Co je služba funkcí Databricks?
Funkce Databricks Obsluha zpřístupňuje data na platformě Databricks pro modely nebo aplikace nasazené mimo Azure Databricks. Funkce obsluhující koncové body se automaticky škálují tak, aby se přizpůsobily provozu v reálném čase a poskytovaly službu s vysokou dostupností a nízkou latencí pro poskytování funkcí. Tato stránka popisuje, jak nastavit a používat Feature Serving. Podrobný kurz najdete v tématu Nasazení a dotazování koncového bodu obsluhy funkcí.
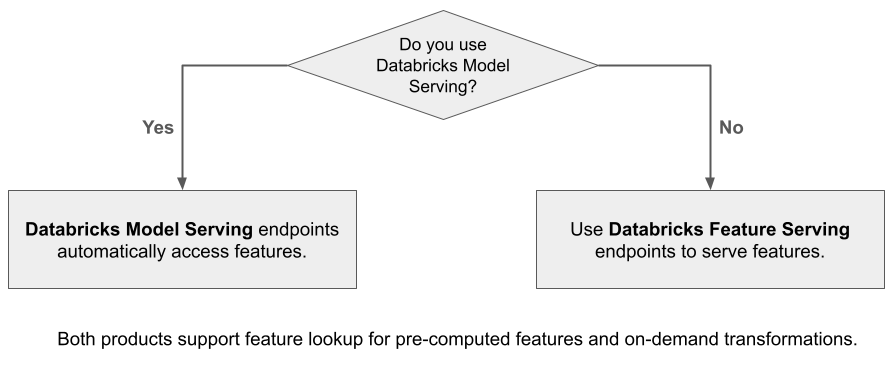
Když použijete službu Rozhraní AI Model Serving pro obsluhu modelu vytvořeného pomocí funkcí z Databricks, model automaticky vyhledá a transformuje funkce pro žádosti o odvozování. Pomocí služby Databricks pro poskytování vlastností můžete nabízet strukturovaná data pro aplikace podporující generování s rozšířeným vyhledáváním (RAG), stejně jako vlastnosti, které jsou potřebné pro jiné aplikace, jako jsou modely poskytované mimo Databricks nebo jakákoli jiná aplikace, která vyžaduje vlastnosti založené na datech v Unity Catalogu.
Proč používat funkci obsluhy?
Služba funkcí Databricks poskytuje jedno rozhraní, které obsluhuje před materializované funkce a funkce na vyžádání. Zahrnuje také následující výhody:
- Jednoduchost. Databricks zpracovává infrastrukturu. S jedním voláním rozhraní API vytvoří Databricks produkční prostředí pro obsluhu.
- Vysoká dostupnost a škálovatelnost. Funkce obsluhující koncové body se automaticky škálují nahoru a dolů, aby se přizpůsobily objemu obsluhovaných požadavků.
- Zabezpečení. Koncové body se nasazují v zabezpečené síťové hranici a používají vyhrazené výpočetní prostředky, které se ukončí při odstranění nebo škálování koncového bodu na nulu.
Požadavky
- Databricks Runtime 14.2 ML nebo novější
- Aby bylo možné používat rozhraní PYTHON API, služba funkcí vyžaduje
databricks-feature-engineeringverzi 0.1.2 nebo vyšší, která je integrovaná do Databricks Runtime 14.2 ML. Pro starší verze Databricks Runtime ML ručně nainstalujte požadovanou verzi pomocí%pip install databricks-feature-engineering>=0.1.2. Pokud používáte poznámkový blok Databricks, musíte restartovat jádro Pythonu spuštěním tohoto příkazu v nové buňce:dbutils.library.restartPython(). - Pokud chcete použít sadu Databricks SDK, služba funkcí vyžaduje
databricks-sdkverzi 0.18.0 nebo vyšší. Chcete-li ručně nainstalovat požadovanou verzi, použijte%pip install databricks-sdk>=0.18.0. Pokud používáte poznámkový blok Databricks, musíte restartovat jádro Pythonu spuštěním tohoto příkazu v nové buňce:dbutils.library.restartPython().
