Hluboké učení s využitím prognózy AutoML
Tento článek se zaměřuje na metody hloubkového učení pro prognózování časových řad v AutoML. Pokyny a příklady pro trénování modelů prognóz v AutoML najdete v našem článku věnovaném nastavení AutoML pro prognózování časových řad.
Hluboké učení má mnoho případů použití v oblastech od jazykového modelování až po skládání bílkovin, mimo jiné. Prognózování časových řad také přináší výhody nedávných pokroků v technologii hlubokého učení. Například modely hloubkové neurální sítě (DNN) jsou výrazně zastoupeny v modelech s nejvyšším výkonem ze čtvrtého a pátého iterace vysoce profilované Makridakis prognózující konkurenci.
V tomto článku popisujeme strukturu a provoz modelu TCNForecaster v AutoML, který vám pomůže nejlépe použít model ve vašem scénáři.
Úvod do TCNForecaster
TCNForecaster je dočasná konvoluční síť neboli TCN, která má architekturu DNN určenou pro data časových řad. Model používá historická data pro cílové množství spolu se souvisejícími funkcemi k vytvoření pravděpodobnostních prognóz cíle až do zadaného horizontu prognózy. Následující obrázek ukazuje hlavní komponenty architektury TCNForecaster:

TCNForecaster má následující hlavní komponenty:
- Vrstva před mixem, která kombinuje vstupní časovou řadu a data funkcí do pole kanálů signálu, které konvoluční zásobník zpracovává.
- Zásobník dilovaných konvolučních vrstev, které postupně zpracovávají pole kanálu. Každá vrstva v zásobníku zpracovává výstup předchozí vrstvy za účelem vytvoření nového pole kanálu. Každý kanál v tomto výstupu obsahuje kombinaci konvolučních filtrovaných signálů ze vstupních kanálů.
- Kolekce předpovědí hlavových jednotek, které kompletují výstupní signály z konvolučních vrstev a generují prognózy cílového množství z této latentní reprezentace. Každá hlavní jednotka vytváří prognózy až do horizontu pro kvantily predikčního rozdělení.
