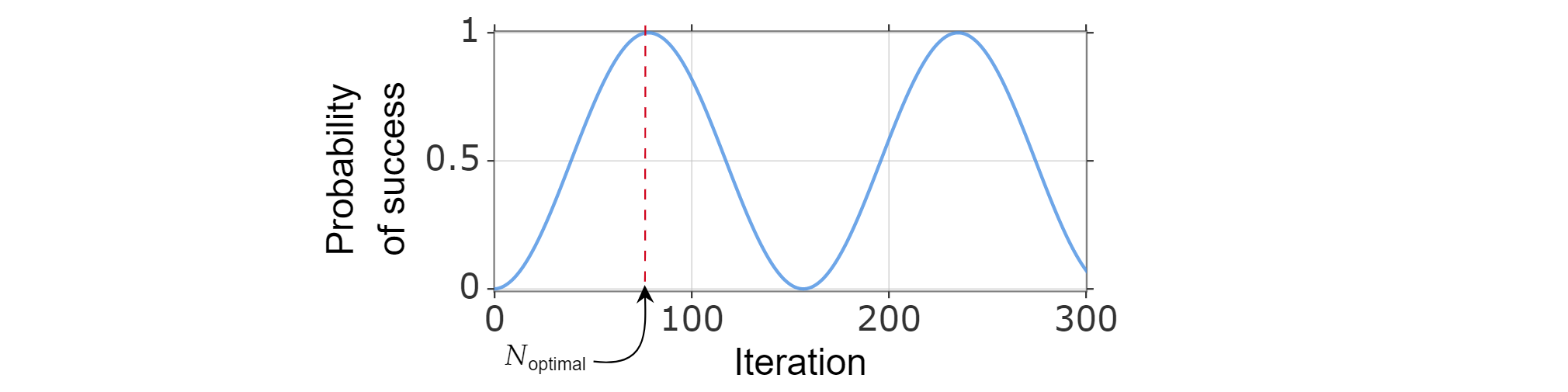
Je známo, že $\sin^2{x}$ dosáhne svého prvního maxima pro $x=\frac{\pi}{2}$, takže:
$$\frac{\pi}{{2}=(2k_{\text{optimální}} +1)\\leftarccos ( \sqrt{\frac{N-M}{N}}\right)$$
To dává:
$$ {\text{k_optimal}}=\frac{\pi}{4\arccos\left(\sqrt{1-M/N}\right)}-1/2=\frac{ \pi}{{4}\sqrt{\frac{N}{M}}-\frac{1}{2}-O\left(\sqrt\frac{M}{N)}\right$$
Kde v posledním kroku $\arccos \sqrt{1-x x}=\sqrt{+} O(x^{3/2})$.
Proto si můžete vybrat $N_{\text{optimální}}=\left\lfloor \frac{\pi}{{4}\sqrt{\frac{N}{M}}-\frac{{1}{{2}\right\rpodlaha$.
Analýza složitosti
Z předchozí analýzy $jsou potřeba dotazy O\left(\sqrt{\frac{N}{M}}\right)$ oracle $O_f$ k vyhledání platné položky. Je však možné algoritmus efektivně implementovat z hlediska složitosti času? $ $ O_0 je založená na výpočetních logických operacích na $n$ bitech a je známo, že je možné implementovat pomocí $bran O(n$). Existují také dvě vrstvy $n$ Hadamardových bran. Obě tyto komponenty proto vyžadují pouze $brány O(n)$ pro každou iteraci. Protože $N=2^n$, následuje $O(n)=O(log(N))$. Proto pokud $jsou potřeba iterace O\left(\sqrt{\frac{N}{M}}\right)$ a $brány O(log(N))$ na iteraci, celková složitost času (bez zohlednění implementace orákula) je $O\left(\sqrt{\frac{N}{M}}log(N))\right).$
Celková složitost algoritmu nakonec závisí na složitosti implementace orákulum $O_f$. Pokud je vyhodnocení funkce na kvantovém počítači mnohem složitější než v klasickém počítači, bude celkové runtime algoritmu v kvantovém případě delší, i když technicky vzato používá méně dotazů.
Reference
Pokud chcete pokračovat ve učení o Groverově algoritmu, můžete zkontrolovat některý z následujících zdrojů:
- Originální papír od Lov K. Grover
- Oddíl kvantových vyhledávacích algoritmů nielsen, M. A. &zesilovač; Chuang, I. L. (2010). Kvantové výpočty a kvantové informace.
- Groverův algoritmus na Arxiv.org