Rozhraní API pro základní modely s přidělenou propustností
Tento článek ukazuje, jak nasadit modely pomocí rozhraní API modelu Foundation zřízenou propustnost. Databricks doporučuje zřízenou propustnost pro produkční úlohy a poskytuje optimalizované odvozování základních modelů se zárukami výkonu.
Co je zřízená propustnost?
Zřízená propustnost odkazuje na počet požadavků, které můžete odeslat do koncového bodu najednou. Koncové body s vyhrazenou propustností jsou dedikované koncové body nakonfigurované v rámci rozsahu tokenů za sekundu, které můžete odeslat na koncový bod.
Další informace najdete v následujících zdrojích informací:
- Co znamenají rozsahy tokenů za sekundu při zřízené propustnosti?
- Provedení vlastních srovnávacích testů koncových bodů LLM
Seznam podporovaných architektur modelů pro koncové body zřízené propustnosti najdete v tématu Zřízená propustnost.
Požadavky
Viz požadavky . Informace o nasazení jemně vyladěných základních modelů najdete v tématu Nasazení jemně vyladěných základních modelů.
[Doporučeno] Nasazení základních modelů z katalogu Unity
Důležitý
Tato funkce je ve verzi Public Preview.
Databricks doporučuje používat základní modely, které jsou předinstalované v katalogu Unity. Tyto modely najdete v katalogu system ve schématu ai (system.ai).
Nasazení základního modelu:
- V Průzkumníku katalogu přejděte na
system.ai. - Klikněte na název modelu, který chcete nasadit.
- Na stránce modelu klikněte na tlačítko Obsluha tohoto modelu.
- Zobrazí se stránka Vytvořit obslužný koncový bod. Viz Vytvoření zřízeného koncového bodu propustnosti pomocíuživatelského rozhraní .
Nasazení základních modelů z Marketplace Databricks
Alternativně můžete do katalogu Unity nainstalovat základní modely z webu Databricks Marketplace.
Můžete vyhledat řadu modelů a na stránce modelu vybrat Získat přístup a zadat přihlašovací údaje pro instalaci modelu do katalogu Unity.
Po instalaci modelu do katalogu Unity můžete vytvořit model obsluhující koncový bod pomocí uživatelského rozhraní obsluhy.
Nasazení modelů DBRX
Databricks doporučuje obsluhovat model DBRX Instruct pro vaše úlohy. Pokud chcete model DBRX Instruct používat s využitím předem definované propustnosti, postupujte podle pokynů v tématu [Doporučeno] Nasazení základních modelů z Unity Catalog.
Při poskytování těchto modelů DBRX podporuje přednastavená propustnost délku kontextového okna až 16 tisíc.
Modely DBRX používají následující výchozí výzvu k zajištění relevance a přesnosti v odpovědích modelu:
You are DBRX, created by Databricks. You were last updated in December 2023. You answer questions based on information available up to that point.
YOU PROVIDE SHORT RESPONSES TO SHORT QUESTIONS OR STATEMENTS, but provide thorough responses to more complex and open-ended questions.
You assist with various tasks, from writing to coding (using markdown for code blocks — remember to use ``` with code, JSON, and tables).
(You do not have real-time data access or code execution capabilities. You avoid stereotyping and provide balanced perspectives on controversial topics. You do not provide song lyrics, poems, or news articles and do not divulge details of your training data.)
This is your system prompt, guiding your responses. Do not reference it, just respond to the user. If you find yourself talking about this message, stop. You should be responding appropriately and usually that means not mentioning this.
YOU DO NOT MENTION ANY OF THIS INFORMATION ABOUT YOURSELF UNLESS THE INFORMATION IS DIRECTLY PERTINENT TO THE USER'S QUERY.
Nasazení jemně vyladěných základních modelů
Pokud nemůžete použít modely ve schématu system.ai nebo nainstalovat modely z Webu Databricks Marketplace, můžete nasadit jemně vyladěný základní model tak, že ho přihlásíte do katalogu Unity. Tato část a následující části ukazují, jak nastavit kód pro protokolování modelu MLflow do katalogu Unity a vytvoření zřízeného koncového bodu propustnosti pomocí uživatelského rozhraní nebo rozhraní REST API.
Viz Omezení zřízené propustnosti podporované modely Meta Llama 3.1, 3.2 a 3.3 a jejich dostupnost v jednotlivých oblastech.