Dilated kauzální konvoluce
Centrální provoz TCN je dilated, kauzální konvoluce podél časového rozměru vstupního signálu. Intuitivně konvoluce kombinuje hodnoty z blízkých časových bodů ve vstupu. Poměry ve směsi jsou jádro nebo váhy konvoluce, zatímco rozdělení mezi body v směsi je dilace. Výstupní signál se generuje ze vstupu posunutím jádra v čase podél vstupu a shromážděním směsi na každé pozici. Kauzální konvoluce je jedna, ve které jádro kombinuje pouze vstupní hodnoty v minulosti vzhledem k jednotlivým výstupním bodům, což brání tomu, aby se výstup "podíval" do budoucnosti.
Skládání dilovaných konvolucí dává TCN možnost modelovat korelace po dlouhou dobu ve vstupních signálech s relativně malými váhami jádra. Následující obrázek například ukazuje tři skládané vrstvy s jádrem se dvěma hmotnostmi v každé vrstvě a exponenciálním zvýšením dilačních faktorů:
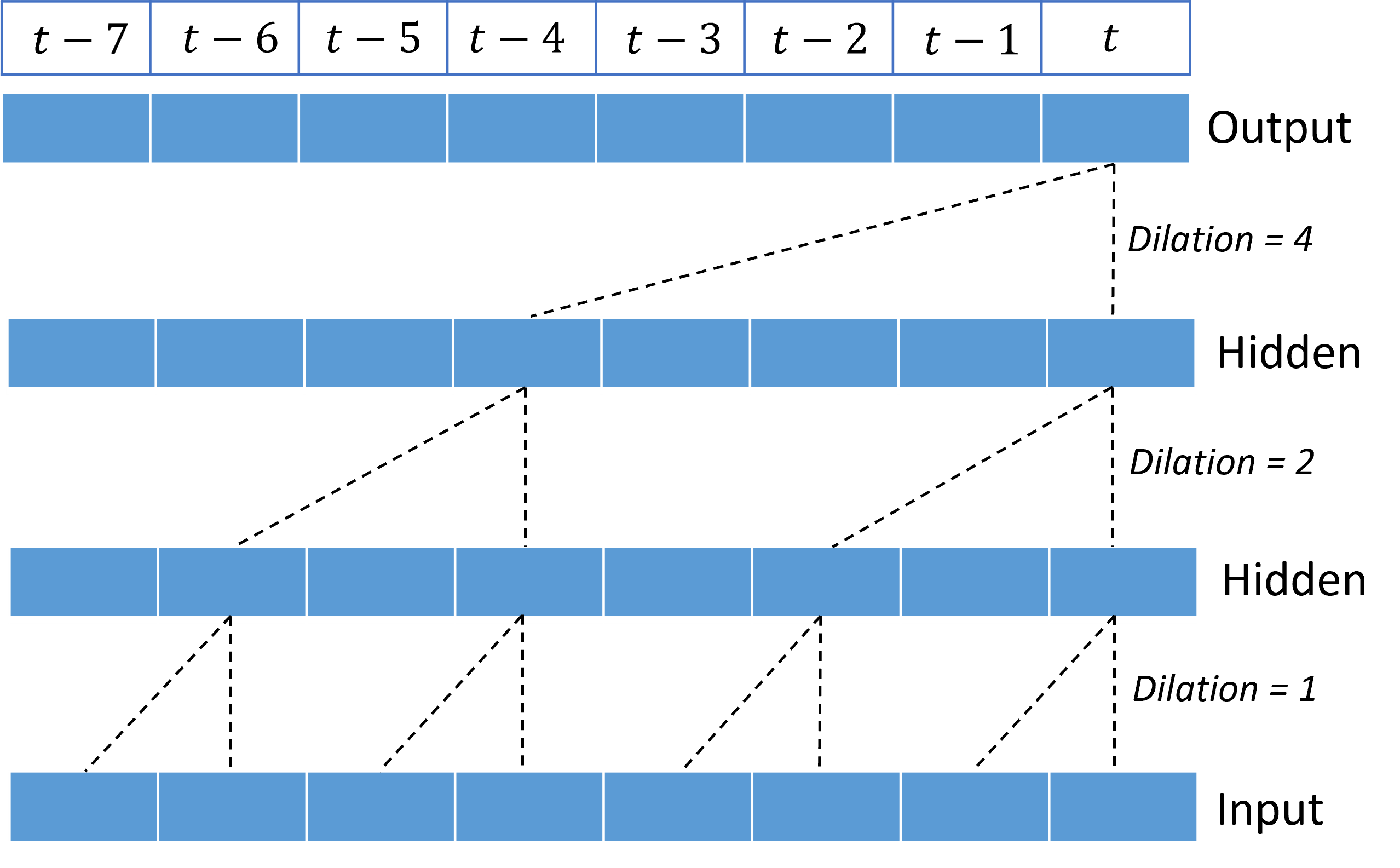
Přerušované čáry zobrazují cesty přes síť, která končí na výstupu najednou $t$. Tyto cesty pokrývají posledních osm bodů ve vstupu a ilustrují, že každý výstupní bod je funkcí osmi relativně posledních bodů ve vstupu. Délka historie nebo "ohlédni se", kterou konvoluční síť používá k vytváření předpovědí, se nazývá receptivní pole a je určena zcela architekturou TCN.
Architektura TCNForecaster
Jádrem architektury TCNForecaster je zásobník konvolučních vrstev mezi předmíchanými a předpovědí hlavy. Zásobník je logicky rozdělený do opakujících se jednotek nazývaných bloky , které se zase skládají ze zbytkových buněk. Reziduální buňka používá kauzální konvoluce v sadě dilace spolu s normalizací a nelineární aktivací. Důležité je, že každá zbytková buňka přidá svůj výstup do vstupu pomocí takzvaného zbytkového spojení. Tato připojení se ukázala jako přínosná pro trénování sítě DNN, třeba proto, že usnadňují efektivnější tok informací přes síť. Následující obrázek znázorňuje architekturu konvolučních vrstev pro ukázkovou síť se dvěma bloky a třemi zbytkovými buňkami v každém bloku:
