Předpoklad: Shromáždění požadavků
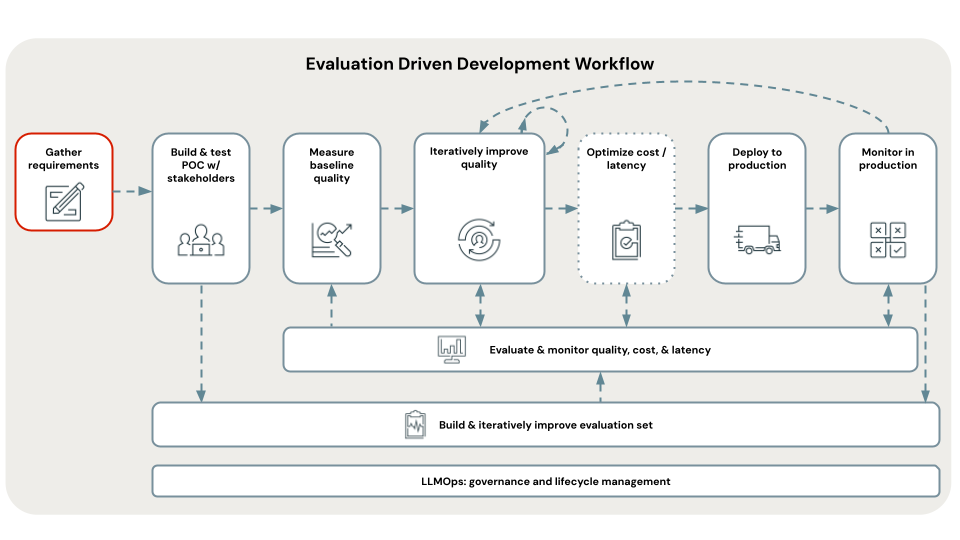
Definování jasných a ucelených požadavků na případ použití je kritickým prvním krokem při vývoji úspěšné aplikace generativní AI. Tyto požadavky slouží ke dvěma primárním účelům. Za prvé pomáhají určit, jestli je RAG nejvhodnějším přístupem pro daný případ použití. Pokud je RAG skutečně vhodný, tyto požadavky řídí návrh, implementaci a hodnocení řešení. Investice času na začátku projektu ke shromáždění podrobných požadavků může zabránit významným výzvám a překážkám později v procesu vývoje a zajistit, aby výsledné řešení splňovalo potřeby koncových uživatelů a zúčastněných stran. Dobře definované požadavky poskytují základ pro následné fáze životního cyklu vývoje, které si projdeme.
Podívejte se na úložiště GitHub pro vzorový kód v této části. Kód úložiště můžete použít také jako šablonu, pomocí které můžete vytvářet vlastní aplikace AI.
Je případ použití vhodný pro RAG?
První věc, kterou je třeba stanovit, je, zda je RAG dokonce správným přístupem pro váš případ použití. Vzhledem k hypu kolem RAG je lákavé ho vidět jako možné řešení jakéhokoli problému. Existují však drobné odlišnosti, pokud je RAG vhodný versus ne.
RAG je vhodný v případech, kdy:
- Odůvodnění načtených informací (nestrukturovaných i strukturovaných), které se zcela nevejdou do kontextového okna LLM
- Syntetizace informací z více zdrojů (například generování souhrnu klíčových bodů z různých článků v tématu)
- Dynamické načítání na základě uživatelského dotazu je nezbytné (například pro uživatelský dotaz určete, z jakého zdroje dat se má načíst).
- Případ použití vyžaduje generování nového obsahu na základě načtených informací (například odpovídání na otázky, poskytování vysvětlení, nabízení doporučení).
RAG nemusí být nejvhodnější, pokud:
- Úloha nevyžaduje načtení specifické pro dotazy. Například generování souhrnů přepisů hovorů; i v případě, že jsou ve výzvě LLM poskytnuty jednotlivé přepisy jako kontext, zůstávají získané informace pro každý souhrn stejné.
- Celá sada informací, které se mají načíst, se může vejít do kontextového okna LLM.
- Vyžadují se extrémně nízké latence odpovědi (například když se vyžadují odpovědi v milisekundách).
- Jednoduché odpovědi založené na pravidlech nebo šablony jsou dostatečné (například chatovací robot zákaznické podpory, který poskytuje předdefinované odpovědi na základě klíčových slov).