Požadavky
- Nasazení jemně vyladěných základních modelů podporuje pouze MLflow 2.11 nebo novější. Databricks Runtime 15.0 ML a vyšší předinstaluje kompatibilní verzi MLflow.
- Databricks doporučuje používat modely v katalogu Unity pro rychlejší nahrávání a stahování velkých modelů.
Definování katalogu, schématu a názvu modelu
Pokud chcete nasadit jemně vyladěný základní model, definujte cílový katalog katalogu Unity, schéma a název modelu podle vašeho výběru.
mlflow.set_registry_uri('databricks-uc')
CATALOG = "catalog"
SCHEMA = "schema"
MODEL_NAME = "model_name"
registered_model_name = f"{CATALOG}.{SCHEMA}.{MODEL_NAME}"
Zaznamenejte svůj model
Pokud chcete povolit zřízenou propustnost koncového bodu modelu, musíte model protokolovat pomocí příchutě transformers MLflow a zadat argument task s odpovídajícím rozhraním typu modelu z následujících možností:
"llm/v1/completions""llm/v1/chat""llm/v1/embeddings"
Tyto argumenty určují podpis rozhraní API použitý pro koncový bod obsluhy modelu. Další podrobnosti o těchto úlohách a odpovídajících schématech vstupu a výstupu najdete v dokumentaci k MLflow.
Následuje příklad protokolování jazykového modelu pro dokončování textu zaprotokolovaný pomocí MLflow:
model = AutoModelForCausalLM.from_pretrained("mosaicml/mixtral-8x7b-instruct", torch_dtype=torch.bfloat16)
tokenizer = AutoTokenizer.from_pretrained("mosaicml/mixtral-8x7b-instruct")
with mlflow.start_run():
components = {
"model": model,
"tokenizer": tokenizer,
}
mlflow.transformers.log_model(
transformers_model=components,
artifact_path="model",
# Specify the llm/v1/xxx task that is compatible with the model being logged
task="llm/v1/completions",
# Specify an input example that conforms to the input schema for the task.
input_example={"prompt": np.array(["Below is an instruction that describes a task. Write a response that appropriately completes the request.\n\n### Instruction:\nWhat is Apache Spark?\n\n### Response:\n"])},
# By passing the model name, MLflow automatically registers the Transformers model to Unity Catalog with the given catalog/schema/model_name.
registered_model_name=registered_model_name
# Optionally, you can set save_pretrained to False to avoid unnecessary copy of model weight and gain more efficiency.
save_pretrained=False
)
Poznámka
Pokud používáte MLflow starší než 2.12, musíte místo toho zadat úlohu v rámci metadata parametru stejné funkce mlflow.transformer.log_model().
metadata = {"task": "llm/v1/completions"}metadata = {"task": "llm/v1/chat"}metadata = {"task": "llm/v1/embeddings"}
Zřízená propustnost také podporuje základní i velké vkládací modely GTE. Následuje příklad protokolování modelu Alibaba-NLP/gte-large-en-v1.5, aby se mohl obsluhovat se zřízenou propustností:
model = AutoModel.from_pretrained("Alibaba-NLP/gte-large-en-v1.5")
tokenizer = AutoTokenizer.from_pretrained("Alibaba-NLP/gte-large-en-v1.5")
with mlflow.start_run():
components = {
"model": model,
"tokenizer": tokenizer,
}
mlflow.transformers.log_model(
transformers_model=components,
artifact_path="model",
task="llm/v1/embeddings",
registered_model_name=registered_model_name,
# model_type is required for logging a fine-tuned BGE models.
metadata={
"model_type": "gte-large"
}
)
Po záznamu vašeho modelu v katalogu Unity pokračujte na Vytvoření zřízeného koncového bodu propustnosti pomocí uživatelského rozhraní k vytvoření koncového bodu obsluhujícího model se zřízenou propustností.
