Vytvořte vlastní koncové body pro obsluhu modelů
Tento článek popisuje, jak vytvořit model obsluhující koncové body, které obsluhují vlastní modely pomocí služby Databricks Model Serving.
Obsluha modelu poskytuje následující možnosti pro obsluhu vytváření koncových bodů:
- Uživatelské rozhraní obsluhy
- REST API
- Sada SDK pro nasazení MLflow
Informace o vytváření koncových bodů, které obsluhují modely generující AI, najdete v tématu Vytvoření základního modelu obsluhujícího koncové body.
Požadavky
- Váš pracovní prostor musí být v podporované oblasti.
- Pokud ve svém modelu používáte vlastní knihovny nebo knihovny ze serveru privátního mirroru, přečtěte si téma Použití vlastních knihoven Pythonu s nasazením modelů před vytvořením koncového bodu modelu.
- Pokud chcete vytvářet koncové body pomocí sady SDK pro nasazení MLflow, musíte nainstalovat klienta nasazení MLflow. Pokud ho chcete nainstalovat, spusťte:
import mlflow.deployments
client = mlflow.deployments.get_deploy_client("databricks")
Řízení přístupu
Pro pochopení možností řízení přístupu ke koncovým bodům pro poskytování modelu při správě koncových bodů si přečtěte Správa oprávnění pro koncový bod poskytování modelu.
Můžete také přidat proměnné prostředí pro uložení přihlašovacích údajů pro obsluhu modelu. Viz Konfigurace přístupu k prostředkům z koncových bodů obsluhujících model
Vytvoření koncového bodu
Obsluha uživatelského rozhraní
Můžete vytvořit koncový bod pro servírování modelů pomocí uživatelského rozhraní Serving.
Klikněte na Serving na bočním panelu pro zobrazení uživatelského rozhraní.
Klikněte na Vytvořit koncový bod obsluhy.
Pro modely zaregistrované v registru modelů pracovního prostoru nebo modely v katalogu Unity:
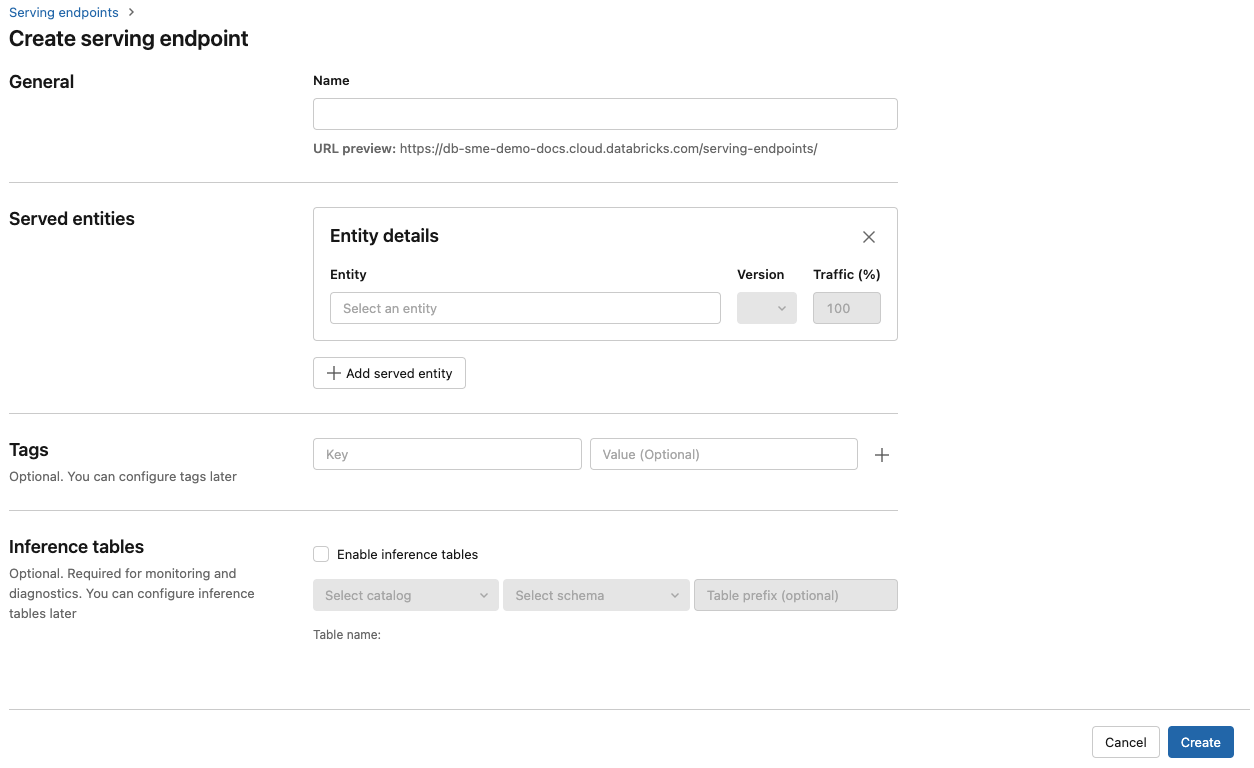
Do pole Název zadejte název vašeho koncového bodu.
