Mosaic AI Vector Search
Tento článek poskytuje přehled řešení vektorové databáze Databricks, hledání vektorů AI v systému Mosaic, včetně toho, co je a jak funguje.
Co je Hledání vektorů AI v systému Mosaic?
Mosaic AI Vector Search je vektorová databáze integrovaná do platformy Databricks Data Intelligence Platform a integrovaná se svými nástroji pro zásady správného řízení a produktivitu. Vektorová databáze je databáze optimalizovaná pro ukládání a načítání vložených objektů. Vkládání jsou matematické znázornění sémantického obsahu dat, obvykle textových nebo obrázkových dat. Vkládání je generováno velkým jazykovým modelem a jsou klíčovou součástí mnoha aplikací GenAI, které závisí na hledání dokumentů nebo obrázků, které se vzájemně podobají. Příkladem jsou systémy RAG, doporučené systémy a rozpoznávání obrázků a videa.
Pomocí funkce Mosaic AI Vector Search vytvoříte z tabulky Delta index vektorového vyhledávání. Index obsahuje vložená data s metadaty. Pak můžete index dotazovat pomocí rozhraní REST API, abyste identifikovali nejvíce podobné vektory a vrátili přidružené dokumenty. Index můžete strukturovat tak, aby se automaticky synchronizoval při aktualizaci podkladové tabulky Delta.
Rozhraní AI Vector Search v systému Mosaic podporuje následující:
- Hledání podobnosti hybridních klíčových slov
- Filtrování.
- Seznamy řízení přístupu (ACL) pro správu koncových bodů vektorového vyhledávání
- Synchronizovat pouze vybrané sloupce.
- Ukládat a synchronizovat vygenerované vnořené vektory.
Jak funguje hledání vektorů AI v systému Mosaic?
Rozhraní AI Vector Search používá algoritmus Hierarchical Navigable Small World (HNSW) pro přibližné hledání nejbližších sousedů a metriku vzdálenosti L2 k měření podobnosti vektorů vkládání. Pokud chcete použít kosinusovou podobnost, musíte před jejich podáváním do vektorového vyhledávání normalizovat vkládání datových bodů. Když jsou datové body normalizovány, pořadí vytvořené vzdáleností L2 je stejné jako pořadí produkuje kosinus podobnost.
Rozhraní AI Vector Search podporuje také hybridní vyhledávání podobnosti klíčových slov, které kombinuje vektorové vkládání hledání s tradičními technikami hledání založenými na klíčových slovech. Tento přístup odpovídá přesným slovům v dotazu a zároveň používá vyhledávání podobnosti založené na vektorech k zachycení sémantických relací a kontextu dotazu.
Díky integraci těchto dvou technik vyhledávání hybridních klíčových slov načítá dokumenty, které obsahují nejen přesná klíčová slova, ale také ty, které jsou koncepčně podobné a poskytují komplexnější a relevantnější výsledky hledání. Tato metoda je zvláště užitečná v aplikacích RAG, kde zdrojová data mají jedinečná klíčová slova, jako jsou skladové položky nebo identifikátory, které nejsou vhodné pro čistě podobné vyhledávání.
Podrobnosti o rozhraní API najdete v referenčních informacích k sadě Python SDK a dotazování koncového bodu vektorového vyhledávání.
Výpočet vyhledávání podobnosti
Výpočet vyhledávání podobnosti používá následující vzorec:
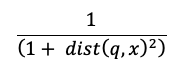
kde dist je euklidská vzdálenost mezi q dotazu a položkou indexu x:
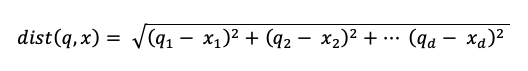
Algoritmus vyhledávání klíčových slov
Skóre relevance se počítají pomocí okapi BM25. Prohledávají se všechny sloupce textu nebo řetězce, včetně sloupců vkládání zdrojového textu a metadat ve formátu textu nebo řetězce. Funkce tokenizace rozdělí hranice slova, odebere interpunkci a převede veškerý text na malá písmena.
Jak se vyhledávání podobností a hledání klíčových slov kombinuje
Hledání podobnosti a výsledky hledání klíčových slov se kombinují pomocí funkce Reciproční Rank Fusion (RRF).