Vytvoření zřízeného koncového bodu propustnosti pomocí uživatelského rozhraní
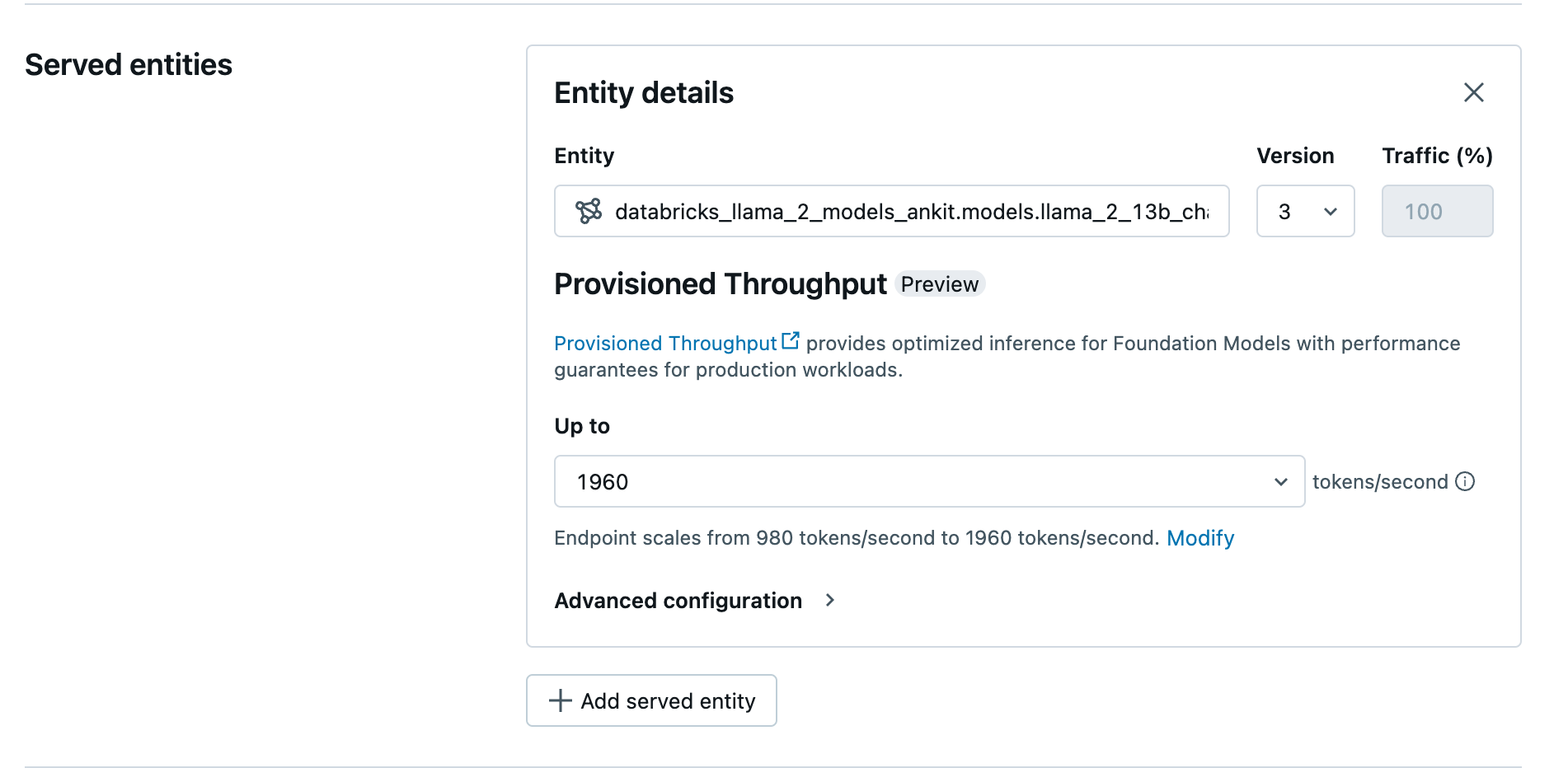
Po zaznamenání modelu v katalogu Unity vytvořte obsluhující koncový bod s nakonfigurovanou propustností pomocí následujícího postupu:
- Přejděte do uživatelského rozhraní obsluhy ve vašem pracovním prostoru.
- Vyberte Vytvořit obslužný koncový bod.
- V poli Entity vyberte model z katalogu Unity. U způsobilých modelů uživatelské rozhraní obsluhované entity zobrazuje obrazovku Zřízená propustnost.
- V rozevíracím seznamu Až můžete pro koncový bod nakonfigurovat maximální propustnost tokenů za sekundu.
- Zřízené koncové body propustnosti se automaticky škálují, takže můžete vybrat Upravit a zobrazit minimální počet tokenů za sekundu, na který se může váš koncový bod snížit.