Služba funkcí Databricks poskytuje uživatelské rozhraní a několik programových možností pro vytváření, aktualizaci, dotazování a odstraňování koncových bodů. Tento článek obsahuje pokyny pro každou z následujících možností:
- Uživatelské rozhraní Databricks
- REST API
- Rozhraní API pro Python
- Databricks SDK
Pokud chcete použít rozhraní REST API nebo sadu SDK pro nasazení MLflow, musíte mít token rozhraní API Databricks.
Důležité
Jako osvědčený postup zabezpečení pro produkční scénáře doporučuje Databricks používat tokeny OAuth počítače pro ověřování během produkčního prostředí.
Pro účely testování a vývoje doporučuje Databricks místo uživatelů pracovního prostoru používat osobní přístupový token patřící instančním objektům . Pokud chcete vytvořit tokeny pro instanční objekty, přečtěte si téma Správa tokenů instančního objektu.
Ověřování pro obsluhu funkcí
Informace o ověřování najdete v tématu Autorizace přístupu k prostředkům Azure Databricks.
Vytvořte soubor FeatureSpec
FeatureSpec je uživatelsky definovaná sada vlastností a funkcí. Funkce a funkce můžete zkombinovat v objektu FeatureSpec.
FeatureSpecs se ukládají a spravují pomocí katalogu Unity a zobrazují se v Průzkumníku katalogu.
Tabulky zadané v FeatureSpec musí být publikovány v online tabulce nebo v online obchodě třetí strany. Viz Online tabulky pro poskytování funkcí v reálném čase nebo online obchody třetích stran.
K vytvoření souboru databricks-feature-engineeringje nutné použít FeatureSpec balíček .
from databricks.feature_engineering import (
FeatureFunction,
FeatureLookup,
FeatureEngineeringClient,
)
fe = FeatureEngineeringClient()
features = [
# Lookup column `average_yearly_spend` and `country` from a table in UC by the input `user_id`.
FeatureLookup(
table_name="main.default.customer_profile",
lookup_key="user_id",
feature_names=["average_yearly_spend", "country"]
),
# Calculate a new feature called `spending_gap` - the difference between `ytd_spend` and `average_yearly_spend`.
FeatureFunction(
udf_name="main.default.difference",
output_name="spending_gap",
# Bind the function parameter with input from other features or from request.
# The function calculates a - b.
input_bindings={"a": "ytd_spend", "b": "average_yearly_spend"},
),
]
# Create a `FeatureSpec` with the features defined above.
# The `FeatureSpec` can be accessed in Unity Catalog as a function.
fe.create_feature_spec(
name="main.default.customer_features",
features=features,
)
Vytvoření koncového bodu
Definuje FeatureSpec koncový bod. Další informace najdete v tématu Vytvoření vlastního modelu obsluhující koncové body, dokumentaci k rozhraní Python API nebo dokumentaci k sadě Databricks SDK.
Poznámka:
U úloh, které jsou citlivé na latenci nebo vyžadují vysoké dotazy za sekundu, nabízí služba Model Serving optimalizaci tras u vlastních koncových bodů obsluhy modelů, viz Konfigurace optimalizace trasy pro obsluhu koncových bodů.