RRF znovu ohodnotí každý dokument z každé metody pomocí skóre:
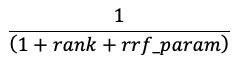
Ve výše uvedené rovnici pořadí začíná na 0, sečte skóre pro každý dokument a vrátí nejvyšší bodovací dokumenty.
rrf_param určuje relativní důležitost dokumentů s vyšším pořadím a s nižším pořadím. Na základě literatury je rrf_param nastaveno na 60.
Skóre jsou normalizována tak, aby nejvyšší skóre bylo 1 a nejnižší skóre je 0 pomocí následující rovnice:
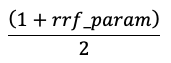
Možnosti pro poskytování vložených vektorů
Pokud chcete vytvořit vektorovou databázi v Databricks, musíte se nejprve rozhodnout, jak poskytovat vkládání vektorů. Databricks podporuje tři možnosti:
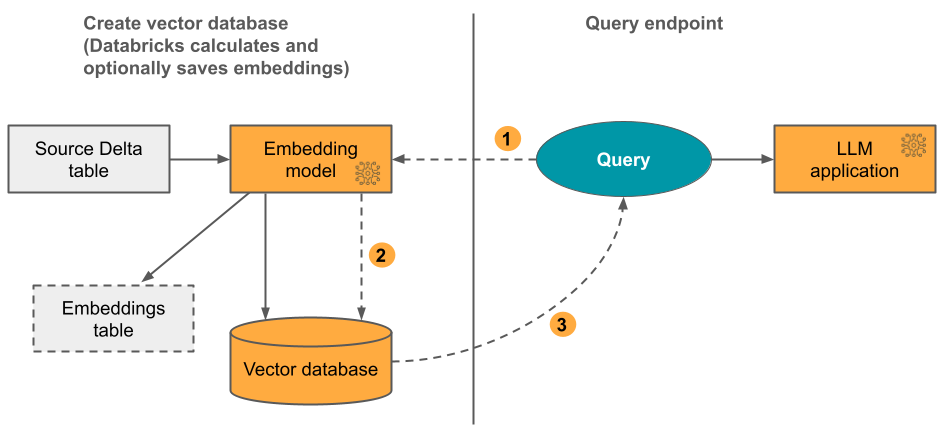
možnost 1: Rozdílový synchronizační index s vloženými daty vypočítanými službou Databricks Poskytnete zdrojovou tabulku Delta, která obsahuje data v textovém formátu. Databricks vypočítá vkládání pomocí zadaného modelu a volitelně uloží vložení do tabulky v katalogu Unity. Při aktualizaci tabulky Delta zůstane index synchronizovaný s tabulkou Delta.
Tento proces znázorňuje následující diagram:
- Výpočet vkládání dotazů Dotaz může obsahovat filtry metadat.
- Vyhledávání podobností umožňuje identifikovat nejrelevavantnější dokumenty.
- Vraťte nejrelevavantnější dokumenty a připojte je k dotazu.
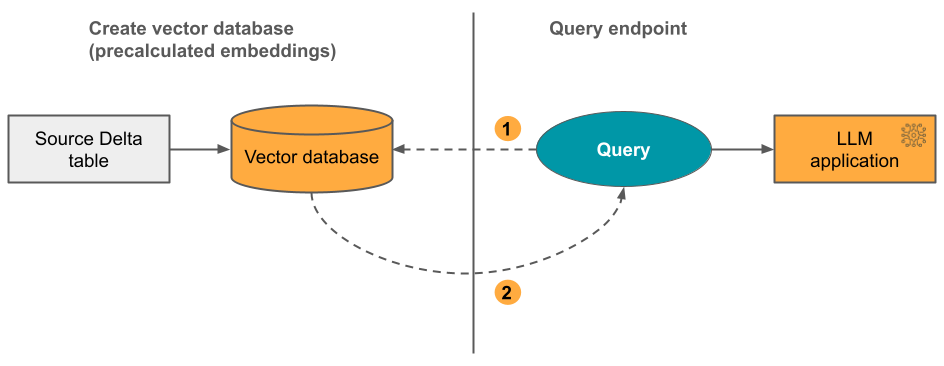
Možnost 2: Delta Sync Index s vlastně spravovanými embeddingy Poskytujete zdrojovou tabulku Delta, která obsahuje předem vypočítané embeddingy. Při aktualizaci tabulky Delta zůstane index synchronizovaný s tabulkou Delta.