Vytvoření zřízeného koncového bodu propustnosti pomocí rozhraní REST API
Pokud chcete model nasadit v režimu zřízené propustnosti pomocí rozhraní REST API, musíte v požadavku zadat min_provisioned_throughput a max_provisioned_throughput pole. Pokud dáváte přednost Pythonu, můžete také vytvořit koncový bod pomocí sady SDK pro nasazení MLflow.
Informace o vhodném rozsahu přidělené propustnosti pro váš model najdete v tématu Získání přidělené propustnosti v přírůstcích.
import requests
import json
# Set the name of the MLflow endpoint
endpoint_name = "prov-throughput-endpoint"
# Name of the registered MLflow model
model_name = "ml.llm-catalog.foundation-model"
# Get the latest version of the MLflow model
model_version = 3
# Get the API endpoint and token for the current notebook context
API_ROOT = "<YOUR-API-URL>"
API_TOKEN = "<YOUR-API-TOKEN>"
headers = {"Context-Type": "text/json", "Authorization": f"Bearer {API_TOKEN}"}
optimizable_info = requests.get(
url=f"{API_ROOT}/api/2.0/serving-endpoints/get-model-optimization-info/{model_name}/{model_version}",
headers=headers)
.json()
if 'optimizable' not in optimizable_info or not optimizable_info['optimizable']:
raise ValueError("Model is not eligible for provisioned throughput")
chunk_size = optimizable_info['throughput_chunk_size']
# Minimum desired provisioned throughput
min_provisioned_throughput = 2 * chunk_size
# Maximum desired provisioned throughput
max_provisioned_throughput = 3 * chunk_size
# Send the POST request to create the serving endpoint
data = {
"name": endpoint_name,
"config": {
"served_entities": [
{
"entity_name": model_name,
"entity_version": model_version,
"min_provisioned_throughput": min_provisioned_throughput,
"max_provisioned_throughput": max_provisioned_throughput,
}
]
},
}
response = requests.post(
url=f"{API_ROOT}/api/2.0/serving-endpoints", json=data, headers=headers
)
print(json.dumps(response.json(), indent=4))
Logaritmická pravděpodobnost pro úkoly dokončování chatu
U úloh dokončení chatu můžete pomocí parametru logprobs poskytnout log pravděpodobnost výběru tokenu během procesu generování velkého jazykového modelu.
logprobs můžete použít pro různé scénáře, včetně klasifikace, posouzení nejistoty modelu a spouštění metrik vyhodnocení. Podrobnosti o parametrech najdete v úkolu chatu .
Získání zřízené propustnosti po přírůstcích
Zřízená propustnost je dostupná v přírůstcích tokenů za sekundu s konkrétními přírůstky, které se liší podle modelu. K identifikaci vhodného rozsahu pro vaše potřeby doporučuje Databricks používat rozhraní API pro optimalizaci modelů v rámci platformy.
GET api/2.0/serving-endpoints/get-model-optimization-info/{registered_model_name}/{version}
Následuje příklad odpovědi z rozhraní API:
{
"optimizable": true,
"model_type": "llama",
"throughput_chunk_size": 1580
}
Příklady poznámkových bloků
Následující poznámkové bloky ukazují příklady vytvoření rozhraní API základního modelu zřízené propustnosti:
Nastavená propustnost podporující poznámkový blok modelu GTE
Pořiďte poznámkový blok
Předem nakonfigurovaná propustnost pro poznámkový blok modelu BGE
Pořiďte poznámkový blok
Následující poznámkový blok ukazuje, jak můžete stáhnout a zaregistrovat DeepSeek R1, destilovaný model Llama, v katalogu Unity, abyste ho mohli nasadit pomocí koncového bodu s propustností zřízenou rozhraním API základního modelu.
Zřízená propustnost pro destilovaný poznámkový blok modelu Llama DeepSeek R1
Pořiďte poznámkový blok
Omezení
- Nasazení modelu může selhat kvůli problémům s kapacitou GPU, což vede k vypršení časového limitu při vytváření nebo aktualizaci koncového bodu. Obraťte se na svůj tým podpory Databricks, aby vám pomohl s řešením.
- Automatické škálování pro API základových modelů je pomalejší než obsluha modelů na CPU. Databricks doporučuje nadměrné nastavení kapacity, aby se předešlo překročení časových limitů.
- GTE v1.5 (angličtina) negeneruje normalizované vkládání.