Požadavky na zjišťování
Jakmile si ověříte, že RAG je vhodný pro váš případ použití, zvažte následující otázky, abyste získali konkrétní požadavky. Požadavky jsou upřednostňovány následujícím způsobem:
🟢 P0: Před zahájením POC je nutné tento požadavek definovat.
🟡 P1: Musí být definován před přechodem do produkce, ale může být iterativně zpřesňován během POC.
⚪ P2: Požadavek, který je dobré mít.
Nejedná se o vyčerpávající seznam otázek. Měl by ale poskytnout pevný základ pro zachycení klíčových požadavků pro vaše řešení RAG.
Uživatelské prostředí
Definování způsobu interakce uživatelů se systémem RAG a očekávaného druhu odpovědí
🟢 [P0] Jak bude typický požadavek na řetězec RAG vypadat? Požádejte zúčastněné strany o příklady potenciálních uživatelských dotazů.
🟢 [P0] Jaký druh odpovědí budou uživatelé očekávat (krátké odpovědi, dlouhé vysvětlení, kombinace nebo něco jiného)?
🟡 [P1] Jak budou uživatelé pracovat se systémem? Prostřednictvím rozhraní chatu, vyhledávacího panelu nebo jiného způsobu?
🟡 [P1] Jaký tón nebo styl by měly mít generované odpovědi? (formální, konverzační, technický?)
🟡 [P1] Jak by aplikace měla zpracovávat nejednoznačné, neúplné nebo irelevantní dotazy? Měla by být v takových případech poskytována nějaká forma zpětné vazby nebo pokynů?
⚪ [P2] Existují specifické požadavky na formátování nebo prezentaci pro vygenerovaný výstup? Měl by výstup obsahovat kromě odpovědi řetězu nějaká metadata?
Data
Určete povahu, zdroje a kvalitu dat, která budou použita v řešení RAG.
🟢 [P0] Jaké jsou dostupné zdroje, které se mají použít?
Pro každý zdroj dat:
- 🟢 [P0] Jsou data strukturovaná nebo nestrukturovaná?
- 🟢 [P0] Jaký je zdrojový formát načítaných dat (např. PDF soubory, dokumentace s obrázky/tabulkami, strukturované odpovědi rozhraní API)?
- 🟢 [P0] Kde se tato data nacházejí?
- 🟢 [P0] Kolik dat je k dispozici?
- 🟡 [P1] Jak často se data aktualizují? Jak by se tyto aktualizace měly zpracovávat?
- 🟡 [P1] Existují nějaké známé problémy s kvalitou dat nebo nekonzistence pro každý zdroj dat?
Zvažte vytvoření tabulky inventáře pro konsolidaci těchto informací, například:
| Zdroj dat | Zdroj | Typy souborů | Velikost | Četnost aktualizací |
|---|---|---|---|---|
| Zdroj dat 1 | Svazek katalogu Unity | JSON | 10 GB | Každý den |
| Zdroj dat 2 | Veřejné rozhraní API | XML | NA (API) | V reálném čase |
| Zdroj dat 3 | SharePoint | PDF, .docx | 500 MB | měsíčně |
Omezení výkonu
Zachyťte požadavky na výkon a prostředky pro aplikaci RAG.
🟡 [P1] Jaká je maximální přijatelná latence pro generování odpovědí?
🟡 [P1] Jaká je maximální přijatelná doba do prvního tokenu?
🟡 [P1] Pokud se výstup streamuje, je přijatelná vyšší celková latence?
🟡 [P1] Existují nějaká omezení nákladů na výpočetní prostředky dostupné pro zpracování?
🟡 [P1] Jaké jsou očekávané vzory využití a zatížení ve špičce?
🟡 [P1] Kolik souběžných uživatelů nebo požadavků by měl systém zvládnout? Databricks nativně zpracovává takové požadavky na škálovatelnost prostřednictvím možnosti automatického škálování pomocí služby Model Serving.
Hodnocení
Zjistěte, jak se bude řešení RAG vyhodnocovat a v průběhu času zlepšovat.
🟢 [P0] Jaký je obchodní cíl nebo klíčový ukazatel výkonu, který chcete ovlivnit? Jaká je základní hodnota a jaký je cíl?
🟢 [P0] Kteří uživatelé nebo účastníci budou poskytovat počáteční a průběžnou zpětnou vazbu?
🟢 [P0] Jaké metriky by se měly použít k vyhodnocení kvality vygenerovaných odpovědí? Hodnocení agenta Mosaic AI poskytuje doporučenou sadu metrik, které se mají použít.
