Co znamenají rozsahy tokenů za sekundu v konfigurované propustnosti?
Tento článek popisuje, jak a proč Databricks měří tokeny za sekundu pro vyhrazené úlohy propustnosti rozhraní API modelu základu .
Výkon velkých jazykových modelů (LLM) se často měří z hlediska tokenů za sekundu. Při konfiguraci produkčního modelu obsluhujícího koncové body je důležité zvážit počet požadavků, které vaše aplikace odešle do koncového bodu. To vám pomůže pochopit, jestli je potřeba nakonfigurovat koncový bod tak, aby se škáloval, aby to nemělo vliv na latenci.
Když konfigurujete škálovací rozsahy pro koncové body nasazené se zřízenou propustností, Databricks zjistila, že je snazší zdůvodnit vstupy přicházející do vašeho systému pomocí tokenů.
Co jsou tokeny?
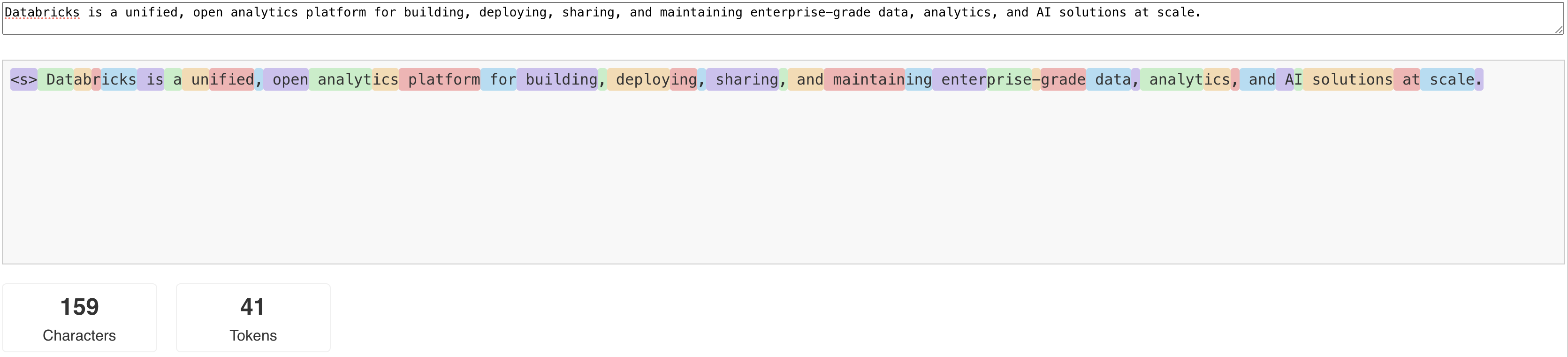
Modely zpracování přirozeného jazyka (LLM) čtou a generují text podle toho, co se nazývá token . Tokeny můžou být slova nebo dílčí slova a přesná pravidla pro rozdělení textu na tokeny se liší od modelu po model. Pomocí online nástrojů můžete například zjistit, jak Tokenizátor Llama převádí slova na tokeny.
Následující diagram znázorňuje příklad toho, jak tokenizátor Llama rozdělí text:
Proč měřit výkon LLM z hlediska tokenů za sekundu?
Tradičně se koncové body obsluhy konfigurují na základě počtu souběžných požadavků za sekundu (RPS). Požadavek na inferenci LLM ale trvá různě dlouho liší se časová náročnost podle toho, kolik tokenů se předává a kolik vygeneruje, což může vést k nerovnováze mezi jednotlivými požadavky. Proto při rozhodování o tom, kolik škálování váš koncový bod potřebuje, je skutečně nutné měřit škálování koncových bodů podle obsahu vašeho požadavku – tokenů.
Různé případy použití mají různé poměry vstupních a výstupních tokenů:
- různé délky vstupních kontextů: I když některé požadavky můžou zahrnovat jenom několik vstupních tokenů, například krátkou otázku, jiné můžou zahrnovat stovky nebo dokonce tisíce tokenů, jako je dlouhý dokument pro shrnutí. Díky této variabilitě je konfigurace koncového bodu obsluhy založená pouze na rpS náročná, protože nezohláňuje různé požadavky na zpracování různých požadavků.
- různé délky výstupu v závislosti na případu použití: Různé případy použití pro LLM můžou vést k výrazně odlišným délkám výstupních tokenů. Generování výstupních tokenů je časově nejnáročnější částí inferenčního procesu LLM, takže to může dramaticky ovlivnit propustnost. Například shrnutí zahrnuje kratší a údernější odpovědi, ale generování textu, jako je psaní článků nebo popisů produktů, může vytvářet mnohem delší odpovědi.
Jak zvolím rozsah tokenů za sekundu pro koncový bod?
Zřízené koncové body pro obsluhu propustnosti se konfigurují z hlediska rozsahu tokenů za sekundu, které můžete odeslat do koncového bodu. Koncový bod se škáluje nahoru a dolů, aby zvládl zatížení produkční aplikace. Jste účtováni za hodinu na základě rozsahu tokenů za sekundu, kterému je váš koncový bod přizpůsoben.
Nejlepším způsobem, jak zjistit, jaký rozsah tokenů za sekundu na koncovém bodu s nastavenou propustností bude fungovat ve vašem případě použití, je provést zátěžový test s reprezentativní datovou sadou. Viz Provedení vlastních srovnávacích testů koncových bodů LLM.
