Provedení vlastních srovnávacích testů koncových bodů LLM
Tento článek obsahuje příklad doporučeného poznámkového bloku Databricks pro srovnávací testy koncového bodu LLM. Obsahuje také stručný úvod k tomu, jak Databricks provádí odvozování LLM a vypočítá latenci a propustnost jako metriky výkonu koncových bodů.
Odvozování LLM u Databricks měří tokeny za sekundu pro zřízený režim propustnosti pro rozhraní API základního modelu. Viz Co znamenají tokeny za sekundu v přidělené propustnosti?.
Ukázkový „notebook“ pro srovnávací testování
Následující poznámkový blok můžete naimportovat do prostředí Databricks a zadat název koncového bodu LLM pro spuštění zátěžového testu.
Srovnávací testy koncového bodu LLM
Vezmi poznámkový blok
úvod k odvozování LLM
LLM provádí odvozování ve dvou krocích:
- Předvyplnit, kde se tokeny ve vstupní výzvě zpracovávají paralelně.
- dekódování, kde se text generuje po jednom tokenu automaticky regresivním způsobem. Každý vygenerovaný token se připojí ke vstupu a vrátí se do modelu, aby se vygeneroval další token. Generování se zastaví, když LLM vypíše speciální token zastavení nebo když je splněna podmínka definovaná uživatelem.
Většina produkčních aplikací má stanovený limit latence a společnost Databricks doporučuje maximalizovat propustnost v rámci tohoto limitu latence.
- Počet vstupních tokenů má významný vliv na požadovanou paměť pro zpracování požadavků.
- Celkový počet výstupních tokenů dominuje celkové latenci odezvy.
Databricks rozděluje inferenci LLM do následujících dílčích metrik:
- Čas na první token (TTFT): Takto rychle uživatelé začnou po zadání dotazu vidět výstup modelu. Nízká doba čekání na odpověď je nezbytná v interakcích v reálném čase, ale méně důležitá v offline úlohách. Tato metrika se řídí časem potřebným ke zpracování výzvy a následnému vygenerování prvního výstupního tokenu.
- Čas na výstupní token (TPOT): Doba potřebná k vygenerování výstupního tokenu pro každého uživatele, který dotazuje systém. Tato metrika odpovídá tomu, jak každý uživatel vnímá "rychlost" modelu. Například TPOT 100 milisekund na token by znamenal 10 tokenů za sekundu nebo přibližně 450 slov za minutu, což je rychlejší, než obvykle dokáže člověk číst.
Na základě těchto metrik je možné celkovou latenci a propustnost definovat následujícím způsobem:
- latence = TTFT + (TPOT) * (počet vygenerovaných tokenů)
- propustnost = počet výstupních tokenů za sekundu napříč všemi požadavky souběžnosti
V Databricks dokáže obsluhující koncové body LLM škálovat tak, aby odpovídaly zatížení odeslanému klienty s několika souběžnými požadavky. Mezi latencí a propustností je kompromis. Důvodem je, že na koncových bodech pro obsluhu LLM mohou být souběžné požadavky a jsou zpracovávány současně. Při nízkých souběžných zatíženích požadavků je latence nejnižší možná. Pokud ale zvýšíte zatížení požadavku, může se latence zvýšit, ale propustnost se pravděpodobně zvýší. Důvodem je to, že dva požadavky na tokeny za sekundu je možné zpracovat za méně než dvojnásobek času.
Řízení počtu paralelních požadavků v systému je proto jádrem pro vyrovnávání latence s propustností. Pokud máte případ použití s nízkou latencí, chcete do koncového bodu odeslat méně souběžných požadavků, aby byla latence nízká. Pokud máte případ použití s vysokou propustností, chcete koncový bod nasytit spoustou požadavků souběžnosti, protože vyšší propustnost stojí za to i na úkor latence.
- Případy použití vysoké propustnosti můžou zahrnovat dávkové predikce a další úlohy, které nejsou zaměřené na uživatele.
- Případy použití s nízkou latencí můžou zahrnovat aplikace v reálném čase, které vyžadují okamžité odpovědi.
Nástroj pro srovnávací testování Databricks
Dříve sdílený ukázkový poznámkový blok srovnávacích testů je nástroj pro srovnávací testy Databricks. Poznámkový blok zobrazuje celkovou latenci napříč všemi požadavky a metriky propustnosti a vykresluje křivku propustnosti ve vztahu k latenci při různých počtech paralelních požadavků. Strategie automatického škálování koncového bodu Databricks se vyrovnává mezi latencí a propustností. V poznámkovém bloku zjistíte, že latence a propustnost se zvyšují, jakmile více souběžných uživatelů odesílá dotazy na koncový bod.
Začnete ale také vidět, že s rostoucím počtem paralelních požadavků se propustnost začne vyrovnávat, dosahující limitu přibližně 8 000 tokenů za sekundu. K této plošině dochází, protože zřízená propustnost koncového bodu omezuje počet pracovních procesů a paralelních požadavků, které je možné provést. Vzhledem k tomu, že se více požadavků provádí nad rámec toho, co koncový bod dokáže zpracovat současně, celková latence se bude dál zvyšovat, protože ve frontě čekají další požadavky.
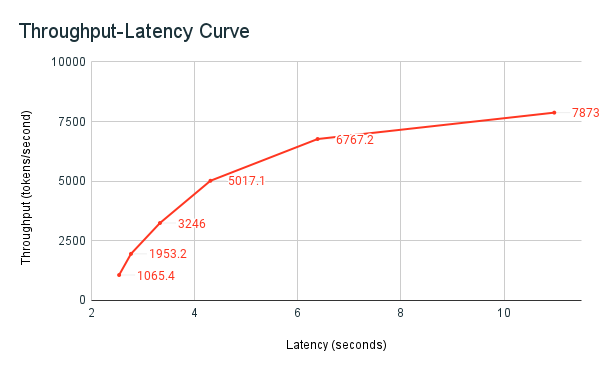
Další podrobnosti o filozofii společnosti Databricks týkající se srovnávacích testů výkonu LLM jsou popsány v blogu LLM Inference Performance Engineering: Osvědčené postupy.