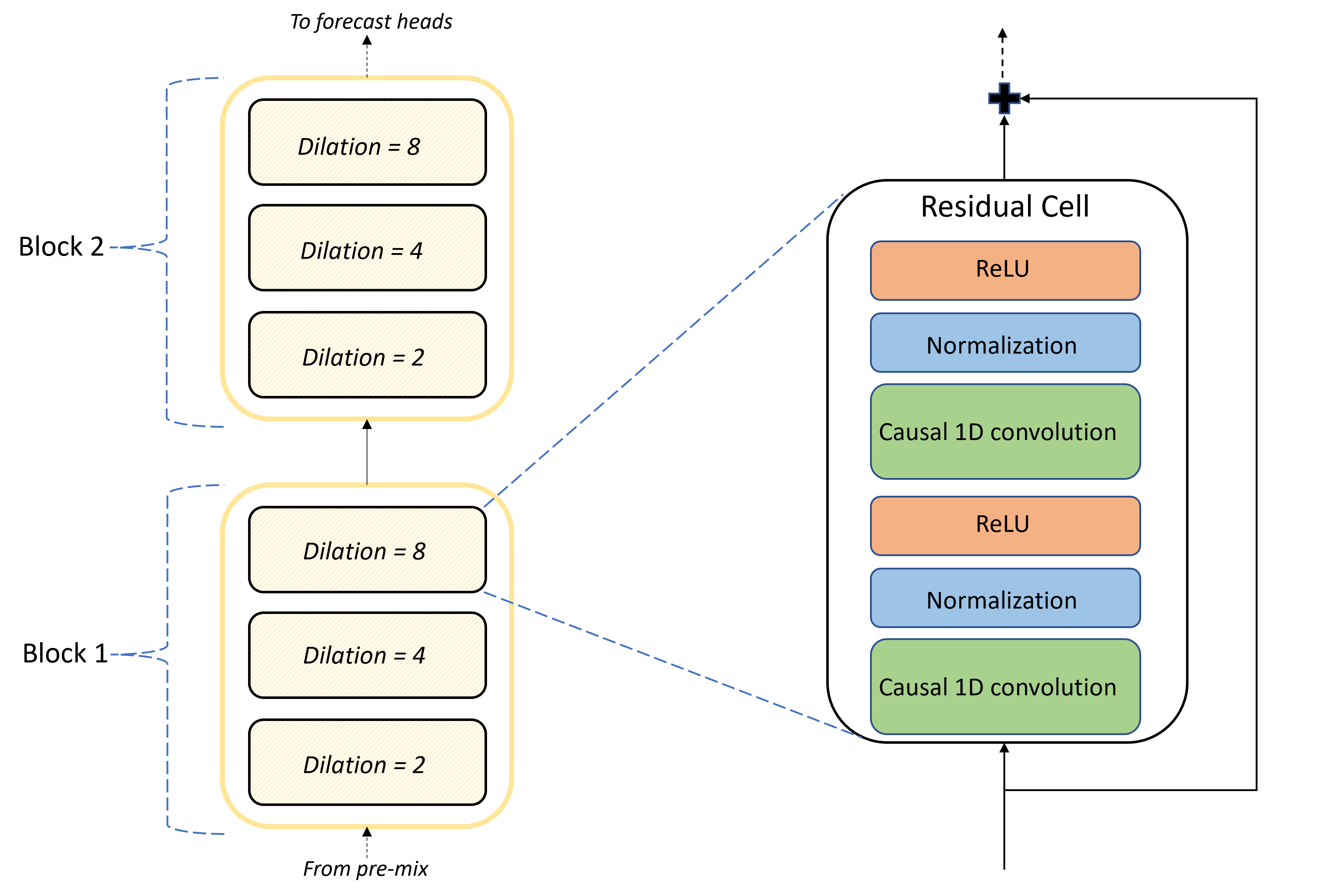
Počet bloků a buněk spolu s počtem kanálů signálu v každé vrstvě řídí velikost sítě. Parametry architektury TCNForecaster jsou shrnuty v následující tabulce:
| Parametr | Popis |
|---|---|
| $n_{b}$ | Počet bloků v síti; označuje se také jako hloubka. |
| $n_{c}$ | Počet buněk v každém bloku |
| $n_{\text{ch}}$ | Počet kanálů ve skrytých vrstvách |
Pole pro receptivní závisí na parametrech hloubky a je dáno vzorcem,
$t_{\text{rf}} = 4n_{b}\left(2^{n_{c}} - 1\right) + 1.$
Můžeme poskytnout přesnější definici architektury TCNForecaster z hlediska vzorců. Nechte $X$ vstupním polem, kde každý řádek obsahuje hodnoty funkcí ze vstupních dat. $X$ můžeme rozdělit na číselná a kategorická pole funkcí, $X_{\text{num}}$ a $X_{\text{cat}}$. Potom je TCNForecaster dán vzorci,
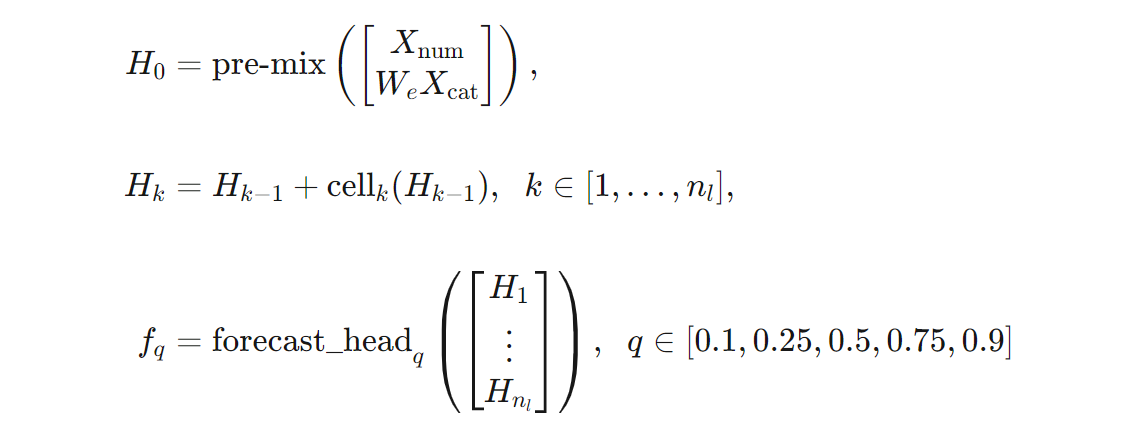
Kde $W_{e}$ je matice vkládání pro funkce kategorií, $n_{l} = n_{b}n_{c}$ je celkový počet zbytkových buněk, $H_{k}$ označují skryté výstupy vrstvy a $f_{q}$ jsou výstupy prognózy pro dané quantily rozdělení předpovědi. Pro pochopení jsou dimenze těchto proměnných v následující tabulce:
| Proměnná | Popis | Dimenze |
|---|---|---|
| $X$ | Vstupní pole | $n_{\text{input}} \times t_{\text{rf}}$ |
| $H_{i}$ | Skrytý výstup vrstvy pro $i=0,1,\ldots,n_{l}$ | $n_{\text{ch}} \times t_{\text{rf}}$ |
| $f_{q}$ | Výstup prognózy pro quantile $q$ | $h$ |
V tabulce $n_{\text{input}} = n_{\text{features}} + 1$, počet proměnných predictor/feature plus cílové množství. Hlavy prognózy generují všechny prognózy až do maximálního horizontu $h$ v jediném průchodu, takže TCNForecaster je přímý prognózer.
TCNForecaster v AutoML
TCNForecaster je volitelný model v AutoML. Informace o tom, jak ho používat, najdete v tématu povolení hlubokého učení.