Tento proces znázorňuje následující diagram:
- Dotaz se skládá z vkládání a může obsahovat filtry metadat.
- Vyhledávání podobností umožňuje identifikovat nejrelevavantnější dokumenty. Vraťte nejrelevavantnější dokumenty a připojte je k dotazu.
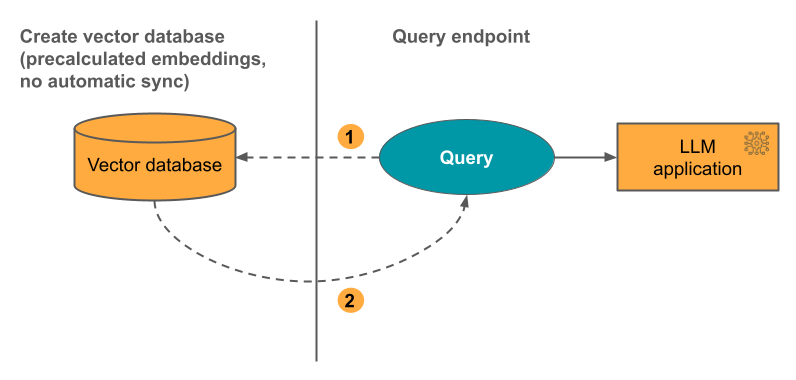
možnost 3: Index přímého přístupu vektoru Musíte ručně aktualizovat index pomocí rozhraní REST API při změně tabulky vektorů.
Tento proces znázorňuje následující diagram:
Jak nastavit vektorové vyhledávání v systému Mosaic AI
Chcete-li použít vectorové vyhledávání v systému Mosaic AI, je nutné vytvořit následující:
Koncový bod vektorového vyhledávání. Tento koncový bod slouží indexu vektorového vyhledávání. Koncový bod můžete dotazovat a aktualizovat pomocí rozhraní REST API nebo sady SDK. Pokyny najdete v tématu Vytvoření koncového bodu vektorového vyhledávání.
Koncové body se automaticky škálují tak, aby podporovaly velikost indexu nebo počet souběžných požadavků. Koncové body se automaticky neškálují dolů.
Index vektorového vyhledávání. Index vektorového vyhledávání se vytvoří z tabulky Delta a je optimalizovaný tak, aby poskytoval přibližné hledání nejbližších sousedů v reálném čase. Cílem hledání je identifikovat dokumenty, které jsou podobné dotazu. Indexy pro vektorové vyhledávání se zobrazují v katalogu Unity a jsou jím řízeny. Pokyny najdete v tématu Vytvoření indexu vektorového vyhledávání.
Pokud se navíc rozhodnete databricks vypočítat vkládání, můžete použít předem nakonfigurovaný koncový bod rozhraní API základního modelu nebo vytvořit koncový bod obsluhující model, který bude sloužit modelu vkládání podle vašeho výběru. Pokyny najdete v tématu rozhraní API základního modelu pro platby za token nebo Vytvoření základního modelu obsluhujícího koncové body.
K dotazování koncového bodu obsluhy modelu použijete buď rozhraní REST API, nebo sadu Python SDK. Dotaz může definovat filtry na základě libovolného sloupce v tabulce Delta. Podrobnosti najdete v tématu Použití filtrů pro dotazy, reference k rozhraní API nebo referenční informace k sadě Python SDK.
Požadavky
- Pracovní prostor s aktivovaným katalogem Unity
- Bezserverové výpočetní prostředky jsou povolené. Pokyny najdete v tématu Připojení k výpočetním prostředkům bez serveru.
- Zdrojová tabulka musí mít povolený kanál pro změny dat. Pokyny najdete v tématu Použití kanálu změn Delta Lake v Azure Databricks.
- Pokud chcete vytvořit index vektorového vyhledávání, musíte mít oprávnění CREATE TABLE ve schématu katalogu, kde bude index vytvořen.
Oprávnění k vytváření a správě koncových bodů vektorového vyhledávání se konfiguruje pomocí seznamů řízení přístupu. Viz seznamy ACL koncového bodu vektoru vyhledávání.
ochrana a ověřování dat
Databricks implementuje následující bezpečnostní prvky, které chrání vaše data:
- Každá žádost zákazníka o hledání vektorů AI v systému Mosaic je logicky izolovaná, ověřená a autorizovaná.