V části Obsluhované entity
- Kliknutím do pole Entita otevřete formulář Výběr obsluhované entity.
- Vyberte typ modelu, který chcete poskytovat. Formulář se dynamicky aktualizuje na základě vašeho výběru.
- Vyberte, který model a verzi modelu chcete použít.
- Vyberte procento provozu, které chcete směrovat do vašeho obsluhovaného modelu.
- Vyberte, jakou velikost výpočetních prostředků chcete použít. Pro své úlohy můžete použít výpočetní výkon procesoru nebo GPU. Další informace o dostupných výpočetních prostředcích GPU najdete v typech úloh GPU.
- Vyberte, jakou velikost výpočetních prostředků chcete použít. Pro své úlohy můžete použít výpočetní výkon procesoru nebo GPU. Další informace o dostupných výpočetních prostředcích GPU najdete v typech úloh GPU.
- V části Horizontální navýšení kapacity výpočetních prostředkůvyberte velikost horizontálního navýšení kapacity výpočetních prostředků odpovídající počtu požadavků, které tento obsluhovaný model může zpracovat současně. Toto číslo by se mělo přibližně rovnat době běhu modelu QPS x.
- Dostupné velikosti jsou malé pro 0 až 4 požadavky, středně velké 8 až 16 požadavků a velké pro požadavky 16 až 64.
- Určete, jestli se má koncový bod při nepoužívání škálovat na nulu.
- V části Rozšířenékonfigurace můžete přidat proměnné prostředí, které se budou připojovat k prostředkům z koncového bodu nebo protokolovat vyhledávací datový rámec funkce do tabulky odvozování koncového bodu. Protokolování datového rámce pro vyhledávání funkcí vyžaduje MLflow 2.14.0 nebo vyšší.
Klikněte na Vytvořit. Stránka Obslužné koncové body se zobrazí se stavem Obsluhy koncového bodu, který je zobrazený jako Není připravený.
REST API
Koncové body můžete vytvářet pomocí rozhraní REST API. Parametry konfigurace koncového bodu najdete v POST /api/2.0/serving-endpoints.
Následující příklad vytvoří koncový bod, který slouží první verzi modelu ads1, který je zaregistrovaný v registru modelu Katalogu Unity. Pokud chcete zadat model z katalogu Unity, zadejte úplný název modelu včetně nadřazeného katalogu a schématu, například catalog.schema.example-model.
POST /api/2.0/serving-endpoints
{
"name": "uc-model-endpoint",
"config":
{
"served_entities": [
{
"name": "ads-entity"
"entity_name": "catalog.schema.my-ads-model",
"entity_version": "3",
"workload_size": "Small",
"scale_to_zero_enabled": true
},
{
"entity_name": "catalog.schema.my-ads-model",
"entity_version": "4",
"workload_size": "Small",
"scale_to_zero_enabled": true
}
],
"traffic_config":
{
"routes": [
{
"served_model_name": "my-ads-model-3",
"traffic_percentage": 100
},
{
"served_model_name": "my-ads-model-4",
"traffic_percentage": 20
}
]
}
},
"tags": [
{
"key": "team",
"value": "data science"
}
]
}
Následuje příklad odpovědi. Stav koncového bodu config_update je NOT_UPDATING a stav modelu, který je poskytován, je READY.
