Krok 1. Klonování úložiště kódu a vytvoření výpočetních prostředků
Podívejte se na úložiště GitHub pro vzorový kód v této části. Kód úložiště můžete použít také jako šablonu, pomocí které můžete vytvářet vlastní aplikace AI.
Tímto postupem načtete ukázkový kód do pracovního prostoru Databricks a nakonfigurujete globální nastavení pro aplikaci.
Požadavky
- Pracovní prostor Azure Databricks s povolenými bezserverovými výpočetními a Catalog Unity.
- Existující koncový bod Nebo oprávnění k vytvoření nového koncového bodu vektorového vyhledávání v prostředí Mosaic AI (v tomto případě pro vás vytvoří poznámkový blok nastavení).
- Přístup pro zápis k existující jednotce Unity Catalogschemawhere, kam se ukládá výstup rozdílové Delta tables, který obsahuje analyzované a blokované dokumenty a indexy vektorového vyhledávání, nebo oprávnění k vytvoření nové catalog a schema (v tomto případě pro vás nastavovací poznámkový blok vytvoří jedno).
- Jeden uživatelský cluster se spuštěným DBR 14.3 nebo novějším, který má přístup k internetu. Ke stažení potřebných balíčků Pythonu a systémových balíčků se vyžaduje přístup k internetu. Nepoužívejte cluster se spuštěným modulem Databricks Runtime pro Machine Learning, protože tyto kurzy mají konflikty s balíčkem Python s modulem Databricks Runtime ML.
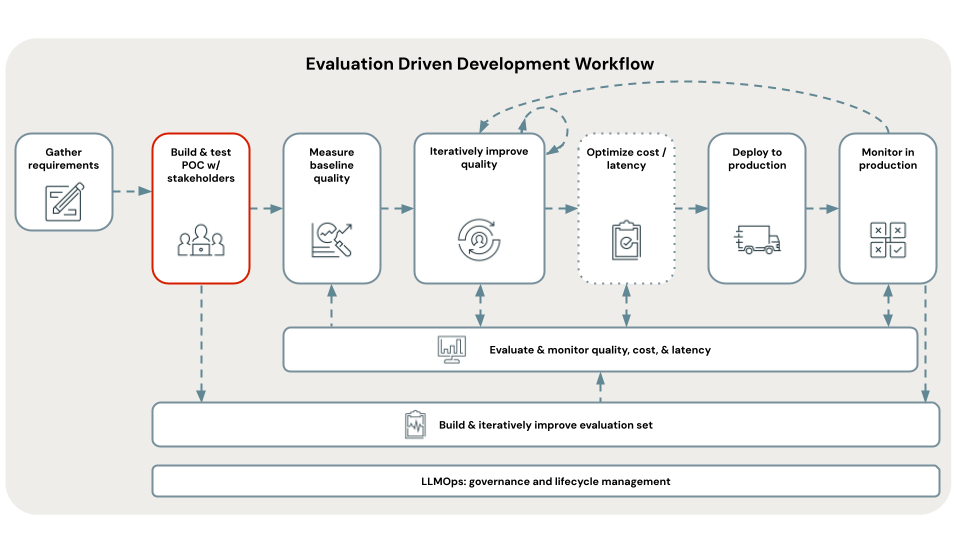
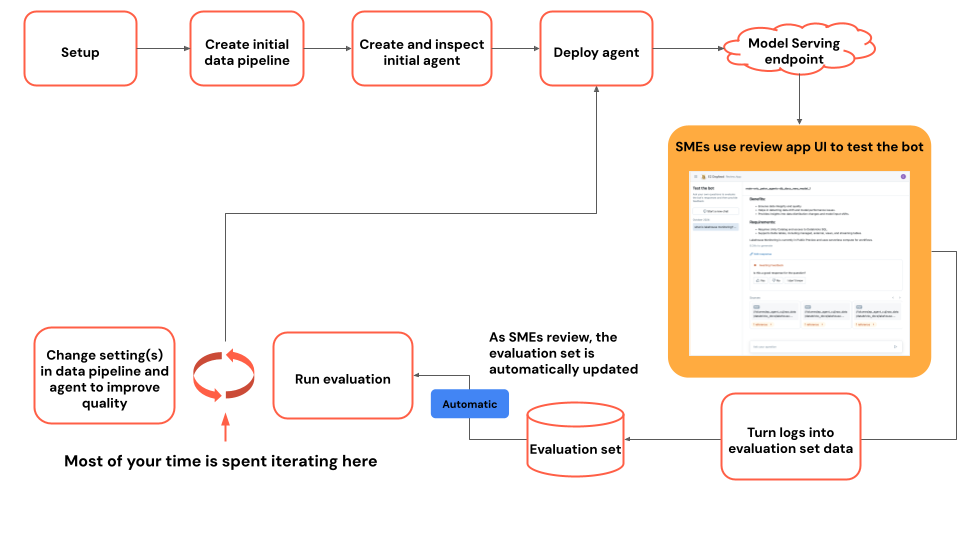
Diagram toku kurzu
Diagram znázorňuje tok kroků použitých v tomto kurzu.
Pokyny
Naklonujte toto úložiště do svého pracovního prostoru pomocí složek Gitu.
Otevřete poznámkový blok rag_app_sample_code/00_global_config a upravte nastavení.
# The name of the RAG application. This is used to name the chain's model in Unity Catalog and prepended to the output Delta tables and vector indexes RAG_APP_NAME = 'my_agent_app' # Unity Catalog catalog and schema where outputs tables and indexes are saved # If this catalog/schema does not exist, you need create catalog/schema permissions. UC_CATALOG = f'{user_name}_catalog' UC_SCHEMA = f'rag_{user_name}' ## Name of model in Unity Catalog where the POC chain is logged UC_MODEL_NAME = f"{UC_CATALOG}.{UC_SCHEMA}.{RAG_APP_NAME}" # Vector Search endpoint where index is loaded # If this does not exist, it will be created VECTOR_SEARCH_ENDPOINT = f'{user_name}_vector_search' # Source location for documents # You need to create this location and add files SOURCE_PATH = f"/Volumes/{UC_CATALOG}/{UC_SCHEMA}/source_docs"Otevřete a spusťte poznámkový blok 01_validate_config_and_create_resources.
Další krok
Pokračujte v nasazení POC.