- Rozhraní AI Vector Search šifruje všechna neaktivní uložená data (AES-256) a přenášená data (TLS 1.2+).
Rozhraní AI Vector Search podporuje dva způsoby ověřování:
Token hlavního oprávnění služby. Správce může vygenerovat token objektu služby a předat ho sadě SDK nebo rozhraní API. Viz použití instančních objektů. Pro případy použití v produkčním prostředí doporučuje Databricks použít token instančního objektu.
# Pass in a service principal vsc = VectorSearchClient(workspace_url="...", service_principal_client_id="...", service_principal_client_secret="..." )Osobní přístupový token. Osobní přístupový token můžete použít k ověření s využitím Funkce vektorového vyhledávání v systému Mosaic AI. Viz token patového ověřování. Pokud používáte sadu SDK v prostředí poznámkového bloku, sada SDK automaticky vygeneruje token PAT pro ověřování.
# Pass in the PAT token client = VectorSearchClient(workspace_url="...", personal_access_token="...")
Klíče spravované zákazníkem (CMK) se podporují na koncových bodech vytvořených 8. května 2024 nebo po 8. květnu 2024.
Sledování využití a nákladů
Tabulka fakturovatelného systému využití umožňuje monitorovat využití a náklady spojené s indexy a koncovými body vektorového vyhledávání. Zde je příklad dotazu:
WITH all_vector_search_usage (
SELECT *,
CASE WHEN usage_metadata.endpoint_name IS NULL THEN 'ingest'
WHEN usage_type = "STORAGE_SPACE" THEN 'storage'
ELSE 'serving'
END as workload_type
FROM system.billing.usage
WHERE billing_origin_product = 'VECTOR_SEARCH'
),
daily_dbus AS (
SELECT workspace_id,
cloud,
usage_date,
workload_type,
usage_metadata.endpoint_name as vector_search_endpoint,
CASE WHEN workload_type = 'serving' THEN SUM(usage_quantity)
WHEN workload_type = 'ingest' THEN SUM(usage_quantity)
ELSE null
END as dbus,
CASE WHEN workload_type = 'storage' THEN SUM(usage_quantity)
ELSE null
END as dsus
FROM all_vector_search_usage
GROUP BY all
ORDER BY 1,2,3,4,5 DESC
)
SELECT * FROM daily_dbus
Podrobnosti o obsahu tabulky fakturačního využití najdete v referenční informace k tabulce systému účtovatelného využití. Další dotazy jsou v následujícím ukázkovém poznámkovém bloku.
Dotazy na tabulky v systému vektorového vyhledávání v poznámkovém bloku
Získejte poznámkový blok
Omezení velikosti prostředků a dat
Následující tabulka shrnuje omezení velikosti prostředků a dat pro koncové body a indexy vektorového vyhledávání:
| Prostředek | Členitost | Limit |
|---|---|---|
| Koncové body vektorového vyhledávání | Na pracovní prostor | 100 |
| Vkládání | Na koncový bod | 320,000,000 |
| Dimenze vložení | Na index | 4096 |
| Indexy | Na koncový bod | 50 |
| Sloupce | Na index | 50 |
| Sloupce | Podporované typy: Bajty, krátké, celé číslo, long, float, double, boolean, string, timestamp, date | |
| Pole metadat | Na index | 50 |
| Název indexu | Na index | 128 znaků |
Následující omezení platí pro vytváření a aktualizaci indexů vektorového vyhledávání:
| Prostředek | Členitost | Limit |
|---|---|---|
| Velikost řádku pro Delta synchronizační index | Na index | 100 kB |
| Vložení velikosti zdrojového sloupce pro index Delta Sync | Na index | 32764 bajtů |
| Limit hromadné velikosti požadavku na upsert pro index Direct Vector | Na index | 10 MB |
| Hromadný limit velikosti žádosti o odstranění indexu Direct Vector | Na index | 10 MB |
Následující omezení platí pro rozhraní API pro dotazy.
| Prostředek | Členitost | Omezení |
|---|---|---|
| Délka textu dotazu | Na dotaz | 32764 bajtů |
| Maximální počet vrácených výsledků | Na dotaz | 10,000 |
Omezení
- Oprávnění na úrovni řádků a sloupců nejsou podporována. Můžete ale implementovat vlastní seznamy ACL na úrovni aplikace pomocí rozhraní API filtru.