{
"name": "uc-model-endpoint",
"creator": "user@email.com",
"creation_timestamp": 1700089637000,
"last_updated_timestamp": 1700089760000,
"state": {
"ready": "READY",
"config_update": "NOT_UPDATING"
},
"config": {
"served_entities": [
{
"name": "ads-entity",
"entity_name": "catalog.schema.my-ads-model-3",
"entity_version": "3",
"workload_size": "Small",
"scale_to_zero_enabled": true,
"workload_type": "CPU",
"state": {
"deployment": "DEPLOYMENT_READY",
"deployment_state_message": ""
},
"creator": "user@email.com",
"creation_timestamp": 1700089760000
}
],
"traffic_config": {
"routes": [
{
"served_model_name": "catalog.schema.my-ads-model-3",
"traffic_percentage": 100
}
]
},
"config_version": 1
},
"tags": [
{
"key": "team",
"value": "data science"
}
],
"id": "e3bd3e471d6045d6b75f384279e4b6ab",
"permission_level": "CAN_MANAGE",
"route_optimized": false
}
Sada SDK pro nasazení MLflow
Nasazení MLflow poskytuje rozhraní API pro úkoly vytváření, aktualizace a odstraňování. Rozhraní API pro tyto úlohy přijímají stejné parametry jako rozhraní REST API pro obsluhu koncových bodů. Parametry konfigurace koncového bodu najdete v POST /api/2.0/serving-endpoints.
Následující příklad vytvoří koncový bod, který slouží třetí verzi modelu my-ads-model, který je zaregistrovaný v registru modelu Katalogu Unity. Je nutné zadat úplný název modelu včetně nadřazeného katalogu a schématu, například catalog.schema.example-model.
from mlflow.deployments import get_deploy_client
client = get_deploy_client("databricks")
endpoint = client.create_endpoint(
name="unity-catalog-model-endpoint",
config={
"served_entities": [
{
"name": "ads-entity"
"entity_name": "catalog.schema.my-ads-model",
"entity_version": "3",
"workload_size": "Small",
"scale_to_zero_enabled": true
}
],
"traffic_config": {
"routes": [
{
"served_model_name": "my-ads-model-3",
"traffic_percentage": 100
}
]
}
}
)
Můžete také:
- Nakonfigurujte koncový bod tak, aby sloužil více modelům.
- Nakonfigurujte koncový bod pro optimalizaci tras.
- Povolit odvozovací tabulky pro automatické zachytávání příchozích požadavků a odchozích odpovědí na koncových bodech obsluhy modelu.
- Pokud máte na koncovém bodu povolené tabulky odvozování, můžete protokolovat datový rámec vyhledávání vlastností do tabulky odvozování.
Typy úloh GPU
Nasazení GPU je kompatibilní s následujícími verzemi balíčků:
- Pytorch 1.13.0 - 2.0.1
- TensorFlow 2.5.0 – 2.13.0
- MLflow 2.4.0 a vyšší
Pokud chcete nasadit modely pomocí grafických procesorů, zahrňte pole workload_type do konfigurace koncového bodu během vytváření koncového bodu nebo jako aktualizaci konfigurace koncového bodu pomocí rozhraní API. Pokud chcete nakonfigurovat koncový bod pro úlohy GPU pomocí uživatelského rozhraní Obsluha, vyberte požadovaný typ GPU v rozevíracím seznamu Typ výpočetních prostředků.
{
"served_entities": [{
"entity_name": "catalog.schema.ads1",
"entity_version": "2",
"workload_type": "GPU_LARGE",
"workload_size": "Small",
"scale_to_zero_enabled": false,
}]
}
Následující tabulka shrnuje podporované typy úloh GPU.
| Typ úlohy GPU | GPU instance | Paměť GPU |
|---|---|---|
GPU_SMALL |
1xT4 | 16 GB |
GPU_LARGE |
1xA100 | 80 GB |
GPU_LARGE_2 |
2xA100 | 160 GB |
Úprava vlastního koncového bodu modelu
Po povolení vlastního koncového bodu modelu můžete podle potřeby aktualizovat konfiguraci výpočetních prostředků. Tato konfigurace je užitečná zejména v případě, že potřebujete další prostředky pro váš model. Velikost úloh a konfigurace výpočetních prostředků hrají klíčovou roli v tom, jaké prostředky se přidělují pro poskytování modelu.
