Úklid a výběr modelu pro prognózování v AutoML
Tento článek popisuje, jak automatizované strojové učení (AutoML) ve službě Azure Machine Learning hledá a vybírá modely prognózování. Pokud se chcete dozvědět více o metodologii prognózování v AutoML, přečtěte si téma Přehled metod prognózování v AutoML. Pokud chcete prozkoumat příklady trénování pro prognózování modelů v AutoML, přečtěte si téma Nastavení autoML pro trénování modelu prognózování časových řad pomocí sady SDK a rozhraní příkazového řádku.
Úklid modelů v AutoML
Centrální úlohou pro AutoML je trénování a vyhodnocování několika modelů a výběr nejlepšího modelu s ohledem na danou primární metriku. Slovo "model" v tomto případě odkazuje na třídu modelu, jako je ARIMA nebo Náhodná doménová struktura, a konkrétní nastavení hyperparametrů, která rozlišují modely v rámci třídy. ARIMA například odkazuje na třídu modelů, které sdílejí matematickou šablonu a sadu statistických předpokladů. Trénování nebo přizpůsobení modelu ARIMA vyžaduje seznam kladných celých čísel, které určují přesnou matematickou formu modelu. Tyto hodnoty jsou hyper-parametry. Modely ARIMA(1, 0, 1) a ARIMA(2, 1, 2) mají stejnou třídu, ale různé hyper-parametry. Tyto definice se dají samostatně přizpůsobit trénovacím datům a vyhodnotit je navzájem. AutoML vyhledává nebo zamytává různé třídy modelu a v rámci tříd pomocí různých parametrů hyper-parameters.
Metody úklidu hyperparametrů
Následující tabulka ukazuje různé metody úklidu hyperparametrů, které AutoML používá pro různé třídy modelů:
| Skupina tříd modelu | Typ modelu | Metoda úklidu hyperparametrů |
|---|---|---|
| Naive, Sezónní Naive, Průměr, Sezónní průměr | Časové řady | Bez úklidu v rámci třídy kvůli jednoduchosti modelu |
| Exponenciální vyhlazování, ARIMA(X) | Časové řady | Hledání mřížky pro úklid v rámci třídy |
| Prorok | Regrese | Bez úklidu v rámci třídy |
| Lineární SGD, LARS LARS LASSO, Elastic Net, K nejbližší sousedé, rozhodovací strom, náhodný les, extrémně randomizované stromy, gradientní zesílené stromy, lightGBM, XGBoost | Regrese | Služba doporučení modelu AutoML dynamicky zkoumá prostory hyperparametrů. |
| ForecastTCN | Regrese | Statický seznam modelů následovaných náhodným vyhledáváním podle velikosti sítě, poměru vyřazení a rychlosti učení |
Popis různých typů modelů najdete v části Modely prognózování v článku s přehledem metod prognózování.
Množství úklidu pomocí AutoML závisí na konfiguraci úlohy prognózy. Kritéria zastavení můžete zadat jako časový limit nebo limit počtu pokusů nebo ekvivalentní počet modelů. Logiku předčasného ukončení je možné použít v obou případech k zastavení úklidu, pokud se primární metrika nezlepšuje.
Výběr modelu v AutoML
AutoML se řídí třífázovým procesem, který hledá a vybírá modely prognózování:
Fáze 1: Uklidte modely časových řad a vyberte nejlepší model z každé třídy pomocí metod odhadu maximální pravděpodobnosti.
Fáze 2: Přemístit regresní modely a zařadit je do pořadí spolu s nejlepšími modely časových řad z fáze 1 podle jejich primárních hodnot metrik z ověřovacích sad.
Fáze 3: Sestavte si souborový model z nejlépe seřazených modelů, vypočítejte metriku ověření a seřadíte ho s ostatními modely.
Model s nejvyšší hodnotou metriky na konci fáze 3 je určen nejlepším modelem.
Důležité
Ve fázi 3 autoML vždy vypočítá metriky na datech mimo ukázku , která se nepoužívají k přizpůsobení modelů. Tento přístup pomáhá chránit před přetěžováním.
Konfigurace ověřování
AutoML má dvě konfigurace ověřování: křížové ověření a explicitní ověřovací data.
V případě křížového ověření používá AutoML vstupní konfiguraci k vytvoření dat rozdělených na trénovací a ověřovací záhyby. V těchto rozděleních musí být zachováno časové pořadí. AutoML používá tzv . průběžné ověřování původu, které rozděluje řadu na trénovací a ověřovací data pomocí počátečního časového bodu. Posunutím počátku v čase se vygenerují křížové záhyby křížového ověření. Každý ověřovací složený záhyb obsahuje další horizont pozorování bezprostředně za umístěním původu pro danou složenou záhybu. Tato strategie zachovává integritu dat časové řady a snižuje riziko úniku informací.
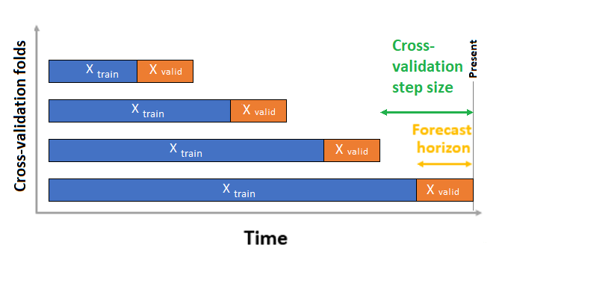
AutoML se řídí obvyklým postupem křížového ověření, trénováním samostatného modelu na každém záhybu a průměrováním ověřovacích metrik ze všech složených záhybů.
Křížové ověřování pro úlohy prognózování je nakonfigurováno nastavením počtu záhybů křížového ověření a volitelně počtu časových období mezi dvěma po sobě jdoucími složenými křížovými ověřeními. Další informace a příklad konfigurace křížového ověřování pro prognózování najdete v tématu Vlastní nastavení křížového ověření.
Můžete také použít vlastní ověřovací data. Další informace najdete v tématu Konfigurace trénování, ověřování, křížového ověření a testování dat v AutoML (SDK v1).