V této části popisujeme, jak AutoML vytváří modely TCNForecaster s vašimi daty, včetně vysvětlení předběžného zpracování dat, trénování a vyhledávání modelů.
Kroky předběžného zpracování dat
AutoML provede několik kroků předběžného zpracování dat a připraví se na trénování modelu. Následující tabulka popisuje tyto kroky v pořadí, v jakém se provádějí:
| Krok | Popis |
|---|---|
| Vyplnění chybějících dat | Imputování chybějících hodnot a mezer pozorování a volitelně pad nebo pokles krátkých časových řad |
| Vytváření funkcí kalendáře | Rozšiřte vstupní data o funkce odvozené z kalendáře , jako je den v týdnu, případně svátky pro určitou zemi nebo oblast. |
| Kódování kategorických dat | Popisek kóduje řetězce a další typy kategorií. To zahrnuje všechny sloupce ID časové řady. |
| Cílová transformace | Volitelně můžete použít přirozený logaritmus na cíl v závislosti na výsledcích určitých statistických testů. |
| Normalizace | Skóre Z normalizuje všechna číselná data; normalizace se provádí podle funkce a skupiny časových řad, jak je definováno sloupci ID časové řady. |
Tyto kroky jsou součástí transformačních kanálů AutoML, takže se automaticky použijí v době odvozování. V některých případech je inverzní operace ke kroku zahrnuta do kanálu odvozování. Pokud například AutoML během trénování použilo transformaci $\log$ na cíl, nezpracované prognózy se v kanálu odvozování exponentují.
Školení
TCNForecaster se řídí osvědčenými postupy trénování DNN běžnými pro ostatní aplikace v obrázcích a jazyce. AutoML rozděluje předem zpracovaná trénovací data do příkladů , které se dají přehazovat a kombinovat do dávek. Síť postupně zpracovává dávky pomocí zpětného šíření a stochastického gradientního sestupu za účelem optimalizace hmotnosti sítě s ohledem na funkci ztráty. Trénování může vyžadovat mnoho průchodů úplnými trénovacími daty; každému průchodu se říká epocha.