REST API
curl -X POST -u token:$DATABRICKS_API_TOKEN ${WORKSPACE_URL}/api/2.0/serving-endpoints \
-H 'Content-Type: application/json' \
-d '"name": "customer-features",
"config": {
"served_entities": [
{
"entity_name": "main.default.customer_features",
"workload_size": "Small",
"scale_to_zero_enabled": true
}
]
}'
Databricks SDK – Python
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.serving import EndpointCoreConfigInput, ServedEntityInput
workspace = WorkspaceClient()
# Create endpoint
workspace.serving_endpoints.create(
name="my-serving-endpoint",
config = EndpointCoreConfigInput(
served_entities=[
ServedEntityInput(
entity_name="main.default.customer_features",
scale_to_zero_enabled=True,
workload_size="Small"
)
]
)
)
Rozhraní API pro Python
from databricks.feature_engineering.entities.feature_serving_endpoint import (
ServedEntity,
EndpointCoreConfig,
)
fe.create_feature_serving_endpoint(
name="customer-features",
config=EndpointCoreConfig(
served_entities=ServedEntity(
feature_spec_name="main.default.customer_features",
workload_size="Small",
scale_to_zero_enabled=True,
instance_profile_arn=None,
)
)
)
Pokud chcete zobrazit koncový bod, klikněte na obsluhu v levém bočním panelu uživatelského rozhraní Databricks. Jakmile je stav Připraveno, koncový bod je připravený reagovat na dotazy. Další informace o obsluhě modelu Mosaic AI najdete v tématu O obsluhě modelu AI v systému Mosaic AI.
Získání koncového bodu
K získání metadat a stavu koncového bodu můžete použít sadu Databricks SDK nebo rozhraní Python API.
Databricks SDK – Python
endpoint = workspace.serving_endpoints.get(name="customer-features")
# print(endpoint)
Rozhraní API pro Python
endpoint = fe.get_feature_serving_endpoint(name="customer-features")
# print(endpoint)
Získání schématu koncového bodu
K získání schématu koncového bodu můžete použít rozhraní REST API. Další informace o schématu koncového bodu naleznete v tématu Získání modelu obsluhující schéma koncového bodu.
ACCESS_TOKEN=<token>
ENDPOINT_NAME=<endpoint name>
curl "https://example.databricks.com/api/2.0/serving-endpoints/$ENDPOINT_NAME/openapi" -H "Authorization: Bearer $ACCESS_TOKEN" -H "Content-Type: application/json"
Dotazování koncového bodu
K dotazování koncového bodu můžete použít rozhraní REST API, sadu MLflow Deployments SDK nebo obslužné uživatelské rozhraní.
Následující kód ukazuje, jak nastavit přihlašovací údaje a vytvořit klienta při použití sady SDK pro nasazení MLflow.
# Set up credentials
export DATABRICKS_HOST=...
export DATABRICKS_TOKEN=...
# Set up the client
import mlflow.deployments
client = mlflow.deployments.get_deploy_client("databricks")
Poznámka:
Osvědčeným postupem při ověřování pomocí automatizovaných nástrojů, systémů, skriptů a aplikací doporučuje Databricks místo uživatelů pracovního prostoru používat tokeny patního přístupu, které patří instančním objektům . Pokud chcete vytvořit tokeny pro instanční objekty, přečtěte si téma Správa tokenů instančního objektu.
Dotazování koncového bodu pomocí rozhraní API
Tato část obsahuje příklady dotazování koncového bodu pomocí rozhraní REST API nebo sady SDK pro nasazení MLflow.
REST API
curl -X POST -u token:$DATABRICKS_API_TOKEN $ENDPOINT_INVOCATION_URL \
-H 'Content-Type: application/json' \
-d '{"dataframe_records": [
{"user_id": 1, "ytd_spend": 598},
{"user_id": 2, "ytd_spend": 280}
]}'
Sada SDK pro nasazení MLflow
Důležité
Následující příklad používá predict() rozhraní API ze sady SDK pro nasazení MLflow. Toto rozhraní API je experimentální a definice rozhraní API se může změnit.
import mlflow.deployments
client = mlflow.deployments.get_deploy_client("databricks")
response = client.predict(
endpoint="test-feature-endpoint",
inputs={
"dataframe_records": [
{"user_id": 1, "ytd_spend": 598},
{"user_id": 2, "ytd_spend": 280},
]
},
)
Dotazování koncového bodu pomocí uživatelského rozhraní
Koncový bod obsluhy můžete dotazovat přímo z uživatelského rozhraní obsluhy. Uživatelské rozhraní obsahuje vygenerované příklady kódu, které můžete použít k dotazování koncového bodu.