🟡 [P1] Jaká je sada otázek, které musí aplikace RAG vyžadovat, aby přešla do produkčního prostředí?
🟡 [P1] Provede [sadu vyhodnocení]
existovat? Je možné získat zkušební sadu uživatelských dotazů spolu s odpověďmi na základní pravdu a (volitelně) správnými podpůrnými dokumenty, které by se měly načíst?
🟡 [P1] Jak se bude shromažďovat a začlenit zpětná vazba uživatelů do systému?
Zabezpečení
Identifikujte všechny aspekty zabezpečení a ochrany osobních údajů.
🟢 [P0] Jsou citlivá/důvěrná data, která je potřeba zpracovat opatrně?
🟡 [P1] Je třeba v řešení implementovat řízení přístupu (například daný uživatel může načíst pouze z omezené sady dokumentů)?
Nasazení
Principy integrace, nasazení a údržby řešení RAG
🟡 Jak by se řešení RAG mělo integrovat se stávajícími systémy a pracovními postupy?
🟡 Jak by měl být model nasazen, škálován a verzován? V tomto kurzu se dozvíte, jak lze v Databricks zpracovávat kompletní životní cyklus pomocí MLflow, Katalogu Unity, sady SDK agenta a obsluhy modelů.
Příklad
Jako příklad zvažte, jak tyto otázky platí pro tuto ukázkovou aplikaci RAG používanou týmem zákaznické podpory Databricks:
| Plocha | Úvahy | Požadavky |
|---|---|---|
| Uživatelské prostředí | - Způsob interakce. – Typické příklady uživatelských dotazů. - Očekávaný formát a styl odpovědi. - Zpracování nejednoznačných nebo irelevantních dotazů. |
- Chat rozhraní integrované se Slack. – Příklady dotazů: "Návody zkrátit čas spuštění clusteru?" "Jaký druh plánu podpory mám?" - Jasné technické odpovědi s fragmenty kódu a odkazy na příslušnou dokumentaci, kde je to vhodné. – V případě potřeby poskytněte kontextové návrhy a eskalace technikům podpory. |
| Údaje | - Počet a typ zdrojů dat. - Formát a umístění dat. - Velikost dat a frekvence aktualizací. - Kvalita a konzistence dat. |
– Tři zdroje dat. - Firemní dokumentace (HTML, PDF). – Vyřešené tikety podpory (JSON). - Příspěvky komunitního fóra (Delta tabulka). – Data uložená v katalogu Unity a aktualizována každý týden. - Celková velikost dat: 5 GB. – Konzistentní datová struktura a kvalita udržovaná dokumentačními a podpůrnými týmy. |
| Výkon | - Maximální přijatelná latence. - Omezení nákladů. – Očekávané využití a souběžnost. |
– Požadavek na maximální latenci. - Omezení nákladů. - Očekávané zatížení ve špičce. |
| Hodnocení | – Dostupnost testovací datové sady. - Metriky kvality. - Shromažďování názorů uživatelů. |
– Odborníci na danou problematiku z jednotlivých oblastí produktů pomáhají kontrolovat výstupy a upravovat nesprávné odpovědi pro vytvoření testovací datové sady. - Obchodní klíčové ukazatele výkonu. - Zvýšení míry řešení požadavků zákaznické podpory. - Snížení času stráveného uživatelem na jednom podpůrném požadavku. - Metriky kvality. Posouzení správnosti a relevance odpovědí pomocí LLM. - LLM hodnotí přesnost vyhledávání. - Uživatel dává palec nahoru nebo dolů. - Zpětná vazba. - Slack bude upraven tak, aby poskytoval palec nahoru nebo dolů. |
| Zabezpečení | - Zpracování citlivých dat. - Požadavky na řízení přístupu. |
– Ve zdroji načítání by neměla být žádná citlivá zákaznická data. – Ověřování uživatelů prostřednictvím jednotného přihlašování komunity Databricks. |
| Nasazení | - Integrace se stávajícími systémy. – Nasazení a správa verzí. |
- Integrace se systémem lístků podpory. – Řetězení nasazené jako koncový bod obsluhy modelu Databricks |
Další krok
Začínáme s krokem 1. Naklonujte úložiště kódu a vytvořte výpočetní prostředky.
< Předchozí: Vývoj řízený vyhodnocením
Další: Krok 1. Klonování úložiště a vytvoření výpočetních prostředků >