Dokud nebude nová konfigurace připravená, stará konfigurace bude dál obsluhovat predikční provoz. Zatímco probíhá aktualizace, nelze provést jinou aktualizaci. Probíhající aktualizaci ale můžete zrušit z uživatelského rozhraní obsluhy.
Obsluha uživatelského rozhraní
Po povolení koncového bodu modelu vyberte Upravit koncový bod, abyste mohli upravit jeho výpočetní konfiguraci.
Můžete udělat toto:
- Vyberte si z několika velikostí úloh a automatické škálování se automaticky nakonfiguruje v rámci velikosti úlohy.
- Určete, jestli se má koncový bod při nepoužívání škálovat dolů na nulu.
- Upravte procento provozu tak, aby se směroval do vašeho obsluhovaného modelu.
Probíhající aktualizaci konfigurace můžete zrušit tak, že vyberete Zrušit aktualizaci v pravém horním rohu stránky podrobností koncového bodu. Tato funkce je k dispozici pouze v uživatelském rozhraní obsluhy.
REST API
Následuje příklad aktualizace konfigurace koncového bodu pomocí rozhraní REST API. Viz PUT /api/2.0/serving-endpoints/{name}/config.
PUT /api/2.0/serving-endpoints/{name}/config
{
"name": "unity-catalog-model-endpoint",
"config":
{
"served_entities": [
{
"entity_name": "catalog.schema.my-ads-model",
"entity_version": "5",
"workload_size": "Small",
"scale_to_zero_enabled": true
}
],
"traffic_config":
{
"routes": [
{
"served_model_name": "my-ads-model-5",
"traffic_percentage": 100
}
]
}
}
}
Sada SDK pro nasazení MLflow
Sada SDK pro nasazení MLflow používá stejné parametry jako rozhraní REST API, viz PUT /api/2.0/serving-endpoints/{name}/config podrobnosti schématu požadavků a odpovědí.
Následující ukázka kódu používá model z registru modelů katalogu Unity:
import mlflow
from mlflow.deployments import get_deploy_client
mlflow.set_registry_uri("databricks-uc")
client = get_deploy_client("databricks")
endpoint = client.create_endpoint(
name=f"{endpointname}",
config={
"served_entities": [
{
"entity_name": f"{catalog}.{schema}.{model_name}",
"entity_version": "1",
"workload_size": "Small",
"scale_to_zero_enabled": True
}
],
"traffic_config": {
"routes": [
{
"served_model_name": f"{model_name}-1",
"traffic_percentage": 100
}
]
}
}
)
Vyhodnocení koncového bodu modelu
Pokud chcete model vyhodnotit, odešlete požadavky do koncového bodu obsluhy modelu.
- Podívejte se na Obslužné koncové body pro dotazy na vlastní modely.
- Viz základní modely dotazů.
Další materiály
- Správa koncových bodů pro obsluhu modelů
- Externí modely ve službě Mosaic AI Model Serving.
- Pokud dáváte přednost použití Pythonu, můžete použít Python SDK Databricks pro obsluhu v reálném čase.
Příklady poznámkových bloků
Následující poznámkové bloky zahrnují různé registrované modely Databricks, které můžete použít k rychlému spuštění s rozhraními pro obsluhu modelů. Další příklady najdete v tématu Kurz: Nasazení a dotazování vlastního modelu.
Příkladové modely je možné importovat do pracovního prostoru podle pokynů v Importujte poznámkový blok. Jakmile vyberete a vytvoříte model z některého z příkladů, ho zaregistrujte vUnity katalogu a pak postupujte podle pracovního postupu uživatelského rozhraní pro nasazení modelu.
Trénování a registrace modelu scikit-learn pro model obsluhující poznámkový blok
Pořiďte si poznámkový blok
Trénování a registrace modelu HuggingFace pro model obsluhující poznámkový blok
Vezměte poznámkový blok