Na levém bočním panelu pracovního prostoru Azure Databricks klikněte na Obsluha.
Klikněte na koncový bod, který chcete dotazovat.
V pravém horním rohu obrazovky klikněte na koncový bod dotazu.
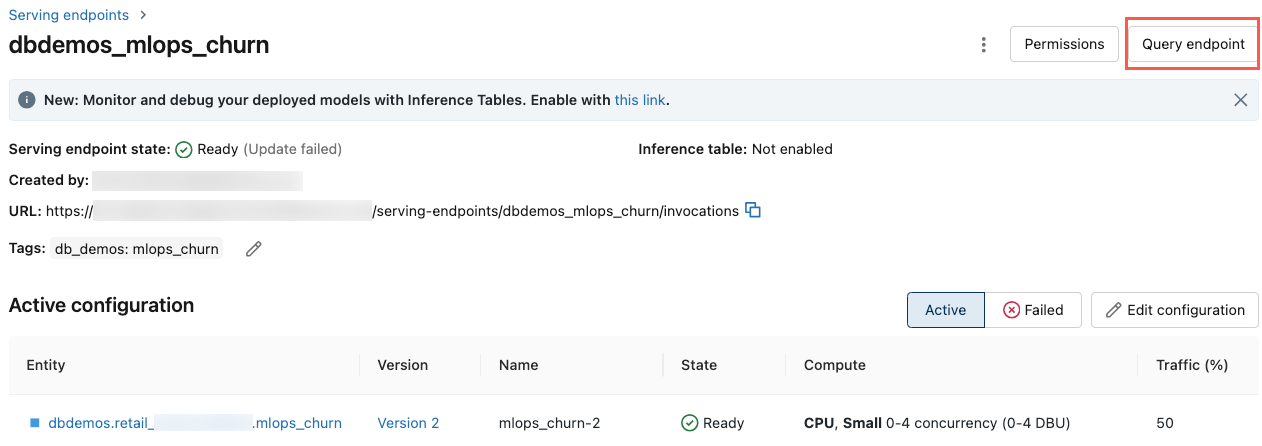
Do pole Požadavek zadejte text požadavku ve formátu JSON.
Klikněte na Odeslat požadavek.
// Example of a request body.
{
"dataframe_records": [
{"user_id": 1, "ytd_spend": 598},
{"user_id": 2, "ytd_spend": 280}
]
}
Dialogové okno koncového bodu dotazu obsahuje vygenerovaný ukázkový kód v curl, Pythonu a SQL. Kliknutím na karty zobrazíte a zkopírujete ukázkový kód.
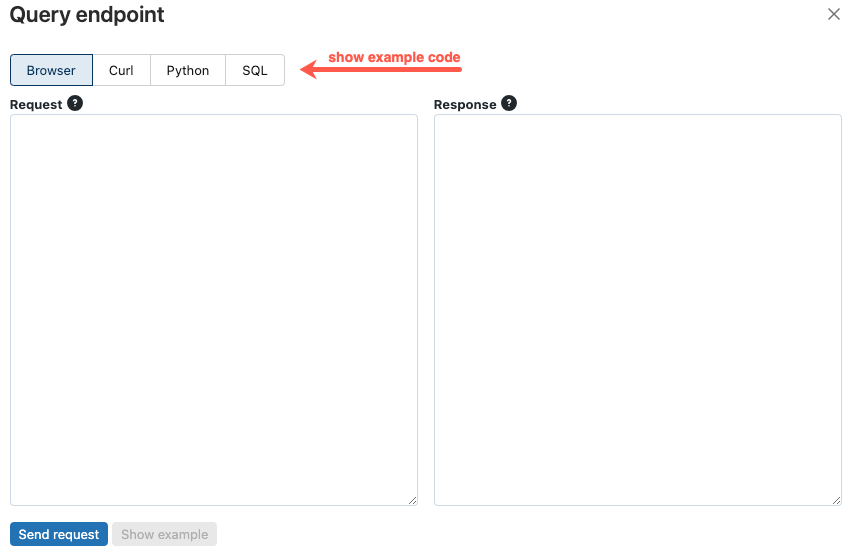
Pokud chcete kód zkopírovat, klikněte v pravém horním rohu textového pole na ikonu kopírování.
