Prognózování ve velkém měřítku: mnoho modelů a distribuované trénování
Tento článek se zabývá trénováním modelů prognózování velkých objemů historických dat. Pokyny a příklady pro trénování modelů prognóz v AutoML najdete v našem článku věnovaném nastavení AutoML pro prognózování časových řad.
Data časových řad můžou být velká z důvodu počtu řad v datech, počtu historických pozorování nebo obojího. Řada modelů a hierarchických časových řad neboli HTS slouží ke škálování řešení pro předchozí scénář, kde se data skládají z velkého počtu časových řad. V těchto případech může být přínosné pro přesnost a škálovatelnost modelu rozdělení dat do skupin a paralelní trénování velkého počtu nezávislých modelů ve skupinách. Naopak existují scénáře, kdy je lepší jeden nebo několik modelů s vysokou kapacitou. Tento případ cílí na distribuované trénování DNN. Koncepty týkající se těchto scénářů si projdeme ve zbývající části článku.
Mnoho modelů
Mnoho komponent modelů v AutoML umožňuje trénovat a spravovat miliony modelů paralelně. Předpokládejme například, že máte historická prodejní data pro velký počet obchodů. Mnoho modelů můžete použít ke spuštění paralelních trénovacích úloh AutoML pro každé úložiště, jako v následujícím diagramu:

Součástí trénování mnoha modelů je použití úklidu a výběru modelu AutoML nezávisle na každém úložišti v tomto příkladu. Tato nezávislost modelu pomáhá škálovatelnosti a může těžit z přesnosti modelu zejména v případě, že obchody mají rozbíhající se prodejní dynamiku. Přístup k jednomu modelu ale může přinést přesnější prognózy, pokud existují běžné prodejní dynamiky. Další podrobnosti o tomto případě najdete v části věnované distribuovanému trénování DNN.
Můžete nakonfigurovat dělení dat, nastavení AutoML pro modely a stupeň paralelismu pro mnoho trénovacích úloh modelů. Příklady najdete v naší příručce k mnoha komponentám modelů.
Hierarchické prognózování časových řad
U časových řad v obchodních aplikacích je běžné mít vnořené atributy, které tvoří hierarchii. Atributy zeměpisu a katalogu produktů jsou často vnořené, například. Představte si příklad, kdy hierarchie obsahuje dva geografické atributy, ID stavu a úložiště a dva atributy produktu, kategorii a skladovou položku:

Tato hierarchie je znázorněna v následujícím diagramu:

Důležité je, že objemy prodeje na úrovni list (SKU) se sčítají do agregovaných objemů prodeje ve stavu a celkové úrovni prodeje. Metody hierarchického prognózování zachovávají tyto vlastnosti agregace při prognózování množství prodaného na libovolné úrovni hierarchie. Prognózy s touto vlastností jsou koherentní s ohledem na hierarchii.
AutoML podporuje pro hierarchické časové řady (HTS) následující funkce:
- Trénování na libovolné úrovni hierarchie V některých případech mohou být data na úrovni listu hlučná, ale agregace mohou být pro prognózování srozumitelnější.
- Načítání prognóz bodů na libovolné úrovni hierarchie Pokud je úroveň prognózy nižší než úroveň trénování, prognózy z úrovně trénování se člení prostřednictvím průměrných historických podílů nebo podílů historických průměrů. Prognózy úrovně trénování se sečtou podle agregační struktury, pokud je úroveň prognózy vyšší než úroveň trénování.
- Načítání kvantových/pravděpodobnostních prognóz pro úrovně na úrovni trénování nebo nižší úrovně trénování Současné možnosti modelování podporují členěnou agregaci pravděpodobnostních prognóz.
Komponenty HTS v AutoML jsou postavené na mnoha modelech, takže HTS sdílí škálovatelné vlastnosti mnoha modelů. Příklady najdete v naší příručce k komponentám HTS.
Distribuované trénování DNN (Preview)
Důležité
Tato funkce je v současné době ve verzi Public Preview. Tato verze Preview je poskytována bez smlouvy o úrovni služeb a nedoporučujeme ji pro produkční úlohy. Některé funkce se nemusí podporovat nebo mohou mít omezené možnosti.
Další informace najdete v dodatečných podmínkách použití pro verze Preview v Microsoft Azure.
Scénáře dat, které obsahují velké množství historických pozorování nebo velkého počtu souvisejících časových řad, můžou těžit ze škálovatelného přístupu s jedním modelem. AutoML proto podporuje distribuované trénování a vyhledávání modelů v dočasných konvolučních síťových modelech (TCN), což je typ hluboké neurální sítě (DNN) pro data časových řad. Další informace o třídě modelu TCN autoML najdete v našem článku o DNN.
Distribuované trénování DNN dosahuje škálovatelnosti pomocí algoritmu dělení dat, který respektuje hranice časových řad. Následující diagram znázorňuje jednoduchý příklad se dvěma oddíly:
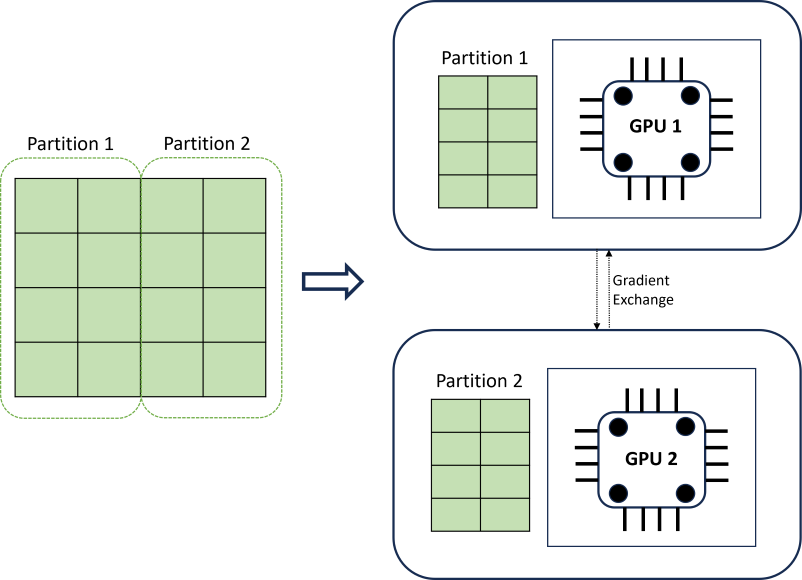
Během trénování zavaděče dat DNN na každém výpočetním zatížení přesně to, co potřebují k dokončení iterace zpětného šíření; celá datová sada se nikdy nepřečte do paměti. Oddíly se dále distribuují napříč několika výpočetními jádry (obvykle GPU) na několika uzlech, aby se urychlilo trénování. Koordinaci výpočetních prostředků poskytuje architektura Horovod .
Další kroky
- Přečtěte si další informace o tom, jak nastavit AutoML pro trénování modelu prognózování časových řad.
- Přečtěte si, jak AutoML používá strojové učení k vytváření modelů prognózování.
- Další informace o modelech hlubokého učení pro prognózování v AutoML