Je potřeba vzít v úvahu dva důležité faktory:
- Jak Databricks měří výkon LLM v počtu tokenů za sekundu.
- Jak funguje automatické škálování
Jak Databricks měří výkon LLM v počtu tokenů za sekundu
Databricks provádí srovnávací testy koncových bodů s ohledem na úlohu, která představuje úkoly souhrnu běžné pro případy použití generace obohacené o načítání. Konkrétně se úloha skládá z:
- Vstupní tokeny 2048
- 256 výstupních tokenů
Rozsahy tokenů zobrazené kombinují propustnost vstupního a výstupního tokenu a ve výchozím nastavení optimalizují vyrovnávání propustnosti a latence.
Databricks stanovuje, že uživatelé mohou současně posílat do koncového bodu tolik tokenů za sekundu při velikosti dávky 1 na požadavek. Tím se simuluje více požadavků, které dorazí na koncový bod současně, což přesněji představuje způsob, jakým byste ve skutečnosti používali koncový bod v produkčním prostředí.
- Pokud má například zřízený koncový bod pro obsluhu propustnosti nastavenou rychlost 2304 tokenů za sekundu (2048 + 256), pak se očekává, že spuštění jednoho požadavku se vstupem 2048 tokenů a očekávaný výstup 256 tokenů bude trvat přibližně jednu sekundu.
- Podobně platí, že pokud je rychlost nastavena na 5600, můžete očekávat, že jeden požadavek s výše uvedenými počty vstupních a výstupních tokenů bude spuštěn přibližně za 0,5 sekundy – to znamená, že koncový bod může zpracovat dva podobné požadavky přibližně za jednu sekundu.
Pokud se vaše úloha liší od výše uvedeného, můžete očekávat, že se latence bude lišit s ohledem na uvedenou zřízenou rychlost propustnosti. Jak jsme uvedli dříve, generování více výstupních tokenů je časově náročnější než zahrnutí více vstupních tokenů. Pokud provádíte dávkové odvozování a chcete odhadnout dobu, kterou bude trvat dokončení, můžete vypočítat průměrný počet vstupních a výstupních tokenů a porovnat s výše uvedenou úlohou srovnávacího testu Databricks.
- Pokud máte například 1 000 řádků s průměrným počtem vstupních tokenů 3000 a průměrným počtem výstupních tokenů 500 a zřízenou propustností 3500 tokenů za sekundu, může trvat delší než 1 000 sekund (jedna sekunda za řádek), protože průměrné počty tokenů jsou větší než srovnávací test Databricks.
- Podobně, pokud máte 1 000 řádků, průměrný vstup 1 500 tokenů, průměrný výstup 100 tokenů a zřízenou propustnost 1 600 tokenů za sekundu, může to trvat méně než celkem 1 000 sekund (jedna sekunda za řádek) kvůli tomu, že váš průměrný počet tokenů je méně než referenční hodnota Databricks.
Pokud chcete odhadnout ideální zřízenou propustnost potřebnou k dokončení úlohy odvozování dávky, můžete použít poznámkový blok v Provést odvozování dávky LLM pomocí ai_query
Jak funguje automatické škálování
Model Serving se vyznačuje rychle reagujícím systémem automatického škálování, který přizpůsobuje základní výpočetní kapacitu tak, aby splnila požadavky vaší aplikace na počet tokenů za sekundu. Databricks vertikálně navyšuje zřízenou propustnost v blocích tokenů za sekundu, takže se vám účtují další jednotky zřízené propustnosti jenom v případě, že je používáte.
Následující graf latence propustnosti ukazuje testovaný koncový bod zřízené propustnosti s rostoucím počtem paralelních požadavků. První bod představuje 1 požadavek, druhý, 2 paralelní požadavky, třetí, 4 paralelní požadavky atd. S rostoucím počtem požadavků a tím i požadovaných tokenů za sekundu zjistíte, že se zvyšuje také zřízená propustnost. Toto zvýšení znamená, že automatické škálování zvyšuje dostupné výpočetní prostředky. Možná ale začnete vidět, že propustnost začíná dostávat na plošinu a dosáhnout limitu přibližně 8 000 tokenů za sekundu, v důsledku toho, že se zadávají další paralelní požadavky. Celková latence se zvyšuje, protože před zpracováním musí čekat více požadavků ve frontě, protože přidělený výpočetní objekt se používá současně.
Poznámka
Propustnost můžete zachovat konzistentně vypnutím škálování na nulu a konfigurací minimální propustnosti pro koncový bod obsluhy. Tím se vyhnete nutnosti čekat na zvýšení kapacity koncového bodu.
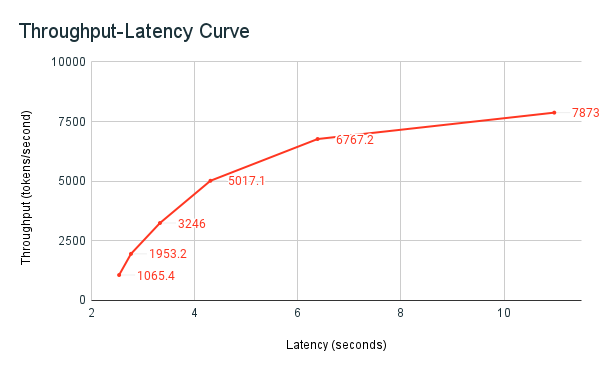
Můžete se také podívat z modelu obsluhující koncový bod, jak se prostředky v závislosti na poptávce roztáhnou nahoru nebo dolů:
obrázek