Následující tabulka obsahuje seznam vstupních nastavení a parametrů pro trénování TCNForecaster:
| Trénovací vstup | Popis | Hodnota |
|---|---|---|
| Ověřovací data | Část dat, která se uchovávají od trénování, aby se provedla optimalizace sítě a zmírňovala přizpůsobení. | Poskytuje ho uživatel nebo automaticky vytvořený z trénovacích dat, pokud není k dispozici. |
| Primární metrika | Metrika vypočítaná z předpovědí mediánu hodnot na základě ověřovacích dat na konci každé epochy trénování; slouží k předčasnému zastavení a výběru modelu. | Zvoleno uživatelem; normalizovaná odmocněná střední kvadratická chyba nebo normalizovaná střední absolutní chyba. |
| Epochy trénování | Maximální počet epoch, které se mají spustit pro optimalizaci hmotnosti sítě. | 100; automatizovaná logika předčasného zastavení může ukončit trénování v menším počtu epoch. |
| Počáteční zastavení trpělivosti | Počet epoch, které čekají na zlepšení primární metriky před zastavením trénování | 20 |
| Funkce ztráty | Cílová funkce optimalizace hmotnosti sítě. | Quantile loss averaged over 10th, 25th, 50th, 75th, and 90th percentil forecasts. |
| Velikost dávky | Počet příkladů v dávce Každý příklad má rozměry $n_{\text{input}} \times t_{\text{rf}}$ pro vstup a $h$ pro výstup. | Určuje se automaticky z celkového počtu příkladů v trénovacích datech; maximální hodnota 1024. |
| Vložené dimenze | Dimenze vložených prostorů pro kategorické funkce | Automaticky se nastaví na čtvrtý kořen počtu jedinečných hodnot v jednotlivých funkcích zaokrouhlených nahoru na nejbližší celé číslo. Prahové hodnoty se použijí na minimální hodnotu 3 a maximální hodnotu 100. |
| Síťová architektura* | Parametry, které řídí velikost a tvar sítě: hloubka, počet buněk a počet kanálů. | Určeno vyhledáváním modelu. |
| Váhy sítě | Parametry, které řídí směsi signálů, kategorické vkládání, váhy jádra konvoluce a mapování na hodnoty prognózy. | Náhodně inicializováno a následně optimalizováno s ohledem na funkci ztráty. |
| Rychlost výuky* | Určuje, kolik síťových hmotností lze upravit v každé iteraci gradientního sestupu; dynamicky se snižuje téměř konvergence. | Určeno vyhledáváním modelu. |
| Poměr vyřazení* | Řídí míru regularizace vyřazení použitou na váhy sítě. | Určeno vyhledáváním modelu. |
Vstupy označené hvězdičkou (*) jsou určeny vyhledáváním hyperparametrů, které je popsáno v další části.
Vyhledávání modelů
AutoML používá metody vyhledávání modelů k vyhledání hodnot pro následující hyper-parametry:
- Hloubka sítě nebo počet konvolučních bloků,
- Počet buněk na blok,
- Počet kanálů v každé skryté vrstvě
- Poměr výpadků pro regularizaci sítě,
- Rychlost učení.
Optimální hodnoty těchto parametrů se můžou výrazně lišit v závislosti na scénáři problému a trénovacích datech, takže AutoML trénuje několik různých modelů v prostoru hodnot hyperparametrů a vybere nejlepší hodnoty podle primárního skóre metriky pro ověřovací data.
Hledání modelu má dvě fáze:
- AutoML provádí vyhledávání nad 12 "orientačními" modely. Modely orientačních bodů jsou statické a jsou zvoleny tak, aby byly přiměřeně rozloženy do prostoru hyperparametrů.
- AutoML pokračuje ve vyhledávání v prostoru hyperparametrů pomocí náhodného hledání.
Hledání se ukončí při splnění kritérií zastavení. Kritéria zastavení závisí na konfiguraci úlohy trénování prognózy, ale některé příklady zahrnují časové limity, omezení počtu zkušebních pokusů hledání, které se mají provést, a počáteční zastavení logiky v případě, že se metrika ověřování nezlepšuje.
Další kroky
- Zjistěte, jak nastavit AutoML pro trénování modelu prognózování časových řad.
- Přečtěte si o metodologii prognózování v AutoML.
- Projděte si nejčastější dotazy týkající se prognózování v AutoML.