Aktualizace koncového bodu
Koncový bod můžete aktualizovat pomocí rozhraní REST API, sady Databricks SDK nebo uživatelského rozhraní obsluhy.
Aktualizace koncového bodu pomocí rozhraní API
REST API
curl -X PUT -u token:$DATABRICKS_API_TOKEN ${WORKSPACE_URL}/api/2.0/serving-endpoints/<endpoint_name>/config \
-H 'Content-Type: application/json' \
-d '"served_entities": [
{
"name": "customer-features",
"entity_name": "main.default.customer_features_new",
"workload_size": "Small",
"scale_to_zero_enabled": True
}
]'
Databricks SDK – Python
workspace.serving_endpoints.update_config(
name="my-serving-endpoint",
served_entities=[
ServedEntityInput(
entity_name="main.default.customer_features",
scale_to_zero_enabled=True,
workload_size="Small"
)
]
)
Aktualizace koncového bodu pomocí uživatelského rozhraní
Při používání uživatelského rozhraní obsluhy postupujte takto:
- Na levém bočním panelu pracovního prostoru Azure Databricks klikněte na Obsluha.
- V tabulce klikněte na název koncového bodu, který chcete aktualizovat. Zobrazí se obrazovka koncového bodu.
- V pravém horním rohu obrazovky klikněte na Upravit koncový bod.
- V dialogovém okně Upravit obsluhu koncového bodu upravte nastavení koncového bodu podle potřeby.
- Uložte změny kliknutím na Aktualizovat.
 koncový bod
koncový bod
Odstranění koncového bodu
Upozorňující
Tato akce je nevratná.
Koncový bod můžete odstranit pomocí rozhraní REST API, sady Databricks SDK, rozhraní Python API nebo uživatelského rozhraní pro obsluhu.
Odstranění koncového bodu pomocí rozhraní API
REST API
curl -X DELETE -u token:$DATABRICKS_API_TOKEN ${WORKSPACE_URL}/api/2.0/serving-endpoints/<endpoint_name>
Databricks SDK – Python
workspace.serving_endpoints.delete(name="customer-features")
Rozhraní API pro Python
fe.delete_feature_serving_endpoint(name="customer-features")
Odstranění koncového bodu pomocí uživatelského rozhraní
Pomocí uživatelského rozhraní obsluhy odstraňte koncový bod takto:
- Na levém bočním panelu pracovního prostoru Azure Databricks klikněte na Obsluha.
- V tabulce klikněte na název koncového bodu, který chcete odstranit. Zobrazí se obrazovka koncového bodu.
- V pravém horním rohu obrazovky klikněte na nabídku kebab
 a vyberte Odstranit.
a vyberte Odstranit.

Monitorování stavu koncového bodu
Řízení přístupu
Informace o oprávněních ke koncovým bodům obsluhy funkcí najdete v tématu Správa oprávnění pro koncový bod obsluhující model.
Příklad poznámkového bloku
Tento poznámkový blok ukazuje, jak pomocí sady Databricks SDK vytvořit koncový bod obsluhy funkcí pomocí tabulek Databricks Online.
Ukázkový poznámkový blok s ukázkami funkcí s online tabulkami
Získejte poznámkový blok